Кэширование — это распространенный способ, который предназначен для повышения производительности и масштабируемости системы. Он кэширует данные, временно скопировав часто доступ к данным в быстрое хранилище, которое находится рядом с приложением. Если это быстрое хранилище данных находится ближе к приложению, чем исходный оригинал, кэширование может значительно улучшить время отклика для клиентских приложений путем более быстрой обработки данных.
Кэширование становится наиболее эффективным, когда экземпляр клиента несколько раз считывает те же данные, особенно в том случае, если к исходному хранилищу данных применяются все указанные далее условия.
- Оно остается относительно статичным.
- Оно является медленным по сравнению со скоростью кэша.
- Оно является объектом высокого числа конкурентных запросов.
- Оно находится далеко, из-за чего задержки в сети могут вызвать снижение скорости доступа.
Кэширование в распределенных приложениях
Распределенные приложения обычно реализуют одну или обе из следующих стратегий кэширования данных.
- Они используют частный кэш, где данные хранятся локально на компьютере, на котором выполняется экземпляр приложения или службы.
- Они используют общий кэш, выступая в качестве общего источника, доступ к которому можно получить несколькими процессами и компьютерами.
В обоих случаях кэширование может быть выполнено на стороне клиента и сервера. Кэширование на стороне клиента выполняется процессом, предоставляющим пользовательский интерфейс для системы, например веб-браузер или классическое приложение. Кэширование на стороне сервера выполняется процессом, предоставляющим бизнес-службы, работающие удаленно.
Частный кэш
Самый простой тип кэша — это хранилище в памяти. Оно создается в адресном пространстве одного процесса, а доступ к нему осуществляется непосредственно кодом, выполняемым в этом процессе. Этот тип кэша обладает высокой скоростью доступа. Он также может предоставлять эффективные средства для хранения скромных объемов статических данных. Размер кэша обычно ограничивается объемом памяти, доступной на компьютере, на котором размещен процесс.
Если необходимо кэшировать больше данных, чем физически возможно разместить в памяти, можно сохранить кэшированные данные в локальной файловой системе. Этот процесс будет медленнее получать доступ, чем данные, которые хранятся в памяти, но все равно должны быть более быстрыми и надежными, чем получение данных в сети.
Если имеется несколько экземпляров приложения, использующего эту модель, которые выполняются одновременно, каждый экземпляр приложения будет иметь собственный независимый кэш со своей копией данных.
Представляйте кэш как моментальный снимок исходных данных в определенный момент в прошлом. Если эти данные не статически, скорее всего, разные экземпляры приложений содержат разные версии данных в своих кэшах. Таким образом, результат выполнения одинаковых запросов этими экземплярами может быть различным, как показано на рисунке 1.
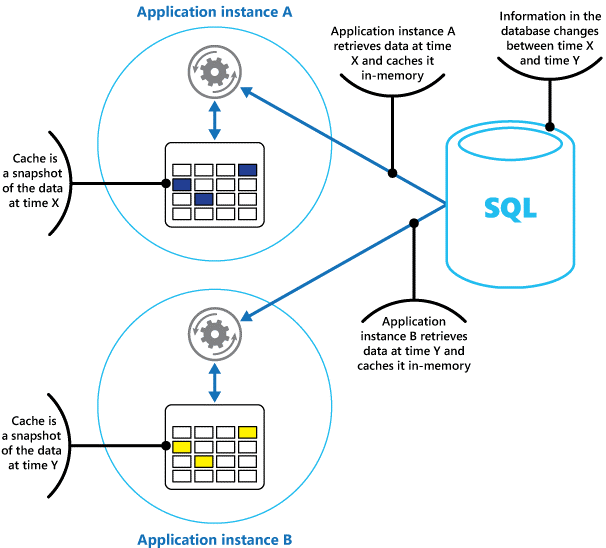
Рисунок 1. Использование кэша в памяти в разных экземплярах приложения
Общий кэш
Если вы используете общий кэш, это может помочь устранить проблемы, которые могут отличаться в каждом кэше, что может произойти при кэшировании в памяти. Общее кэширование гарантирует, что различные экземпляры приложения будут иметь одинаковое представление кэшированных данных. Он находит кэш в отдельном расположении, которое обычно размещается в составе отдельной службы, как показано на рис. 2.
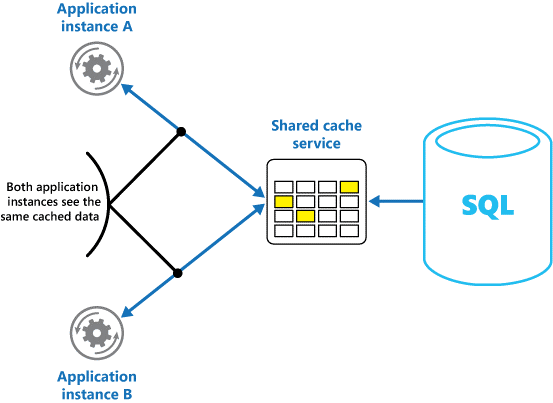
Рисунок 2. Использование общего кэша
Важным преимуществом использования общего кэширования является возможность масштабируемости. Многие службы общего кэша реализуются с помощью кластера серверов и используют программное обеспечение для распределения данных по кластеру прозрачным образом. Экземпляр приложения просто отправляет запрос к службе кэша. Базовая инфраструктура определяет расположение кэшированных данных в кластере. Можно легко масштабировать кэш путем добавления дополнительных серверов.
Общее кэширование имеет два основных недостатка:
- Кэш медленнее для доступа, так как он больше не хранится локально для каждого экземпляра приложения.
- необходимость реализации отдельной службы кэша может усложнить решение.
Рекомендации по использованию кэширования
В следующих разделах подробно описываются рекомендации по разработке и использованию кэша.
Определение необходимости кэширования данных
Кэширование может значительно повысить производительность, масштабируемость и доступность данных. Преимущества кэширования становятся все заметнее с увеличением объемов данных и числа пользователей, которым необходим доступ к этим данным. Кэширование уменьшает задержку и состязание, связанное с обработкой больших объемов одновременных запросов в исходном хранилище данных.
Например, база данных может поддерживать ограниченное число одновременных подключений. Но извлечение данных из общего кэша, а не из самой базы данных позволит клиентскому приложению получить доступ к этим данным, даже если число доступных в настоящее время подключений исчерпано. Кроме того, если база данных становится недоступной, клиентские приложения могут продолжить свою работу, используя данные, хранящиеся в кэше.
Рекомендуется предусмотреть кэширование часто читаемых, но редко изменяемых данных (например: данных с более высоким объемом операций чтения, чем операций записи). Однако не следует использовать кэш как полномочное хранилище критически важной информации. Вместо этого убедитесь, что все изменения, которые приложение не может позволить себе потерять, всегда сохраняются в постоянном хранилище данных. Если кэш недоступен, приложение по-прежнему может работать с помощью хранилища данных, и вы не потеряете важные сведения.
Определение способа эффективного кэширования данных
Ключом к эффективному использованию кэша является определение наиболее подходящих данных для помещения в кэш и их кэширование в правильный момент времени. Данные можно добавить в кэш по запросу при первом получении приложением. Приложение должно получить данные только один раз из хранилища данных, а последующий доступ может быть удовлетворен с помощью кэша.
Кроме того, кэш может полностью или частично заполняться данными заранее, обычно при запуске приложения (этот подход известен как "заполнение"). Тем не менее не рекомендуется использовать метод заполнения для большого кэша, так как этот подход может вызвать возникновение резкой, высокой нагрузки на хранилище исходных данных при запуске приложения.
Часто анализ шаблонов использования может помочь решить, следует ли выполнить полное или частичное предварительное заполнение кэша, а также выбрать данные для кэширования. Например, можно заполнить кэш статическими данными профиля пользователя для клиентов, которые регулярно используют приложение (возможно, каждый день), но не для клиентов, которые используют приложение только один раз в неделю.
Кэширование обычно хорошо работает с данными, которые являются неизменяемыми или изменяются редко. Примеры включают справочные сведения, такие как информация о продукте и сведения о ценах в приложении электронной коммерции или общие статические ресурсы, которые довольно сложно создать. Все эти данные или некоторые из них могут загружаться в кэш при запуске приложения для минимизации ресурсных требований и повышения производительности. Кроме того, вам может потребоваться фоновый процесс, который периодически обновляет эталонные данные в кэше, чтобы обеспечить актуальность. Или фоновый процесс может обновить кэш при изменении ссылочных данных.
Кэширование менее полезно для динамических данных, хотя существуют и некоторые исключения (для получения дополнительных сведений обратитесь к разделу "Кэширование высокодинамичных данных" далее в этом руководстве). Когда исходные данные регулярно изменяются, кэшированные данные становятся устаревшими или накладными затратами на синхронизацию кэша с исходным хранилищем данных снижает эффективность кэширования.
Кэш не должен включать полные данные для сущности. Например, если элемент данных представляет многозначный объект, например банковский клиент с именем, адресом и балансом счета, некоторые из этих элементов могут оставаться статическими, такими как имя и адрес. Другие элементы, такие как баланс учетной записи, могут быть более динамичными. В таких ситуациях может быть полезно кэшировать статические части данных и извлекать (или вычислять) только оставшиеся сведения, если это необходимо.
Чтобы определить, следует ли использовать метод предварительного заполнения или метод загрузки данных из кэша по требованию (или сочетание этих методов), рекомендуется провести тестирование производительности и анализ загруженности. Решение должно быть основано на информации об изменчивости данных и характере их использования. Использование кэша и анализ производительности важны в приложениях, которые сталкиваются с тяжелыми нагрузками и должны быть высокомасштабируемыми. Например, в высокомасштабируемых сценариях можно заполнить кэш, чтобы уменьшить нагрузку на хранилище данных в пиковое время.
Кэширование может также использоваться во избежание повторения вычислений во время работы приложения. Если операция преобразует данные или выполняет сложные вычисления, можно сохранить результаты операции в кэше. Если проведение таких же вычислений потребуется впоследствии, приложение может просто получить результаты из кэша.
Приложения могут изменять данные, хранящиеся в кэше. Однако кэш следует рассматривать как хранилище временных данных, которое может стать недоступным в любое время. Не сохраняйте ценные данные только в кэше; Убедитесь, что данные также хранятся в исходном хранилище данных. Таким образом, если кэш станет недоступным, можно свести к минимуму вероятность потери данных.
Кэширование высокодинамичных данных
Хранение быстро изменяющейся информации в постоянном хранилище данных может создать нагрузку на систему. Например, рассмотрим устройство, которое постоянно сообщает о состоянии или производит какие-либо других измерения. Если приложение примет решение не кэшировать эти данные на основе того, что кэшированные данные почти всегда будут устаревшими, то же самое может произойти при отправке и получении этих сведений из хранилища данных. В течение времени, необходимого для сохранения и получения данных, эти данные уже могут быть изменены.
В подобной ситуации следует рассмотреть преимущества хранения динамических данных непосредственно в кэше, а не в постоянном хранилище данных. Если данные некритичные и не требуют аудита, это не имеет значения, если случайные изменения потеряны.
Управление истечением срока актуальности данных в кэше
В большинстве случаев данные, хранящиеся в кэше, являются копией данных, находящихся в хранилище исходных данных. Данные в хранилище исходных данных могут измениться после того, как были кэшированы, в результате чего кэшированные данные устаревают. Многие системы кэширования позволяют установить срок актуальности кэшированных данных и сократить период, в течение которого данные могут быть устаревшими.
Когда кэшированные данные устаревают, они удаляются из кэша и приложение должно получить данные из исходного хранилища данных (приложение может поместить недавно извлеченные данные обратно в кэш). Можно задать политику истечения срока действия по умолчанию при настройке кэша. Во многих службах кэша можно также указать срок для отдельных объектов при их программном хранении в кэше. Некоторые кэши позволяют указать срок действия как абсолютное значение или как скользящее значение, которое приводит к удалению элемента из кэша, если доступ к нему не выполняется в течение указанного времени. Этот параметр переопределяет любые политики срока действия кэша, но только для указанных объектов.
Примечание.
Следует тщательно обдумать выбор срока актуальности кэша и объектов, содержащихся в нем. Если вы сделаете его слишком коротким, объекты устареют слишком быстро, что уменьшит преимущества использования кэша. Если будет установлен слишком длинный период, то существует риск, что данные перестанут быть актуальными.
Также возможно переполнение кэша, если допустить нахождение данных в кэше в течение длительного времени. В этом случае запросы для добавления новых элементов в кэш могут привести к тому, что некоторые элементы будут принудительно удалены в ходе процесса, называемого вытеснением. Службы кэша обычно исключают данные на основе принципа наиболее давно использовавшихся (LRU) элементов, но обычно можно переопределить эту политику, чтобы предотвратить удаление элементов. Однако, если будет применен такой подход, существует риск, что размер кэша превысит объем доступной памяти. Приложение, которое попытается добавить элемент в кэш, завершится ошибкой с исключением.
Некоторые реализации кэширования могут предоставлять дополнительные политики вытеснения. Существует несколько типов политик вытеснения. Например:
- Последняя политика (в ожидании того, что данные не потребуются снова).
- Политика "первым прибыл, первым обслужен" (сначала вытесняются более старые данные).
- Политика явного удаления на основе запущенного события (например, изменяемые данные).
Данные кэша на стороне клиента, утратившие актуальность
Данные, хранящиеся в кэше на стороне клиента, обычно рассматриваются как находящиеся за пределами ответственности службы, предоставляющей данные для клиента. Служба не может напрямую принудительно добавлять или удалять сведения из клиентского кэша.
Это означает, что клиент, использующий неправильно настроенный кэш, будет продолжать пользоваться устаревшей информацией. Например, если политики срока действия кэша не реализованы должным образом, клиент может использовать устаревшие данные, кэшируемые локально при изменении информации в исходном источнике данных.
Если вы создаете веб-приложение, которое обслуживает данные через HTTP-подключение, вы можете неявно принудительно принудительно принудить веб-клиент (например, браузер или веб-прокси) получить последние сведения. Это можно сделать, если ресурс обновляется путем изменения URI ресурса. Веб-клиенты обычно используют URI ресурса как ключ для кэша на стороне клиента, поэтому при изменении URI веб-клиент игнорирует любые ранее кэшированные версии ресурса и получает вместо них новую версию данных.
Управление параллелизмом в кэше
Кэши часто предназначены для совместного использования нескольких экземпляров одного приложения. Каждый экземпляр приложения может считывать и изменять данные в кэше. Следовательно, та же проблема параллелизма, присущая любому хранилищу данных, применима и к кэшу. В ситуации, когда приложению необходимо изменить данные, которые хранятся в кэше, может потребоваться убедиться, что обновления, внесенные одним экземпляром приложения, не перезаписывают изменения, внесенные другим экземпляром.
В зависимости от характера данных и вероятности конфликтов можно пользоваться одним из двух подходов к решению вопроса параллелизма.
- Оптимистичный подход. Приложение проверяет, изменялись ли данные в кэше с момента получения, непосредственно перед их обновлением. Если данные не изменялись, то можно произвести изменения. В противном случае приложение должно принять решение, следует ли обновить данные. (Бизнес-логика, которая управляет этим решением, будет конкретным приложением.) Этот подход подходит для ситуаций, когда обновления нечасто или где столкновения вряд ли возникают.
- Пессимистичный подход. Извлекая данные, приложение блокирует их в кэше, чтобы предотвратить их изменение другим экземпляром. Этот процесс гарантирует, что столкновения не могут возникать, но они также могут блокировать другие экземпляры, которые должны обрабатывать те же данные. Пессимистичный параллелизм может повлиять на масштабируемость решения и рекомендуется к использованию только для кратковременных операций. Этот подход более подходит для ситуаций, где возникновение конфликтов наиболее вероятно, особенно в том случае, если приложение обновляет несколько элементов в кэше, и необходимо убедиться, что эти изменения применяются последовательно.
Реализация высокой доступности и масштабируемости и повышение производительности
Кэш не следует использовать в качестве основного хранилища данных. Эту роль должно выполнять хранилище исходных данных, из которого заполняется кэш. Исходное хранилище данных отвечает за постоянное хранение данных.
Будьте внимательны и не создавайте критической зависимости от доступности службы общего кэша в своих решениях. Приложения должны иметь возможность продолжать функционирование при недоступности службы общего кэша. Приложение не должно перестать отвечать на запросы или завершать сбой при ожидании возобновления службы кэша.
Таким образом, приложение должно быть способно определить доступность службы кэширования и переключиться на исходное хранилище данных, если кэш недоступен. Для обработки такой ситуации полезен шаблон "Автоматическое выключение" (Circuit-Breaker Pattern). Служба кэша может быть восстановлена, и как только она станет доступной, кэш может начать заполняться по мере считывания данных из хранилища исходных данных, следуя стратегии шаблона "Отдельно от кэша"(Cache-Aside pattern).
Однако обращение приложения к исходному хранилищу данных, когда кэш временно недоступен, может повлиять на масштабируемость системы. Пока хранилище данных восстанавливается, исходное хранилище данных может быть загружено множеством запросов к данным, что приведет к увеличению времени ожидания и к сбоям соединения.
Рассмотрите возможность реализации локального частного кэша в каждом экземпляре приложения вместе с общим кэшем, к которому все экземпляры приложения имеют доступ. Когда приложение получает элемент, оно может проверить сначала свой локальный кэш, затем общий кэш и только потом хранилище исходных данных. Локальный кэш может быть заполнен с помощью данных из общего кэша или базы данных, если общий кэш недоступен.
Этот подход требует внимательной настройки, чтобы предотвратить устаревание локального кэша по отношению к общему кэшу. Однако локальный кэш будет служить буфером, если общий кэш недоступен. Эта структура показана на рис. 3.
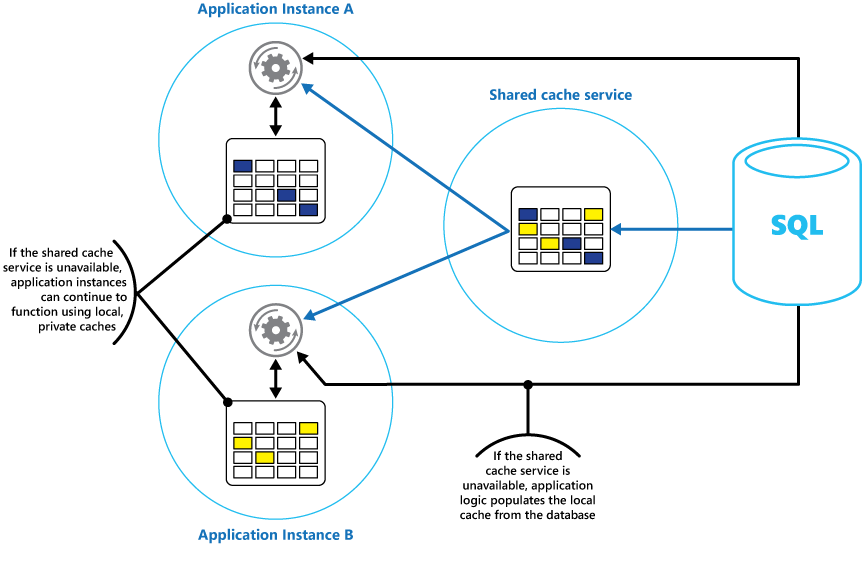
Рисунок 3. Использование локального частного кэша с общим кэшем
Для поддержки крупных кэшей, содержащих данные с относительно большим временем выполнения, некоторые службы кэша предоставляют параметр высокого уровня доступности, который реализует автоматический переход на другой ресурс, если кэш становится недоступным. Этот подход обычно подразумевает репликацию кэшированных данных, хранящихся на сервере основного кэша, на сервер вторичного кэша и переключение на работу со вторичным сервером в случае сбоя основного сервера или при потере связи.
Чтобы сократить задержки, связанные с записью в несколько местоположений, репликация на вторичный сервер может происходить асинхронно, если данные записываются в кэш на основной сервер. Такой подход приводит к тому, что некоторые кэшированные сведения могут быть потеряны при сбое, но доля этих данных должна быть небольшой, по сравнению с общим размером кэша.
При большом объеме общего кэша может быть полезным произвести секционирование кэшированных данных по узлам, чтобы снизить вероятность конфликтов и повысить масштабируемость. Многие службы общего кэша поддерживают возможность динамического добавления (и удаления) узлов и изменения баланса данных по секциям. Этот подход может включать кластеризацию, когда коллекция узлов представляется клиентским приложениям в виде целого, единого кэша. Но внутри данные распределены между узлами в соответствии с некоторыми стандартными стратегиями распределения, что равномерно распределяет нагрузку. См. дополнительные сведения о секционировании данных.
Кластеризация может также повысить уровень доступности кэша. В случае сбоя узла остальная часть кэша по-прежнему остается доступной. Кластеризация часто используется в сочетании с репликации и отработкой отказов. Каждый узел может быть реплицирован, а реплика — быстро переведена в оперативный режим, если на узле происходит сбой.
Множественные операции чтения и записи, скорее всего, будут выполняться с единым значением данных или объектов. Однако иногда это необходимо для быстрого хранения и извлечения больших объемов данных. Например, заполнение кэша может предполагать запись сотен или тысяч элементов в кэш. Или приложению может потребоваться получить большое количество связанных элементов из кэша как часть того же запроса.
Для этих целей многие крупномасштабные кэши позволяют выполнять пакетные операции. Это позволяет клиентскому приложению сгруппировать большое количество элементов в один запрос и сократить издержки, связанные с выполнением большого количества небольших запросов.
Кэширование и окончательная согласованность
Чтобы шаблон "Отдельно от кэша" работал, экземпляр приложения, который заполняет кэш, должен иметь доступ к самым актуальным и согласованным данным. В системе, которая реализует окончательную согласованность (реплицируемое хранилище данных), это может быть не так.
Один экземпляр приложения может изменить элемент данных и сделать кэшированную версию этого элемента недействительной. Другой экземпляр приложения может попытаться прочитать этот элемент из кэша, что приведет к промаху кэша, поэтому он считает данные из хранилища данных и добавит их в кэш. Однако если хранилище данных не было полностью синхронизировано с другими реплика, экземпляр приложения может считывать и заполнять кэш старым значением.
Дополнительные сведения см. в руководстве по обеспечению согласованности данных.
Защита кэшированных данных
Независимо от используемой службы кэша следует рассмотреть вопрос защиты данных, хранящихся в кэше, от несанкционированного доступа. Существуют две основные проблемы.
- Конфиденциальность данных в кэше.
- Конфиденциальность данных в процессе их передачи между кэшем и приложением, в котором используется этот кэш.
Для защиты данных в кэше служба кэша может реализовать механизм проверки подлинности, который требует от приложений указывать следующие моменты:
- какие удостоверения могут обращаться к данным в кэше;
- какие операции (чтение и запись) разрешено выполнять этим удостоверениям.
Чтобы снизить издержки, связанные с чтением и записью данных, после того как удостоверению был предоставлен доступ к записи или чтению в кэш, удостоверение может использовать любые данные в кэше.
Если требуется ограничить доступ к подмножествам кэшированных данных, можно сделать следующее:
- Разбить кэш на секции (с помощью различных серверов кэширования) и предоставить доступ удостоверениям только к тем секциям, которые они должны использовать.
- Зашифровать данные в каждом подмножестве с помощью различных ключей и предоставить ключи шифрования только тем удостоверениям, которые должны иметь доступ к каждому подмножеству. Клиентское приложение по-прежнему сможет получить все данные в кэше, но при этом расшифровать только те данные, для которых имеются ключи.
Необходимо также обеспечить защиту данных по мере поступления в кэш и из него. Эта защита зависит от средств безопасности, предоставляемых сетевой инфраструктурой, которую клиентские приложения используют для подключения к кэшу. Если кэш реализуется на локальном сервере той же организации, где размещены клиентские приложения, то изоляция самой сети может позволить не предпринимать никаких дополнительных действий. Если кэш расположен в удаленном месте и требует подключения TCP или HTTP через общедоступную сеть (например Интернет), рассмотрите возможность реализации SSL.
Рекомендации по реализации кэширования в Azure
Кэш Azure для Redis — это реализация кэша Redis с открытым кодом, которая выполняется как служба в центре обработки данных Azure. Он предоставляет службу кэша, к которой можно получить доступ из любого приложения Azure, вне зависимости от того, как реализовано приложение — в виде облачной службы, веб-сайта либо в виртуальной машине Azure. Кэши могут совместно использоваться клиентскими приложениями, имеющими соответствующие ключи доступа.
Кэш Azure для Redis представляет собой высокопроизводительное решение кэширования, обеспечивающее доступность, масштабируемость и безопасность. Данное решение обычно запускается как служба, распределенная между одной или несколькими выделенными машинами. Оно пытается сохранить как можно больший объем информации в памяти для обеспечения быстрого доступа. Такая архитектура предназначена для обеспечения малой задержки и высокой пропускной способности, уменьшая необходимость выполнения медленных операций ввода-вывода.
Кэш Azure для Redis совместим со многими различными интерфейсами API, которые используются клиентскими приложениями. При наличии существующих приложений, которые уже используют Кэш Azure для Redis локально, Кэш Azure для Redis предоставляет возможность быстрого перехода к кэшированию в облаке.
Функции Redis
Redis — это больше, чем простой сервер кэширования. Он предоставляет распределенную базу данных в памяти с набором расширенных команд, который поддерживает многие распространенные сценарии. Они описаны далее в этом документе в разделе "Варианты использования кэширования Redis". В этом разделе перечислены некоторые ключевые функции, которые предоставляет Redis.
Redis в качестве базы данных в памяти
Redis поддерживает операции чтения и записи. В Redis запись может быть защищена от сбоя системы либо путем периодического размещения в локальном файле моментальных снимков, либо в файле журнала только для добавления. Эта ситуация не является делом во многих кэшах, которые следует рассматривать как временные хранилища данных.
Все записи являются асинхронными и не блокируют чтение и запись данных клиентами. Когда Redis начинает работу, он считывает данные из файла моментальных снимков или из журнала и использует эти данные для создания кэша в памяти. Дополнительные сведения см. в разделе Redis persistence (Сохраняемость Redis) на веб-сайте Redis.
Примечание.
Redis не гарантирует, что все записи будут сохранены, если есть катастрофический сбой, но в худшем случае вы можете потерять только несколько секунд стоит данных. Помните, что кэш не предназначен для работы в качестве авторитетного источника данных, и это ответственность за приложения, использующие кэш, чтобы обеспечить успешное сохранение критически важных данных в соответствующем хранилище данных. Дополнительные сведения см. в статье о шаблоне программирования отдельно от кэша.
Типы данных Redis
Redis представляет собой хранилище "ключ-значение", где значения могут содержать простые типы или сложные структуры данных в виде хэшей, списков и наборов. Он поддерживает ряд атомарных операций с этими типами данных. Ключи могут быть постоянными или ограниченными по времени действия, по достижении которого ключ и соответствующие ему значения будут автоматически удалены из кэша. Для получения дополнительных сведений о ключах и значениях Redis посетите страницу Введение в типы данных Redis и абстракции на веб-сайте Redis.
Репликация и кластеризация Redis
Redis поддерживает главную/подчиненную репликацию для обеспечения доступности и пропускной способности. Операции записи на главном узле Redis реплицируются на один или более подчиненных узлов. Операции считывания могут обрабатываться главным или любым подчиненным узлом.
Если у вас есть сетевая секция, подчиненные могут продолжать обслуживать данные, а затем прозрачно переназначать с основным при повторном развертывании подключения. Для получения дополнительных сведений посетите страницу Репликации на веб-сайте Redis.
Redis также предоставляет возможность кластеризации, что позволяет выполнять прозрачное секционирование данных на сегменты на серверах и распределение нагрузки. Эта функция повышает масштабируемость, так как можно добавлять новые серверы Redis, в то время как данные будут секционированы по мере увеличения размера кэша.
Кроме того, каждый сервер в кластере может реплицироваться путем метода главной/подчиненной репликации. Это обеспечивает доступность каждого узла в кластере. Дополнительные сведения о кластеризации и сегментировании можно найти на странице Руководство по кластеризации Redis на веб-сайте Redis.
Использование памяти Redis
Кэш Redis имеет ограниченный размер в зависимости от доступных ресурсов на главном компьютере. При настройке сервера Redis можно указать максимальный объем памяти, который может использоваться. Вы также можете настроить ключ в кэше Redis для истечения срока действия, после которого он автоматически удаляется из кэша. Эта функция помогает предотвратить заполняемость кэша в памяти старыми или устаревшими данными.
При заполнении памяти Redis можно автоматически исключить ключи и значения, выполнив ряд политик. По умолчанию используется LRU (по крайней мере используется), но вы также можете выбрать другие политики, такие как вытеснение ключей случайным образом или отключение вытеснения (в этом случае попытки добавления элементов в кэш завершаются ошибкой, если они полны). Дополнительные сведения можно найти на странице Использование Redis в качестве кэша LRU .
Транзакции и пакетные операции Redis
Redis позволяет клиентскому приложению осуществлять серию операций чтения и записи данных в кэше путем единой атомарной транзакции. Все команды в транзакции будут гарантированно выполнены последовательно, и никакие команды других параллельных клиентов не будут выполняться между ними.
Однако эти транзакции не являются истинными, так как реляционная база данных будет выполнять их. Обработка транзакций состоит из двух этапов: постановка команд в очередь и выполнение команд. На этапе постановки команд в очередь команды, которые составляют транзакцию, отправляются клиентом. Если на данном этапе возникает какая-либо ошибка (например синтаксическая ошибка или появление неправильного количества параметров), Redis отклонит обработку всей транзакции и удалит ее.
На этапе выполнения Redis выполняет каждую команду из очереди последовательно. Если команда завершается сбоем на этом этапе, Redis продолжает выполнять следующую команду в очереди и не откатывает эффекты уже запущенных команд. Такая упрощенная форма транзакции помогает поддерживать производительность и избегать проблем с ней, вызванных конфликтами доступа.
Redis реализует вариант оптимистичной блокировки для поддержания согласованности данных. Для получения подробных сведений о транзакциях и блокировке с Redis посетите страницу Транзакции веб-сайта Redis.
Redis также поддерживает нетранзакционную пакетную обработку запросов. Протокол Redis, используемый клиентами для отправки команд для сервера Redis, позволяет клиенту отправлять ряд операций в рамках одного запроса. Это может помочь снизить уровень фрагментации пакетов в сети. При обработке пакета выполняется каждая команда. Если какая-либо из этих команд неправильно сформирована, они будут отклонены (что не происходит с транзакцией), но остальные команды будут выполнены. Кроме того, нет никаких гарантий о порядке обработки команд в пакете.
Безопасность Redis
Redis предназначен исключительно для предоставления быстрого доступа к данным и для выполнения в безопасных средах, доступных только доверенным клиентам. Redis поддерживает ограниченную модель безопасности на основе проверки подлинности с помощью пароля. (Можно полностью удалить проверку подлинности, хотя мы не рекомендуем это.)
Все клиенты, прошедшие проверку подлинности, совместно используют один и тот же глобальный пароль и имеют доступ к тем же ресурсам. Если требуется более сложная модель безопасности для входа в систему, необходимо реализовать собственный уровень безопасности перед сервером Redis, и все клиентские запросы должны проходить через этот дополнительный уровень. Redis не должен быть напрямую предоставлен ненадежным или неуверенным клиентам.
Можно ограничить доступ к командам путем их отключения или переименования (и предоставив новые имена только привилегированным клиентам).
Redis не поддерживает ни одну форму шифрования данных, поэтому все кодировки должны выполняться клиентскими приложениями. Кроме того, Redis не предоставляет никакой формы безопасности транспорта. Если необходимо защитить данные при передаче по сети, рекомендуется реализовать прокси-сервер SSL.
Дополнительные сведения можно найти на странице Безопасность Redis на веб-сайте Redis.
Примечание.
Кэш Azure для Redis предоставляет собственный уровень безопасности, через который клиенты производят подключение. Базовые серверы Redis не предоставляются общедоступной сети.
Кэш Redis для Azure
Кэш Azure для Redis предоставляет доступ к серверам Redis, размещенным в центре обработки данных Azure. Он служит интерфейсом, обеспечивающим контроль доступа и безопасность. Подготовить кэш можно с помощью портала Azure.
Портал предоставляет ряд стандартных конфигураций. Минимальное предложение — кэш размером 53 ГБ, который выполняется в виде выделенной службы, поддерживает SSL-подключения (для обеспечения конфиденциальности) и главные или подчиненные репликации с соглашением об уровне обслуживания (доступность 99,9 %). Максимальный вариант — кэш размером 250 МБ без репликации (без гарантии доступности), который выполняется на общем оборудовании.
С помощью портала Azure можно также настроить политику вытеснения данных из кэша и управлять доступом к кэшу, добавляя пользователей к предоставленным ролям. В число этих ролей, которые определяют операции, выполняемые членами роли, входят "Владелец", "Участник", "Читатель". Например, члены роли "Владелец" имеют полный контроль над кэшем (включая безопасность) и его содержимым, члены роли "Участник" могут читать и записывать данные в кэш, а члены роли "Для чтения" могут только получать данные из кэша.
Большинство административных задач выполняются через портал Azure. По этой причине многие административные команды, доступные в стандартной версии Redis, недоступны, включая возможность программного изменения конфигурации, завершение работы сервера Redis, настройка дополнительных подчиненных или принудительное сохранение данных на диск.
Портал Azure имеет удобное графическое отображение, что позволяет отслеживать производительность кэша. Например, можно просмотреть количество подключений, число выполняемых запросов, количество операций чтения и записи и срабатываний кэша по отношению к промахам. С помощью этих сведений можно определить эффективность кэша и при необходимости переключить его на другую конфигурацию или изменить политику вытеснения.
Кроме того, можно создать оповещения, которые будут отправлять сообщения по электронной почте администратору, если один или несколько важных показателей выходят за пределы ожидаемого диапазона. Например, можно настроить отправку оповещений администратору, если указанное значение превышает число промахов кэша за последний час, поскольку кэш может быть слишком мал или данные могут удаляться слишком быстро.
Также можно отслеживать загрузку ЦП, памяти и использования сети для кэша.
Для получения дополнительных сведений и примеров, показывающих, как создать и настроить Кэш Azure для Redis, посетите страницу Знакомство с функциями Кэша Azure для Redis в блоге Azure.
Кэширование состояния сеанса и результат в формате HTML
Если вы создаете ASP.NET веб-приложения, которые выполняются с помощью веб-ролей Azure, можно сохранить сведения о состоянии сеанса и выходные данные HTML в Кэш Azure для Redis. Поставщик состояний сеанса для Кэш Azure для Redis позволяет совместно использовать сведения о сеансах между различными экземплярами веб-приложения ASP.NET и очень полезно в ситуациях веб-фермы, когда сходство между клиентским сервером недоступно и кэширование данных сеанса в памяти не будет подходящим.
Использование поставщика состояний сеансов с Кэшем Azure для Redis предоставляет несколько преимуществ, включая перечисленные ниже.
- Совместное использование состояния сеанса с большим числом экземпляров веб-приложений ASP.NET.
- Обеспечение улучшенной масштабируемости.
- Поддержка контролируемого параллельного доступа к тем же данным состояния сеанса для нескольких читателей и одного писателя.
- Использование сжатия для экономии памяти и повышения производительности сети.
Дополнительные сведения см. в статье Поставщик состояний сеансов ASP.NET для Кэша Azure для Redis.
Примечание.
Не используйте поставщик состояний сеанса для Кэш Azure для Redis с ASP.NET приложениями, работающими за пределами среды Azure. Задержка доступа к кэшу не из среды Azure может исключить преимущества от кэширования данных.
Аналогично, поставщик кэша выходных данных для Кэша Azure для Redis позволяет сохранять ответы HTTP, создаваемые веб-приложением ASP.NET. Использование поставщика кэша выходных данных с Кэшем Azure для Redis может улучшить время отклика приложений, которые отображают сложные выходные данные HTML. Экземпляры приложения, выдающие схожие ответы, могут использовать общие фрагменты выходных данных в кэше вместо создания таких выходных данных HTML заново. Дополнительные сведения см. в статье Поставщик кэша выходных данных ASP.NET для Кэша Azure для Redis.
Построение пользовательского кэша Redis
Кэш Azure для Redis выступает в качестве оболочки для базовых серверов Redis. Если требуется расширенная конфигурация, которая не охватывается кэшем Redis Azure (например, кэш размером более 53 ГБ), можно создавать и размещать собственные серверы Redis с помощью виртуальных машин Azure.
Это потенциально сложный процесс, поскольку может потребоваться создать несколько виртуальных машин в качестве главного и подчиненных узлов, если нужно реализовать репликацию. Кроме того, если вы хотите создать кластер, будет необходимо наличие нескольких главных и подчиненных серверов. Минимальная кластеризованная топология репликации, обеспечивающая высокий уровень доступности и масштабируемости, состоит по крайней мере из шести виртуальных машин, организованных в виде трех пар главных/подчиненных серверов (кластер должен содержать по крайней мере три главных узла).
Каждая пара главный/подчиненный должна располагаться рядом друг с другом, чтобы свести к минимуму задержки. Но каждый набор пар может работать в разных центрах обработки данных Azure, находящихся в разных регионах, если вы хотите разместить кэшированные данные рядом с приложениями, которые, скорее всего, будут использовать эти данные. Пример создания и настройки узла Redis, который выполняется как виртуальная машина Azure, см. в статье о запуске Redis на виртуальной машине CentOS Linux в Azure.
Примечание.
Если вы реализуете собственный кэш Redis таким образом, вы несете ответственность за мониторинг, управление и защиту службы.
Секционирование кэша Redis
Секционирование кэша предполагает разделение кэша на несколько компьютеров. Такая структура дает следующие преимущества по сравнению с использованием кэша на одном сервере.
- Возможность создания более объемного кэша, чем может храниться на одном сервере.
- Распределение данных между серверами, повышение доступности. Если один сервер неисправен или становится недоступным, данные, которые он содержит, также оказываются недоступны. Однако данные на остальных серверах по-прежнему остаются доступными. Для кэша это не важно, так как кэшированные данные — это только временная копия данных, которые хранятся в базе данных. Кэшированные данные на сервере, который становится недоступным, могут быть кэшированы на другом сервере.
- Распределение нагрузки между серверами,чем улучшается производительность и масштабируемость.
- Данные расположены ближе к пользователям географически, что уменьшает задержку.
Для кэша наиболее распространенной формой секционирования является сегментирование. В этой стратегии каждая секция (или сегмент) представляет собой кэш Redis сама по себе. Данные направляются в определенную секцию в соответствии с логикой сегментирования, которая может использовать различные подходы для распределения данных. Шаблон сегментирования содержит более подробные сведения о реализации сегментирования.
Для реализации секционирования в кэше Redis можно использовать один из следующих подходов:
- Маршрутизация запросов на стороне сервера. В этом методе клиентское приложение отправляет запрос на один из серверов Redis, являющийся кэшем (возможно, ближайший сервер). Каждый сервер Redis хранит метаданные, описывающие секции, которые он содержит, и также содержит сведения о том, какие разделы находятся на других серверах. Сервер Redis проверяет запрос клиента. Если он может быть обработан локально, сервер выполнит запрошенную операцию. В противном случае запрос будет перенаправлен на соответствующий сервер. Эта модель реализуется путем кластеризации Redis и более подробно описана на странице Redis cluster tutorial (Учебник по кластеризации Redis) на веб-сайте Redis. Кластеризация Redis прозрачна для клиентских приложений, и в кластер можно добавлять дополнительные серверы Redis (а также повторно секционировать данные) без необходимости перенастройки клиентов.
- Секционирование на стороне клиента. В этой модели клиентское приложение содержит логику (возможно, в виде библиотеки), которая перенаправляет запросы на соответствующие серверы Redis. Этот подход может использоваться с Кэшем Azure для Redis. Создайте несколько Кэшей Azure для Redis (по одному для каждой секции данных) и реализуйте клиентскую логику, которая направляет запросы к правильному кэшу. При изменении схемы секционирования (например, если создаются дополнительные Кэши Azure для Redis) может потребоваться изменить конфигурацию клиентских приложений.
- Секционирование с помощью прокси-сервера. В этой схеме клиентские приложения отправляют запросы к промежуточной прокси-службе, которая хранит информацию о секционировании данных и передает запрос на соответствующий сервер Redis. Этот подход также может использоваться с Кэшем Azure для Redis; служба прокси-сервера может быть реализована в виде облачной службы Azure. Этот подход подразумевает наличие дополнительного уровня сложности для реализации службы, и запросы могут занять больше времени, чем с помощью секционирования на стороне клиента.
Подробнее о реализации секционирования с помощью Redis см. на странице Partitioning: how to split data among multiple Redis instances (Секционирование: распределение данных между несколькими экземплярами Redis) на веб-сайте Redis.
Реализация клиентских приложений кэша Redis
Redis поддерживает клиентские приложения, написанные на различных языках программирования. Если вы создаете новые приложения с помощью платформа .NET Framework, мы рекомендуем использовать клиентская библиотека StackExchange.Redis. Эта библиотека предоставляет объектную модель платформы .NET Framework, абстрагирующую подробные сведения для соединения с сервером Redis, отправки команд и получения ответов. Он доступен в Visual Studio в виде пакета NuGet. Эту же библиотеку можно использовать для подключения к Кэшу Azure для Redis или пользовательскому кэшу Redis, размещенному на виртуальной машине.
Для подключения к серверу Redis следует использовать статический Connect метод ConnectionMultiplexer класса. Подключение, которое создает этот метод, предназначается для использования во время работы клиентского приложения, и то же подключение может использоваться несколькими параллельными потоками. Не подключайтесь и не отключайтесь при каждом выполнении операции Redis, так как это может снизить производительность.
Можно указать параметры подключения, например адрес узла Redis и пароль. Если вы используете Кэш Azure для Redis, пароль является первичным или вторичным ключом, созданным для Кэш Azure для Redis с помощью портал Azure.
После подключения к серверу Redis можно получить дескриптор в базе данных Redis, который выступает в качестве кэша. Подключение Redis для этого предоставляет метод GetDatabase . Далее можно извлекать элементы из кэша и хранить данные в кэше, используя методы StringGet и StringSet. Эти методы ожидают ключ как параметр и возвращают элемент в кэше с соответствующим значением (StringGet) или добавляют элемент в кэш с этим ключом (StringSet).
В зависимости от расположения сервера Redis многие операции могут выполняться с задержкой, пока запрос передается на сервер и ответ возвращается клиенту. Библиотека StackExchange предоставляет асинхронные версии для множества методов, способных помочь клиентским приложениям избежать зависаний. Эти методы поддерживают асинхронную модель на основе задач в .NET Framework.
В приведенном ниже фрагменте кода показан метод с именем RetrieveItem. Он иллюстрирует пример реализации шаблона отдельно от кэша на основе Redis и библиотеки StackExchange. Метод получает строковое значение ключа и пытается получить соответствующий элемент из кэша Redis, вызвав метод StringGetAsync (асинхронная версия StringGet).
Если элемент не найден, он извлекается из базового источника данных с помощью GetItemFromDataSourceAsync метода (который является локальным методом, а не частью библиотеки StackExchange). Затем он добавляется в кэш с помощью метода StringSetAsync , поэтому в следующий раз его можно будет получить быстрее.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
StringSet Методы StringGet не ограничиваются извлечением или хранением строковых значений. Они могут принимать любые элементы, упорядоченные в виде массива байтов. Если необходимо сохранить объект .NET, можно упорядочить его как поток байтов и использовать метод StringSet для записи в кэш.
Аналогичным образом можно считать объект из кэша с помощью метода StringGet и разупорядочить его как объект .NET. В приведенном далее коде показан набор методов расширения для интерфейса IDatabase (метод GetDatabase подключения Redis возвращает объект IDatabase) и некоторые образцы кода, использующие эти методы для чтения объектов BlogPost и их записи в кэш.
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
В следующем коде демонстрируется метод с именем RetrieveBlogPost, использующий эти методы расширения для чтения и записи упорядочиваемого объекта BlogPost в кэш согласно шаблону «Отдельно от кэша».
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis поддерживает команды конвейеризации, если клиентское приложение отправляет несколько асинхронных запросов. Redis может мультиплексировать запросы в том же соединении вместо получения и обработки команд в строгой последовательности.
Такой подход позволяет сократить задержку путем более эффективного использования сети. В следующем фрагменте кода показан пример, который получает сведения о двух клиентах одновременно. Код отправляет два запроса, а затем выполняет некоторую обработку (не показано) перед ожиданием для получения результатов. Метод Wait объекта кэша аналогичен методу .NET Framework Task.Wait.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Дополнительные сведения о написании клиентских приложений, которые могут использовать Кэш Azure для Redis, см. в документации по Кэш Azure для Redis. Дополнительные сведения вы найдете на сайте StackExchange.Redis.
На странице Конвейеры и мультиплексоры на том же веб-сайте содержатся дополнительные сведения об асинхронных операциях и конвейеризации с Redis при использовании библиотеки StackExchange.
Варианты использования кэша Redis
Простое использование кэширования Redis подразумевает хранение пар "ключ-значение", где значением является строка без интерпретации произвольной длины, которая может содержать любые двоичные данные. (Это, по сути, массив байтов, которые можно рассматривать как строку). Этот сценарий был описан в разделе "Реализация клиентских приложений кэша Redis" ранее в этой статье.
Следует отметить, что ключи также содержат данные без интерпретации, поэтому в качестве ключа можно использовать любые двоичные данные. Чем длиннее ключ, тем больше места ему будет необходимо для хранения и тем больше времени потребуется для выполнения операции поиска. Для удобства и простоты обслуживания рекомендуется более тщательно создавать пространство ключей и использовать содержательные (но не многословные) ключи.
Например, можно использовать структурированные ключи, такие как "customer:100", для представления ключа для клиента с идентификатором 100, а не просто "100". Эта схема позволяет легко различать значения, которые хранят различные типы данных. Например, можно также использовать ключ "orders:100" для представления ключа для заказа с идентификатором 100.
Помимо одномерных двоичных строк значение в паре "ключ-значение" Redis также может содержать более структурированные данные, включая списки, наборы (отсортированные и несортированные) и хэши. Redis предоставляет набор комплексных команд, с помощью которых можно работать с этими типами данных, и многие из этих команд доступны для приложений .NET Framework через клиентскую библиотеку, например StackExchange. На странице Введение в типы данных Redis и абстракции веб-сайта Redis предоставлен более подробный обзор этих типов и команды, которые позволяют работать с ними.
В этом разделе перечислены некоторые распространенные варианты использования этих типов данных и команд.
Выполнение атомарных и пакетных операций
Redis поддерживает ряд атомарных операций get и set для строковых значений. Эти операции помогают избежать рисков возможных конфликтов доступа, которые могут возникнуть при использовании отдельных команд GET и SET. Доступные следующие операции:
INCR,INCRBY,DECRиDECRBY, которые выполняют операции инкремента и декремента целочисленных значений числовых данных. Библиотека StackExchange предоставляет перегруженные версии методовIDatabase.StringIncrementAsyncиIDatabase.StringDecrementAsyncдля выполнения этих операций и возвращения результирующих значений, хранящихся в кэше. В следующем фрагменте кода показано, как использовать эти методы.ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, которая извлекает значение, связанное с ключом, и изменяет его на новое значение. Библиотека StackExchange предоставляет эту операцию в методеIDatabase.StringGetSetAsync. В следующем фрагменте кода показан пример этого метода. Этот код возвращает текущее значение, связанное с ключом "данные:счетчик", из предыдущего примера. Затем он сбрасывает значение для этого ключа к нулю, все в рамках одной операции.ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETиMSET, которые могут вернуть или изменить набор строковых значений за одну операцию.IDatabase.StringGetAsyncиIDatabase.StringSetAsyncявляются перегруженными методами для поддержки этих функций, как показано в следующем примере.ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Также можно объединить несколько операций в одну транзакцию Redis, как описано в разделе "Транзакции и пакетные операции Redis" в этой статье. Библиотека StackExchange обеспечивает поддержку транзакций через интерфейс ITransaction.
Можно создать объект ITransaction с помощью метода IDatabase.CreateTransaction. Вызовите команды для транзакции с помощью методов, предоставленных объектом ITransaction .
Интерфейс ITransaction предоставляет доступ к аналогичному набору методов, доступных с помощью интерфейса IDatabase, за исключением того, что все методы являются асинхронными. Это означает, что они выполняются только при вызове ITransaction.Execute метода. Значение, возвращаемое методом ITransaction.Execute , указывает, была ли транзакция создана успешно (true) или неудачно (false).
В следующем фрагменте кода показан пример увеличения и уменьшения двух счетчиков в рамках одной транзакции.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Помните, что транзакции Redis отличаются от транзакций в реляционных базах данных. Метод Execute просто помещает в очередь все команды, которые составляют транзакцию для выполнения, а если какая-либо из них имеет неправильный формат, транзакция прерывается. Если все команды были помещены в очередь успешно, каждая команда будет выполняться асинхронно.
Если какая-либо из команд завершается ошибкой, другие по-прежнему будут продолжать работу. Если необходимо убедиться, что команда выполнена успешно, нужно получить результаты выполнения команды с помощью свойства Result соответствующей задачи, как показано в приведенном выше примере. Возможность чтения свойства Result будет блокировать вызывающий поток до завершения задачи.
Дополнительные сведения см. в статье о транзакциях в Redis.
Для выполнения пакетных операций можно использовать интерфейс IBatch библиотеки StackExchange. Этот интерфейс предоставляет доступ к аналогичному набору методов, доступных с помощью интерфейса IDatabase , за исключением того, что все методы являются асинхронными.
Создать объект IBatch можно с помощью метода IDatabase.CreateBatch, а затем запустить пакетную операцию с помощью метода IBatch.Execute, как показано в следующем примере. Этот код просто задает строковое значение и увеличивает и уменьшает счетчики, используемые в предыдущем примере, и отображает результат.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Важно понимать, что в отличие от транзакции, если команда в пакете завершается ошибкой, так как она неправильно сформирована, другие команды по-прежнему могут выполняться. Метод IBatch.Execute не возвращает никаких признаков успешности или сбоя.
Выполнение автономных операций кэша
Redis поддерживает автономные операции с помощью командной строки. В этой ситуации клиент просто инициирует операцию, но не имеет интереса к результату и не ожидает завершения команды. В приведенном ниже примере показано, как выполнить команду INCR в виде автономной операции.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Указание автоматически устаревающих ключей
При сохранении элемента в кэше Redis можно указать время ожидания, после которого элемент будет автоматически удален из кэша. Можно также узнать, сколько времени осталось до истечения срока действия ключа с помощью команды TTL . Эта команда доступна для приложений StackExchange с использованием метода IDatabase.KeyTimeToLive .
В следующем фрагменте кода показан пример настройки времени окончания срока действия в 20 секунд для ключа и запрос оставшегося времени действия ключа.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Также можно задать в качестве срока действия определенную дату и время. Для этого служит команда EXPIRE, доступная в библиотеке StackExchange как метод KeyExpireAsync.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Совет
Вы можете вручную удалить объект из кэша с помощью команды DEL, которая доступна в библиотеке StackExchange как метод IDatabase.KeyDeleteAsync.
Использование тегов для взаимной корреляции кэшированных элементов
Набор Redis — это совокупность нескольких элементов, которые совместно используют один ключ. Можно создать набор с помощью команды SADD. Элементы в наборе можно получить с помощью команды SMEMBERS. Библиотека StackExchange реализует команду SADD через метод IDatabase.SetAddAsync и команду SMEMBERS через метод IDatabase.SetMembersAsync.
Можно также объединять существующие наборы данных для создания новых наборов с помощью команды SUNION (объединение), SINTER (пересечение) и SDIFF (разность). Библиотека StackExchange объединяет эти операции в методе IDatabase.SetCombineAsync . Первый параметр в этом методе указывает операцию с набором, которую нужно выполнить.
В следующих фрагментах кода показано, как можно использовать наборы для быстрого хранения и получения коллекции связанных элементов. Этот код использует объект типа BlogPost , который был описан в разделе "Реализация клиентских приложений кэша Redis" ранее в этой статье.
Объект BlogPost содержит четыре поля — идентификатор, заголовок, оценка ранжирования и набор тегов. Первый фрагмент кода ниже показывает пример данных, используемых для заполнения списка C# объектов BlogPost .
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Теги для каждого объекта BlogPost можно сохранить в виде набора в кэше Redis и связать каждый набор с идентификатором BlogPost. Это позволяет приложению быстро находить все теги, относящиеся к конкретной записи блога. Чтобы активировать поиск в обратном направлении и найти все сообщения в блогах, имеющие указанный тег, можно создать другой набор, содержащий записи блога со ссылкой на идентификатор тега в ключе.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Эти структуры позволяют эффективно выполнять многие общие запросы. Например, можно найти и отобразить все теги для записи блога 1 следующим образом.
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Можно найти все теги, которые являются общими для записей блогов 1 и 2, выполняя операцию пересечения наборов следующим образом.
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
И вы найдете все записи блога, содержащие определенный тег.
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Поиск последних использовавшихся элементов
Распространенной задачей, необходимой для многих приложений, является поиск недавно использовавшихся элементов. Например, веб-сайту может потребоваться отобразить сведения о наиболее недавно прочитанных записях блога.
Эту функциональность можно реализовать с помощью списка Redis. Список Redis содержит несколько элементов, которые совместно используют тот же ключ. Сам список действует как двусторонняя очередь. Можно отправить элементы в любой конец списка с помощью команд RPUSH (добавить справа) и LPUSH (добавить слева). Можно извлекать элементы из любого конца списка с помощью команды LPOP и RPOP. Также можно получить набор элементов с помощью команд LRANGE и RRANGE.
Фрагменты кода ниже показывают, как эти операции можно выполнить с помощью библиотеки StackExchange. Этот код использует объект типа BlogPost из предыдущих примеров. По мере чтения пользователями записей в блоге заголовки этих записей помещаются в список, связанный с ключом "blog:recent_posts", в кэше Redis с помощью метода IDatabase.ListLeftPushAsync.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
При чтении дополнительных сообщений в блогах их заголовки помещаются в этот же список. Список упорядочен по последовательности, в которой были добавлены заголовки. Недавно прочитанные записи блога располагаются ближе к левому концу списка. (Если одна и та же запись блога будет прочитана несколько раз, список будет содержать несколько таких записей.)
Отобразить названия недавно прочитанных записей можно с помощью метода IDatabase.ListRange . Этот метод получает ключ, который содержит список, начальную точку и конечную точку. Следующий код извлекает заголовки 10 записей блога (элементы от 0 до 9) в конце списка слева.
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Обратите внимание, что ListRangeAsync метод не удаляет элементы из списка. Для этого можно использовать методы IDatabase.ListLeftPopAsync и IDatabase.ListRightPopAsync.
Чтобы предотвратить бесконечный рост списка, вы может периодически исключать элементы, сокращая список. В следующем фрагменте кода показано, как удалить все элементы из списка, кроме пяти самых левых.
await cache.ListTrimAsync(redisKey, 0, 5);
Реализация "таблицы лидеров"
По умолчанию элементы в наборе не хранятся в определенном порядке. Упорядоченный набор можно создать с помощью команды ZADD (метод IDatabase.SortedSetAdd в библиотеке StackExchange). Элементы упорядочиваются с помощью числового значения, называемого оценкой, которое передается в качестве параметра команды.
В следующем фрагменте кода заголовок записи блога добавляется в упорядоченный список. В этом примере каждая запись блога также содержит поле оценки, содержащее ранг записи блога.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Вы можете получить записи блога и оценки по их возрастанию, используя метод IDatabase.SortedSetRangeByRankWithScores.
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Примечание.
Библиотека StackExchange также предоставляет IDatabase.SortedSetRangeByRankAsync метод, который возвращает данные в порядке оценки, но не возвращает оценки.
Можно извлекать элементы в порядке убывания оценок и ограничить число возвращаемых элементов, предоставляя дополнительные параметры в метод IDatabase.SortedSetRangeByRankWithScoresAsync. Следующий пример отображает заголовки и оценки 10 самых популярных записей в блогах.
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
В следующем примере применяется метод IDatabase.SortedSetRangeByScoreWithScoresAsync , который можно использовать для ограничения количества возвращаемых элементов только теми, которые попадают в данный диапазон оценок.
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Обмен сообщениями с использованием каналов
Помимо функционирования в качестве кэша данных сервер Redis обеспечивает обмен сообщениями через высокопроизводительный механизм "издатель-подписчик". Клиентские приложения могут подписываться на канал, и другие приложения или службы могут публиковать сообщения в этот канал. Подписанные приложения будут получать эти сообщения с возможностью последующей обработки.
Чтобы подписаться на канал, для клиентских приложений в Redis предусмотрена команда SUBSCRIBE. Эта команда получает имя одного или нескольких каналов, с которых приложение будет принимать сообщения. Библиотека StackExchange содержит интерфейс ISubscription, который позволяет приложению .NET Framework подписываться на каналы и публиковать в них сообщения.
Создать объект ISubscription можно с помощью метода GetSubscriber подключения к серверу Redis. Затем можно прослушивать сообщения по каналу с помощью метода SubscribeAsync этого объекта. В следующем примере кода показано, как подписаться на канал с именем "messages:blogPosts".
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Первый параметр метода Subscribe является именем канала. Это имя следует тем же правилам, что и используемые ключи в кэше. Имя может содержать любые двоичные данные, но мы рекомендуем использовать относительно короткие, значимые строки, чтобы обеспечить хорошую производительность и удобство обслуживания.
Следует отметить, что пространство имен, используемое каналами, отделено от такого же пространства, используемого ключами. Поэтому можно иметь каналы и ключи с одинаковыми именами, несмотря на то, что это может затруднить работу с кодом приложения.
Второй параметр — делегат Action. Этот делегат выполняется асинхронно при появлении нового сообщения по каналу. В этом примере сообщение просто отображается на консоль (сообщение будет содержать заголовок записи блога).
Чтобы опубликовать канал, приложение может использовать команду Redis PUBLISH. Для выполнения этой операции библиотека StackExchange предоставляет метод IServer.PublishAsync . В следующем фрагменте кода показан способ публикации сообщения в канал "messages: blogPosts".
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Существует несколько моментов, на которые необходимо обратить внимание, если речь идет о механизме публикации/подписки.
- Несколько подписчиков могут подписаться на один канал, и все они получат сообщения, опубликованные в этом канале.
- Подписчики получают только сообщения, опубликованные после подписки. Каналы не буферичены, и после публикации сообщения инфраструктура Redis отправляет сообщение каждому подписчику, а затем удаляет его.
- По умолчанию сообщения получаются подписчиками в том порядке, в котором они отправляются. В системе с высокой активностью с большим количеством сообщений и многими подписчиками и издателями гарантированная последовательная доставка сообщений может снизить производительность системы. Если каждое сообщение является независимым и порядок не имеет значения, можно включить параллельную обработку системой Redis, что может помочь повысить скорость реагирования. Этого можно добиться в клиенте StackExchange, установив параметр PreserveAsyncOrder соединения, используемого подписчиком, в значение false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Рекомендации по сериализации
При выборе формата сериализации важно правильно оценить компромиссы между производительностью, взаимодействием, управлением версиями, совместимостью с существующими системами, сжатием данных и затратами памяти. При оценке производительности помните, что тесты зависят от контекста. Они могут не соответствовать характеру реальной рабочей нагрузки или не охватывать новые библиотеки либо версии. Для всех сценариев нет единого сериализатора "быстрый".
Некоторые варианты, которые следует рассмотреть, включают в себя:
Protocol Buffers (protobuf) — это формат, разработанный Google для эффективной сериализации структурированных данных. В нем используются файлы определений со строгой типизацией для определения структур сообщений. Эти файлы определений компилируются в код определенного языка для сериализации и десериализации сообщений. Protobuf можно использовать поверх существующих механизмов RPC или создать с его помощью новую службу RPC.
В Apache Thrift используется аналогичный подход со строгой типизацией файлов определений и процессом компиляции, при помощи которого создается код сериализации и службы RPC.
Apache Avro предоставляет аналогичные функции буферов протокола и Thrift, но нет шага компиляции. Вместо этого во все сериализованные данные добавляется схема с описанием структуры.
В открытом стандарте JSON используются текстовые поля в понятном для человека формате. Он поддерживается множеством разных платформ. JSON не использует схемы сообщений. Будучи текстовым форматом, это не очень эффективно по проводу. Но иногда кэшированные элементы возвращаются напрямую клиенту по протоколу HTTP. В таком случае хранение в формате JSON позволит избежать затрат на десериализацию из другого формата с последующей сериализацией в JSON.
Для формата двоичной сериализации BSON используется структура, аналогичная JSON. Формат BSON проще, чем JSON, в обработке и просмотре и обеспечивает более высокую скорость сериализации и десериализации. Размер полезных данных примерно такой же, как для JSON. В зависимости от конкретных данных полезные данные BSON могут занять меньше или больше пространства, чем полезные данные JSON. BSON содержит некоторые дополнительные типы данных, которые недоступны в ФОРМАТЕ JSON, в частности BinData (для массивов байтов) и Date.
MessagePack — это формат двоичной сериализации, который обеспечивает компактность при передаче по сети. В нем не предусмотрены схемы сообщений и проверка их типа.
Bond — это кроссплатформенная платформа для работы со схематизированными данными. Она поддерживает межъязыковую сериализацию и десериализацию. Важные отличия от других систем из этого списка заключаются в поддержке наследования, псевдонимов типов и универсальных шаблонов.
gRPC представляет собой систему RPC с открытым кодом, которую разработала компания Google. По умолчанию она использует Protocol Buffers как язык определений и базовый формат обмена сообщениями.
Следующие шаги
- Документация по Кэшу Azure для Redis
- вопросы и ответы по Кэш Azure для Redis
- Асинхронная модель на основе задач
- Документация по Redis
- StackExchange.Redis
- Руководство по секционированию данных
Связанные ресурсы
Следующие шаблоны также могут относиться к сценариям реализации кэширования в приложениях:
Шаблон "Отдельно от кэша": данный шаблон описывает способ загрузки данных по требованию из хранилища данных в кэш. Этот шаблон также помогает поддерживать согласованность данных, хранящихся в кэше, и данных в хранилище исходных данных.
Шаблон сегментирования содержит сведения о реализации горизонтального секционирования для улучшения масштабируемости при хранении и доступе к большим объемам данных.