Высокий уровень доступности с поддержкой Azure Arc Управляемый экземпляр SQL
Управляемый экземпляр SQL, включенная Azure Arc, развертывается в Kubernetes в качестве контейнерного приложения. В нем используются конструкции Kubernetes, такие как наборы с отслеживанием состояния и постоянное хранилище для обеспечения встроенного кода:
- Мониторинг работоспособности
- Обнаружение сбоев
- Автоматический отработка отказа для поддержания работоспособности службы.
Для повышения надежности можно также настроить Управляемый экземпляр SQL, включенную Azure Arc для развертывания с дополнительными реплика в конфигурации высокой доступности. Контроллер данных служб данных Arc управляет:
- Наблюдение
- Обнаружение сбоев
- автоматический переход на другой ресурс
Служба данных с поддержкой Arc предоставляет эту службу без вмешательства пользователя. Служба
- Настройка группы доступности
- Настройка конечных точек зеркало базы данных
- Добавляет базы данных в группу доступности
- Координирует отработку отказа и обновление.
В этом документе рассматриваются оба типа обеспечения высокого уровня доступности.
Управляемый экземпляр SQL, включенная Azure Arc, предоставляет различные уровни высокой доступности в зависимости от того, был ли развернут управляемый экземпляр SQL в качестве Уровень служб общего назначения или уровень служб критически важный для бизнеса.
Обеспечение высокого уровня доступности для уровня обслуживания "Общего назначения"
На уровне обслуживания "Общего назначения" доступна только одна реплика, а высокий уровень доступности обеспечивается за счет оркестрации Kubernetes. Например, если модуль pod или узел, содержащий образ контейнера управляемого экземпляра, завершается сбоем, Kubernetes пытается встать на другой модуль pod или узел и подключиться к тому же постоянному хранилищу. В течение этого времени управляемый экземпляр SQL будет недоступен для приложений. Приложениям необходимо повторно подключиться и повторить транзакцию при запуске нового модуля pod. Если используется тип обслуживания load balancer, приложения могут повторно подключиться к той же основной конечной точке, а Kubernetes перенаправит подключение к новой основной конечной точке. Если используется тип обслуживания nodeport, приложениям потребуется повторно подключиться к новому IP-адресу.
Проверка встроенного высокого уровня доступности
Чтобы проверить высокий уровень доступности сборки, предоставляемый Kubernetes, можно:
- Удаление модуля pod существующего управляемого экземпляра
- Убедитесь, что Kubernetes восстанавливается после этого действия.
Во время восстановления Kubernetes загрузит другой модуль pod и подключает постоянное хранилище.
Необходимые компоненты
- Кластер Kubernetes требует общего, удаленного хранилища
- Управляемый экземпляр SQL, включенная Azure Arc, развернутая с одной реплика (по умолчанию)
Просмотрите модули pod.
kubectl get pods -n <namespace of data controller>Удалите модуль pod управляемого экземпляра.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Например.
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedПросмотрите модули pod, чтобы убедиться, что управляемый экземпляр восстанавливается.
kubectl get pods -n <namespace of data controller>Например:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
После восстановления всех контейнеров в модуле pod можно подключиться к управляемому экземпляру.
Обеспечение высокого уровня доступности на уровне обслуживания "Критически важный для бизнеса"
На уровне служб критически важный для бизнеса в дополнение к тому, что изначально предоставляет оркестрация Kubernetes, Управляемый экземпляр SQL для Azure Arc предоставляет содержащуюся группу доступности. Автономная группа доступности построена на основе технологии Always On в SQL Server. Она обеспечивает более высокий уровень доступности. Управляемый экземпляр SQL, включенную Azure Arc, развернутой с критически важный для бизнеса уровня служб, можно развернуть с помощью 2 или 3 реплика. Эти реплики постоянно синхронизируются друг с другом.
При наличии содержащихся групп доступности любые сбои pod или сбои узлов прозрачны для приложения. Содержащаяся группа доступности предоставляет по крайней мере один другой модуль pod, имеющий все данные из основного объекта и готовый к подключению.
Включенные группы доступности
Группа доступности связывает одну или несколько пользовательских баз данных в одну логическую группу, благодаря чему при отработке отказа вся эта группа баз данных переходит на вторичную реплику как единое целое. Группа доступности реплицирует данные только из пользовательских, а не системных баз данных (например, имена для входа, разрешения или задания агента). Автономная группа доступности включает метаданные из системных баз данных, таких как msdb и master. Имена для входа, создаваемые или изменяемые в первичной реплике, автоматически создаются во вторичных репликах. Аналогичным образом, создание или изменение задания агента в первичной реплике также дублируется во вторичных репликах.
Управляемый экземпляр SQL, включенная Azure Arc, принимает эту концепцию автономной группы доступности и добавляет оператор Kubernetes, чтобы их можно было развертывать и управлять в большом масштабе.
Возможности, которые включают автономные группы доступности:
При развертывании с несколькими репликами создается одна группа доступности с тем же именем, что и управляемый экземпляр SQL с поддержкой Arc. По умолчанию автономная группа доступности имеет три реплики, включая первичную. Все операции CRUD для группы доступности управляются внутренним образом, в том числе создание группы доступности или присоединение реплик к созданной группе доступности. В экземпляре нельзя создавать больше групп доступности.
Все базы данных автоматически добавляются в группу доступности, в том числе все пользовательские и системные базы данных, такие как
masterиmsdb. Эта возможность обеспечивает представление единой системы во всех репликах группы доступности. При подключении напрямую к экземпляру обратите внимание на базы данныхcontainedag_masterиcontainedag_msdb. Базы данныхcontainedag_*представляютmasterиmsdbв группе доступности.Внешняя конечная точка автоматически подготавливается для подключения к базам данных в группе доступности. Эта конечная точка
<managed_instance_name>-external-svcвыполняет роль прослушивателя группы доступности.
Развертывание Управляемый экземпляр SQL в Azure Arc с несколькими реплика с помощью портал Azure
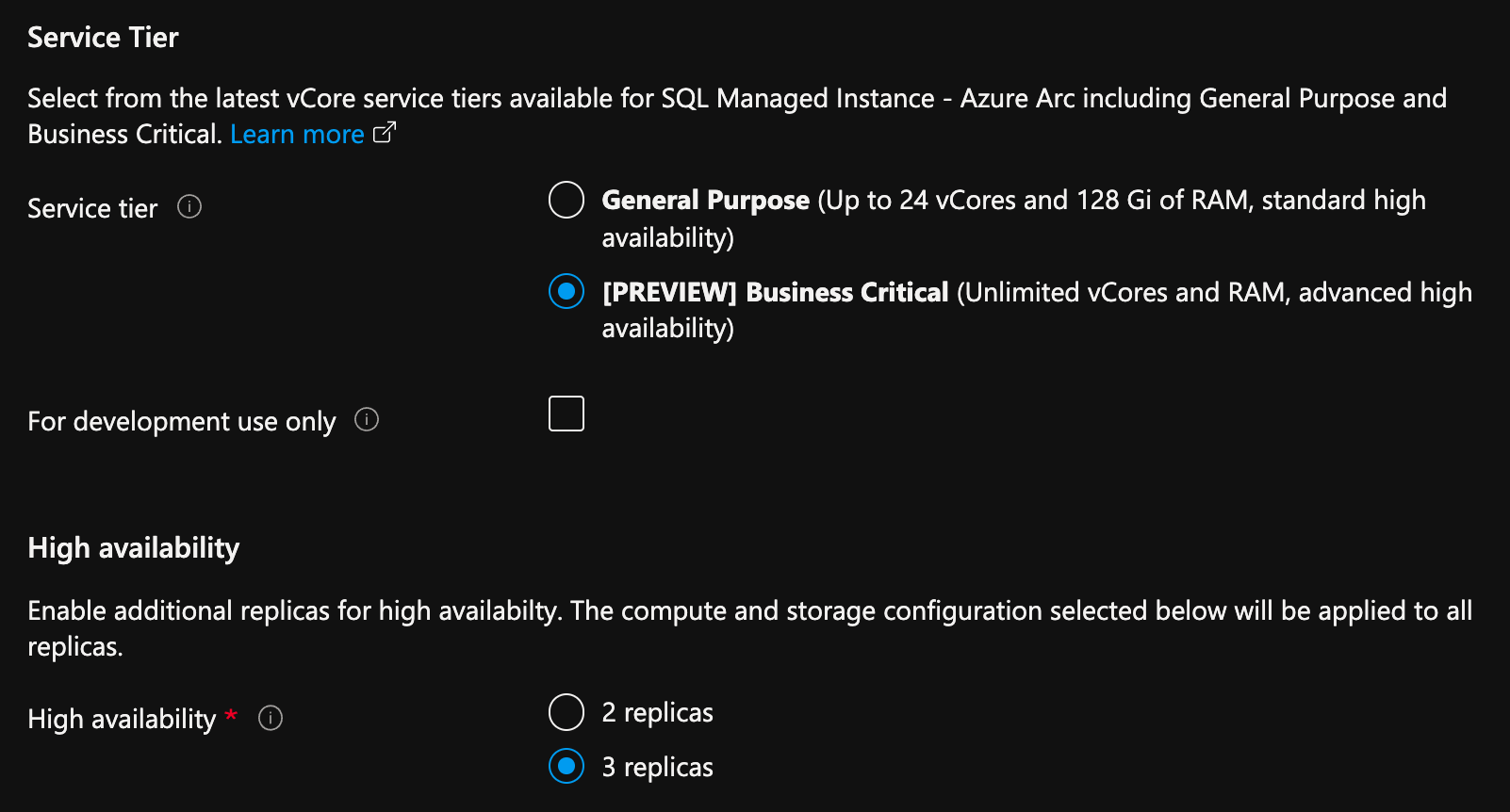
В портал Azure на странице создания Управляемый экземпляр SQL, включенной на странице Azure Arc:
- Выберите Настроить вычисления и хранилище в разделе "Вычисления и хранилище". На портале откроется вкладка дополнительных параметров.
- В разделе "Уровень обслуживания" выберите Критически важный для бизнеса.
- Если необходимо, установите флажок "Только для разработки".
- В разделе "Высокий уровень доступности" выберите 2 реплики или 3 реплики.
Развертывание с несколькими реплика с помощью Azure CLI
При развертывании Управляемый экземпляр SQL с помощью Azure Arc на уровне служб критически важный для бизнеса развертывание создает несколько реплика. Настройка и конфигурация автономных групп доступности для этих экземпляров выполняется автоматически во время подготовки.
Например, следующая команда создает управляемый экземпляр с 3 репликами.
Режим непрямого подключения:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Пример:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Режим прямого подключения:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Пример:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
По умолчанию все реплики настраиваются в синхронном режиме. Это означает, что все обновления основного экземпляра синхронно реплика по каждому из вторичных экземпляров.
Просмотр и мониторинг состояния высокой доступности
После завершения развертывания подключитесь к первичной конечной точке из SQL Server Management Studio.
Проверьте и получите конечную точку первичной реплики и подключитесь к ней из SQL Server Management Studio.
Например, если экземпляр SQL был развернут с использованием service-type=loadbalancer, выполните следующую команду, чтобы получить конечную точку для подключения:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
or
kubectl get sqlmi -A
Получение первичных и вторичных конечных точек, а также состояния группы доступности
kubectl describe sqlmi Используйте команды для az sql mi-arc show просмотра основных и вторичных конечных точек и состояния высокой доступности.
Пример:
kubectl describe sqlmi sqldemo -n my-namespace
or
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Пример результата:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
Вы можете подключиться к основной конечной точке с помощью SQL Server Management Studio и проверить динамические административные представления следующим образом:
SELECT * FROM sys.dm_hadr_availability_replica_states
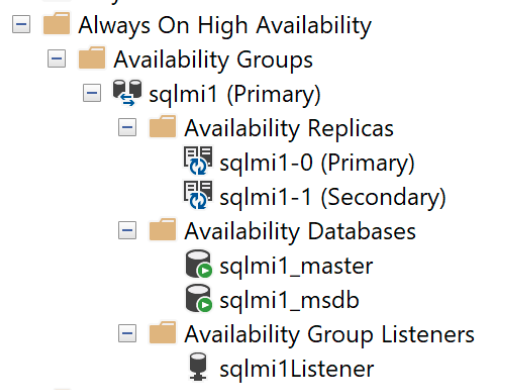
И автономная панель мониторинга доступности:
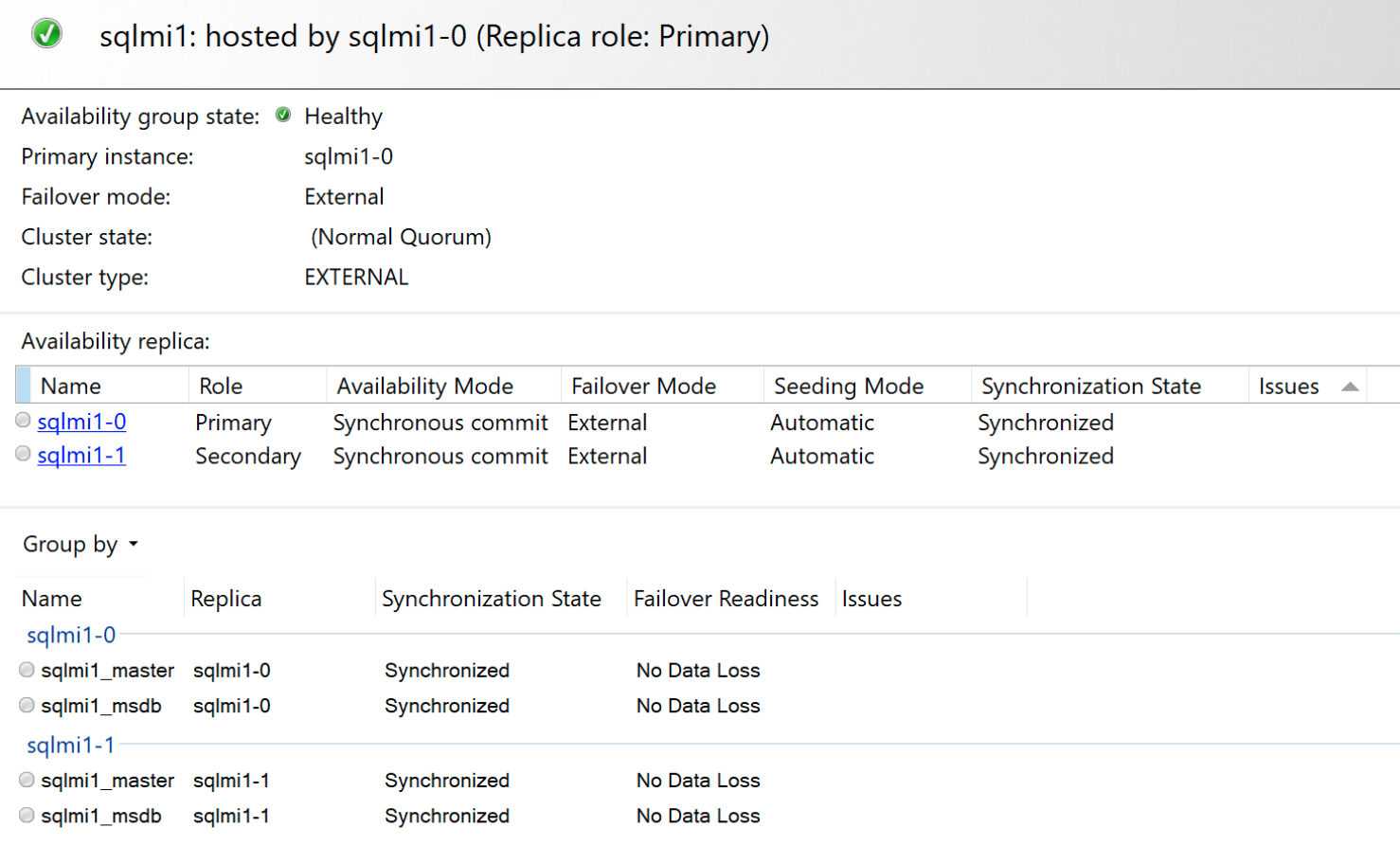
Сценарии отработки отказа
В отличие от групп доступности Always On в SQL Server, автономная группа доступности представляет собой управляемое решение по обеспечению высокого уровня доступности. Поэтому она реализует ограниченные режимы отработки отказа по сравнению с типовыми режимами, представленными в группах доступности Always On в SQL Server.
Управляемые экземпляры SQL с уровнем обслуживания "Критически важный для бизнеса" развертываются в конфигурации с двумя репликами или тремя репликами. Последствия сбоев и последующей возможности восстановления отличаются при каждой конфигурации. Три экземпляра реплика обеспечивают более высокий уровень доступности и восстановления, чем два реплика экземпляра.
В конфигурации с двумя репликами, если оба узла находятся в состоянии SYNCHRONIZED, первичная становится недоступна, а вторичная повышается до уровня первичной. Когда не удалось реплика становится доступным, он обновляется со всеми ожидающих изменений. При возникновении проблем с подключением между репликами первичная реплика не будет фиксировать никакие транзакции, поскольку сообщение об успешном выполнении возвращается в первичную реплику только в том случае, если каждая транзакция зафиксирована в обеих репликах.
В конфигурации с тремя репликами сообщение об успешном выполнении возвращается в приложение только в том случае, если транзакция была зафиксирована по крайней мере в двух из трех реплик. В случае отказа одна из вторичных реплик автоматически повышается до уровня первичной, а Kubernetes пытается восстановить отказавшую реплику. Когда реплика становится доступным, он автоматически присоединяется к автономной группе доступности и ожидается синхронизация изменений. Если между реплика и более 2 реплика возникают проблемы с подключением, основной реплика не зафиксирует никаких транзакций.
Примечание.
Чтобы снизить риск потери данных до почти нулевого уровня, рекомендуется разворачивать Управляемый экземпляр SQL с уровнем обслуживания "Критически важный для бизнеса" в конфигурации с тремя, а не двумя репликами.
Чтобы выполнить отработку отказа из первичной реплики в одну из вторичных в рамках запланированного события, выполните следующую команду:
При подключении к первичной реплике можно использовать следующий запрос T-SQL для отработки отказа экземпляра SQL в одну из вторичных реплик:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
При подключении к вторичной реплике можно использовать следующий запрос T-SQL для повышения требуемой вторичной реплики до уровня первичной.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Предпочтительная первичная реплика
Можно также задать конкретную реплику в качестве первичной с помощью CLI зоны доступности следующим образом:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Пример:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Примечание.
Kubernetes попытается задать предпочтительную реплику, однако успешное выполнение это операции не гарантируется.
Восстановление базы данных в экземпляр с несколькими репликами
Для восстановления базы данных в группу доступности требуются дополнительные шаги. В следующих шагах показано, как восстановить базу данных в управляемый экземпляр и добавить в группу доступности.
Предоставьте внешнюю конечную точку первичного экземпляра путем создания новой службы Kubernetes.
Определите объект pod, в котором размещается первичная реплика. Подключитесь к управляемому экземпляру и выполните следующую команду:
SELECT @@SERVERNAMEЭтот запрос возвращает объект pod, в котором размещена первичная реплика.
Создайте службу Kubernetes в основном экземпляре, выполнив следующую команду, если кластер Kubernetes использует
NodePortслужбы. Замените<podName>именем сервера, возвращенного на предыдущем шаге, а<serviceName>— предпочтительным именем для созданной службы Kubernetes.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortДля службы LoadBalancer выполните ту же команду, за исключением того, что созданная служба имеет тип
LoadBalancer. Например:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerНиже приведен пример выполнения этой команды для службы Azure Kubernetes, когда первичная реплика размещается в модуле pod
sql2-0.kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerПолучите IP-адрес созданной службы Kubernetes:
kubectl get services -n <namespaceName>Восстановите базу данных в конечной точке первичного экземпляра.
Добавьте файл резервной копии базы данных в контейнер первичного экземпляра.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Пример
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcВосстановите файл резервной копии базы данных, выполнив приведенную ниже команду.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOПример
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOДобавьте базу данных в группу доступности.
Чтобы добавить базу данных в группу доступности, необходимо запустить ее в режиме полного восстановления и создать резервную копию журнала. Выполните приведенные ниже инструкции TSQL, чтобы добавить восстановленную базу данных в группу доступности.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>В следующем примере добавляется база данных с именем
WideWorldImporters, которая была восстановлена в экземпляре.ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Важно!
Рекомендуется удалить созданную выше службу Kubernetes с помощью следующей команды:
kubectl delete svc sql2-0-p -n arc
Ограничения
Управляемый экземпляр SQL в группах доступности Azure Arc имеет те же ограничения, что и группы доступности кластера больших данных. Дополнительные сведения см. в разделе Развертывание Кластера больших данных SQL Server с высокой доступностью.
Связанный контент
Дополнительные сведения о функциях и возможностях Управляемый экземпляр SQL, включенных Azure Arc