Мониторинг виртуальных машин Azure с помощью Azure Monitor: рабочие нагрузки: оповещения
Эта статья является частью руководства по мониторингу виртуальных машин и их рабочих нагрузок в Azure Monitor. Оповещения в Azure Monitor позволяют заблаговременно получать уведомления об интересных данных и закономерностях в данных мониторинга. Для виртуальных машин нет предварительно настроенных правил генерации оповещений, но вы можете создать собственные данные, собранные агентом Azure Monitor. В этой статье представлены понятия оповещения, относящиеся к виртуальным машинам и общим правилам генерации оповещений, используемым другими клиентами Azure Monitor.
В этом сценарии описывается, как реализовать полный мониторинг среды Azure и гибридной виртуальной машины:
Чтобы приступить к наблюдению за первой виртуальной машиной Azure, см. статью Мониторинг виртуальных машин Azure.
Чтобы быстро включить рекомендуемый набор оповещений, см . статью "Включить рекомендуемые правила генерации оповещений" для виртуальной машины Azure.
Внимание
Большинство правил генерации оповещений имеют стоимость, зависящую от типа правила, количества измерений, которые оно включает, и частоты его выполнения. Прежде чем создавать правила генерации оповещений, ознакомьтесь с разделом "Правила генерации оповещений" в разделе "Правила генерации оповещений" в ценах на Azure Monitor.
сбор данных
Правила генерации оповещений проверяют данные, уже собранные в Azure Monitor. Перед созданием правила генерации оповещений необходимо убедиться, что данные собираются для определенного сценария. См. статью "Мониторинг виртуальных машин с помощью Azure Monitor: сбор данных для настройки сбора данных для различных сценариев, включая все правила генерации оповещений в этой статье".
Рекомендуемые правила генерации оповещений
Azure Monitor предоставляет набор рекомендуемых правил генерации оповещений, которые можно быстро включить для любой виртуальной машины Azure. Эти правила являются отличной отправной точкой для базового мониторинга. Но только они не будут предоставлять достаточно оповещений для большинства корпоративных реализаций по следующим причинам:
- Рекомендуемые оповещения применяются только к виртуальным машинам Azure, а не к гибридным машинам.
- Рекомендуемые оповещения включают только метрики узлов, а не гостевые метрики или журналы. Эти метрики полезны для мониторинга работоспособности самого компьютера. Но они обеспечивают минимальную видимость рабочих нагрузок и приложений, работающих на компьютере.
- Рекомендуемые оповещения связаны с отдельными компьютерами, которые создают чрезмерное количество правил генерации оповещений. Вместо использования этого метода для каждого компьютера см . правила масштабирования оповещений для стратегий использования минимального количества правил генерации оповещений для нескольких компьютеров.
Типы оповещений
Наиболее распространенными типами правил генерации оповещений в Azure Monitor являются оповещения метрик и оповещения поиска по журналам. Тип правила генерации оповещений, создаваемого для конкретного сценария, зависит от того, где находятся данные, которые вы оповещаете.
У вас могут быть случаи, когда данные для определенного сценария оповещения доступны как в метриках, так и в журналах. В этом случае необходимо определить, какой тип правила следует использовать. Вы также можете проявить гибкость при сборе определенных видов данных и принять решение о методе сбора данных на основе решения о типе правила генерации оповещений.
Оповещения метрики
Часто используется для оповещений метрик:
- Оповещение, когда определенная метрика превышает пороговое значение. Примером может служить высокая нагрузка на процессор компьютера.
Источники данных для оповещений метрик:
- Метрики узлов для виртуальных машин Azure, которые собираются автоматически
- Метрики, собранные агентом Azure Monitor из гостевой операционной системы
Оповещения поиска по журналам
Распространенные способы использования оповещений поиска по журналам:
- Оповещение при обнаружении определенного события или шаблона событий из журнала событий Windows или системного журнала. Эти правила генерации оповещений обычно измеряют строки таблицы, возвращаемые из запроса.
- Оповещение на основе вычисления числовых данных на нескольких компьютерах. Эти правила генерации оповещений обычно измеряют вычисление числового столбца в результатах запроса.
Источники данных для оповещений поиска по журналам:
- Все данные, собранные в рабочей области Log Analytics
Масштабирование правил генерации оповещений
Так как у вас может быть много виртуальных машин, требующих одного и того же мониторинга, вам не нужно создавать отдельные правила генерации оповещений для каждого из них. Кроме того, необходимо убедиться, что существуют различные стратегии ограничения количества правил генерации оповещений, которым необходимо управлять в зависимости от типа правила. Каждая из этих стратегий зависит от понимания целевого ресурса правила генерации оповещений.
Правила генерации оповещений метрик
Виртуальные машины поддерживают несколько правил генерации оповещений метрик ресурсов, как описано в разделе "Мониторинг нескольких ресурсов". Эта возможность позволяет создать одно правило генерации оповещений метрик, которое применяется ко всем виртуальным машинам в группе ресурсов или подписке в одном регионе.
Начните с рекомендуемых оповещений и создайте соответствующее правило для каждого с помощью подписки или группы ресурсов в качестве целевого ресурса. При наличии компьютеров в нескольких регионах необходимо создать повторяющиеся правила для каждого региона.
При определении требований для дополнительных правил генерации оповещений метрик следуйте этой же стратегии, используя подписку или группу ресурсов в качестве целевого ресурса:
- Свести к минимуму количество правил генерации оповещений, которым необходимо управлять.
- Убедитесь, что они автоматически применяются к любым новым компьютерам.
Правила генерации оповещений поиска по журналам
Если задать целевой ресурс правила генерации оповещений поиска по журналам для определенного компьютера, запросы ограничиваются данными, связанными с этим компьютером, что дает для него отдельные оповещения. Для этого требуется отдельное правило генерации оповещений для каждого компьютера.
Если целевой ресурс правила генерации оповещений поиска по журналам установлен в рабочей области Log Analytics, у вас есть доступ ко всем данным в этой рабочей области. По этой причине вы можете оповещать данные со всех компьютеров в рабочей группе одним правилом. Это позволяет создавать одно оповещение для всех компьютеров. Затем можно использовать измерения для создания отдельного оповещения для каждого компьютера.
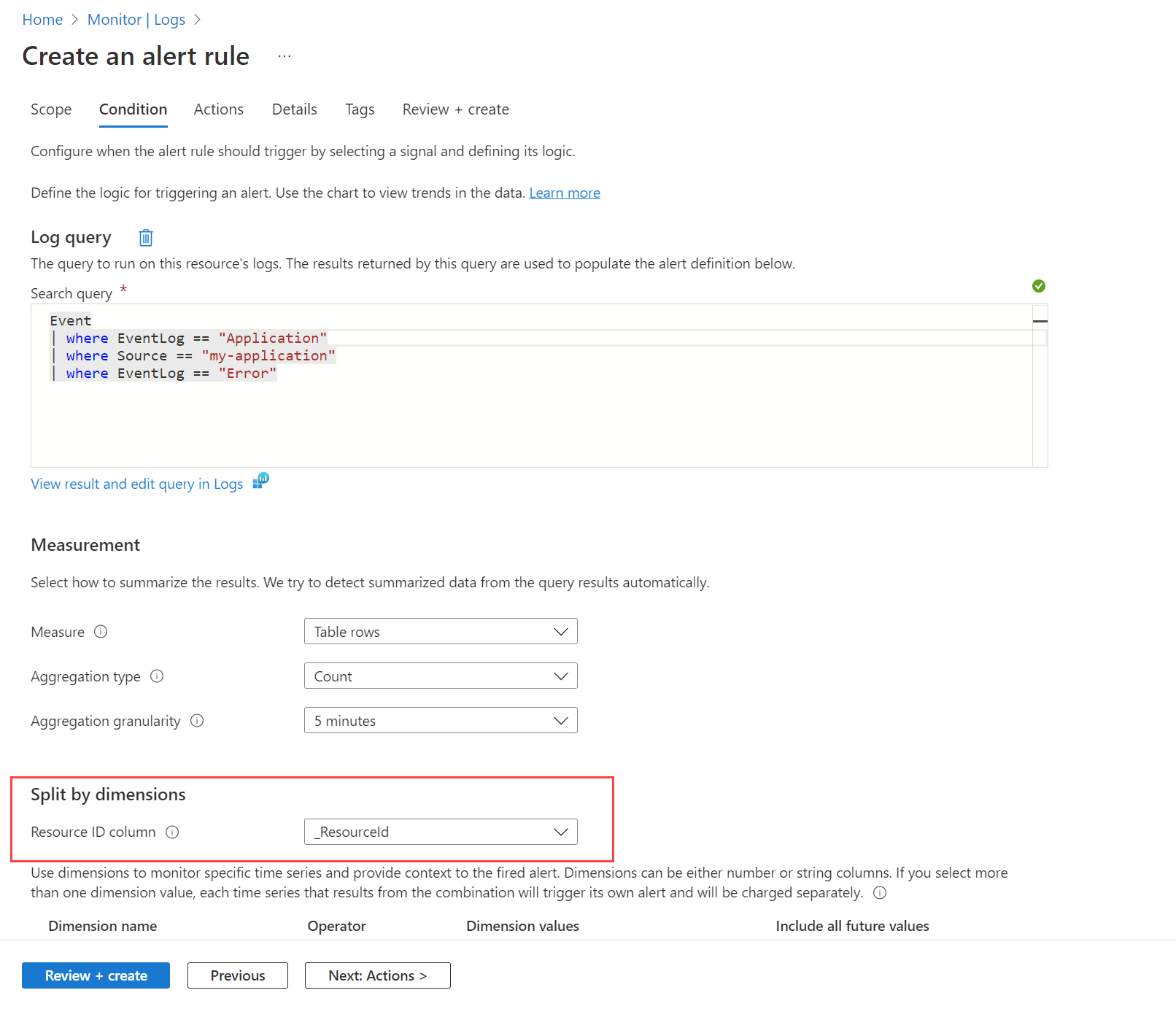
Например, при создании события ошибки в журнале событий Windows на любом компьютере может потребоваться оповещение. Сначала необходимо создать правило сбора данных, как описано в разделе "Сбор событий и счетчиков производительности" с помощью агента Azure Monitor для отправки этих событий Event в таблицу в рабочей области Log Analytics. Затем вы создадите правило генерации оповещений, которое запрашивает эту таблицу с помощью рабочей области в качестве целевого ресурса и условия, показанного на следующем рисунке.
Запрос возвращает запись для любых сообщений об ошибках на любом компьютере. Используйте параметр Split by dimensions и укажите _ResourceId, чтобы указать правилу создать оповещение для каждого компьютера, если в результатах возвращаются несколько компьютеров.
Измерения
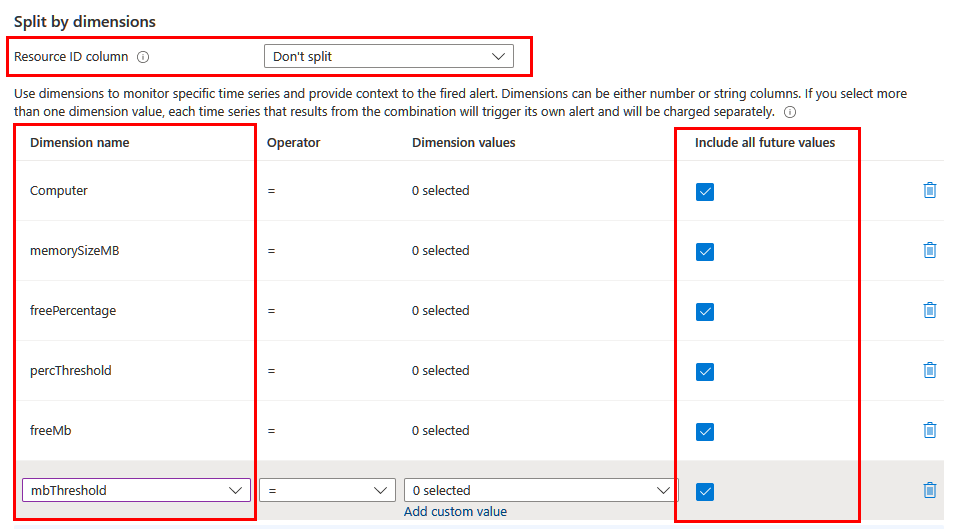
В зависимости от информации, которую вы хотите включить в оповещение, может потребоваться разделить с помощью различных измерений. В этом случае убедитесь, что необходимые измерения проецируются в запросе с помощью оператора проекта или расширения . Задайте для поля столбца идентификатора ресурса не разделять и включить все значимые измерения в список. Убедитесь, что выбрано включение всех будущих значений , чтобы любое значение, возвращаемое из запроса, было включено.
Динамические пороги
Еще одним преимуществом использования правил генерации оповещений поиска по журналам является возможность включения сложной логики в запрос для определения порогового значения. Можно жестко закодировать пороговое значение, применить его ко всем ресурсам или динамически вычислить его на основе определенного поля или вычисляемого значения. Пороговое значение применяется только к ресурсам в соответствии с конкретными условиями. Например, вы можете создать оповещение на основе доступной памяти, но только для компьютеров с определенным объемом общей памяти.
Стандартные правила генерации оповещений
В следующем разделе перечислены стандартные правила оповещения для виртуальных машин в Azure Monitor. Сведения о оповещениях метрик и оповещениях поиска по журналам предоставляются для каждого из них. Инструкции по использованию типа оповещений см. в разделе "Типы оповещений". Если вы не знакомы с процедурой создания правил генерации оповещений в Azure Monitor, ознакомьтесь с соответствующими инструкциями.
Примечание.
Сведения об оповещениях поиска по журналам, предоставляемых здесь, используют данные, собранные с помощью Аналитика виртуальной машины, которая предоставляет набор общих счетчиков производительности для клиентской операционной системы. Это имя не зависит от типа операционной системы.
Доступность компьютера
Одним из наиболее распространенных требований к мониторингу виртуальной машины является создание оповещения при остановке работы. Лучший способ — создать правило генерации оповещений метрик в Azure Monitor с помощью метрики доступности виртуальной машины, которая в настоящее время находится в общедоступной предварительной версии. Пошаговое руководство по этой метрике см. в статье "Создание правила генерации оповещений о доступности для виртуальной машины Azure".
Правило генерации оповещений ограничено одним сигналом журнала действий. Поэтому для каждого условия необходимо создать одно правило генерации оповещений. Например, для запуска или остановки виртуальной машины требуется два правила генерации оповещений. Однако для оповещения при перезапуске виртуальной машины требуется только одно правило генерации оповещений.
Как описано в правилах масштабирования оповещений, создайте правило генерации оповещений доступности с помощью подписки или группы ресурсов в качестве целевого ресурса. Правило применяется к нескольким виртуальным машинам, включая новые машины, создаваемые после правила генерации оповещений.
Пульс агента
Пульс агента немного отличается от недоступного оповещения компьютера, так как он использует агент Azure Monitor для отправки пульса. Пульс агента может предупредить вас, если компьютер запущен, но агент не отвечает.
Правила генерации оповещений метрик
В каждой рабочей области Log Analytics есть метрика пакета пульса Heartbeat. Каждая виртуальная машина, присоединенная к этой рабочей области, каждую минуту отправляет значение метрики пакета пульса. Поскольку измерением метрики является компьютер, оповещение может срабатывать, если какой-либо компьютер не отправляет сигнал пульса. Задайте для параметра Тип агрегирования значение Количество, а для параметра Пороговое значение — значение, соответствующее степени детализации оценки.
Правила генерации оповещений поиска по журналам
Оповещения поиска по журналам используют таблицу Heartbeat, которая должна иметь запись пульса каждую минуту от каждого компьютера.
Используйте правило со следующим запросом:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
Оповещения о загрузке ЦП
В этом разделе описываются оповещения ЦП.
Правила генерации оповещений метрик
| Назначение | Metric |
|---|---|
| Хост | Процент ЦП (включен в рекомендуемые оповещения) |
| Гость Windows | \Processor Information(_Total)% Время работы ЦП |
| Гость Linux | cpu/usage_active |
Правила генерации оповещений поиска по журналам
Загрузка ЦП
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Оповещения и загрузке памяти
В этом разделе описываются оповещения о памяти.
Правила генерации оповещений метрик
| Назначение | Metric |
|---|---|
| Хост | Доступные байты памяти (предварительная версия) (включены в рекомендуемые оповещения) |
| Гость Windows | \Memory% Использование выделенной памяти (в байтах) \Память\доступные байты |
| Гость Linux | mem/available mem/available_percent |
Правила генерации оповещений поиска по журналам
Доступная память в МБ
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Доступная память в процентах
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Оповещения о загрузке диска
В этом разделе описаны оповещения о диске.
Правила генерации оповещений метрик
| Назначение | Metric |
|---|---|
| Гость Windows | \Logical Disk(_Total)% Свободное место \Logical Disk(_Total)\Свободно мегабайт |
| Гость Linux | disk/free disk/free_percent |
Правила генерации оповещений поиска по журналам
Используемый логический диск — все диски на каждом компьютере
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Используемый логический диск — отдельные диски
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Число операций ввода-вывода логического диска
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Скорость передачи данных логического диска
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Сетевые оповещения
Правила генерации оповещений метрик
| Назначение | Metric |
|---|---|
| Хост | Общее число сетевых подключений (включено в рекомендуемые оповещения) |
| Гость Windows | \Network Interface\Отправленных байтов/с \Logical Disk(_Total)\Свободно мегабайт |
| Гость Linux | disk/free disk/free_percent |
Правила генерации оповещений поиска по журналам
Получено байт сетевых интерфейсов — все интерфейсы
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Получено байт сетевых интерфейсов — отдельные интерфейсы
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Отправлено байт сетевых интерфейсов — все интерфейсы
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Отправлено байт сетевых интерфейсов — отдельные интерфейсы
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
События Windows и Linux
В следующем примере показано создание оповещения при создании определенного события Windows. Для создания отдельного оповещения для каждого компьютера используется правило генерации оповещений при измерении метрик.
Создание правила генерации оповещений для определенного события Windows. В этом примере показано событие в журнале приложений. Укажите пороговое значение 0 и число последовательных нарушений больше 0.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Создание правила генерации оповещений для событий Syslog с определенным уровнем серьезности. В следующем примере показаны события ошибок авторизации. Укажите пороговое значение 0 и число последовательных нарушений больше 0.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
настраиваемые счетчики производительности;
Создание оповещения по достижении максимального значения счетчика.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerСоздание оповещения по достижении среднего значения счетчика.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer