Идеи решения
Эта статья является идеей решения. Если вы хотите расширить содержимое с дополнительными сведениями, такими как потенциальные варианты использования, альтернативные службы, рекомендации по реализации или рекомендации по ценам, сообщите нам, предоставив отзыв GitHub.
В этом примере описывается, как выполнять добавочную загрузку в конвейере извлечения, загрузки и преобразования (ELT). Для автоматизации этого конвейера используется Фабрика данных Azure. Конвейер постепенно перемещает последние данные OLTP из локальной базы данных SQL Server в Azure Synapse. Данные о транзакциях преобразуются в табличную модель для анализа.
Архитектура

Скачайте файл Visio для этой архитектуры.
Эта архитектура основана на той, которая показана в Enterprise BI с Azure Synapse, но добавляет некоторые функции, важные для корпоративных сценариев хранения данных.
- Автоматизация конвейера с помощью Фабрики данных.
- Добавочная загрузка.
- Интеграция нескольких источников данных.
- Загрузка таких двоичных данных, как геопространственные данные и изображения.
Рабочий процесс
Архитектура состоит из следующих служб и компонентов.
Источники данных
Локальный сервер SQL Server. Исходные данные размещаются локально в базе данных SQL Server. Имитация локальной среды. В качестве базы данных-источника используется пример базы данных OLTP Wide World Importers.
Внешние данные. Распространенный сценарий для хранилищ данных — выполнение интеграции нескольких источников данных. Для этой эталонной архитектуры загружается набор внешних данных о численности населения города по годам, интегрируемый с данными из базы данных OLTP. Эта данные можно использовать для получения полезных сведений. Например, чтобы узнать, соответствуют ли показатели роста продаж в каждом регионе показателям роста населения или превышают их.
Прием и хранение данных
Хранилище больших двоичных объектов. Хранилище BLOB-объектов используется в качестве промежуточной области для исходных данных перед загрузкой в Azure Synapse.
Azure Synapse. Azure Synapse — это распределенная система для аналитических вычислений на основе больших объемов данных. Она поддерживает массовую параллельную обработку (MPP), что делает ее пригодной для выполнения высокопроизводительной аналитики.
Фабрика данных Azure. Фабрика данных — это управляемая служба, которая координирует и автоматизирует перемещение и преобразование данных. В этой архитектуре она координирует разные этапы процесса ELT.
Анализ и создание отчетов
Службы Azure Analysis Services. Analysis Services — полностью управляемая служба, которая предоставляет возможности моделирования данных. Семантическая модель загружается в службы Analysis Services.
Power BI. Power BI — набор средств бизнес-аналитики для анализа информации о бизнесе. В этой архитектуре он запрашивает семантическую модель, хранящуюся в службе Analysis Services.
Проверка подлинности
Идентификатор Microsoft Entra (Идентификатор Microsoft Entra) проверяет подлинность пользователей, которые подключаются к серверу служб Analysis Services через Power BI.
Фабрика данных также может использовать идентификатор Microsoft Entra для проверки подлинности в Azure Synapse с помощью субъекта-службы или управляемого удостоверения службы (MSI).
Компоненты
- Хранилище BLOB-объектов Azure
- Azure Synapse Analytics
- Фабрика данных Azure
- Azure Analysis Services;
- Power BI
- Microsoft Entra ID
Подробности сценария
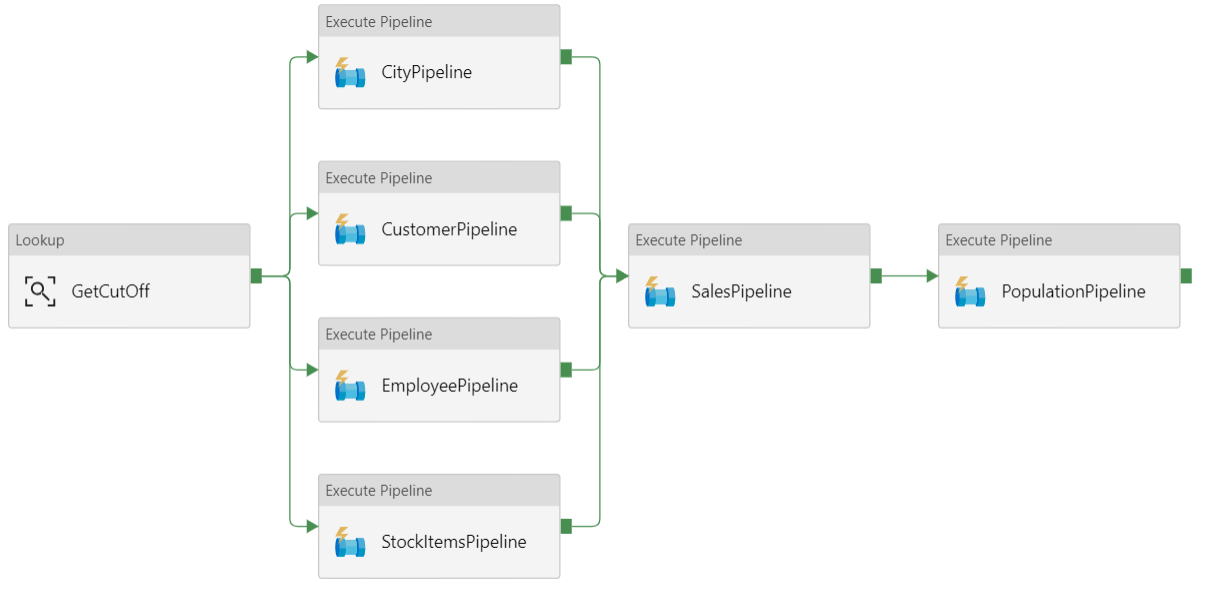
Конвейер данных
В Фабрика данных Azure конвейер представляет собой логическую группу действий, используемых для координации задачи. В этом случае загрузка и преобразование данных в Azure Synapse.
Эта эталонная архитектура определяет родительский конвейер, который выполняет последовательность дочерних конвейеров. Каждый дочерний конвейер загружает данные в одну или несколько таблиц в хранилище данных.
Рекомендации
Добавочная загрузка
При выполнении автоматизированного процесса ETL или ELT гораздо эффективнее загружать только те данные, которые изменились с момента предыдущего выполнения. Это называется добавочной нагрузкой, а не полной нагрузкой, которая загружает все данные. Чтобы выполнить добавочную загрузку, нужно выбрать метод определения измененных данных. Для этого чаще всего используется значение верхнего предела. То есть отслеживается последнее значение в некотором столбце исходной таблицы, например по столбцу даты и времени или по столбцу уникальных целых чисел.
Начиная с версии SQL Server 2016, вы можете использовать темпоральные таблицы. Это таблицы с системным управлением версиями, в которых хранится полный журнал изменения данных. Ядро СУБД автоматически записывает каждое изменение в отдельную таблицу журнала. Чтобы запросить данные журнала, добавьте в запрос предложение FOR SYSTEM_TIME. На внутреннем уровне ядро СУБД отправляет запрос к таблице журнала, но это происходит незаметно для приложения.
Примечание.
Для более ранних версий SQL Server можно использовать функцию отслеживания измененных данных (CDC). Этот метод не такой удобный, как темпоральные таблицы, так как вам нужно запросить отдельную таблицу изменений, и изменения отслеживаются по регистрационному номеру транзакции (LSN) в журнале, а не по метке времени.
Темпоральные таблицы удобно использовать для данных измерений, которые могут изменяться со временем. В таблице фактов обычно представлены неизменяемые транзакции, например при продаже. В этом случае ведение журнала версий системы не имеет смысла. Вместо этого для транзакций обычно присутствует столбец, в котором представлена дата транзакции, что может использоваться в качестве значения верхнего предела. Например, в базе данных OLTP Wide World Importers таблицы Sales.Invoices и Sales.InvoiceLines имеют поле LastEditedWhen со значением по умолчанию sysdatetime().
Ниже приведена стандартный поток для конвейера ELT:
Для каждой таблицы базы данных-источника отслеживается пороговое значение времени, когда запускается последнее задание ELT. Сохраните эту информацию в хранилище данных. (При начальной настройке для всех значений времени указано 1-1-1900.)
На этапе экспорта данных пороговое значение времени передается в качестве параметра в набор хранимых процедур в базе данных-источника. Эти хранимые процедуры запрашивают любые записи, которые были изменены или созданы после этого значения времени. Для таблицы фактов Sales используется столбец
LastEditedWhen. Для данных измерения используются темпоральные таблицы с системным управлением версиями.Когда перенос данных завершится, обновите таблицу, в которой хранятся пороговые значения времени.
Также полезно вести журнал преобразований для каждого выполнения ELT. В таком журнале определенная запись связывается с выполнением ELT, при котором создаются данные. При каждом выполнении ETL создается запись журнала преобразований для каждой таблицы. В этой записи указано время начала и завершения загрузки. Ключи для каждой записи журнала преобразований хранятся в таблицах фактов и измерений.
Когда новый пакет данных загрузится в хранилище, обновите табличную модель служб Analysis Services. Дополнительные сведения см. в статье Асинхронное обновление с помощью REST API.
Очистка данных
Очистка данных должна выполняться в рамках процесса ELT. В этой эталонной архитектуре есть один источник с поврежденными данными — таблица численности населения по городам, где некоторые города имеют нулевое значение, возможно, из-за недоступности данных. Во время обработки в конвейере ELT такие города удаляются из таблицы численности населения по городам. Очистку данных следует выполнять с промежуточными таблицами, а не внешними.
Внешние источники данных
В хранилищах часто объединяются данные из нескольких источников. Например, внешний источник данных, содержащий демографические данные. Этот набор данных доступен в хранилище BLOB-объектов Azure как часть примера WorldWideImportersDW.
В Фабрике данных Azure можно копировать данные прямо из хранилища BLOB-объектов с помощью соответствующего соединителя. Но соединителю требуется строка подключения или подписанный URL-адрес, поэтому вы не сможете использовать соединитель для копирования BLOB-объекта с общим доступом на чтение. В качестве обходного решения можно использовать PolyBase для создания внешней таблицы в хранилище BLOB-объектов, а затем копирования внешних таблиц в Azure Synapse.
Обработка больших двоичных данных
Например, в исходной базе данных таблица "Город" содержит столбец location, содержащий тип пространственных данных географического пространства. Azure Synapse не поддерживает тип geography в собственном коде, поэтому это поле преобразуется в тип varbinary во время загрузки. Дополнительные сведения см. в разделе Обходные решения для неподдерживаемых типов данных.
Но в PolyBase размер столбца не должен превышать значение varbinary(8000). Это означает, что некоторые данные могут быть усечены. Чтобы решить эту проблему, вы можете разбить данные на блоки во время экспорта, а затем воссоединить их, как описано ниже:
Создайте временную промежуточную таблицу для столбца Location.
Для каждого города разбиение данных о расположении на 8000-байтовые блоки, в результате чего 1 – N строк для каждого города.
Чтобы воссоединить эти блоки, с помощью оператора T-SQL PIVOT преобразуйте строки в столбцы, а затем сцепите значения столбцов для каждого города.
Сложность состоит в том, что для каждого города будет разное количество строк, в зависимости от размера географических данных. Для использования оператора PIVOT необходимо, чтобы у каждого города было одинаковое количество строк. Чтобы сделать эту работу, запрос T-SQL выполняет некоторые рекомендации по заполнению строк пустыми значениями, чтобы каждый город имеет одинаковое количество столбцов после сводной таблицы. Результирующий запрос выполняется намного быстрее, чем последовательный циклический перебор каждой строки.
Такой же подход используется для данных изображений.
Медленно изменяющиеся измерения
Данные измерений являются относительно статичными, но могут изменяться. Например, продукт может быть переназначен другой категории продуктов. Медленно изменяющиеся измерения можно обрабатывать несколькими способами. Для этого чаще всего используется тип 2, который позволяет добавлять новую запись при каждом изменении измерения.
Чтобы реализовать такой метод, в таблицу измерений нужно добавить столбцы, которые определяют фактический диапазон дат для определенной записи. Кроме того, нужно продублировать первичные ключи из базы данных-источника, чтобы таблица измерений содержала смоделированные первичные ключи.
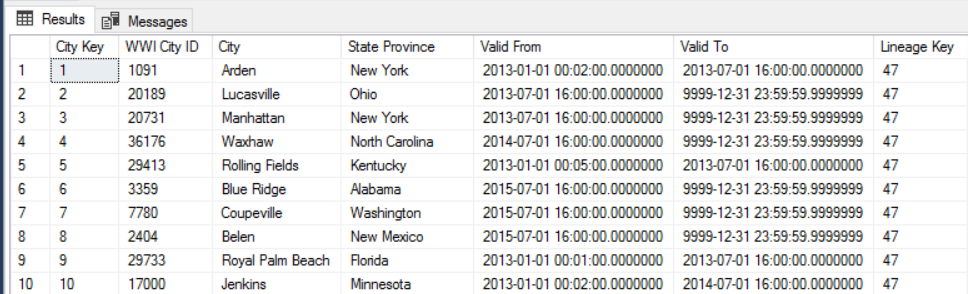
Например, на следующем рисунке показана таблица Dimension.City. В столбце WWI City ID представлены первичные ключи из базы данных-источника. А в столбце City Key содержатся смоделированные ключи, созданные при выполнении конвейера ETL. Также обратите внимание, что в таблице есть столбцы Valid From и Valid To, которые определяют период, в который строка была актуальна. Текущие значения в столбце Valid To равны 9999-12-31.
Преимущество такого подхода заключается в том, что он позволяет хранить данные журнала, которые могут пригодиться для анализа. Но это также означает, что у одной сущности будет несколько строк. Например, ниже показаны записи, для которых в столбце WWI City ID указано значение 28561:

Каждый факт Sales необходимо связать с одной строкой в таблице измерения City, соответствующей дате выставления счета.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Безопасность
Безопасность обеспечивает гарантии от преднамеренного нападения и злоупотребления ценными данными и системами. Дополнительные сведения см. в разделе "Общие сведения о компоненте безопасности".
Чтобы обеспечить дополнительную защиту ресурсов служб Azure только в своей виртуальной сети, используйте конечные точки служб для виртуальной сети. Это позволит полностью исключить открытый доступ из Интернета к этим ресурсам и разрешить трафик только из виртуальной сети.
В этом случае вам нужно создать виртуальную сеть в Azure и частные конечные точки для служб Azure. В такие службы трафик будет поступать только из виртуальной сети. Доступ к таким службам можно также получить в локальной сети через шлюз.
Следует учитывать следующие ограничения.
Если конечные точки службы включены для служба хранилища Azure, PolyBase не может копировать данные из служба хранилища в Azure Synapse. Эту проблему можно устранить. Дополнительные сведения см. в разделе Влияние использования конечных точек службы виртуальной сети со службой хранилища Azure.
Чтобы переместить данные из локальной среды в служба хранилища Azure, необходимо разрешить общедоступные IP-адреса из локальной или ExpressRoute. Дополнительные сведения см. в разделе Защита служб Azure в виртуальных сетях.
Чтобы службы Analysis Services могли считывать данные из Azure Synapse, разверните виртуальную машину Windows в виртуальной сети, содержащей конечную точку службы Azure Synapse. Установите в этой виртуальной машине локальный шлюз данных Azure. Затем подключите службы Azure Analysis Services к этому шлюзу данных.
DevOps
Создайте отдельные группы ресурсов для рабочей среды, сред разработки и тестирования. Так будет проще управлять развертываниями, удалять тестовые развертывания и назначать права доступа.
Поместите каждую рабочую нагрузку в отдельный шаблон развертывания и сохраните ресурсы в системах управления версиями. Вы можете развернуть шаблоны вместе или отдельно в рамках процесса CI/CD, что упрощает процесс автоматизации.
В этой архитектуре существует три основных рабочих нагрузки:
- Сервер хранилища данных, службы Analysis Services и связанные ресурсы.
- Фабрика данных Azure.
- Локальный имитированный в облаке сценарий.
Каждая рабочая нагрузка имеет собственный шаблон развертывания.
Сервер хранилища данных настраивается и настраивается с помощью команд Azure CLI, которые соответствуют императивной методике IaC. Рассмотрите возможность использования скриптов развертывания и их интеграции в процесс автоматизации.
Рассмотрите возможность промежуточного хранения рабочих нагрузок. Развертывание на различных этапах и запуск проверка проверки на каждом этапе перед переходом к следующему этапу. Таким образом вы можете отправлять обновления в рабочие среды с высокой степенью контроля и свести к минимуму непредвиденные проблемы с развертыванием. Используйте стратегии развертывания Blue-green и Canary для обновления рабочих сред в реальном времени.
У вас хорошая стратегия отката для обработки неудачных развертываний. Например, вы можете автоматически повторно развернуть более раннее успешное развертывание из журнала развертывания. См. параметр флага --rollback-on-error в Azure CLI.
Azure Monitor — это рекомендуемый вариант для анализа производительности хранилища данных и всей платформы аналитики Azure для интегрированного мониторинга. Azure Synapse Analytics предоставляет возможности мониторинга в портал Azure для отображения аналитических сведений о рабочей нагрузке хранилища данных. Портал Azure — это рекомендуемое средство для мониторинга хранилища данных, так как оно предоставляет настраиваемые периоды хранения, оповещения, рекомендации и настраиваемые диаграммы и панели мониторинга для метрик и журналов.
Дополнительные сведения см. в разделе DevOps в Microsoft Azure Well-Architected Framework.
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
Для оценки затрат используйте калькулятор цен Azure. Ниже приведены некоторые рекомендации по службам, используемым в этой эталонной архитектуре.
Azure Data Factory
Фабрика данных Azure автоматизирует конвейер ELT. Конвейер перемещает данные из локальной базы данных SQL Server в Azure Synapse. Затем данные преобразуются в табличную модель для анализа. В этом сценарии цены начинаются с 0,001 долл. США в месяц, включая действия, триггеры и отладки. Эта цена является базовой оплатой только для оркестрации. Вы также платите за действия выполнения, такие как копирование данных, уточняющие запросы и внешние действия. Каждое действие тарифицируется по отдельности. Также взимается плата за конвейеры без связанных триггеров или выполнений в течение месяца. Плата за все действия рассчитывается пропорционально в минутах и округляется.
Пример анализа затрат
Рассмотрим вариант использования, в котором есть два действия подстановки из двух разных источников. Один занимает 1 минуту и 2 секунды (округляется до 2 минут), а другой занимает 1 минуту, что приводит к общему времени 3 минуты. Одно действие копирования данных занимает 10 минут. Одно действие хранимой процедуры занимает 2 минуты. Общее количество действий выполняется в течение 4 минут. Стоимость вычисляется следующим образом:
Выполнение действия: 4 * $ 0,001 = $0,004
Подстановки: 3 * ($0,005/ 60) = $0,00025
Хранимая процедура: 2 * ($0,00025 / 60) = $0,000008
Копирование данных: 10 * ($0,25 / 60) * 4 единица интеграции данных (DIU) = $0,167
- Общая стоимость на выполнение конвейера: $0,17.
- Запустите один раз в день в течение 30 дней: $ 5,1 месяц.
- Запуск один раз в день за 100 таблиц в течение 30 дней: $ 510
Каждое действие имеет связанную стоимость. Ознакомьтесь с моделью ценообразования и используйте калькулятор цен ADF, чтобы получить решение, оптимизированное не только для производительности, но и для затрат. Управление затратами путем запуска, остановки, приостановки и масштабирования служб.
Azure Synapse
Azure Synapse идеально подходит для интенсивных рабочих нагрузок с более высокой производительностью запросов и потребностями масштабируемости вычислений. Вы можете выбрать модель оплаты по мере использования или использовать зарезервированные планы одного года (37% экономии) или 3 года (65% экономии).
Хранилище данных взимается отдельно. Другие службы, такие как аварийное восстановление и обнаружение угроз, также взимается отдельно.
Дополнительные сведения см. в разделе "Цены на Azure Synapse".
Службы Analysis Services
Цены на Службы Azure Analysis Services зависят от уровня. Эталонная реализация этой архитектуры использует уровень разработчика , который рекомендуется для оценки, разработки и тестирования сценариев. Другие уровни включают уровень "Базовый", который рекомендуется для небольшой рабочей среды; уровень "Стандартный" для критически важных рабочих приложений. Дополнительные сведения см. в разделе "Правильный уровень" при необходимости.
При приостановке экземпляра плата не взимается.
Дополнительные сведения см. на странице цен на службы Azure Analysis Services.
Хранилище BLOB-объектов
Рекомендуется использовать функцию зарезервированной емкости служба хранилища Azure для снижения затрат на хранилище. С помощью этой модели вы получаете скидку, если вы можете зафиксировать резервирование для фиксированной емкости хранилища в течение одного или трех лет. Дополнительные сведения см. в статье "Оптимизация затрат на хранилище BLOB-объектов с зарезервированной емкостью".
Дополнительные сведения см. в разделе "Затраты" в Microsoft Azure Well-Architected Framework.
Следующие шаги
- Общие сведения об Azure Synapse Analytics
- Начало работы с Azure Synapse Analytics
- Общие сведения о службе фабрики данных Azure, службе интеграции данных в облаке
- Что такое Фабрика данных Azure?
- руководства по Фабрика данных Azure
Связанные ресурсы
Вы можете просмотреть следующий пример сценария Azure, в котором описываются конкретные решения, использующие некоторые из этих технологий: