Управление индексированием в Azure Cosmos DB для MongoDB
Область применения: ![]() Mongodb
Mongodb
Azure Cosmos DB для MongoDB использует основные возможности управления индексами Azure Cosmos DB. В этой статье рассматривается добавление индексов с помощью Azure Cosmos DB для MongoDB. Индексы — это специализированные структуры данных, которые ускоряют обработку запросов к данным в порядке их величины.
Индексирование для сервера MongoDB версии 3.6 и более поздних версий
Azure Cosmos DB для сервера MongoDB версии 3.6+ автоматически индексирует _id поле и ключ сегментов (только в сегментированных коллекциях). API автоматически обеспечивает уникальность поля _id для каждого ключа сегмента.
API для MongoDB работает по-разному от Azure Cosmos DB для NoSQL, который индексирует все поля по умолчанию.
Изменение политики индексирования
Для изменения политики индексирования рекомендуется использовать обозреватель данных на портале Azure. В обозревателе данных можно добавить отдельные поля и индексы с подстановочными знаками из редактора политики индексирования:
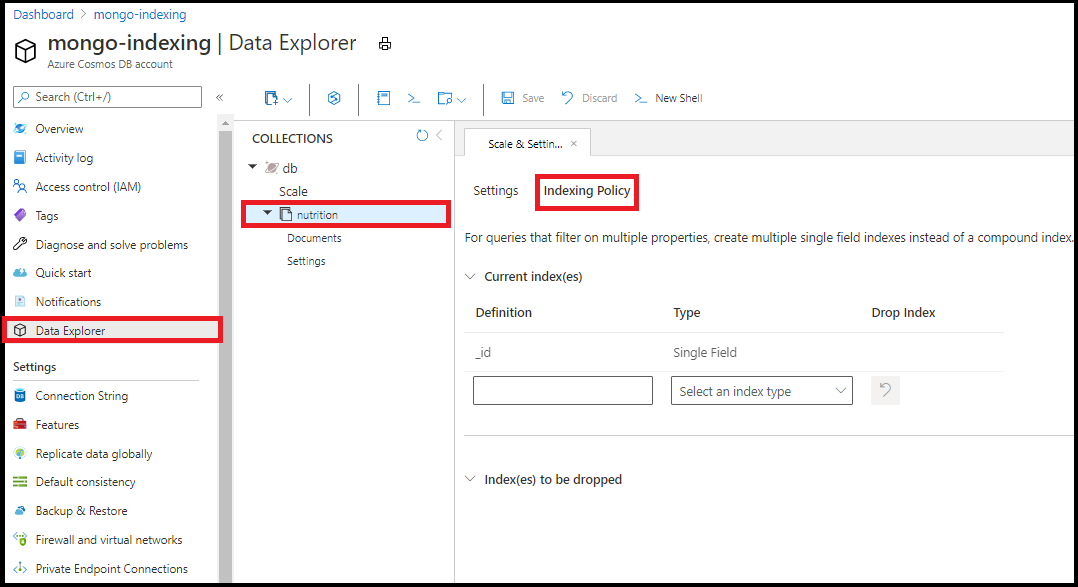
Примечание.
Создавать составные индексы с помощью редактора политики индексирования в обозревателе данных нельзя.
Типы индексов
По одному полю
Индекс можно создать для любого отдельного поля. Порядок сортировки индекса по одному полю не имеет значения. Следующая команда создает уникальный индекс для поля name:
db.coll.createIndex({name:1})
Такой же индекс одного поля по полю name можно создать и на портале Azure:
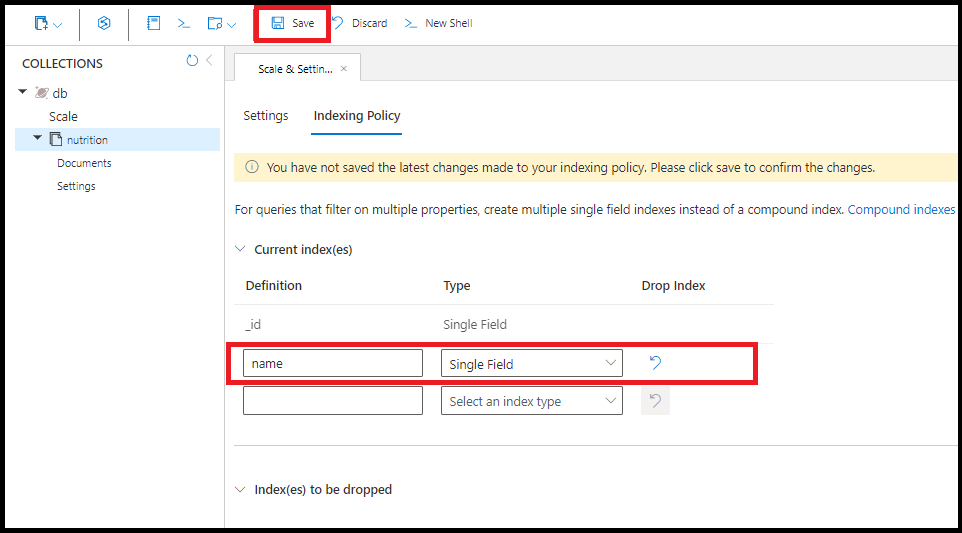
Один запрос использует несколько индексов по одному полю, где это возможно. Для одной коллекции можно создать до 500 индексов в одном поле.
Составные индексы (MongoDB Server версии 3.6 и более поздних)
В API для MongoDB составные индексы необходимы, если запросу нужна возможность одновременной сортировки по нескольким полям. Для запросов с несколькими фильтрами, которые не требуют сортировки, вместо одного составного индекса следует создавать несколько индексов по одному полю, чтобы сэкономить на затратах на индексирование.
Составной индекс или индексы одного поля для каждого поля в составном индексе приводят к одинаковой производительности фильтрации в запросах.
Составные индексы в вложенных полях по умолчанию не поддерживаются из-за ограничений массивов. Если вложенное поле не содержит массив, индекс работает должным образом. Если вложенное поле содержит массив (в любом месте пути), это значение игнорируется в индексе.
Например, составной индекс, содержащий people.dylan.age в данном случае, работает, так как в пути нет массива:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Этот же составной индекс не работает в этом случае, так как в пути есть массив:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Эту функцию можно включить для учетной записи базы данных, включив функцию EnableUniqueCompoundNestedDocs.
Примечание.
Не удается создать составные индексы массивов.
Следующая команда создает составной индекс по полям name и age:
db.coll.createIndex({name:1,age:1})
Составные индексы можно использовать для эффективной сортировки по нескольким полям одновременно, как показано в следующем примере:
db.coll.find().sort({name:1,age:1})
Предыдущий составной индекс также можно использовать для эффективной сортировки в запросе с противоположным порядком сортировки по всем полям. Приведем пример:
db.coll.find().sort({name:-1,age:-1})
Однако последовательность путей в составном индексе должна точно соответствовать запросу. Ниже приведен пример запроса, для которого требуется дополнительный составной индекс:
db.coll.find().sort({age:1,name:1})
Многоключевые индексы
Для индексирования содержимого, хранящегося в массивах, Azure Cosmos DB создает многоключевые индексы. При индексировании поля со значением массива Azure Cosmos DB автоматически индексирует каждый элемент этого массива.
Геопространственные индексы
Многие геопространственные операторы работают эффективнее с геопространственными индексами. В настоящее время Azure Cosmos DB для MongoDB поддерживает 2dsphere индексы. Этот API пока не поддерживает индексы 2d.
Ниже приведен пример создания геопространственного индекса по полю location.
db.coll.createIndex({ location : "2dsphere" })
Текстовые индексы
Azure Cosmos DB для MongoDB в настоящее время не поддерживает текстовые индексы. Для запросов поиска текста в строках следует использовать интеграцию поиска ИИ Azure с Azure Cosmos DB.
Индексы с подстановочными знаками
Для запросов к неизвестным полям можно использовать индексы с подстановочными знаками. Предположим, у вас есть коллекция, содержащая данные о семьях.
Вот пример части документа, который может входить в такую коллекцию:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Вот еще один пример с несколько иным набором свойств в children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
В этой коллекции у документов могут иметь разные свойства. Если требуется проиндексировать все данные в массиве children, существует два варианта: создать отдельные индексы для каждого отдельного свойства или один индекс с подстановочными знаками для всего массива children.
Создание индекса с подстановочными знаками
Следующая команда создает индекс с подстановочными знаками для всех свойств children:
db.coll.createIndex({"children.$**" : 1})
В отличие от MongoDB, индексы с подстановочными знаками могут поддерживать несколько полей в предикатах запросов. При использовании одного индекса с подстановочными знаками вместо создания отдельного индекса для каждого свойства различия в производительности запросов не будет.
С использованием синтаксиса с подстановочными знаками можно создавать следующие типы индексов:
- По одному полю
- Геопространственные данные
Индексирование всех свойств
Вот как создать индекс с подстановочными знаками для всех полей:
db.coll.createIndex( { "$**" : 1 } )
Индексы с подстановочными знаками также можно создавать в обозревателе данных на портале Azure:
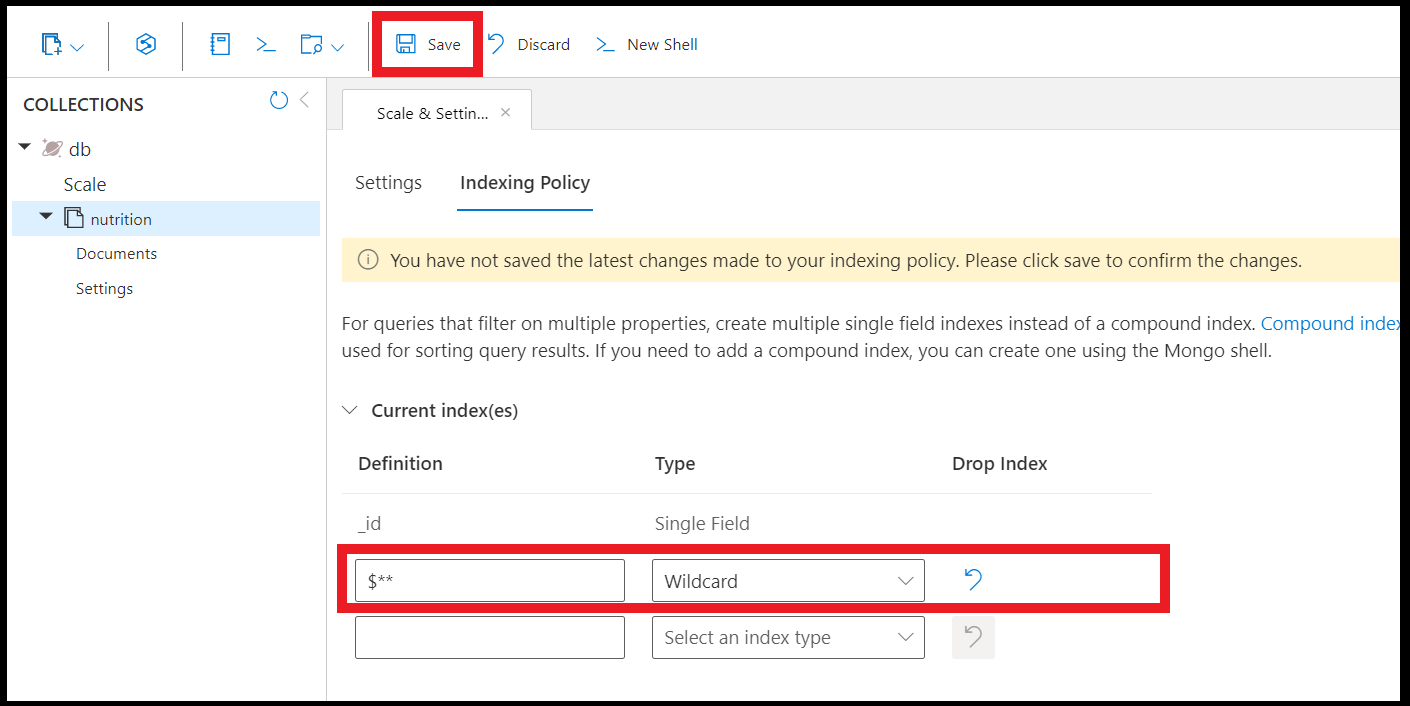
Примечание.
Если вы только начинаете разработку, мы настоятельно рекомендуем начинать с создания индекса с подстановочными знаками для всех полей. Это упростит разработку и оптимизацию запросов.
В документах с множеством полей стоимость в единицах запросов (ЕЗ) для операций записи и обновления может быть высокой. Поэтому при наличии рабочей нагрузки с интенсивными операциями записи вместо использования индексов с подстановочными знаками следует индексировать пути по отдельности.
Примечание.
Поддержка уникального индекса существующих коллекций с данными доступна в предварительной версии. Эту функцию можно включить для учетной записи базы данных, включив функцию EnableUniqueIndexReIndex.
Ограничения
Индексы с подстановочными знаками не поддерживают ни один из следующих типов или свойств индексирования:
- Составные
- СРОК ЖИЗНИ
- Уникальная идентификация
В отличие от MongoDB, в Azure Cosmos DB для MongoDB нельзя использовать дикие индексы карта для:
создания индекса с подстановочными знаками, содержащего несколько конкретных полей;
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )создания индекса с подстановочными знаками, не содержащего несколько конкретных полей.
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
В качестве альтернативы можно создать несколько индексов с подстановочными знаками.
Свойства индекса
Перечисленные ниже операции широко используются в учетных записях, обслуживающих протокол wire версии 4.0 и более ранних версий. Вы можете узнать больше о поддерживаемых индексах и индексируемых свойствах из этой статьи.
Уникальные индексы
Уникальные индексы позволяют гарантировать, что никакие два или несколько документов не будут содержать одинаковые значения для индексированных полей.
Следующая команда создает уникальный индекс для поля student_id:
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
Чтобы создать уникальный индекс для сегментированных коллекций, необходимо указывать ключ сегмента (секции). Другими словами, все уникальные индексы в сегментированной коллекции являются составными индексами, где одно из полей является ключом сегментов. Первое поле в порядке должно быть ключом сегментов.
Следующие команды создают сегментированную коллекцию coll (ключ сегмента — university) с уникальным индексом для полей student_id и university:
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
Если в предыдущем примере опустить предложение "university":1, будет возвращена ошибка со следующим сообщением:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Ограничения
Необходимо создать уникальные индексы, пока коллекция пуста.
Уникальные индексы в вложенных полях по умолчанию не поддерживаются из-за ограничений массивов. Если вложенное поле не содержит массив, индекс будет работать должным образом. Если вложенное поле содержит массив (в любом месте пути), это значение будет игнорироваться в уникальном индексе и уникальности не будет сохранено для этого значения.
Например, уникальный индекс для people.tom.age будет работать в этом случае, так как в пути нет массива:
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
но не будет работать в этом случае, так как в пути есть массив:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Эту функцию можно включить для учетной записи базы данных, включив функцию EnableUniqueCompoundNestedDocs.
Индексы срока жизни
Чтобы настроить истечение срока действия документов в определенной коллекции, необходимо создать индекс срока жизни (TTL). Индекс TTL — это индекс по полю _ts со значением expireAfterSeconds.
Пример:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
Предыдущая команда удаляет все документы коллекции db.coll, которые не менялись последние 10 секунд.
Примечание.
Поле _ts характерно для Azure Cosmos DB и недоступно из клиентов MongoDB. Это зарезервированное (системное) свойство, содержащее метку времени последнего изменения документа.
Отслеживание хода индексирования
Версия 3.6 для Azure Cosmos DB для MongoDB поддерживает currentOp() команду для отслеживания хода выполнения индекса в экземпляре базы данных. Эта команда возвращает документ, содержащий сведения о выполняемых операциях в экземпляре базы данных. Команда currentOpиспользуется для отслеживания всех выполняемых операций во встроенной среде MongoDB. В Azure Cosmos DB для MongoDB эта команда поддерживает отслеживание операции индекса.
Вот несколько примеров, демонстрирующих использование команды currentOp для отслеживания хода индексирования.
Получение хода индексирования для коллекции:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Получение хода индексирования для всех коллекций в базе данных:
db.currentOp({"command.$db": <databaseName>})Получите ход выполнения индекса для всех баз данных и коллекций в учетной записи Azure Cosmos DB:
db.currentOp({"command.createIndexes": { $exists : true } })
Примеры выходных данных индексирования
В сведениях о ходе индексирования отображается процент выполнения текущей операции индексирования. Приведен пример выходного документа для различных этапов индексирования.
Для операции индексирования для коллекции "foo" и базы данных "bar", которая выполнена на 60 %, будет возвращены следующие выходные данные. В поле
Inprog[0].progress.totalв качестве целевого процента выполнения отображается значение 100.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Если операция индексирования для коллекции "foo" и базы данных "bar" только началась, в выходном документе может отображаться 0 % выполнения, пока не будет достигнут минимальный уровень.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }При завершении текущей операции индексирования в выходных данных отображаются пустые операции
inprog.{ "inprog" : [], "ok" : 1 }
Фоновое обновление индекса
Независимо от значения, указанного для свойства Background индекса, обновления индекса всегда выполняются в фоновом режиме. Поскольку обновления индекса потребляют единицы запросов (ЕЗ) с более низким приоритетом по сравнению с другими операциями базы данных, изменения индекса не будут приводить к простою операций записи, обновления или удаления.
При добавлении нового индекса никакого влияния на доступность операций чтения не возникает. Запросы будут использовать только новые индексы по завершению преобразования индекса. В процессе преобразования индекса обработчик запросов продолжит использовать существующие индексы, поэтому во время такого преобразования вы не увидите никаких изменений в плане производительности чтения. При добавлении новых индексов возникает риск невыполнения запроса или получения несогласованных результатов.
При удалении индексов и немедленном выполнении запросов, имеющих фильтры на удаленных индексах, результаты могут быть несогласованными и неполными до завершения преобразования индекса. В случае удаления индексов обработчик запросов не возвращает единообразные или полные результаты, если в запросах применяются фильтры по только что удаленным индексам. Большинство разработчиков не оказываются в ситуации, когда после удаления индексов сразу же выполняются соответствующие запросы, так что на практике такая ситуация маловероятна.
Примечание.
Вы можете отслеживать ход индексирования.
Команда ReIndex
Команда reIndex воссоздает все индексы в коллекции. В некоторых редких случаях проблемы с производительностью запроса или другие проблемы с индексом в вашей коллекции можно решить с помощью команды reIndex. Если у вас возникли проблемы с индексированием, рекомендуется воссоздать индексы с помощью команды reIndex.
Команду reIndex можно запустить с использованием следующего синтаксиса:
db.runCommand({ reIndex: <collection> })
Вы можете использовать приведенный ниже синтаксис, чтобы проверить, улучшит ли выполнение команды reIndex производительность запросов в вашей коллекции:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Образец вывода:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
Если команда reIndex улучшит производительность запроса, requiresReIndex будет имеет значение true. Если reIndex не улучшит производительность запроса, это свойство будет опущено.
Миграция коллекций с индексами
В настоящее время уникальные индексы можно создавать только в том случае, если коллекция не содержит документов. Распространенные средства миграции MongoDB пытаются создавать уникальные индексы после импорта данных. Чтобы обойти эту ошибку, вы можете вручную создать соответствующие коллекции и уникальные индексы вместо их автоматического создания в средстве миграции. (Для этого в mongorestore следует использовать флаг --noIndexRestore в командной строке.)
Индексирование для MongoDB версии 3.2
Доступные функции индексирования и значения по умолчанию отличаются для учетных записей Azure Cosmos DB, совместимых с протоколом подключения MongoDB версии 3.2. Вы можете проверить версию своей учетной записи и выполнить обновление до версии 3.6.
Если вы используете версию 3.2, в этом разделе описаны ее основные отличия от версии 3.6 и более поздних.
Удаление индексов по умолчанию (версия 3.2)
В отличие от версий 3.6 и более поздних версий Azure Cosmos DB для MongoDB, по умолчанию индексирует каждое свойство. Для удаления этих индексов по умолчанию для коллекции (coll) можно использовать следующую команду:
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
После удаления индексов по умолчанию вы можете добавлять новые индексы так же, как это делается в версии 3.6 и более поздних.
Составные индексы (версия 3.2)
Составные индексы содержат ссылки на множество полей документа. Если требуется создать составной индекс, выполните обновление до версии 3.6 или 4.0.
Индексы с подстановочными знаками (версия 3.2)
Если вам требуется индекс с подстановочными знаками, выполните обновление до версии 3.6 или 4.0.
Следующие шаги
- Индексирование в Azure Cosmos DB
- Срок жизни для данных Azure Cosmos DB
- Сведения о связи между секционированием и индексированием см . в статье "Запрос контейнера Azure Cosmos DB".
- Если вы планируете ресурсы для миграции в Azure Cosmos DB, Для планирования ресурсов можно использовать сведения об имеющемся кластере базы данных.
- Если вам известно только количество виртуальных ядер и серверов в существующем кластере баз данных, см. сведения об оценке единиц запросов на основе виртуальных ядер и серверов.
- Если вам известна стандартная частота запросов для текущей рабочей нагрузки базы данных, ознакомьтесь со статьей о расчете единиц запросов с помощью планировщика ресурсов Azure Cosmos DB