Руководство. Запрос контейнера Docker SQL Server Linux в виртуальной сети из записной книжки Azure Databricks
В этом руководстве описано, как интегрировать Azure Databricks с контейнером Docker SQL Server Linux в виртуальной сети.
Из этого руководства вы узнаете, как выполнять следующие действия:
- Развертывание рабочей области Azure Databricks в виртуальной сети
- Установка виртуальной машины Linux в общедоступной сети
- Установка Docker
- Установка контейнера Docker Microsoft SQL Server на Linux
- Запрос SQL Server с помощью JDBC из записной книжки Databricks
Предварительные требования
Установите Ubuntu для Windows.
Скачайте SQL Server Management Studio.
Создание виртуальной машины Linux
В портал Azure щелкните значок Виртуальные машины. Затем выберите + Добавить.
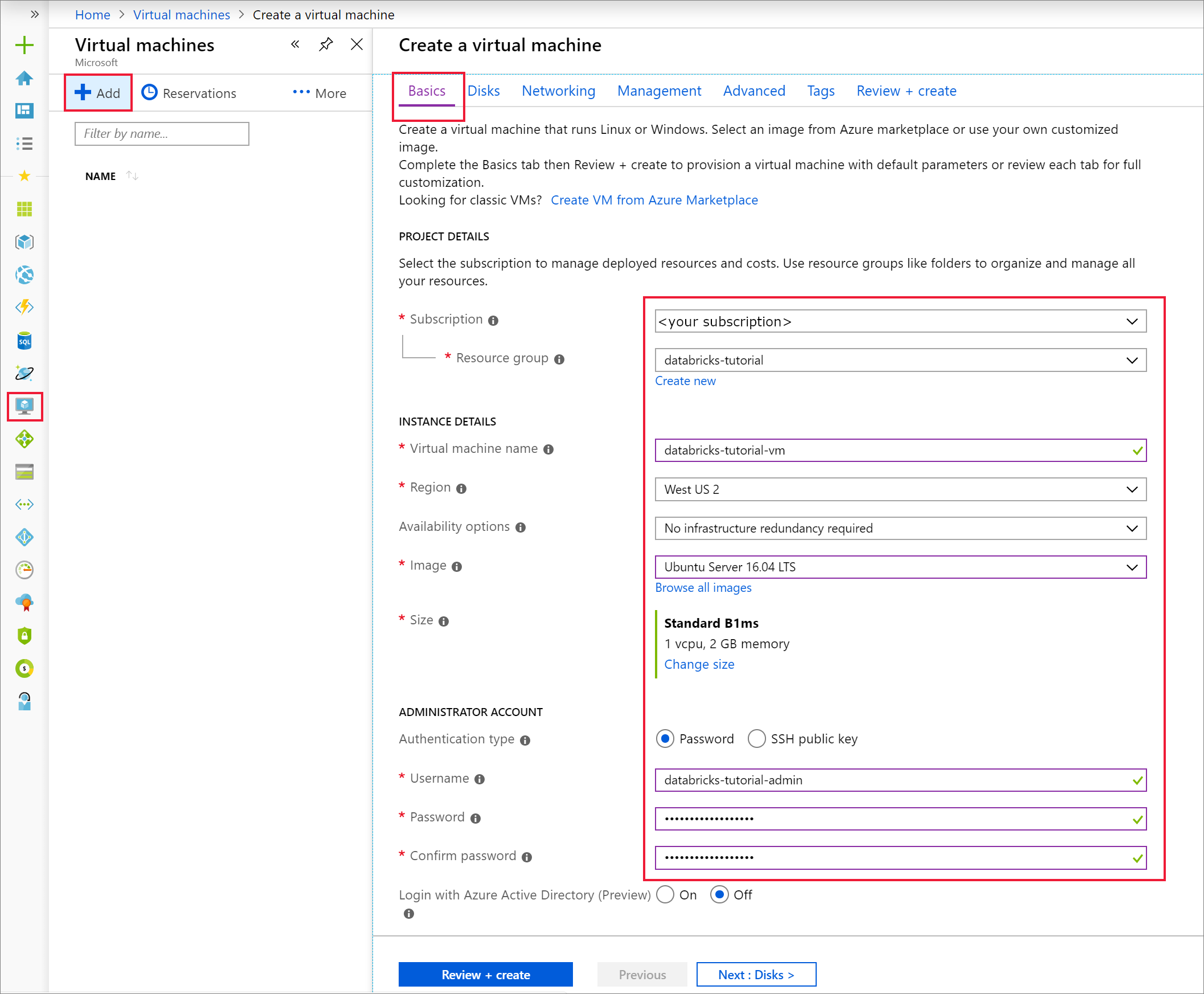
На вкладке Основные сведения выберите Ubuntu Server 18.04 LTS и измените размер виртуальной машины на B2s. Выберите имя пользователя и пароль администратора.
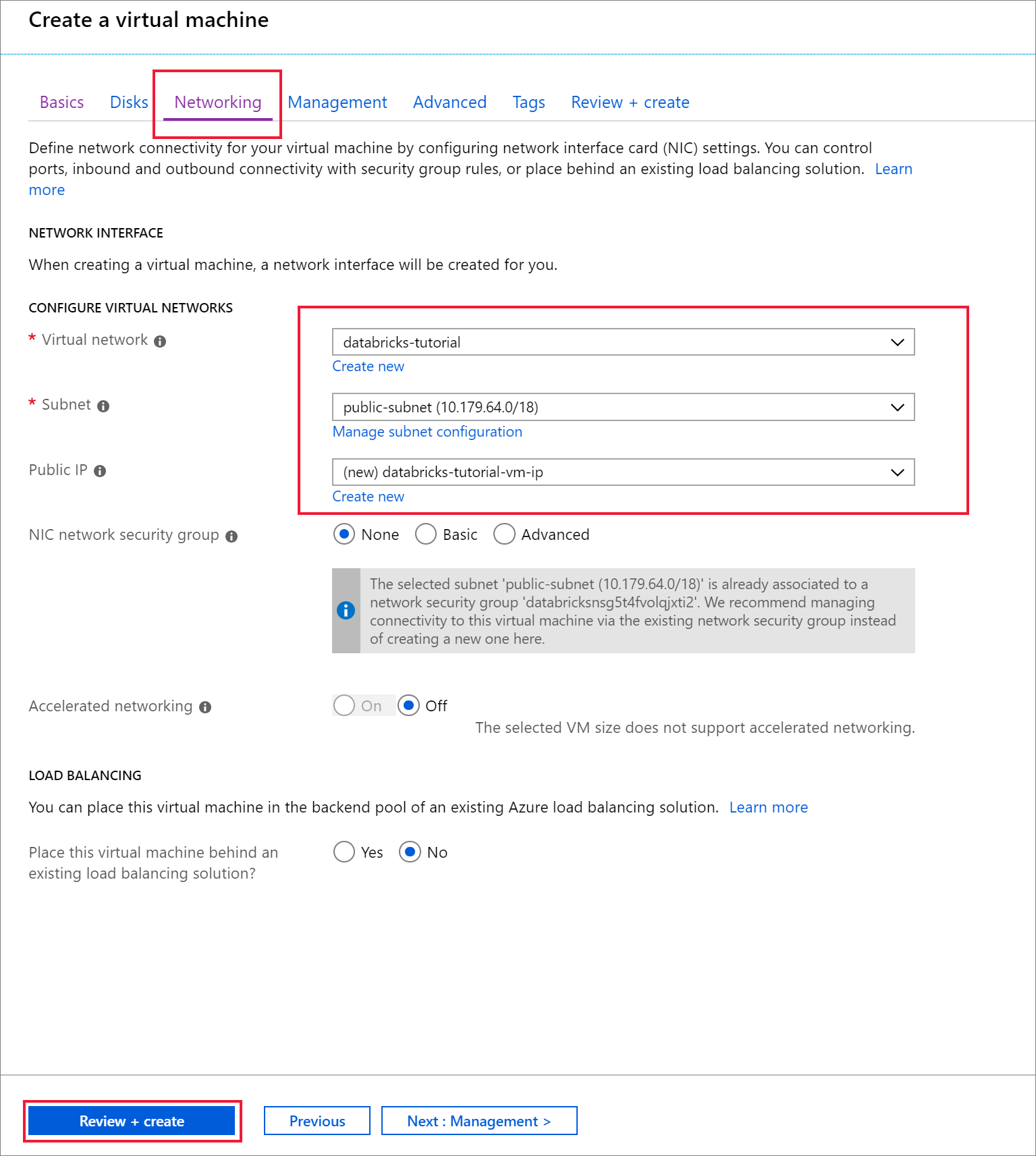
Перейдите на вкладку Сеть . Выберите виртуальную сеть и общедоступную подсеть, в которую входит кластер Azure Databricks. Выберите Просмотр и создание, а затем Создать , чтобы развернуть виртуальную машину.
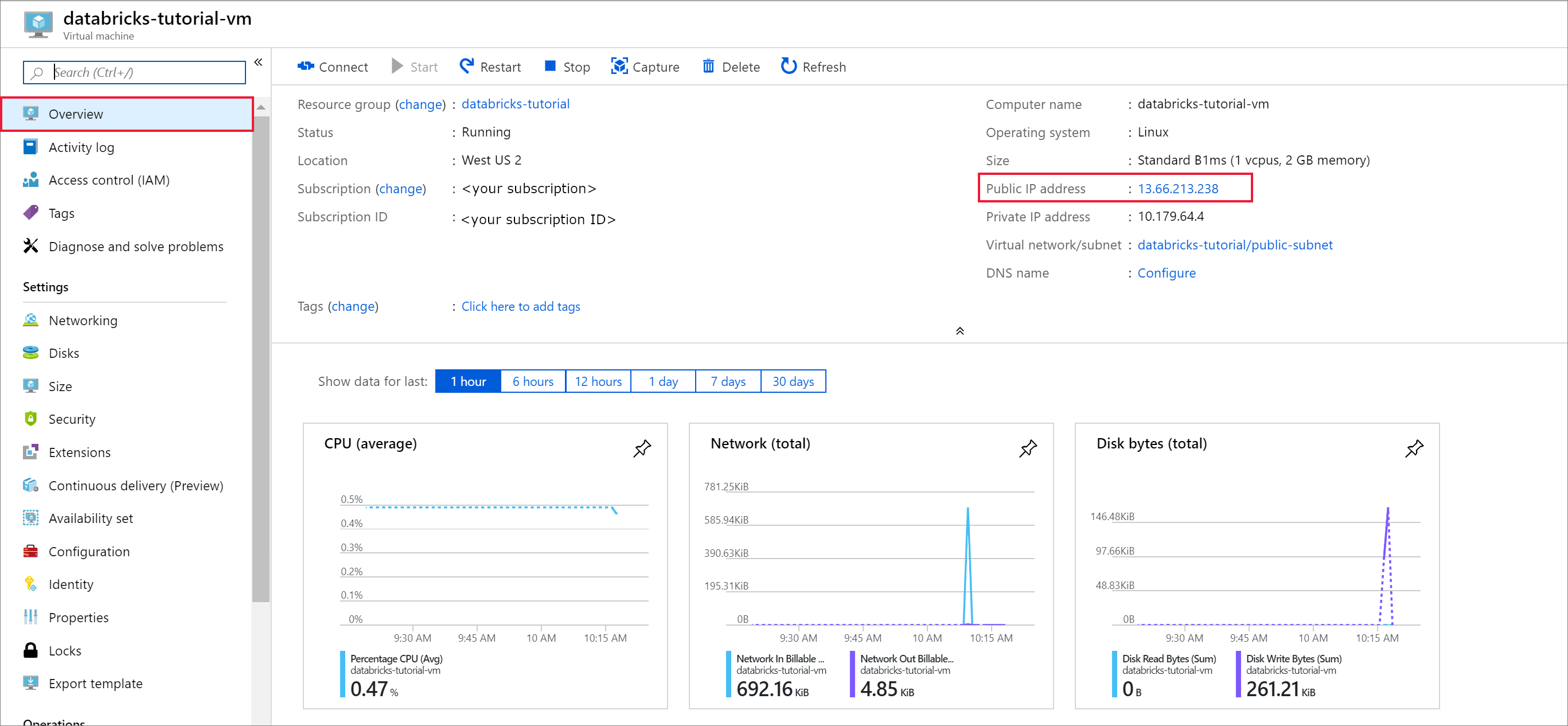
После завершения развертывания перейдите к виртуальной машине. Обратите внимание на общедоступный IP-адрес и виртуальную сеть или подсеть в разделе Обзор. Выберите общедоступный IP-адрес.
Измените значение параметра Назначение на Статическое и введите метку DNS-имени. Выберите Сохранить и перезапустите виртуальную машину.
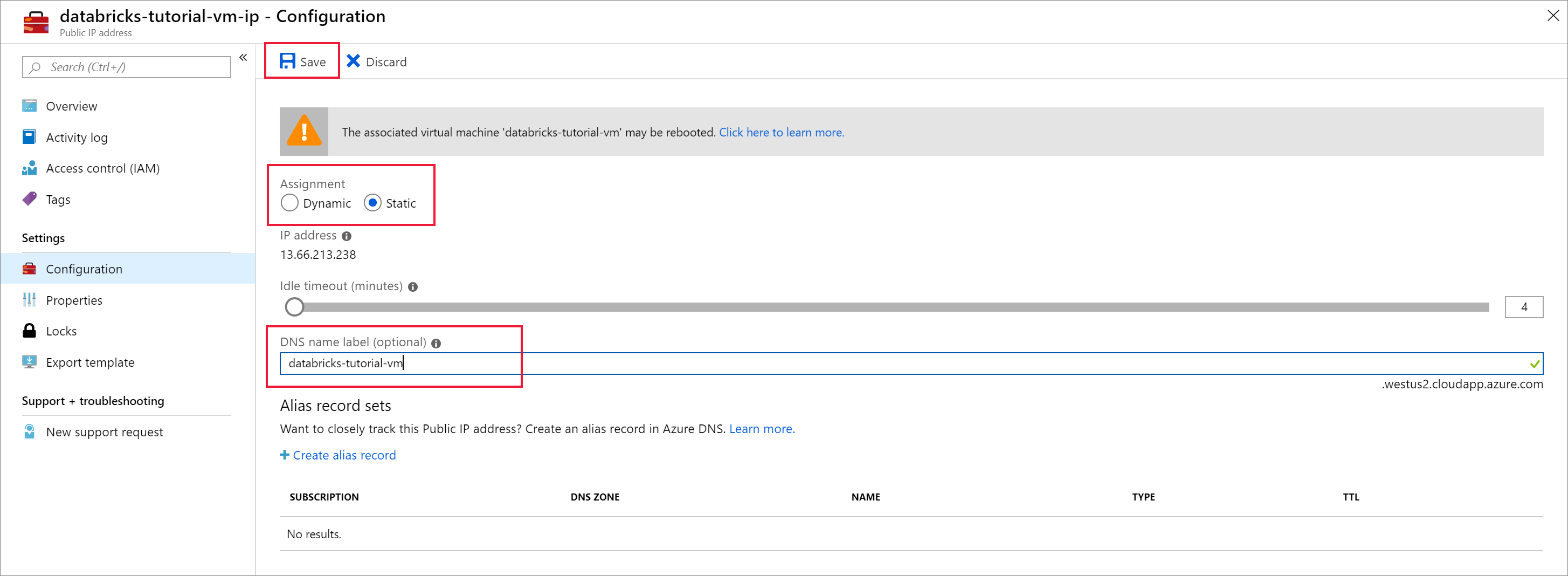
Перейдите на вкладку Сеть в разделе Параметры. Обратите внимание, что группа безопасности сети, созданная во время развертывания Azure Databricks, связана с виртуальной машиной. Выберите Добавить правило входящего порта.
Добавьте правило для открытия порта 22 для SSH. Используйте следующие параметры:
Параметр Предлагаемое значение Описание Источник IP-адреса IP-адреса указывает, что входящий трафик с определенного исходного IP-адреса будет разрешен или запрещен этим правилом. Исходные IP-адреса <общедоступный IP-адрес> Введите общедоступный IP-адрес. Вы можете найти свой общедоступный IP-адрес, посетив bing.com и выполнив поиск по запросу "мой IP-адрес". Диапазоны исходных портов * Разрешить трафик из любого порта. Назначения IP-адреса IP-адреса указывает, что исходящий трафик для определенного исходного IP-адреса будет разрешен или запрещен этим правилом. IP-адреса назначения <общедоступный IP-адрес виртуальной машины> Введите общедоступный IP-адрес виртуальной машины. Его можно найти на странице Обзор виртуальной машины. Диапазоны портов назначения 22 Откройте порт 22 для SSH. Приоритет 290 Присвойте правилу приоритет. Имя ssh-databricks-tutorial-vm Присвойте правилу имя. 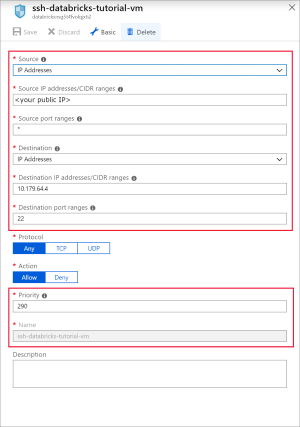
Добавьте правило для открытия порта 1433 для SQL со следующими параметрами:
Параметр Предлагаемое значение Описание Источник Любой Источник указывает, что входящий трафик с определенного исходного IP-адреса будет разрешен или запрещен этим правилом. Диапазоны исходных портов * Разрешить трафик из любого порта. Назначения IP-адреса IP-адреса указывает, что исходящий трафик для определенного исходного IP-адреса будет разрешен или запрещен этим правилом. IP-адреса назначения <общедоступный IP-адрес виртуальной машины> Введите общедоступный IP-адрес виртуальной машины. Его можно найти на странице Обзор виртуальной машины. Диапазоны портов назначения 1433 Откройте порт 22 для SQL Server. Приоритет 300 Присвойте правилу приоритет. Имя sql-databricks-tutorial-vm Присвойте правилу имя. 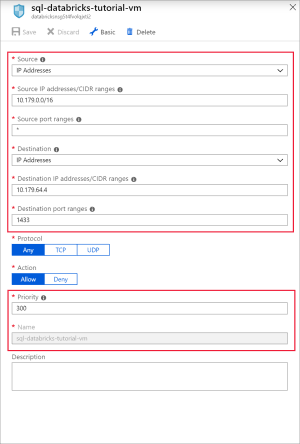
Выполнение SQL Server в контейнере Docker
Откройте Ubuntu для Windows или любое другое средство, позволяющее перейти по протоколу SSH на виртуальную машину. Перейдите к виртуальной машине в портал Azure и выберите Подключиться, чтобы получить команду SSH, необходимую для подключения.
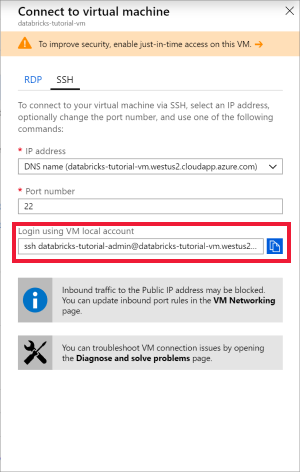
Введите команду в терминале Ubuntu и введите пароль администратора, созданный при настройке виртуальной машины.
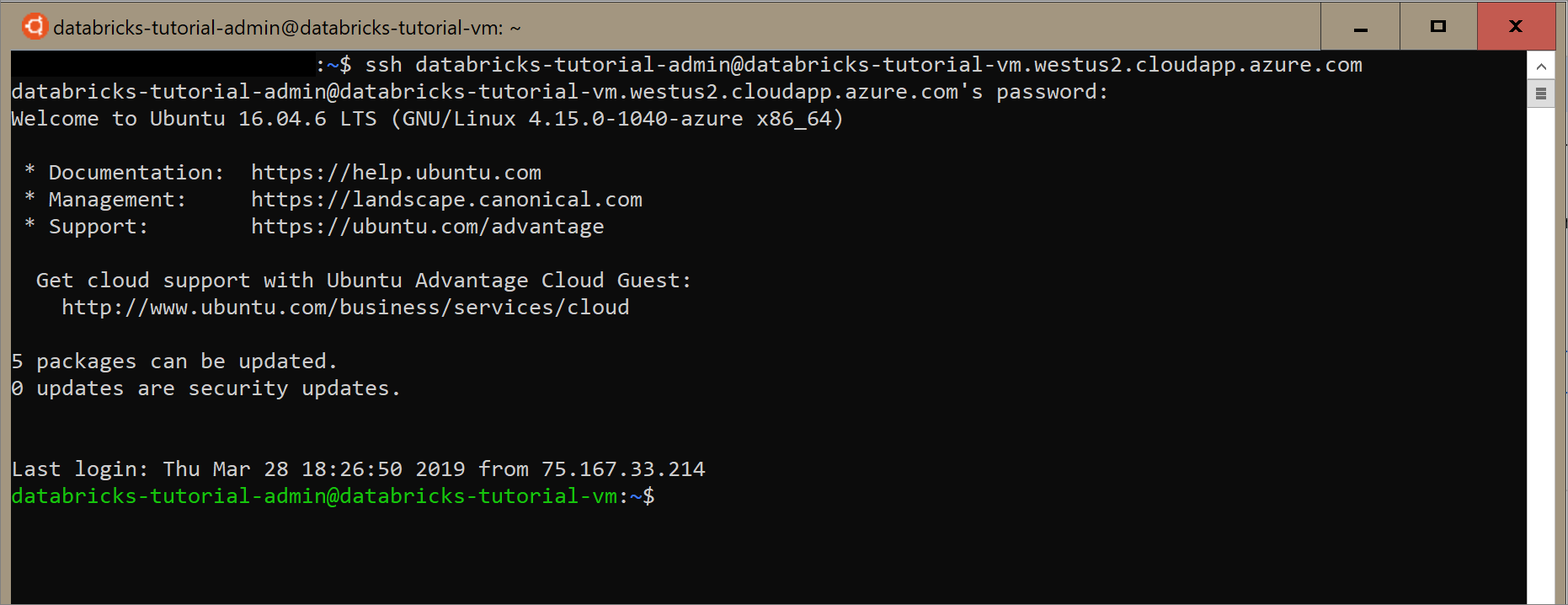
Используйте следующую команду, чтобы установить Docker на виртуальной машине.
sudo apt-get install docker.ioПроверьте установку Docker с помощью следующей команды:
sudo docker --versionУстановите образ.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latestПроверьте изображения.
sudo docker imagesЗапустите контейнер из образа.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latestУбедитесь, что контейнер запущен.
sudo docker ps -a
Создание базы данных SQL
Откройте SQL Server Management Studio и подключитесь к серверу, используя имя сервера и проверку подлинности SQL. Имя пользователя для входа — SA , а пароль — это пароль, заданный в команде Docker. Пароль в примере команды —
Password1234.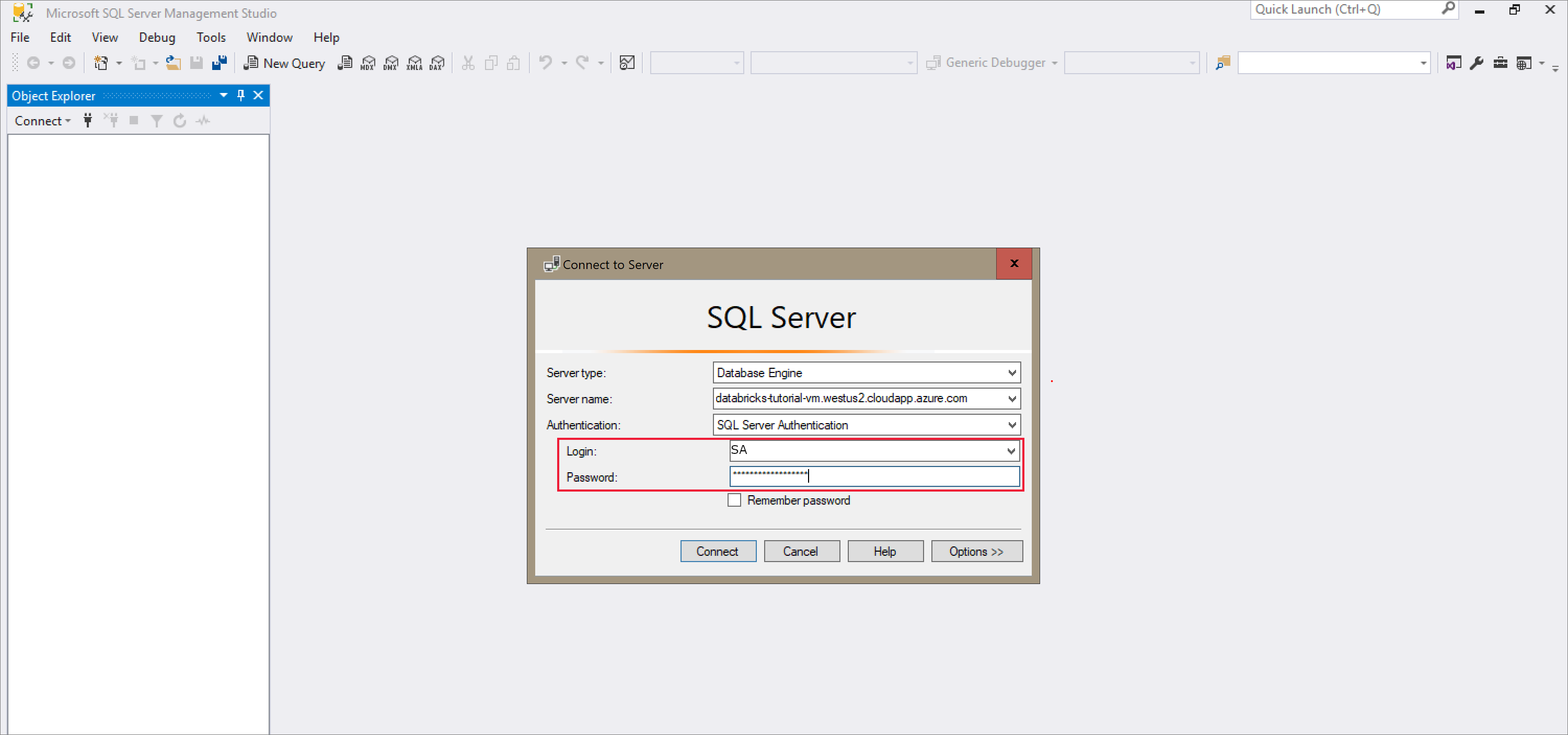
После успешного подключения выберите Создать запрос и введите следующий фрагмент кода, чтобы создать базу данных, таблицу и вставить некоторые записи в таблицу.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO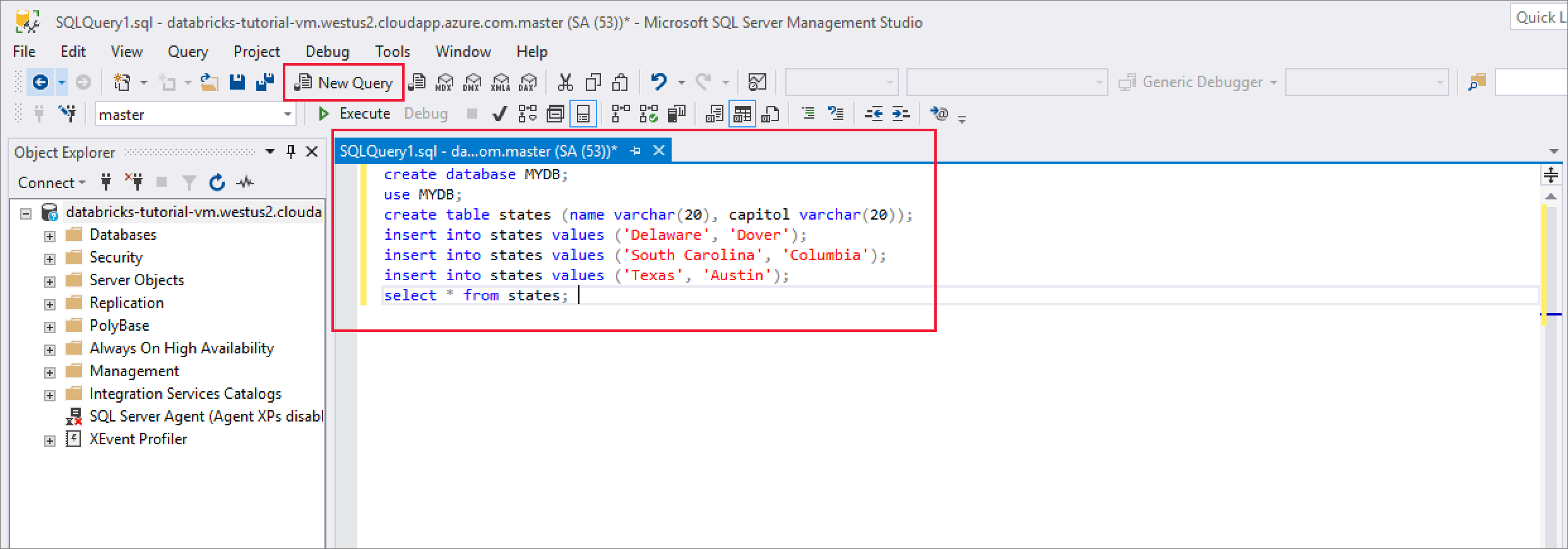
Запрос SQL Server из Azure Databricks
Перейдите в рабочую область Azure Databricks и убедитесь, что вы создали кластер в рамках предварительных требований. Затем выберите Создать записную книжку. Присвойте записной книжке имя, выберите Python в качестве языка и выберите созданный кластер.
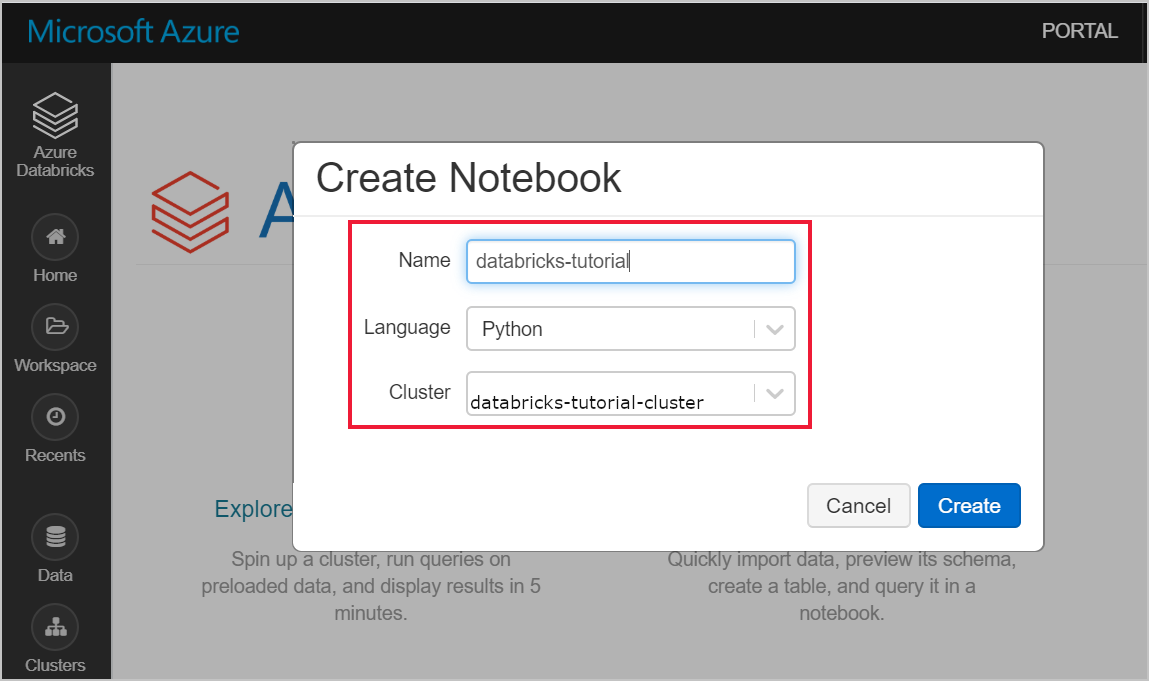
Используйте следующую команду, чтобы выполнить связь с внутренним IP-адресом виртуальной машины SQL Server. Эта связь должна быть успешной. В противном случае убедитесь, что контейнер запущен, и проверьте конфигурацию группы безопасности сети (NSG).
%sh ping 10.179.64.4Для проверки также можно использовать команду nslookup.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comПосле успешной проверки SQL Server можно запросить базу данных и таблицы. Выполните следующий код Python:
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
Очистка ресурсов
Если она больше не нужна, удалите группу ресурсов, рабочую область Azure Databricks и все связанные ресурсы. Удаление задания позволяет избежать ненужных выставления счетов. Если вы планируете использовать рабочую область Azure Databricks в будущем, вы можете остановить кластер и перезапустить его позже. Если вы не собираетесь продолжать использовать эту рабочую область Azure Databricks, удалите все ресурсы, созданные в этом руководстве, выполнив следующие действия.
В меню слева в портал Azure щелкните Группы ресурсов, а затем выберите имя созданной группы ресурсов.
На странице группы ресурсов выберите Удалить, введите имя удаляемого ресурса в текстовом поле, а затем снова нажмите кнопку Удалить .
Дальнейшие действия
Перейдите к следующей статье, чтобы узнать, как извлекать, преобразовывать и загружать данные с помощью Azure Databricks.