Развертывание и тестирование критически важных рабочих нагрузок в Azure
Развертывание и тестирование критически важной среды является важной частью общей эталонной архитектуры. Отдельные метки приложений развертываются с помощью инфраструктуры как кода из репозитория исходного кода. Обновления к инфраструктуре и приложению вверху должны быть развернуты с нулевым временем простоя в приложении. Для получения исходного кода из репозитория и развертывания отдельных меток в Azure рекомендуется использовать конвейер непрерывной интеграции DevOps.
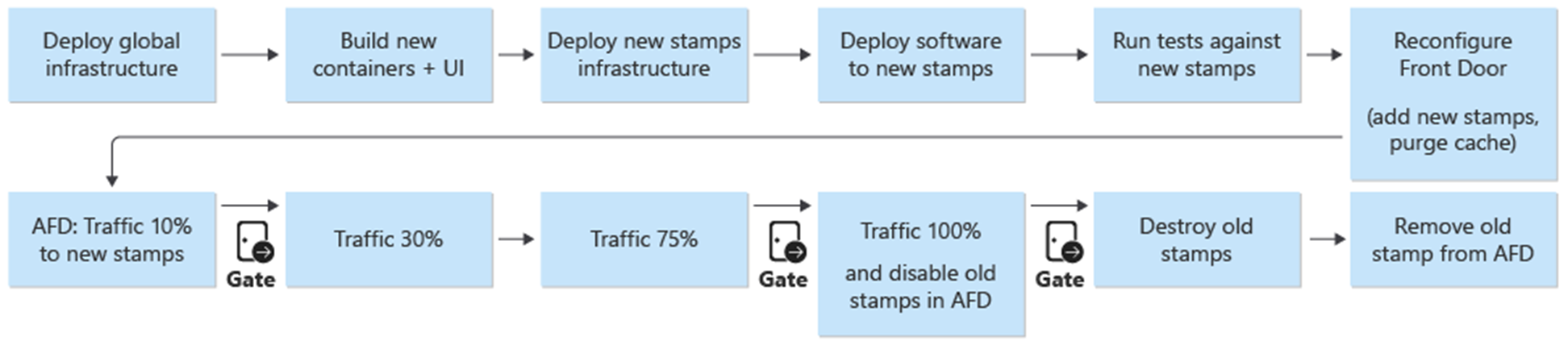
Развертывание и обновление являются центральным процессом в архитектуре. Обновления, связанные с инфраструктурой и приложениями, должны быть развернуты в полностью независимых метках. В метках используются только компоненты глобальной инфраструктуры в архитектуре. Существующие метки в инфраструктуре не затрагиваются. Обновления инфраструктуры будут развертываться только в этих новых метках. Кроме того, новая версия приложения будет развернута только в этих новых метках.
Новые метки добавляются в Azure Front Door. Трафик постепенно перемещается на новые метки. Когда определяется, что трафик обслуживается из новых меток без проблем, предыдущие метки удаляются.
Для развернутой среды рекомендуется проверочное тестирование на проникновение, хаос и стресс-тестирование. При упреждающем тестировании инфраструктуры обнаруживаются слабые места и поведение развернутого приложения в случае сбоя.
Развертывание
Развертывание инфраструктуры в эталонной архитектуре зависит от следующих процессов и компонентов:
DevOps — исходный код из GitHub и конвейеры для инфраструктуры.
Обновления с нулевым временем простоя. Обновления и обновления развертываются в среде с нулевым временем простоя развернутого приложения.
Среды — кратковременные и постоянные среды, используемые для архитектуры.
Общие и выделенные ресурсы — ресурсы Azure, выделенные и совместно используемые для меток и общей инфраструктуры.
Дополнительные сведения см. в статье Развертывание и тестирование критически важных рабочих нагрузок в Azure: рекомендации по проектированию.
Развертывание: DevOps
Компоненты DevOps предоставляют репозиторий исходного кода и конвейеры CI/CD для развертывания инфраструктуры и обновлений. В качестве компонентов были выбраны GitHub и Azure Pipelines.
GitHub — содержит репозитории исходного кода для приложения и инфраструктуры.
Azure Pipelines — конвейеры, используемые архитектурой для всех задач сборки, тестирования и выпуска.
Дополнительным компонентом в структуре, используемой для развертывания, являются агенты сборки. Агенты сборки, размещенные в Майкрософт, используются в составе Azure Pipelines для развертывания инфраструктуры и обновлений. Использование агентов сборки, размещенных в Майкрософт, снимает нагрузку на управление для разработчиков по обслуживанию и обновлению агента сборки.
Дополнительные сведения об Azure Pipelines см. в статье Что такое Azure DevOps Services?.

Дополнительные сведения см. в статье Развертывание и тестирование критически важных рабочих нагрузок в Azure: развертывание инфраструктуры как кода.
Развертывание: ноль обновлений времени простоя
Стратегия обновления с нулевым временем простоя в эталонной архитектуре занимает центральное место в общем критически важном приложении. Методология замены вместо обновления меток обеспечивает новую установку приложения в метку инфраструктуры. Эталонная архитектура использует сине-зеленый подход и позволяет использовать отдельные среды тестирования и разработки.
Существует два main компонента эталонной архитектуры:
Инфраструктура — службы и ресурсы Azure. Развертывается с помощью Terraform и связанной с ним конфигурации.
Приложение — размещенная служба или приложение, которое обслуживает пользователей. На основе контейнеров Docker и npm, созданных артефактами в HTML и JavaScript для пользовательского интерфейса одностраничного приложения (SPA).
Во многих системах предполагается, что обновления приложений будут выполняться чаще, чем обновления инфраструктуры. В результате для каждой из них разрабатываются различные процедуры обновления. Благодаря инфраструктуре общедоступного облака изменения могут происходить быстрее. Был выбран один процесс развертывания для обновлений приложений и инфраструктуры. Один из подходов гарантирует, что обновления инфраструктуры и приложений всегда синхронизированы. Этот подход обеспечивает следующее:
Один согласованный процесс . Меньше шансов на ошибки, если обновления инфраструктуры и приложения смешиваются вместе в выпуске, намеренно или нет.
Включает сине-зеленое развертывание . Каждое обновление развертывается с помощью постепенной миграции трафика в новый выпуск.
Упрощенное развертывание и отладка приложения . Вся метка никогда не будет размещать несколько версий приложения параллельно.
Простой откат . При возникновении ошибок или проблем трафик можно вернуть к отметкам, которые выполняются в предыдущей версии.
Устранение изменений вручную и смещения конфигурации . Каждая среда является новым развертыванием.
Дополнительные сведения см. в статье Развертывание и тестирование критически важных рабочих нагрузок в Azure: временные сине-зеленые развертывания.
Стратегия ветвления
Основой стратегии обновления является использование ветвей в репозитории Git. Эталонная архитектура использует три типа ветвей:
| Ветвь | Описание |
|---|---|
feature/* и fix/* |
Точки входа для любого изменения. Эти ветви создаются разработчиками и должны иметь описательное имя, например feature/catalog-update или fix/worker-timeout-bug. Когда изменения будут готовы к слиянию, создается запрос на вытягивание (PR) для ветви main . Каждый запрос на вытягивание должен быть утвержден по крайней мере одним рецензентом. За ограниченными исключениями каждое изменение, предлагаемое в запросе на вытягивание, должно проходить через конвейер сквозной проверки (E2E). Конвейер E2E должен использоваться разработчиками для тестирования и отладки изменений в полной среде. |
main |
Непрерывно движущаяся и стабильная ветвь. В основном используется для тестирования интеграции. main Изменения в вносятся только через запросы на вытягивание. Политика ветви запрещает прямые операции записи. Ночные выпуски для постоянной integration (int) среды автоматически выполняются из main ветви. Ветвь main считается стабильной. Следует с уверенностью предположить, что в любой момент времени из него можно создать выпуск. |
release/* |
Ветви выпуска создаются только из ветви main . Ветви соответствуют формату release/2021.7.X. Политики ветвей используются таким образом, чтобы создавать release/* ветви разрешено только администраторам репозитория. Для развертывания prod в среде используются только эти ветви. |
Дополнительные сведения см. в статье Развертывание и тестирование критически важных рабочих нагрузок в Azure: стратегия ветвления.
Исправления
Если исправление требуется срочно из-за ошибки или другой проблемы и не удается выполнить обычный процесс выпуска, доступен путь к исправлению. Критические обновления системы безопасности и исправления для пользовательского интерфейса, которые не были обнаружены во время первоначального тестирования, считаются допустимыми примерами исправлений.
Исправление необходимо создать в новой fix ветви, а затем объединить с main помощью обычного запроса на вытягивание. Вместо создания новой ветви выпуска исправление добавляется в существующую ветвь выпуска. Эта ветвь уже развернута в prod среде. Конвейер CI/CD, который изначально развернул ветвь выпуска со всеми тестами, выполняется снова и теперь развертывает исправление как часть конвейера.
Чтобы избежать серьезных проблем, важно, чтобы исправление содержало несколько изолированных фиксаций, которые можно легко выбрать и интегрировать в ветвь выпуска. Если изолированные фиксации не могут быть выбраны для интеграции в ветвь выпуска, это означает, что изменение не квалифицируется как исправление. Изменение должно быть развернуто как полный новый выпуск и, возможно, в сочетании с откатом к прежней стабильной версии до тех пор, пока новый выпуск не будет развернут.
Развертывание: среды
Эталонная архитектура использует два типа сред для инфраструктуры:
Кратковременный — конвейер проверки E2E используется для развертывания кратковременных сред. Кратковременные среды используются для чистой проверки или отладки сред для разработчиков. Среды проверки могут быть созданы из ветви
feature/*, подвергнуты тестам, а затем уничтожены, если все тесты были успешными. Среды отладки развертываются так же, как и при проверке, но не уничтожаются немедленно. Эти среды не должны существовать более нескольких дней и должны быть удалены при слиянии соответствующего запроса на вытягивание ветвь компонента.Постоянное — в постоянных средах есть
integration (int)версии иproduction (prod). Эти среды живут непрерывно и не уничтожаются. Среды используют фиксированные доменные имена , такие как int.mission-critical.app. В реальной реализации эталонной архитектурыstagingнеобходимо добавить среду (предварительную). Средаstagingиспользуется для развертывания и проверкиreleaseветвей с тем же процессом обновления, чтоprodи (сине-зеленое развертывание).Интеграция (int) —
intверсия развертывается ночьюmainиз ветви с тем же процессом, что иprod. Переключение трафика выполняется быстрее, чем в предыдущем выпуске. Вместо постепенного переключения трафика в течение нескольких дней, как вprod, процесс завершаетсяintв течение нескольких минут или часов. Такое быстрое переключение гарантирует, что обновленная среда будет готова к следующему утру. Старые метки автоматически удаляются при успешном выполнении всех тестов в конвейере.Рабочая среда (prod) —
prodверсия развертывается только изrelease/*ветвей. При переключении трафика используются более детализированные шаги. Между каждым этапом находится шлюз утверждения вручную. Каждый выпуск создает новые региональные метки и развертывает новую версию приложения в метках. Существующие метки не затрагиваются в процессе. Наиболее важным факторомprodявляется то, что он должен быть "всегда включен". Плановые или незапланированные простои никогда не должны происходить. Единственным исключением являются базовые изменения уровня базы данных. Может потребоваться период планового обслуживания.
Развертывание: общие и выделенные ресурсы
Постоянные среды (int и prod) в эталонной архитектуре имеют разные типы ресурсов в зависимости от того, используются ли они совместно со всей инфраструктурой или выделены для отдельной метки. Ресурсы могут быть выделены для определенного выпуска и существовать только до тех пор, пока не будет принят следующий выпуск.
Единицы выпуска
Единица выпуска — это несколько региональных меток для каждой конкретной версии выпуска. Метки содержат все ресурсы, которые не являются общими для других меток. Это виртуальные сети, кластер Служба Azure Kubernetes, Центры событий и Key Vault Azure. Azure Cosmos DB и ACR настраиваются с использованием источников данных Terraform.
Глобальные общие ресурсы
Все ресурсы, совместно используемые единицами выпуска, определяются в независимом шаблоне Terraform. К этим ресурсам относятся Front Door, Azure Cosmos DB, реестр контейнеров (ACR), рабочие области Log Analytics и другие ресурсы, связанные с мониторингом. Эти ресурсы развертываются до развертывания первой региональной метки единицы выпуска. Ссылки на ресурсы содержатся в шаблонах Terraform для меток.
Front Door
Хотя Front Door является глобально общим ресурсом для меток, его конфигурация немного отличается от других глобальных ресурсов. Front Door необходимо перенастроить после развертывания новой метки. Front Door необходимо перенастроить для постепенного переключения трафика на новые метки.
Конфигурацию серверной части Front Door нельзя напрямую определить в шаблоне Terraform. Конфигурация вставляется с помощью переменных Terraform. Значения переменных создаются перед запуском развертывания Terraform.
Конфигурация отдельных компонентов для развертывания Front Door определяется следующим образом:
Интерфейс. Сходство сеансов настроено таким образом, чтобы пользователи не переключались между разными версиями пользовательского интерфейса в течение одного сеанса.
Источники — Front Door настраивается с двумя типами групп источников:
Исходная группа для статического хранилища, которое обслуживает пользовательский интерфейс. Группа содержит учетные записи хранения веб-сайтов из всех активных в настоящее время единиц выпуска. Для источников из разных единиц выпуска можно назначить разные весовые коэффициенты, чтобы постепенно перемещать трафик в более новую единицу. Каждому источнику из единицы выпуска должен быть присвоен одинаковый вес.
Исходная группа для API, размещенная в AKS. Если существуют единицы выпуска с разными версиями API, для каждой единицы выпуска существует группа источников API. Если все единицы выпуска предлагают один совместимый API, все источники добавляются в одну группу и назначаются разные весовые коэффициенты.
Правила маршрутизации . Существует два типа правил маршрутизации:
Правило маршрутизации для пользовательского интерфейса, связанного с исходной группой хранилища пользовательского интерфейса.
Правило маршрутизации для каждого API, поддерживаемого в настоящее время источниками. Например,
/api/1.0/*и/api/2.0/*.
Если выпуск представляет новую версию API серверной части, изменения будут отражены в пользовательском интерфейсе, который развертывается как часть выпуска. Конкретный выпуск пользовательского интерфейса всегда будет вызывать определенную версию URL-адреса API. Пользователи, обслуживаемые версией пользовательского интерфейса, будут автоматически использовать соответствующий API серверной части. Для разных экземпляров версии API требуются определенные правила маршрутизации. Эти правила связаны с соответствующими группами источников. Если новый API не был представлен, все связанные с API правила маршрутизации связываются с одной исходной группой. В этом случае не имеет значения, будет ли пользователь обслуживать пользовательский интерфейс из другого выпуска, отличного от API.
Развертывание: процесс развертывания
Сине-зеленое развертывание является целью процесса развертывания. В среде развертывается prod новый выпуск из release/* ветви. Пользовательский трафик постепенно перемещается на метки для нового выпуска.
В качестве первого шага в процессе развертывания новой версии инфраструктура для нового выпуска развертывается с помощью Terraform. Выполнение конвейера развертывания инфраструктуры развертывает новую инфраструктуру из выбранной ветви выпуска. Параллельно с подготовкой инфраструктуры образы контейнеров создаются или импортируются и отправляются в глобальный общий реестр контейнеров (ACR). После завершения предыдущих процессов приложение развертывается в метках. С точки зрения реализации это один конвейер с несколькими зависимыми этапами. Тот же конвейер можно повторно выполнить для развертываний исправлений.
После развертывания и проверки нового блока выпуска он добавляется в Front Door для получения пользовательского трафика.
Следует запланировать параметр или параметр, который различает выпуски, которые выполняют и не вводят новую версию API. В зависимости от того, вводит ли выпуск новую версию API, необходимо создать новую группу источников с серверными серверами API. Кроме того, можно добавить новые серверные серверы API в существующую группу источников. Новые учетные записи хранения пользовательского интерфейса добавляются в соответствующую существующую группу источников. Весовые коэффициенты для новых источников должны быть заданы в соответствии с требуемым разделением трафика. Необходимо создать новое правило маршрутизации, как описано выше, соответствующее соответствующей исходной группе.
При добавлении нового блока выпуска весовые коэффициенты новых источников должны быть заданы в требуемом минимальном трафике пользователя. Если проблем не обнаружено, объем пользовательского трафика следует увеличить до новой группы источников за определенный период времени. Чтобы настроить параметры веса, необходимо снова выполнить те же шаги развертывания с нужными значениями.
Очистка блока выпуска
В рамках конвейера развертывания для единицы выпуска существует этап удаления, который удаляет все метки, когда единица выпуска больше не нужна. Весь трафик перемещается в новую версию выпуска. Этот этап включает удаление ссылок на единицы выпуска из Front Door. Это удаление имеет решающее значение для включения выпуска новой версии на более позднюю дату. Front Door должен указывать на один выпуск, чтобы подготовиться к следующему выпуску в будущем.
Контрольные списки
В рамках частоты выпуска следует использовать контрольный список до и после выпуска. В следующем примере представлены элементы, которые должны быть как минимум в любом контрольном списке.
Контрольный список предварительной версии. Перед запуском выпуска проверка следующее:
Убедитесь, что последнее
mainсостояние ветви успешно развернуто и протестировано вintсреде.Обновите файл журнала изменений с помощью запроса на вытягивание в
mainветвь.Создайте ветвь
release/из ветвиmain.
Контрольный список после выпуска — перед уничтожением старых меток и удалением их ссылок из Front Door проверка, что:
Кластеры больше не получают входящий трафик.
Центры событий и другие очереди сообщений не содержат необработанных сообщений.
Развертывание: ограничения и риски стратегии обновления
Стратегия обновления, описанная в этой эталонной архитектуре, имеет некоторые ограничения и риски, которые следует упомянуть:
Более высокая стоимость. При выпуске обновлений многие компоненты инфраструктуры активируются в два раза за период выпуска.
Сложность Front Door. Процесс обновления в Front Door является сложным для реализации и обслуживания. Возможность выполнения эффективных сине-зеленых развертываний с нулевым временем простоя зависит от правильной работы.
Небольшие изменения требуют много времени. Процесс обновления приводит к более длительному выпуску небольших изменений. Это ограничение можно частично устранить с помощью процесса исправления, описанного в предыдущем разделе.
Развертывание. Рекомендации по совместимости с перенаправлением данных приложения
Стратегия обновления может поддерживать несколько версий API и рабочих компонентов, выполняющихся одновременно. Так как Azure Cosmos DB совместно используется двумя или несколькими версиями, существует вероятность того, что элементы данных, измененные одной версией, могут не всегда соответствовать версии API или рабочих ролей, потребляющих ее. Уровни API и рабочие роли должны реализовывать проект совместимости вперед. Более ранние версии API или рабочие компоненты обрабатывают данные, которые были вставлены более поздней версией API или рабочего компонента. Он игнорирует части, которые он не понимает.
Тестирование
Эталонная архитектура содержит различные тесты, используемые на разных этапах реализации тестирования.
К этим тестам относятся:
Модульные тесты . Эти тесты проверяют, работает ли бизнес-логика приложения должным образом. Эталонная архитектура содержит пример набора модульных тестов, автоматически выполняемых перед каждой сборкой контейнера Azure Pipelines. Если какой-либо тест завершается сбоем, конвейер остановится. Сборка и развертывание не будут продолжены.
Нагрузочные тесты . Эти тесты помогают оценить емкость, масштабируемость и потенциальные узкие места для конкретной рабочей нагрузки или стека. Эталонная реализация содержит генератор пользовательской нагрузки для создания искусственных шаблонов нагрузки, которые можно использовать для имитации реального трафика. Генератор нагрузки также можно использовать независимо от эталонной реализации.
Тесты состояния . Эти тесты определяют, доступны ли инфраструктура и рабочая нагрузка, и действуют должным образом. Тесты состояния выполняются в рамках каждого развертывания.
Тесты пользовательского интерфейса . Эти тесты проверяют, что пользовательский интерфейс был развернут и работает должным образом. Текущая реализация захватывает только снимки экрана нескольких страниц после развертывания без фактического тестирования.
Тесты внедрения ошибок . Эти тесты можно автоматизировать или выполнить вручную. Автоматическое тестирование в архитектуре интегрирует Azure Chaos Studio как часть конвейеров развертывания.
Дополнительные сведения см. в статье Развертывание и тестирование критически важных рабочих нагрузок в Azure: непрерывная проверка и тестирование.
Тестирование: платформы
В интерактивном режиме эталонная реализация существующих возможностей и платформ тестирования, когда это возможно.
| Инфраструктура | Тест | Описание |
|---|---|---|
| NUnit | Unit | Эта платформа используется для модульного тестирования части реализации .NET Core. Azure Pipelines автоматически выполняет модульные тесты перед сборкой контейнера. |
| JMeter с нагрузочного тестирования Azure | Загрузить | Нагрузочное тестирование Azure — это управляемая служба, используемая для выполнения определений нагрузочных тестов Apache JMeter . |
| Locust | Загрузить | Locust — это платформа нагрузочного тестирования с открытым кодом, написанная на Python. |
| Playwright | Пользовательский интерфейс и Дым | Playwright — это библиотека открытый код Node.js для автоматизации Chromium, Firefox и WebKit с помощью одного API. Определение теста Playwright также можно использовать независимо от эталонной реализации. |
| Azure Chaos Studio | Внедрение ошибок | Эталонная реализация использует Azure Chaos Studio в качестве дополнительного шага в конвейере проверки E2E для внедрения ошибок для проверки устойчивости. |
Тестирование: тестирование внедрения сбоев и разработка chaos
Распределенные приложения должны быть устойчивыми к сбоям служб и компонентов. Тестирование внедрения ошибок (также известное как внедрение ошибок или chaos engineering) — это практика, когда приложения и службы подвергаются реальным нагрузкам и сбоям.
Устойчивость — это свойство всей системы, и внедрение ошибок помогает находить проблемы в приложении. Решение этих проблем помогает проверить устойчивость приложения к ненадежным условиям, отсутствующим зависимостям и другим ошибкам.
В инфраструктуре можно выполнять ручные и автоматические тесты для поиска ошибок и проблем в реализации.
Автоматически
Эталонная архитектура интегрирует Azure Chaos Studio для развертывания и запуска набора экспериментов Azure Chaos Studio для внедрения различных ошибок на уровне метки. Эксперименты chaos можно выполнять как необязательную часть конвейера развертывания E2E. При выполнении тестов необязательный нагрузочный тест всегда выполняется параллельно. Нагрузочный тест используется для создания нагрузки в кластере для проверки влияния внедренных ошибок.
Вручную
Тестирование внедрения ошибок вручную должно выполняться в среде проверки E2E. Эта среда обеспечивает полные репрезентативные тесты без риска вмешательства из других сред. Большинство сбоев, созданных с помощью тестов, можно наблюдать непосредственно в представлении динамических метрик Application Insights. Остальные ошибки доступны в представлении Сбои и в соответствующих таблицах журнала. Для других сбоев требуется более глубокая отладка kubectl , например использование для наблюдения за поведением в AKS.
Ниже приведены два примера тестов внедрения ошибок, выполняемых для эталонной архитектуры:
Внедрение отказа на основе DNS — тестовый случай, который может имитировать несколько проблем. Сбои разрешения DNS из-за сбоя DNS-сервера или Azure DNS. Тестирование на основе DNS может помочь имитировать общие проблемы с подключениями между клиентом и службой, например, когда BackgroundProcessor не может подключиться к Центрам событий.
В сценариях с одним узлом можно изменить локальный
hostsфайл, чтобы перезаписать разрешение DNS. В более крупной среде с несколькими динамическими серверами, такими как AKS,hostsфайл не представляется возможным. Зоны Частная зона DNS Azure можно использовать в качестве альтернативы сценариям сбоя тестирования.Центры событий Azure и Azure Cosmos DB — это две службы Azure, используемые в эталонной реализации, которые можно использовать для внедрения ошибок на основе DNS. Разрешением DNS Центров событий можно управлять с помощью зоны azure Частная зона DNS, привязанной к виртуальной сети одной из меток. Azure Cosmos DB — это глобально реплицированная служба с конкретными региональными конечными точками. Обработка записей DNS для этих конечных точек может имитировать сбой для определенного региона и проверить отработку отказа клиентов.
Блокировка брандмауэра . Большинство служб Azure поддерживают ограничения доступа к брандмауэру на основе виртуальных сетей и (или) IP-адресов. В эталонной инфраструктуре эти ограничения используются для ограничения доступа к Azure Cosmos DB или Центрам событий. Простая процедура заключается в удалении существующих правил разрешения или добавлении новых правил блокировки . Эта процедура может имитировать неправильные настройки брандмауэра или сбои служб.
Следующие примеры служб в эталонной реализации можно протестировать с помощью проверки брандмауэра:
Служба Результат хранилище ключей; Когда доступ к Key Vault заблокирован, самым прямым эффектом был сбой создания новых модулей pod. Драйвер Key Vault CSI, который извлекает секреты при запуске pod, не может выполнять свои задачи и предотвращает запуск pod. Соответствующие сообщения об ошибках можно наблюдать с kubectl describe po CatalogService-deploy-my-new-pod -n workloadпомощью . Существующие модули pod будут продолжать работать, хотя будет наблюдаться то же сообщение об ошибке. Сообщение об ошибке создается результатами периодического обновления проверка секретов. Хотя оно не протестировано, предполагается, что выполнение развертывания не будет работать, пока Key Vault недоступен. Задачи Terraform и Azure CLI в конвейере выполняют запросы на Key Vault.Центры событий Если доступ к Центрам событий заблокирован, новые сообщения, отправленные CatalogService и HealthService, завершатся ошибкой . Получение сообщений с помощью BackgroundProcess будет медленно завершаться сбоем с полным сбоем в течение нескольких минут. Azure Cosmos DB Удаление существующей политики брандмауэра для виртуальной сети приводит к сбою службы работоспособности с минимальной задержкой. Эта процедура имитирует только определенный случай— полный сбой Azure Cosmos DB. Большинство случаев сбоев, возникающих на региональном уровне, следует устранять автоматически путем прозрачной отработки отказа клиента в другой регион Azure Cosmos DB. Описанное ранее тестирование внедрения ошибок на основе DNS является более значимым тестом для Azure Cosmos DB. Реестр контейнеров (ACR) Если доступ к ACR заблокирован, создание новых модулей pod, которые были извлечены и кэшированы ранее на узле AKS, продолжат работать. Создание по-прежнему работает из-за флага pullPolicy=IfNotPresentразвертывания k8s . Узлы, которые не извлекли и не кэшировали образ до блока, не могут создать новый модуль pod и немедленно завершатся сбоем сErrImagePullошибками.kubectl describe podотображает соответствующее403 Forbiddenсообщение.Load Balancer входящего трафика AKS Изменение правил входящего трафика для HTTP(S) (порты 80 и 443) в управляемой группе безопасности сети AKS (NSG) на Запрет приводит к тому, что трафик пробы пользователя или пробы работоспособности не достигает кластера. При проверке этого сбоя трудно определить первопричину, которая была имитирована как блокировка между сетевым путем Front Door и региональной меткой. Front Door немедленно обнаруживает этот сбой и снимает сбой поворота.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по