Настройка модели (предварительная версия 4.0)
Настройка модели позволяет обучить специализированную модель анализа изображений для собственного варианта использования. Пользовательские модели могут выполнять классификацию изображений (теги применяются ко всему изображению) или обнаружение объектов (теги применяются к определенным областям изображения). После создания и обучения пользовательской модели он принадлежит ресурсу Визуального распознавания, и его можно вызвать с помощью API анализа изображений.
Быстро и легко реализуйте настройку модели, выполнив краткое руководство.
Важно!
Вы можете обучить пользовательскую модель с помощью службы Пользовательское визуальное распознавание или службы анализа изображений 4.0 с настройкой модели. В следующей таблице сравниваются две службы.
| Области | Пользовательское визуальное распознавание | Служба анализа изображений 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Задачи | Обнаружение объектов классификацииизображений | Обнаружение объектов классификацииизображений | ||||||||||||||||||||||||||||||||||||
| Базовая модель | CNN | Модель преобразователя | ||||||||||||||||||||||||||||||||||||
| Добавление меток | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Веб-портал | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Библиотеки | REST, SDK | REST, пример Python | ||||||||||||||||||||||||||||||||||||
| Минимальные необходимые данные для обучения | 15 изображений на категорию | 2–5 изображений на категорию | ||||||||||||||||||||||||||||||||||||
| Хранилище данных обучения | Отправлено в службу | Учетная запись хранения BLOB-объектов клиента | ||||||||||||||||||||||||||||||||||||
| Размещение моделей | Облако и edge | Только облачное размещение, размещение пограничных контейнеров для получения | ||||||||||||||||||||||||||||||||||||
| Качество ИИ |
|
|
||||||||||||||||||||||||||||||||||||
| Цены | Цены на Пользовательское визуальное распознавание | Цены на анализ изображений |
Компоненты сценария
Основными компонентами системы настройки модели являются обучающие образы, COCO-файл, объект набора данных и объект модели.
Обучающие образы
Набор обучающих изображений должен содержать несколько примеров каждой метки, которую вы хотите обнаружить. Вы также хотите собрать несколько дополнительных изображений, чтобы протестировать модель после его обучения. Образы должны храниться в контейнере служба хранилища Azure, чтобы быть доступными для модели.
Чтобы обучение модели было эффективным, используйте разнообразные изображения. Изображения должны отличаться по следующим аспектам:
- угол обзора камеры;
- освещение;
- background
- стиль изображения;
- отдельные объекты и группы;
- size
- type
Также убедитесь, что все обучающие изображения соответствуют следующим критериям:
- Изображение должно быть представлено в формате JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF или MPO.
- Размер файла изображения должен быть меньше 20 мегабайт (МБ).
- Размеры изображения должны превышать 50 x 50 пикселей и менее 16 000 x 16 000 пикселей.
COCO-файл
Файл COCO ссылается на все обучающие образы и связывает их с информацией о метках. В случае обнаружения объектов он указал координаты ограничивающего прямоугольника каждого тега на каждом изображении. Этот файл должен быть в формате COCO, который является определенным типом JSON-файла. Файл COCO должен храниться в том же контейнере служба хранилища Azure, что и образы обучения.
Совет
Сведения о файлах COCO
ФАЙЛЫ COCO — это JSON-файлы с определенными обязательными полями: "images"и "annotations""categories". Пример COCO-файла будет выглядеть следующим образом:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Справочник по полю файла COCO
Если вы создаете собственный COCO-файл с нуля, убедитесь, что все необходимые поля заполнены правильными сведениями. В следующих таблицах описано каждое поле в COCO-файле:
"изображения"
| Ключ. | Тип | Описание | Обязательное? |
|---|---|---|---|
id |
integer | Уникальный идентификатор изображения, начиная с 1 | Да |
width |
integer | Ширина изображения в пикселях | Да |
height |
integer | Высота изображения в пикселях | Да |
file_name |
строка | Уникальное имя изображения | Да |
absolute_url или coco_url |
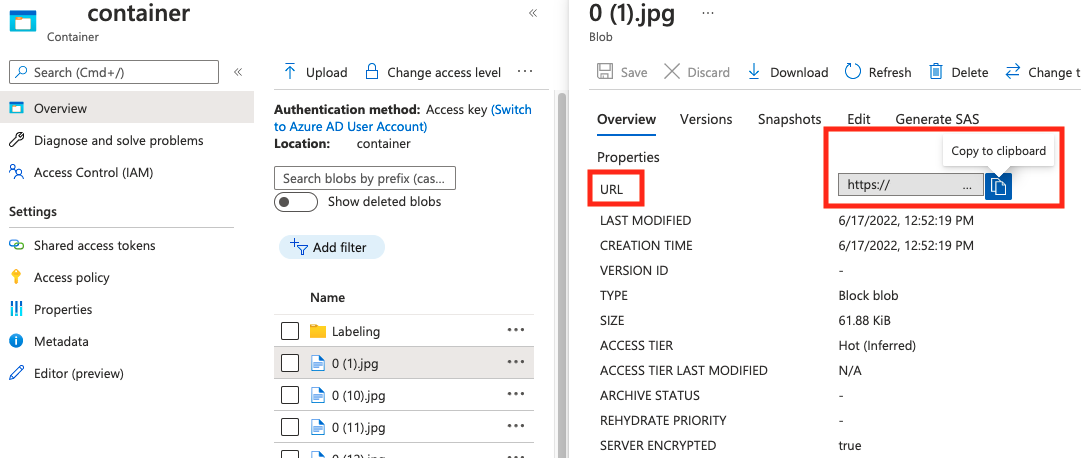
строка | Путь к изображению в качестве абсолютного URI для большого двоичного объекта в контейнере BLOB-объектов. Ресурс визуального зрения должен иметь разрешение на чтение файлов заметок и всех ссылочных файлов изображений. | Да |
Значение для absolute_url этого можно найти в свойствах контейнера BLOB-объектов:
"заметки"
| Ключ. | Тип | Описание | Обязательное? |
|---|---|---|---|
id |
integer | Идентификатор заметки | Да |
category_id |
integer | Идентификатор категории, определенной categories в разделе |
Да |
image_id |
integer | Идентификатор изображения | Да |
area |
integer | Значение "Width" x "Height" (третье и четвертое значения bbox) |
No |
bbox |
list[float] | Относительные координаты ограничивающего поля (от 0 до 1), в порядке "слева", "Сверху", "Ширина", "Высота" | Да |
"категории"
| Ключ. | Тип | Описание | Обязательное? |
|---|---|---|---|
id |
integer | Уникальный идентификатор для каждой категории (класс меток). Они должны присутствовать в annotations разделе. |
Да |
name |
строка | Имя категории (класс метки) | Да |
Проверка файлов COCO
Пример кода Python можно использовать для проверка формата COCO-файла.
Объект набора данных
Объект набора данных представляет собой структуру данных, хранящуюся службой анализа изображений, которая ссылается на файл сопоставления. Перед созданием и обучением модели необходимо создать объект набора данных.
Объект модели
Объект Model — это структура данных, хранящаяся службой анализа изображений, представляющей пользовательскую модель. Он должен быть связан с набором данных, чтобы выполнить начальное обучение. После обучения вы можете запросить модель, введя его имя в model-name параметре запроса вызова API анализа изображений.
Квоты
В следующей таблице описываются ограничения масштаба проектов пользовательской модели.
| Категория | Универсальный классификатор изображений | Универсальный детектор объектов |
|---|---|---|
| Максимальное число часов обучения # | 288 (12 дней) | 288 (12 дней) |
| Максимальное число изображений для обучения | 1 000 000 | 200 000 |
| Максимальное число образов оценки # | 100,000 | 100,000 |
| Мин # обучающие изображения для каждой категории | 2 | 2 |
| Максимальное число тегов # на изображение | multiclass: 1 | Неприменимо |
| Максимальное число регионов на изображение | Неприменимо | 1,000 |
| Максимальное число категорий # | 2500 | 1,000 |
| Категории Min # | 2 | 1 |
| Максимальный размер изображения (обучение) | 20 МБ | 20 МБ |
| Максимальный размер изображения (прогнозирование) | Синхронизация: 6 МБ, пакетная служба: 20 МБ | Синхронизация: 6 МБ, пакетная служба: 20 МБ |
| Максимальная ширина и высота изображения (обучение) | 10 240 | 10 240 |
| Минимальная ширина или высота изображения (прогнозирование) | 50 | 50 |
| Доступные регионы | Западная часть США 2, восточная часть США, Западная Европа | Западная часть США 2, восточная часть США, Западная Европа |
| Принимаемые типы изображений | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Часто задаваемые вопросы
Почему при импорте файла COCO происходит сбой при импорте из хранилища BLOB-объектов?
В настоящее время корпорация Майкрософт решает проблему, которая приводит к сбою импорта файлов COCO с большими наборами данных при запуске в Vision Studio. Чтобы обучить использование большого набора данных, рекомендуется использовать REST API.
Почему обучение занимает больше времени или меньше, чем мой указанный бюджет?
Указанный бюджет обучения — это откалиброванное время вычислений, а не время настенные часы. Перечислены некоторые распространенные причины разницы:
Длиннее указанного бюджета:
- Анализ изображений обеспечивает высокий трафик обучения, а ресурсы GPU могут быть жесткими. Ваше задание может ждать в очереди или удерживаться во время обучения.
- Процесс обучения серверной части столкнулся с непредвиденными сбоями, что привело к повторным попыткам логики. Неудачные запуски не используют бюджет, но это может привести к длительному времени обучения в целом.
- Данные хранятся в другом регионе, отличном от ресурса Визуального зрения, что приведет к более длительной передаче данных.
Короче указанного бюджета: следующие факторы ускоряют обучение по стоимости использования большего бюджета в определенное время.
- Анализ изображений иногда обучается с несколькими GPU в зависимости от данных.
- Анализ изображений иногда обучает несколько пробных версий исследования на нескольких GPU одновременно.
- Анализ изображений иногда использует SKU GPU premier (быстрее) для обучения.
Почему мое обучение завершается ошибкой и что я должен сделать?
Ниже приведены некоторые распространенные причины сбоя обучения:
diverged: обучение не может научиться значимым вещам из ваших данных. Ниже приведены некоторые распространенные причины.- Недостаточно данных: предоставление дополнительных данных должно помочь.
- Данные имеют плохое качество: проверка, если изображения имеют низкое разрешение, крайние пропорции или если заметки неверны.
notEnoughBudget: указанный бюджет недостаточно для размера набора данных и типа модели, который вы обучаете. Укажите больший бюджет.datasetCorrupt: обычно это означает, что предоставленные изображения недоступны или файл заметки находится в неправильном формате.datasetNotFound: не удается найти набор данныхunknown: это может быть проблема серверной части. Обратитесь к поддержке расследования.
Какие метрики используются для оценки моделей?
Используются следующие метрики:
- Классификация изображений: средняя точность, точность 1, точность топ 5
- Обнаружение объектов: средняя точность @ 30, средняя средняя точность @ 50, средняя точность @ 75
Почему регистрация набора данных завершается ошибкой?
Ответы API должны быть достаточно информативными. В их число входят:
DatasetAlreadyExists: набор данных с тем же именем существуетDatasetInvalidAnnotationUri: "Недопустимый URI был предоставлен среди URI заметки во время регистрации набора данных.
Сколько изображений требуется для разумного/ хорошего или лучшего качества модели?
Несмотря на то, что модели Флоренции обладают большим количеством снимков (достижение высокой производительности модели в условиях ограниченной доступности данных), в целом больше данных делает обученную модель более эффективной и более надежной. В некоторых сценариях требуется мало данных (например, классификация яблока против банана), но другие требуют больше (например, обнаружение 200 видов насекомых в тропических лесах). Это затрудняет предоставление одной рекомендации.
Если бюджет маркировки данных ограничен, рекомендуемый рабочий процесс — повторить следующие действия:
Сбор
Nизображений на класс, гдеNможно легко собирать изображения (например,N=3)Обучите модель и протестируйте ее в наборе оценки.
Если производительность модели :
- Достаточно хорошо (производительность лучше, чем ваше ожидание или производительность близко к предыдущему эксперименту с меньшим объемом собранных данных): остановите здесь и используйте эту модель.
- Не хорошо (производительность по-прежнему ниже ожиданий или лучше, чем предыдущий эксперимент с меньшим количеством данных, собранных по разумному краю):
- Соберите больше изображений для каждого класса — число, которое легко собрать, и вернитесь к шагу 2.
- Если вы заметили, что производительность больше не улучшается после нескольких итераций, это может быть потому, что:
- эта проблема не определена или слишком сложна. Обратитесь к нам за анализом по регистру.
- Данные обучения могут быть низким качеством: проверка, если есть неправильные заметки или очень низко пиксельные изображения.
Сколько бюджета обучения следует указать?
Необходимо указать верхний предел бюджета, который вы готовы использовать. Анализ изображений использует систему AutoML в серверной части, чтобы попробовать различные модели и рецепты обучения, чтобы найти лучшую модель для вашего варианта использования. Чем больше бюджет, тем выше вероятность поиска лучшей модели.
Система AutoML также останавливается автоматически, если она завершает попытку больше, даже если остается бюджет. Таким образом, он не всегда исчерпает указанный бюджет. Вы гарантированно не будете выставлены счета за указанный бюджет.
Можно ли управлять гиперпараметров или использовать собственные модели в обучении?
Нет, служба настройки модели анализа изображений использует систему обучения AutoML с низким кодом, которая обрабатывает поиск гипер-парам и выбор базовой модели в серверной части.
Можно ли экспортировать модель после обучения?
API прогнозирования поддерживается только через облачную службу.
Почему оценка завершается ошибкой для модели обнаружения объектов?
Ниже приведены возможные причины:
internalServerError: произошла неизвестная ошибка. Повторите попытку позже.modelNotFound: указанная модель не найдена.datasetNotFound: указанный набор данных не найден.datasetAnnotationsInvalid: произошла ошибка при попытке скачать или проанализировать заметки о действительности, связанные с тестируемым набором данных.datasetEmpty: тестовый набор данных не содержал никаких заметок "земная истина".
Какова ожидаемая задержка прогнозов с пользовательскими моделями?
Мы не рекомендуем использовать пользовательские модели для критически важных для бизнеса сред из-за потенциально высокой задержки. Когда клиенты обучают пользовательские модели в Vision Studio, эти пользовательские модели принадлежат ресурсу Azure AI Vision, которому они были обучены, и клиент может вызывать эти модели с помощью API анализа изображений . При выполнении этих вызовов пользовательская модель загружается в память и инициализирует инфраструктуру прогнозирования. Хотя это происходит, клиенты могут столкнуться с большей задержкой для получения результатов прогнозирования.
Конфиденциальность и безопасность данных
Как и во всех службах ИИ Azure, разработчики, использующие настройку модели анализа изображений, должны учитывать политики Майкрософт по данным клиентов. Дополнительные сведения см. на странице служб ИИ Azure в Центре управления безопасностью Майкрософт.