Задача Azure DevOps для Azure Data Explorer
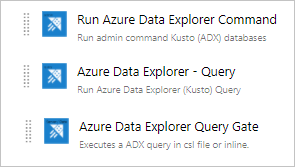
Azure DevOps Services включает инструменты для совместной работы в области разработки, в том числе высокопроизводительные конвейеры, бесплатные частные репозитории Git, настраиваемые канбан-доски, а также различные автоматизированные и непрерывно работающие инструменты тестирования. Azure Pipelines — это функционал Azure DevOps для управления непрерывной поставкой и интеграцией для развертывания кода с помощью высокопроизводительных конвейеров, работающих с любым языком, платформой и облаком. Azure Data Explorer — Pipeline Tools — это задача Azure Pipelines, позволяющая создавать конвейеры выпуска и развертывать изменения базы данных в базах данных Azure Data Explorer. Она доступна бесплатно в Visual Studio Marketplace. Это расширение включает 3 основные задачи:
Azure Data Explorer Command для запуска команд администрирования в кластере Azure Data Explorer
Azure Data Explorer Query — выполнение запросов в кластеру Azure Data Explorer и анализ результатов
Azure Data Explorer Query Server Gate — задача без агента для определения выпусков шлюзов в зависимости от результатов запроса
В этом документе описывается простой пример использования задачи Azure Data Explorer — Pipeline Tools для развертывания изменений схемы в базе данных. Полное описание конвейеров непрерывной поставки и непрерывной интеграции см. в документации по Azure DevOps.
Предварительные требования
- Подписка Azure. Создайте бесплатную учетную запись Azure.
- Кластер и база данных Azure Data Explorer. Создайте кластер и базу данных.
- Настройка кластера azure Data Explorer.
- Создайте приложение Microsoft Entra путем подготовки приложения Microsoft Entra.
- Предоставьте доступ к приложению Microsoft Entra в базе данных azure Data Explorer, управляя разрешениями базы данных azure Data Explorer.
- Настройка Azure DevOps:
- Установка расширения:
- Если вы являетесь владельцем экземпляра Azure DevOps, установите расширение из Marketplace.

- Если вы НЕ являетесь владельцем экземпляра Azure DevOps, обратитесь к владельцу и попросите его установить его.
- Если вы являетесь владельцем экземпляра Azure DevOps, установите расширение из Marketplace.
Подготовка содержимого к выпуску
Существует три способа выполнения команд администрирования для кластера в задаче.
Использование шаблона поиска для получения нескольких командных файлов из локальной папки агента (источники сборки или артефакты выпуска)

Встроенные команды записи
Укажите путь к файлу для получения файлов команд непосредственно из системы управления версиями Git (рекомендуется)
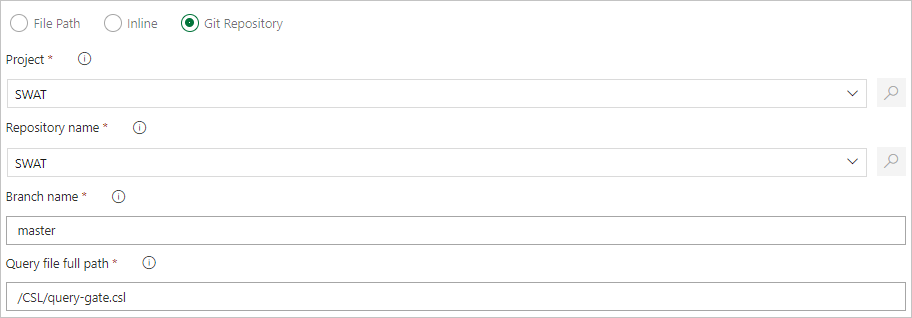
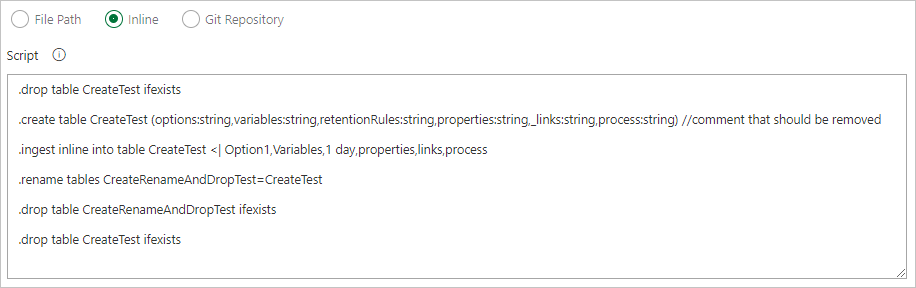
Создайте в репозитории Git следующие образцы папок (Functions, Policies, Tables). Скопируйте файлы отсюда в соответствующие папки, как показано ниже, и зафиксируйте изменения. Примеры файлов предоставляются для выполнения следующего рабочего процесса.

Совет
При создании собственного рабочего процесса рекомендуется сделать код идемпотентным. Например, используйте
.create-merge tableвместо.create tableи функцию.create-or-alterвместо функции.create.
Создание конвейера выпуска
Войдите в организацию Azure DevOps.
Откройте Конвейеры>Выпуски в меню слева и выберите Создать конвейер.
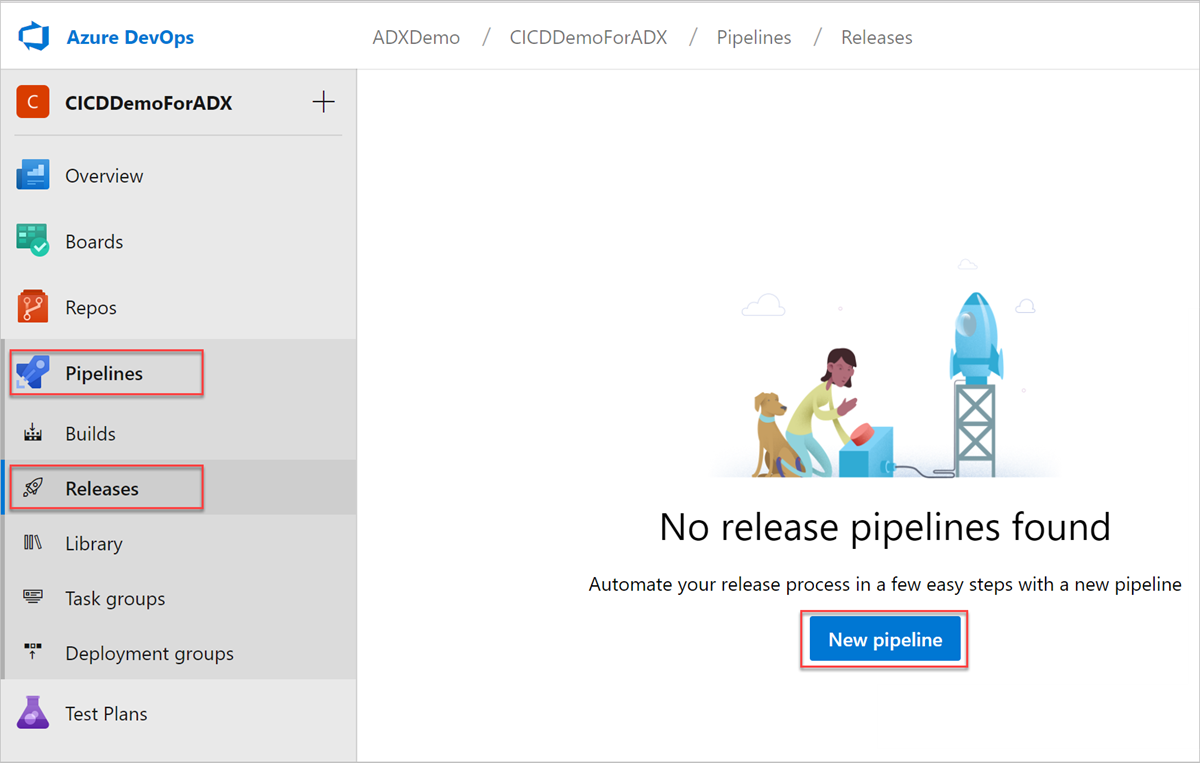
Откроется окно Новый конвейер выпуска. На вкладке Конвейеры в области Выбор шаблона выберите Пустое задание.

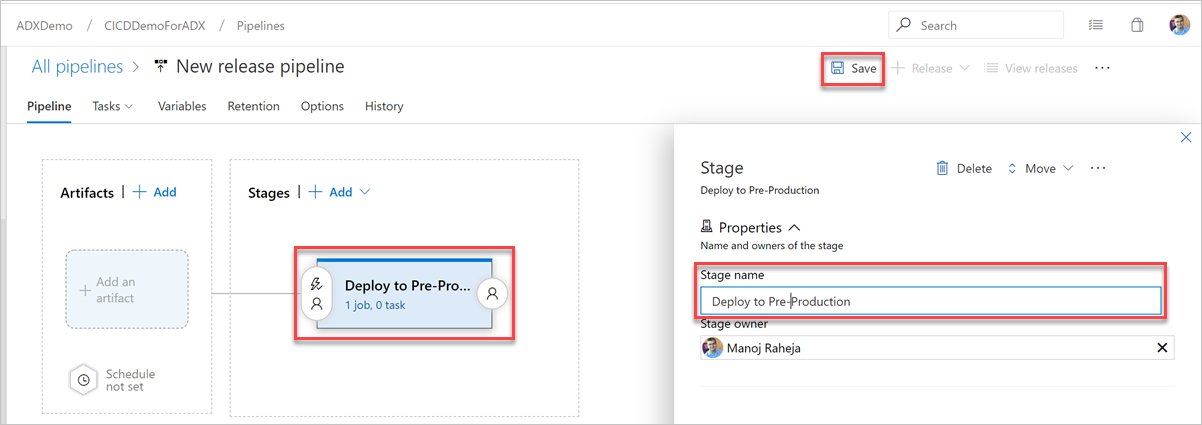
Нажмите кнопку Этап. В области Этап добавьте Имя этапа. Щелкните Сохранить, чтобы сохранить конвейер.
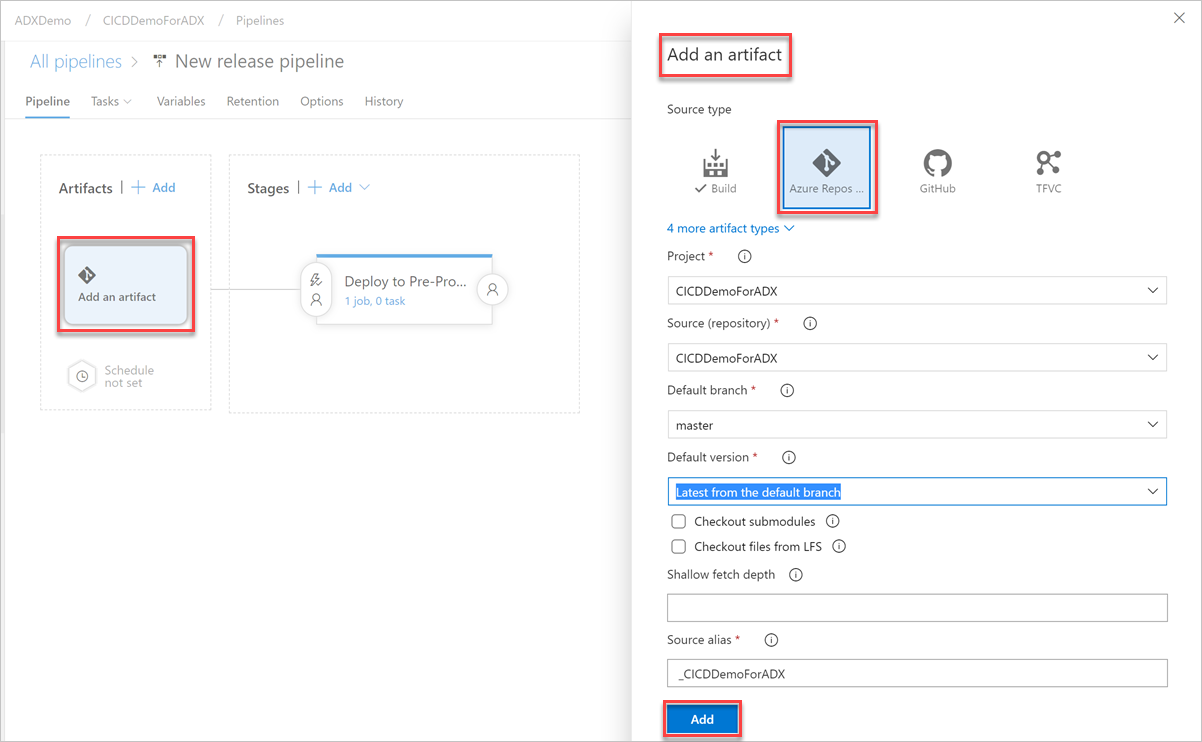
Нажмите кнопку Добавить артефакт. В области Добавить артефакт выберите репозиторий, в котором находится ваш код, введите нужные сведения и нажмите кнопку Добавить. Щелкните Сохранить, чтобы сохранить конвейер.
На вкладке Переменные выберите + Добавить, чтобы создать переменную для URL-адреса конечной точки, которая будет использоваться в задаче. Запишите Имя и Значение конечной точки. Щелкните Сохранить, чтобы сохранить конвейер.

Чтобы найти Endpoint_URL, используйте URI кластера Azure Data Explorer на странице обзора Azure Data Explorer Cluster. Создайте URI в следующем формате
https://<Azure Data Explorer cluster URI>?DatabaseName=<DBName>. Например https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB.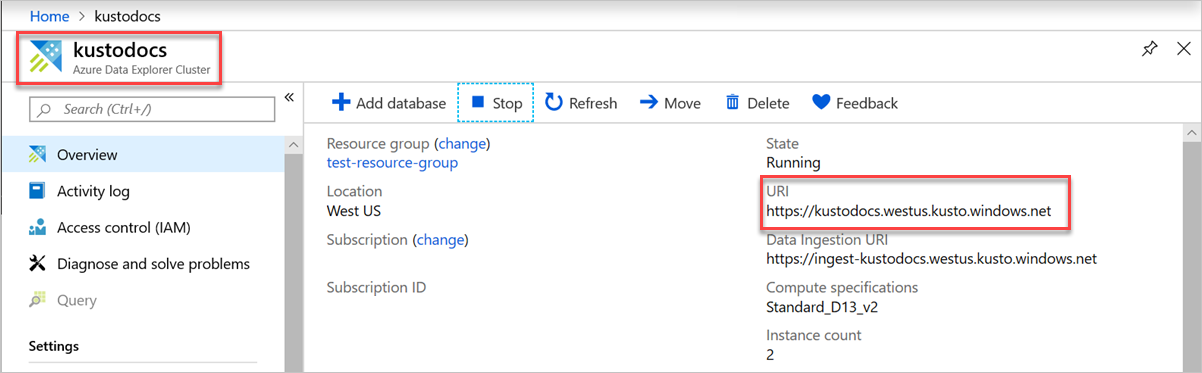
Создание задач для развертывания папок
На вкладке Конвейер щелкните задание 1, задача 0, чтобы добавить задачи.
Повторите следующие шаги, чтобы создать задачи команд для развертывания файлов из папок Tables, Functions и Policies:
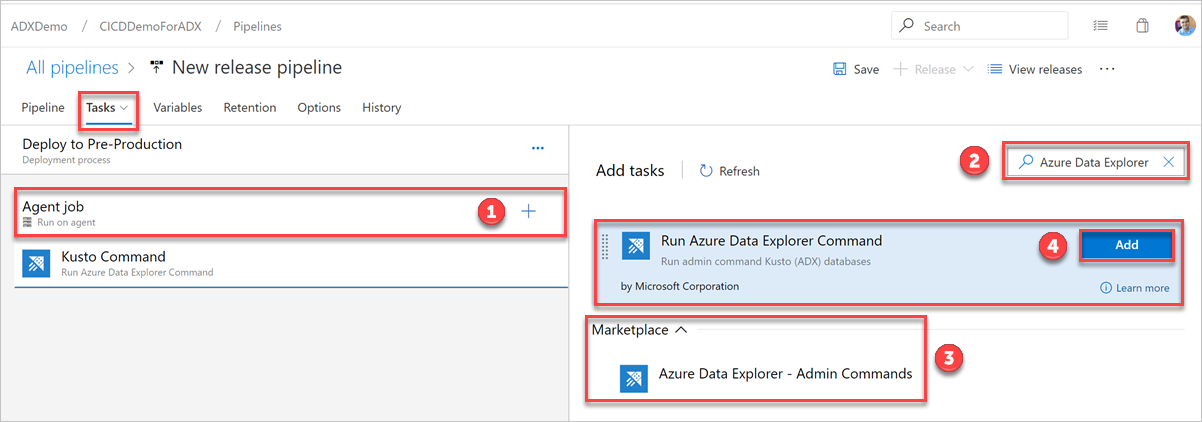
На вкладке Задачи выберите + от Задание агента и выполните поиск Azure Data Explorer.
В разделе Запуск команды Azure Data Explorer выберите Добавить.
Выберите Команда Kusto и обновите задачу, указав следующие сведения:
Отображаемое имя: имя задачи. Например,
Deploy <FOLDER>где<FOLDER>— это имя папки для создаваемой задачи развертывания.Путь к файлу: для каждой папки укажите путь, например
*/<FOLDER>/*.csl, где<FOLDER>— это соответствующая папка для задачи.URL-адрес конечной точки: укажите переменную
EndPoint URL, созданную на предыдущем шаге.Использовать конечную точку службы: выберите этот параметр.
Конечная точка службы: выберите существующую конечную точку службы или создайте новую ( + Создать), указав следующие сведения в окне Добавление подключения к службе Azure Data Explorer:
Параметр Рекомендуемое значение Имя соединения Введите имя для обозначения этой конечной точки службы URL-адрес кластера Значение можно найти в разделе обзорной информации о Azure Data Explorer Cluster на портале Azure Идентификатор субъекта-службы Введите Microsoft Entra идентификатор приложения (создан в качестве предварительного требования) Ключ приложения субъекта-службы Введите ключ приложения Microsoft Entra (созданный в качестве предварительного требования) Microsoft Entra идентификатор клиента Введите клиент Microsoft Entra (например, microsoft.com или contoso.com).
Установите флажок Разрешить всем конвейерам использовать это подключение, а затем нажмите кнопку ОК.

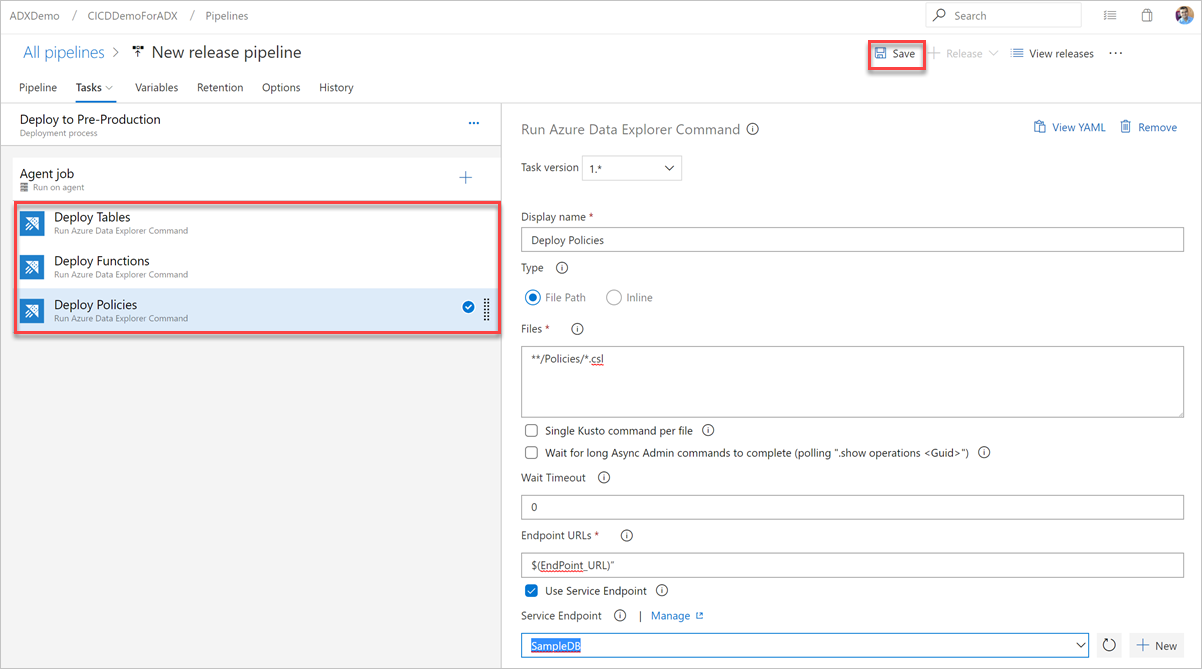
Выберите Сохранить, а затем на вкладке Задачи убедитесь в наличии трех задач: Развертывание таблиц, Развертывание функций и Развертывание политик.
Создание задачи запроса
При необходимости создайте задачу для выполнения запроса к кластеру. Выполнение запросов в конвейере сборки или выпуска можно использовать для проверки набора данных и успешного выполнения шага на основе результатов запроса. Критерии успешного выполнения задач могут быть основаны на пороговом значении счетчика строк или отдельном значении в зависимости от того, что возвращается в ответ на запрос.
На вкладке Задачи выберите + от Задание агента и выполните поиск Azure Data Explorer.
В разделе Запуск запроса Azure Data Explorer выберите Добавить.
Выберите Команда Kusto и обновите задачу, указав следующие сведения:
- Отображаемое имя: имя задачи. Например, Запрос кластера.
- Тип: выберите Встроенный.
- Запрос: введите запрос, который необходимо выполнить.
- URL-адрес конечной точки: укажите переменную
EndPoint URL, созданную ранее. - Использовать конечную точку службы: выберите этот параметр.
- Конечная точка службы: выберите конечную точку службы.
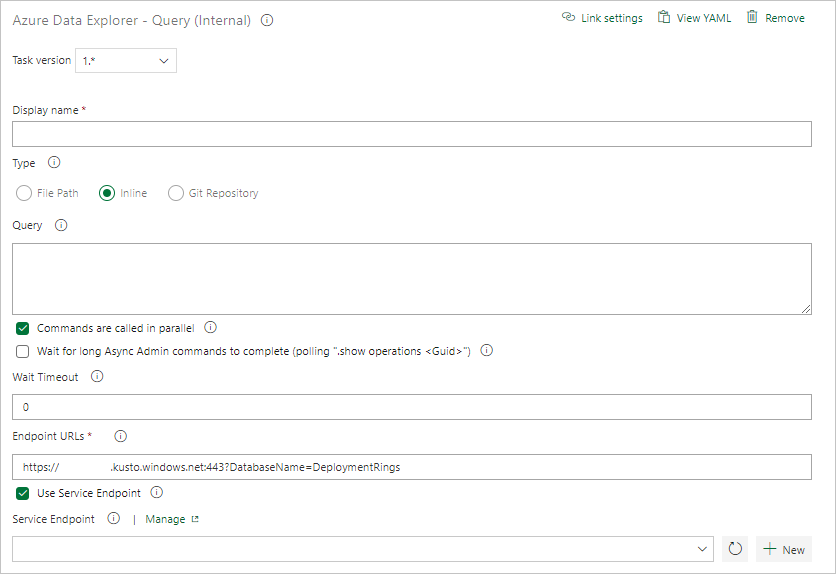
В разделе «Результаты задачи» выберите условия успешного выполнения задачи на основе результатов запроса следующим образом:
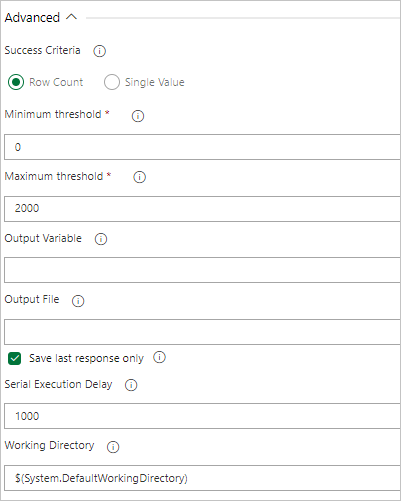
Если запрос возвращает строки, выберите Количество строк и укажите нужные критерии.
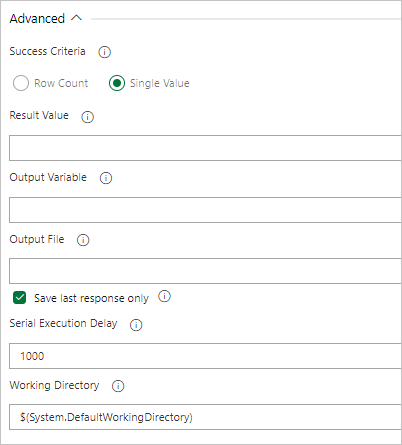
Если запрос возвращает значение, выберите Единственное значение и укажите ожидаемый результат.
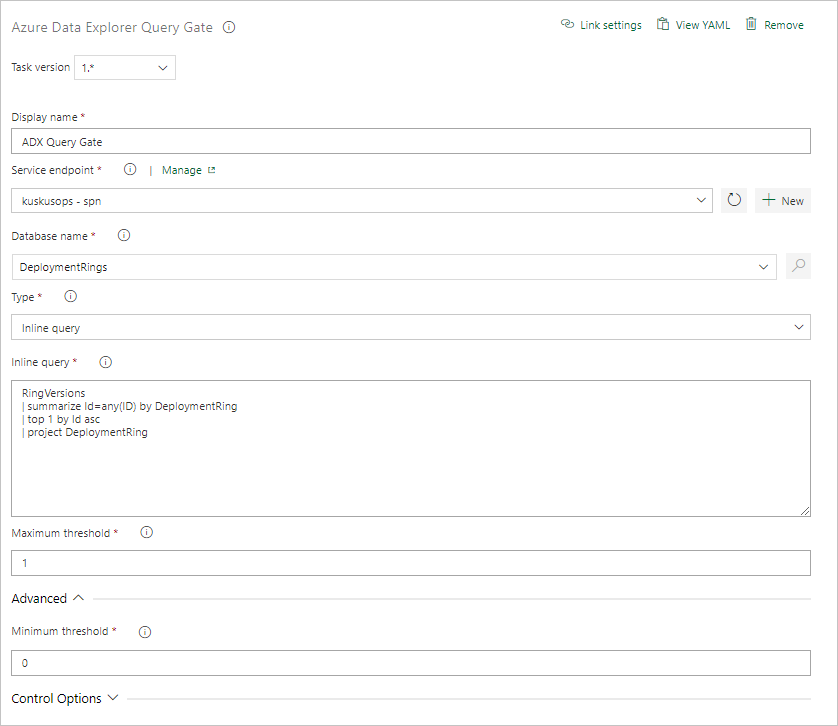
Создание задачи для шлюза сервера запросов
При необходимости создайте задачу для выполнения запроса к кластеру и отрегулируйте шлюз выполнения выпуска, ожидающий число строк в результатах запроса. Задача шлюза запросов сервера — это безагентное задание, означающее, что запрос выполняется непосредственно на Azure DevOps Server.
На вкладке Задачи выберите + от Задание без агента и выполните поиск Azure Data Explorer.
В разделе Запуск шлюза сервера запросов Azure Data Explorer выберите Добавить.
Выберите Шлюз сервера запросов Kusto, а затем выберите Тест шлюза сервера.

Настройте задачу, указав следующие сведения:
- Отображаемое имя: имя шлюза.
- Конечная точка службы: выберите конечную точку службы.
- Имя базы данных: укажите имя базы данных.
- Тип: выберите Встроенный запрос.
- Запрос: введите запрос, который необходимо выполнить.
- Максимальное пороговое значение: укажите максимальное число строк для критериев успешного выполнения запроса.
Примечание
При запуске выпуска вы должны увидеть результаты, аналогичные приведенным ниже.
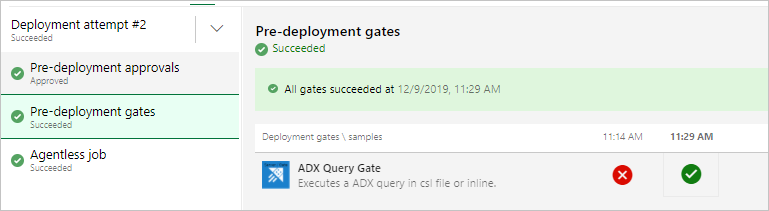
Запуск выпуска
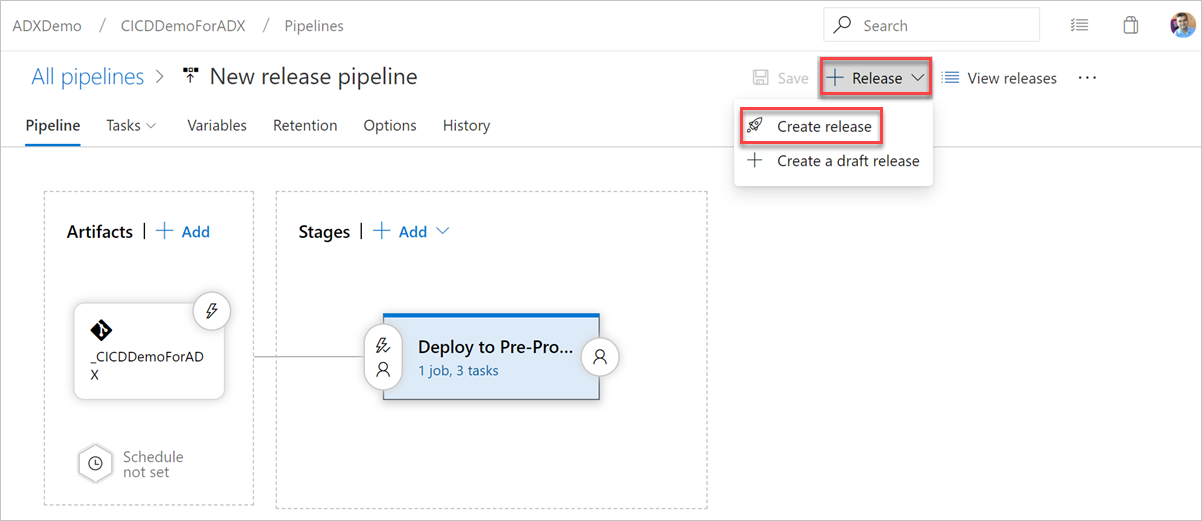
Чтобы создать выпуск, выберите + Выпуск>Создать выпуск.
На вкладке Журналы убедитесь в успешности выполнения развертывания.
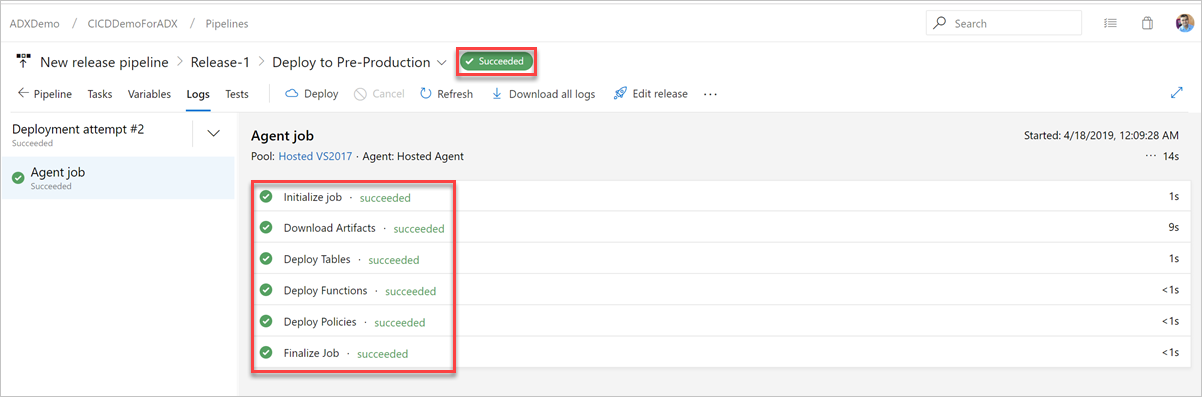
Вы завершили создание конвейера выпуска для развертывания в подготовительной среде.
Конфигурация конвейера Yaml
Задачи можно настроить как через веб-интерфейс Azure DevOps (как показано выше), так и с помощью кода Yaml в схеме конвейера
Использование образца команды администратора
steps:
- task: Azure-Kusto.PublishToADX.PublishToADX.PublishToADX@1
displayName: '<Task Name>'
inputs:
script: '<inline Script>'
waitForOperation: true
kustoUrls: '$(CONNECTIONSTRING):443?DatabaseName=""'
customAuth: true
connectedServiceName: '<Service Endpoint Name>'
serialDelay: 1000
continueOnError: true
condition: ne(variables['ProductVersion'], '') ## Custom condition Sample
Пример использования запроса
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@1
displayName: '<Task Display Name>'
inputs:
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DataBaneName>'
customAuth: true
connectedServiceName: '<Service Endpoint Name>'
continueOnError: true
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по