Перемещение данных в кластер vFXT — параллельный прием данных
После создания кластера vFXT первой задачей может быть перемещение данных в новый том хранилища Azure. Однако, если вы будете использовать обычный метод — выполнение простой команды копирования из одного клиента — вероятно, скорость копирования будет низкой. Однопоточное копирование неэффективно как способ копирования данных в серверное хранилище кластера Avere vFXT.
Так как кластер Avere vFXT для Azure представляет собой масштабируемый кэш с несколькими клиентами, самый быстрый и эффективный способ копирования данных в него — использовать несколько клиентов. Этот метод параллелизует прием файлов и объектов.
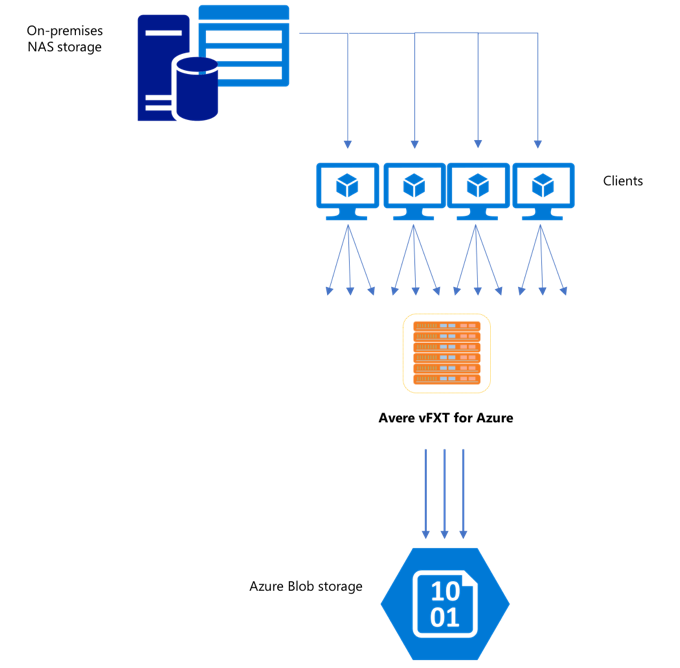
Команды cp или copy, которые обычно используются для переноса данных из одной системы хранения в другую, представляют собой однопотоковые процессы, которые одновременно копируют по одному файлу за раз. Это означает, что файловый сервер принимает только один файл за раз, что является пустой тратой ресурсов кластера.
В этой статье описываются стратегии создания многоклиентской многопоточной системы копирования файлов для перемещения данных в кластер Avere vFXT. В ней описываются концепции передачи файлов и точки принятия решений, которые можно использовать для эффективного копирования данных с использованием нескольких клиентов и простых команд копирования.
Здесь также описываются некоторые служебные программы, которые могут помочь. С помощью служебной программы msrsync можно частично автоматизировать процесс разбиения набора данных на группы и работу с командами rsync. Сценарий parallelcp — это другая служебная программа, которая считывает исходный каталог и выдает команды копирования автоматически. Кроме того, работу со средством rsync можно организовать в два этапа, чтобы ускорить копирование, не жертвуя согласованностью данных.
Щелкните ссылку, чтобы перейти к нужному разделу:
- Пример копирования вручную (подробное объяснение использования команд копирования)
- Пример двухэтапной организации работы с rsync
- Пример частичной автоматизации (msrsync)
- Пример параллельного копирования
Шаблон виртуальной машины для приема данных
На GitHub доступен шаблон Resource Manager, позволяющий автоматически создать виртуальную машину со средствами параллельного приема данных, упомянутыми в этой статье.
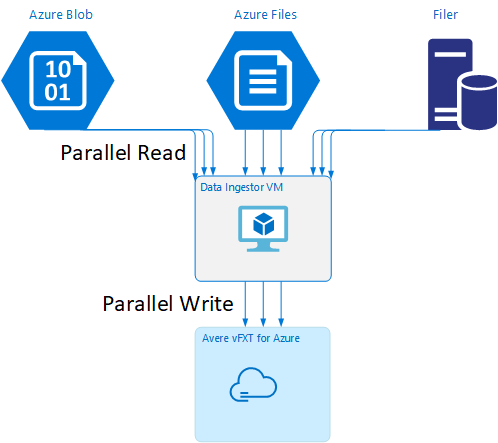
Виртуальная машина для приема данных рассматривается в руководстве, в котором вновь созданная виртуальная машина подключается к кластеру Avere vFXT и скачивает из него сценарий начальной загрузки. Дополнительные сведения см. в статье Data Ingestor - Parallel data ingest (Прием данных — параллельный прием данных).
Стратегическое планирование
При разработке стратегии параллельного копирования данных следует представлять себе компромисс между размерами файлов, их числом и глубиной каталогов.
- Если файлы малы, нужная метрика — количество файлов в секунду.
- Если файлы большие (10 MБ или больше), нужная метрика — число байт в секунду.
Каждый процесс копирования имеет пропускную способность и скорость передачи файлов, которые можно измерять по времени команды копирования с учетом размера и количества файлов. Объяснение того, как измерять скорость, выходит за рамки этого документа, но важно понять, с файлами какого размера вы будете работать.
Пример копирования вручную
Можно вручную создать многопоточные операции копирования на клиентском компьютере, запустив более одной команды копирования одновременно в фоновом режиме для предопределенных наборов файлов или путей.
Команда Linux/UNIX cp содержит аргумент -p для сохранения прав владения и метаданных времени. Добавление этого аргумента в приведенные ниже команды является необязательным. Добавление аргумента увеличивает количество вызовов файловой системы, отправляемых от клиента в целевую файловую систему для изменения метаданных.
В этом простом примере два файла копируются в параллельном режиме:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
После запуска этой команды команда jobs покажет, что выполняются два потока.
Прогнозируемая структура имен файлов
Если имена файлов предсказуемы, можно использовать выражения для создания параллельных потоков копирования.
Например, если в каталоге содержится 1000 файлов, пронумерованных последовательно от 0001 до 1000, можно использовать следующие выражения для создания десяти параллельных потоков, каждый из которых копирует 100 файлов:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Неизвестная структура имен файлов
Если структура именования файлов непредсказуема, можно сгруппировать файлы по именам каталогов.
В этом примере осуществляется сбор целых каталогов для отправки в команды cp, выполняемые в качестве фоновых задач.
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
После сбора файлов можно выполнить команды параллельного копирования, чтобы рекурсивно скопировать подкаталоги и все их содержимое:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Когда добавлять точки подключения
После того как будет достаточно параллельных потоков, направленных к одной точке подключения файловой системы, наступит момент, когда добавление потоков не обеспечит больше пропускной способности. (Пропускная способность будет измеряться в файлах в секунду или байтах в секунду в зависимости от типа данных.) Или, что еще хуже, иногда слишком большое количество параллельных потоков может вызвать снижение пропускной способности.
В этом случае можно добавить клиентские точки подключения к другим IP-адресам кластера vFXT, используя тот же путь подключения к удаленной файловой системе:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Добавление точек подключения на стороне клиента позволяет разделить дополнительные команды копирования на дополнительные точки подключения /mnt/destination[1-3], что позволяет повысить уровень параллелизма.
Например, если файлы очень велики, можно определить для команд копирования использование различных путей назначения, параллельно отправив дополнительные команды из клиента, выполняющего копирование.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
В приведенном выше примере процессы копирования файлов клиента направлены на все три целевые точки подключения.
Когда следует добавлять клиенты
Наконец, когда вы достигли предела возможностей клиента, добавление потоков копирования или точек подключения не даст дополнительного увеличения числа файлов в секунду или байт в секунду. В этой ситуации можно развернуть другой клиент с тем же набором точек подключения, для которых будут выполняться собственные наборы процессов копирования файлов.
Пример:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Создание манифестов файлов
Теперь, когда вы разобрались с описанными выше подходами (множественные потоки копирования в место назначения, множественные места назначения для клиента, несколько клиентов на каждую доступную в сети файловую систему источника), рассмотрите возможность создания манифестов файлов, а затем возможность использования их с командами копирования для нескольких клиентов.
В этом сценарии для создания манифестов файлов или каталогов используется команда UNIX find:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Перенаправьте этот результат в файл: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Затем можно выполнить итерацию по манифесту, используя команды BASH для подсчета файлов и определения размеров подкаталогов:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Наконец, вы должны создавать фактические команды копирования файлов для клиентов.
При наличии четырех клиентов используйте следующую команду:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Если у вас есть пять клиентов, используйте примерно следующее:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
А если шесть, — экстраполируйте соответствующим образом.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Вы получите N файлов (по одному для каждого из ваших N клиентов), у которых есть пути к каталогам 4-го уровня, полученные как часть выходных данных команды find.
Используйте каждый файл для создания команды копирования:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Вы получите N файлов (каждый с командой копирования в строке), которые могут быть запущены в качестве сценария BASH в клиенте.
Целью является параллельное выполнение нескольких потоков этих сценариев в каждом клиенте (одновременно в нескольких клиентах).
Организация работы с rsync в два этапа
Стандартная служебная программа rsync не подходит для заполнения облачного хранилища посредством системы Avere vFXT для Azure, так как инициирует большое количество операций создания и переименования файлов, чтобы гарантировать целостность данных. Однако с rsync можно безбоязненно использовать параметр --inplace, отменяющий некоторые дополнительные предосторожности при копировании, если сразу после выполнить второй прогон для проверки целостности файлов.
При стандартной операции копирования rsync создается временный файл, который заполняется данными. Если передача данных завершается успешно, временный файл переименовывается с присвоением ему исходного имени файла. Этот метод гарантирует согласованность даже в случае доступа к файлам во время копирования, но порождает больше операций записи, из-за чего снижается скорость прохождения файлов через кэш.
Параметр --inplace указывает, что новый файл следует записывать непосредственно в его конечное расположение. Согласованность файлов во время перемещения не гарантируется, но это неважно, если вы подготовите систему хранения данных для последующего использования.
В ходе второй операции rsync проверяется согласованность данных по итогам первой операции. Поскольку файлы уже скопированы, второй этап — это быстрая проверка с целью убедиться, что файлы в месте назначения совпадают с файлами в источнике. Если какие-то файлы не совпадают, они будут скопированы повторно.
Оба этапа можно инициировать одной командой:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Этот простой и эффективный в смысле временных затрат метод копирования наборов данных с числом файлов вплоть до максимального, которое способен обработать внутренний диспетчер каталогов. (Обычно это 200 млн файлов для кластера из трех узлов, 500 млн файлов для кластера из шести узлов и т. д.)
Использование служебной программы msrsync
Средство msrsync также можно использовать для перемещения данных в основное серверное файловое хранилище кластера Avere. Это средство предназначено для оптимизации использования пропускной способности путем запуска нескольких параллельных процессов rsync. Оно доступно на сайте GitHub по адресу https://github.com/jbd/msrsync.
msrsync разбивает исходный каталог на отдельные группы, а затем запускает отдельные процессы rsync в каждой группе.
Предварительное тестирование с использованием четырех основных виртуальных машин показало наилучшую эффективность при выполнении 64 процессов. Используйте параметр -p в msrsync, чтобы настроить 64 процесса.
В командах msrsync также можно указывать аргумент --inplace. Если вы используете этот аргумент, рассмотрите возможность второго прогона (как в описанном выше случае с rsync) для обеспечения целостности данных.
Средство msrsync позволяет выполнять запись только в локальные тома и из них. Источник и назначение должны быть доступны как локальные точки подключения в виртуальной сети кластера.
Чтобы с помощью msrsync заполнить облачный том Azure для кластера Avere, следуйте приведенным ниже инструкциям.
Установите средство
msrsyncи требуемые для него компоненты (rsync и Python 2.6 или более поздней версии).Определите общее число копируемых файлов и каталогов.
Например, используйте служебную программу Avere
prime.pyс аргументамиprime.py --directory /path/to/some/directory(можно скачать по URL-адресу https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Если вы не используете
prime.py, количество элементов можно вычислить с помощью инструмента GNUfind, как описано далее.find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Разделите число элементов на 64, чтобы определить количество элементов для каждого процесса. Используйте это число с параметром
-f, чтобы задать размер групп при выполнении команды.Выполните команду
msrsync, чтобы скопировать файлы:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>При использовании аргумента
--inplaceдобавьте второй прогон без проверки правильности копирования данных:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>К примеру, эта команда предназначена для перемещения 11 000 файлов в 64 процессах из /test/source-repository в /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Использование сценария параллельного копирования
Сценарий parallelcp может также быть полезен для перемещения данных в серверное хранилище кластера vFXT.
Приведенный ниже сценарий добавит исполняемый файл parallelcp. (Этот сценарий предназначен для Ubuntu. Если используется другой дистрибутив, необходимо установить parallel отдельно.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Пример параллельного копирования
В этом примере сценарий параллельного копирования выполняет компиляцию glibc с использованием исходных файлов из кластера Avere.
Исходные файлы хранятся в точке подключения кластера Avere, а файлы объектов — на локальном жестком диске.
Здесь используется сценарий параллельного копирования, описанный выше. Для обеспечения параллелизации с parallelcp и make используется параметр -j.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j