hll_merge()
Объединяет результаты HLL. Это скалярная версия агрегатной версии hll_merge().
Ознакомьтесь с базовым алгоритмом (HyperLogLog) и точностью оценки.
Важно!
Результаты hll(), hll_if() и hll_merge() можно сохранить и получить позже. Например, может потребоваться создать ежедневную сводку уникальных пользователей, которую затем можно использовать для вычисления еженедельных счетчиков. Однако точное двоичное представление этих результатов может со временем меняться. Нет никакой гарантии, что эти функции будут выдавать идентичные результаты для идентичных входных данных, поэтому мы не советуем полагаться на них.
Синтаксис
hll_merge(hll,hll2, [ hll3, ... ])
Дополнительные сведения о соглашениях о синтаксисе.
Параметры
| Имя | Тип | Обязательно | Описание |
|---|---|---|---|
| hll, hll2, ... | string |
✔️ | Имена столбцов, содержащих значения HLL для объединения. Функция ожидает от 2 до 64 аргументов. |
Возвращаемое значение
Возвращает одно значение HLL. Значение является результатом слияния столбцов hll, hll2, ... hllN.
Примеры
В этом примере показано значение объединенных столбцов.
range x from 1 to 10 step 1
| extend y = x + 10
| summarize hll_x = hll(x), hll_y = hll(y)
| project merged = hll_merge(hll_x, hll_y)
| project dcount_hll(merged)
Выходные данные
dcount_hll_merged |
|---|
| 20 |
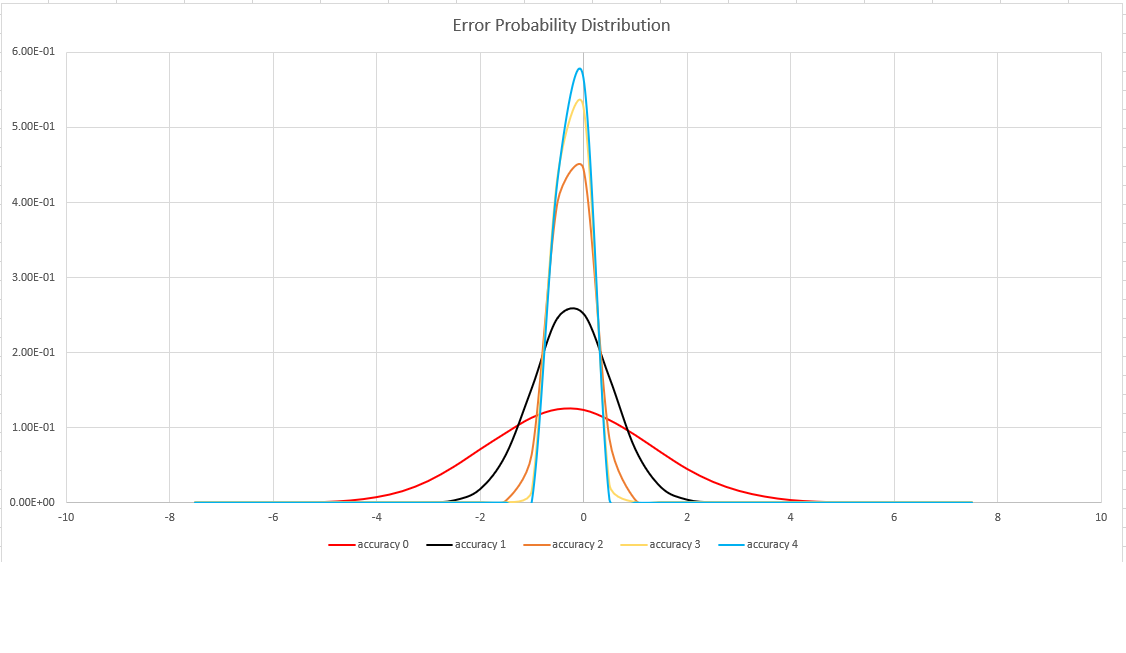
Точность оценки
Эта функция использует вариант алгоритма HyperLogLog (HLL), который выполняет стохастическую оценку кратности набора. Алгоритм предоставляет "рычаг управления", который можно использовать для выравнивания точности и времени выполнения под размер памяти:
| Точность | Ошибка (%) | Число записей |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0.2 | 218 |
Примечание
Столбец "число записей" — это количество 1-байтных счетчиков в реализации HLL.
Алгоритм включает в себя некоторые положения для выполнения идеального подсчета (нулевой ошибки), если кратность набора достаточно мала:
- если уровень точности равен
1, возвращаются значения 1000; - если уровень точности равен
2, возвращаются значения 8000.
Границы погрешности — вероятностная, а не теоретическая граница. Значение является стандартным отклонением распределения погрешностей (сигма). 99,7 % оценок будут иметь относительную погрешность в 3 сигмы.
На следующем изображении показана функция распределения вероятности относительной погрешности оценки (в процентах) для всех поддерживаемых параметров точности:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по