Перенос сотен терабайт данных в Azure Cosmos DB
ПРИМЕНИМО К:![]() Nosql
Nosql![]() Mongodb
Mongodb![]() Кассандра
Кассандра![]() Гремлин
Гремлин![]() Таблица
Таблица
Azure Cosmos DB может хранить терабайты данных. Вы можете выполнить крупномасштабную миграцию данных, чтобы переместить рабочую нагрузку в Azure Cosmos DB. В этой статье описаны проблемы, связанные с крупномасштабным перемещением данных в Azure Cosmos DB, а также представлено средство, которое помогает устранять проблемы и переносить данные в Azure Cosmos DB. В этом примере клиент использовал API Azure Cosmos DB для NoSQL.
Перед переносом всей рабочей нагрузки в Azure Cosmos DB можно выполнить миграцию подмножества данных для проверки некоторых аспектов, например выбора ключа секции, производительности запросов и моделирования данных. После проверки подтверждения концепции можно переместить всю рабочую нагрузку в Azure Cosmos DB.
Средства для переноса данных
Стратегии миграции Azure Cosmos DB в настоящее время различаются в зависимости от выбора API и размера данных. Для переноса небольших наборов данных ( для проверки моделирования данных, производительности запросов, выбора ключа секции и т. д.) можно использовать соединитель Azure Cosmos DB Фабрика данных Azure. Если вы знакомы со Spark, можно также использовать соединитель Azure Cosmos DB Spark для переноса данных.
Трудности при крупномасштабных миграциях
Существующие средства для переноса данных в Azure Cosmos DB имеют некоторые ограничения, которые становятся особенно заметными при больших масштабах:
Ограниченные возможности масштабирования: для максимально быстрого переноса многих терабайт данных в Azure Cosmos DB и для эффективного использования всей подготовленной пропускной способности клиенты миграции должны иметь возможность горизонтального масштабирования.
Отсутствие отслеживания хода выполнения и контрольных точек: важно отслеживать ход выполнения миграции, а также использовать при переносе больших наборов данных контрольные точки. В противном случае любая ошибка, возникающая во время миграции, приведет к прерыванию миграции, и процесс придется начать с нуля. Было бы очень нерационально перезапускать весь процесс миграции, например, когда завершено уже 99 %.
Отсутствие очереди недоставленных сообщений: в больших наборах данных в некоторых случаях могут возникнуть проблемы с частями исходных данных. Кроме того, могут возникать временные проблемы с клиентом или сетью. Любой из этих случаев не должен приводить к сбою всей миграции. Хотя большинство средств миграции обладают надежными средствами осуществления повторных попыток, которые защищены от периодических проблем, этого не всегда достаточно. Например, если менее 0,01 % документов исходных данных имеет размер свыше 2 МБ, это приведет к сбою записи документа в Azure Cosmos DB. В идеале полезно, чтобы средство миграции сохраняло сбойные документы в отдельной очереди недоставленных сообщений, которая может быть обработана после миграции.
Многие из этих ограничений исправляются для таких средств, как Фабрика данных Azure, службы миграции данных Azure.
Пользовательский инструмент с библиотекой исполнителя массовых операций
Проблемы, описанные в приведенном выше разделе, можно решить с помощью пользовательского инструмента, который можно легко масштабировать между несколькими экземплярами, и этот инструмент является устойчивым ко временным сбоям. Кроме того, пользовательское средство может приостанавливать и возобновлять миграцию на различных контрольных точках. Azure Cosmos DB уже предоставляет библиотеку исполнителя массовых операций, в которой содержатся некоторые из этих функций. Например, библиотека исполнителя массовых операций уже имеет функции для обработки временных ошибок и может масштабировать потоки на одном узле для использования примерно 500 тыс. единиц запросов на каждый узел. Библиотека исполнителя массовых операций также разделяет исходный набор данных на микропакеты, которые работают независимо в виде контрольных точек.
Настраиваемое средство использует библиотеку исполнителя массовых операций, поддерживает масштабирование на нескольких клиентах и следит за ошибками в процессе приема. Для использования этого средства исходные данные должны быть разделены на отдельные файлы в Azure Data Lake Storage (ADLS), чтобы различные рабочие процессы миграции могли выбирать отдельные файлы и принимать их в Azure Cosmos DB. Пользовательский инструмент использует отдельную коллекцию, в которой хранятся метаданные о ходе миграции для каждого отдельного исходного файла в ADLS и отслеживаются все ошибки, связанные с ними.
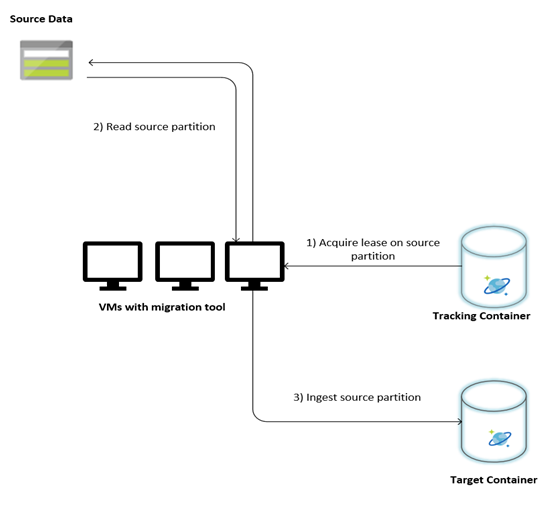
На следующем изображении описан процесс миграции с помощью этого пользовательского инструмента. Средство выполняется на наборе виртуальных машин, и каждая виртуальная машина запрашивает сбор данных отслеживания в Azure Cosmos DB, чтобы получить аренду одной из секций с исходными данными. После этого исходный раздел данных считывается средством и принимается в Azure Cosmos DB с помощью библиотеки исполнителя массовых операций. Далее обновляется коллекция отслеживания для записи хода приема данных и обнаруженных ошибок. После обработки секции данных средство пытается запросить следующую доступную исходную секцию. Обработка следующей исходной секции будет продолжена до тех пор, пока не будут перенесены все данные. Исходный код для средства доступен в репозитории массового приема Azure Cosmos DB.
Коллекция отслеживания содержит документы, как показано в следующем примере. Вы увидите такие документы по одному для каждой секции в исходных данных. Каждый документ содержит метаданные для секции источника данных, например расположение, состояние миграции и ошибки (если они есть):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Предварительные требования для миграции данных
Прежде чем начать перенос данных, необходимо выполнить несколько предварительных условий.
Оценка объема данных
Исходный размер данных может не в точности соответствовать размеру данных в Azure Cosmos DB. Чтобы проверить размер данных в Azure Cosmos DB, можно вставить несколько примеров документов из источника. В зависимости от размера образца документа можно оценить общий размер данных в Azure Cosmos DB после миграции.
Например, если каждый документ после миграции в Azure Cosmos DB имеет размер около 1 КБ и в исходном наборе данных имеется около 60 000 000 000 документов, это означает, что предполагаемый размер в Azure Cosmos DB будет близок к 60 ТБ.
Предварительно создайте контейнеры с достаточным количеством получателей:
Хотя Azure Cosmos DB масштабирует хранилище автоматически, не рекомендуется начинать с наименьшего размера контейнера. Контейнеры меньшего размера имеют меньшую доступность по пропускной способности, что означает, что миграция займет значительно больше времени. Вместо этого полезно создать контейнеры с окончательным размером данных (как показано на предыдущем шаге) и убедиться, что рабочая нагрузка миграции полностью потребляет подготовленную пропускную способность.
На предыдущем шаге. Так как размер данных приблизительно составляет около 60 ТБ, для размещения всего набора данных требуется контейнер по крайней мере 2,4 млн ЕЗ.
Оцените скорость миграции:
При условии, что рабочая нагрузка миграции может потреблять всю подготовленную пропускную способность, этот показатель позволит оценить скорости миграции. Продолжая предыдущий пример, для записи документа размером 1 КБ в учетную запись API Azure Cosmos DB для NoSQL требуется 5 ЕЗ. 2,4 млн ЕЗ обеспечивает передачу 480 000 документов в секунду (или 480 Мбит/с). Это означает, что полная миграция 60 ТБ займет 125 000 секунд или около 34 часов.
Если требуется, чтобы миграция была выполнена в течение одного дня, необходимо увеличить подготовленную пропускную способность до 5 000 000 ЕЗ.
Выключение индексации.
Так как миграция должна быть выполнена как можно скорее, рекомендуется максимально сокращать затраты времени и ЕЗ на создание индексов для каждого из полученных документов. Azure Cosmos DB индексирует все свойства автоматически, поэтому стоит по меньшей мере выполнить индексирование до выбранных нескольких терминов или полностью отключить индексацию в процессе миграции. Политику индексирования контейнера можно отключить, изменив параметр indexingMode задано на "none", как показано ниже.
{
"indexingMode": "none"
}
После завершения миграции можно удалить экземпляр Azure Database Migration Service.
Процесс миграции
После завершения предварительных требований можно выполнить миграцию данных, выполнив следующие действия.
Сначала импортируйте данные из источника в Хранилище BLOB-объектов Azure. Чтобы увеличить скорость миграции, рекомендуется обеспечить параллельное выполнение между различными исходными секциями. Перед началом миграции исходный набор данных должен быть разбит на файлы размером около 200 МБ.
Библиотеку исполнителя массовых операций можно масштабировать, чтобы использовать 500 000 ЕЗ в одной клиентской виртуальной машине. Так как доступная пропускная способность составляет 5 миллионов ЕЗ, 10 виртуальных машин Ubuntu 16.04 (Standard_D32_v3) должны быть подготовлены в том же регионе, где находится база данных Azure Cosmos DB. Необходимо подготовить эти виртуальные машины с помощью средства миграции и файла параметров.
Выполните шаг очереди на одной из клиентских виртуальных машин. На этом шаге создается коллекция отслеживания, которая сканирует контейнер ADLS и создает документ отслеживания хода выполнения для каждого из файлов секции исходного набора данных.
Затем выполните шаг импорта на всех клиентских виртуальных машинах. Каждый из клиентов может стать владельцем исходной секции и принимать свои данные в Azure Cosmos DB. После завершения работы и обновления состояния в коллекции отслеживания клиенты смогут запрашивать следующую доступную исходную секцию в коллекции отслеживания.
Этот процесс будет продолжаться до тех пор, пока не будет получен весь набор исходных секций. После обработки всех исходных секций средство следует перезапустить в режиме исправления ошибок в той же коллекции отслеживания. Этот шаг необходим для обнаружения исходных секций, которые должны быть повторно обработаны из-за ошибок.
Некоторые из этих ошибок могут быть вызваны неверными документами в исходных данных. Их необходимо идентифицировать и исправить. Затем следует повторно запустить шаг импорта в секциях, где произошел сбой.
После завершения миграции можно проверить, что количество документов в Azure Cosmos DB совпадает с количеством документов в базе данных-источнике. В этом примере общий размер Azure Cosmos DB исключается до 65 ТБ. После миграции можно выборочно включить индексирование, а также уменьшить уровень, требуемый для операций рабочей нагрузки.
Дальнейшие действия
- Ознакомьтесь с примерами приложений, использующими библиотеку исполнителя массовых операций, в статьях для .NET и для Java.
- Библиотека исполнителя массовых операций интегрирована в соединитель Spark для Azure Cosmos DB. Дополнительные сведения см. в статье Соединитель Spark для Azure Cosmos DB .
- Обратитесь к группе разработчиков Azure Cosmos DB, открыв запрос в службу поддержки в подтипе проблем "Общие рекомендации" и "Крупные (ТБ+) миграции" для получения дополнительной справки о крупномасштабных миграциях.
- Пытаетесь выполнить планирование ресурсов для миграции на Azure Cosmos DB? Можете использовать для этого сведения о существующем кластере базы данных.
- Если вам известно только количество виртуальных ядер и серверов в существующем кластере баз данных, прочитайте об оценке единиц запроса на основе этих данных.
- Если вам известна стандартная частота запросов для текущей рабочей нагрузки базы данных, ознакомьтесь со статьей о расчете единиц запросов с помощью планировщика ресурсов Azure Cosmos DB