Соединитель Azure Data Explorer для Apache Spark
Важно!
Этот соединитель можно использовать в аналитике в режиме реального времени в Microsoft Fabric. Используйте инструкции в этой статье со следующими исключениями:
- При необходимости создайте базы данных, следуя инструкциям в разделе Создание базы данных KQL.
- При необходимости создайте таблицы, следуя инструкциям в разделе Создание пустой таблицы.
- Получите URI запроса или приема с помощью инструкций в разделе Копирование URI.
- Выполнение запросов в наборе запросов KQL.
Apache Spark — это единый аналитический механизм для крупномасштабной обработки данных. Azure Data Explorer — это быстрая и полностью управляемая служба для аналитики большого объема потоковых данных в реальном времени.
Коннектор Azure Data Explorer для Spark — это проект с открытым исходным кодом, который может работать в любом кластере Spark. Он реализует источник и приемник данных для перемещения данных между кластерами Azure Data Explorer и Spark. Используя Azure Data Explorer и Apache Spark, вы можете создавать быстрые и масштабируемые приложения, ориентированные на сценарии, основанные на данных. Например, машинное обучение (ML), извлечение-преобразование-загрузка (ETL) и Log Analytics. С помощью соединителя Azure Data Explorer становится допустимым хранилищем данных для стандартных операций источника и приемника Spark, таких как запись, чтение и writeStream.
Вы можете выполнять запись в Azure Data Explorer с помощью приема в очереди или потоковой передачи. Чтение из Azure Data Explorer поддерживает обрезку столбцов и раскрытие предикатов, которые фильтруют данные в обозревателе данных Azure, уменьшая объем передаваемых данных.
Примечание
Сведения о работе с соединителем Synapse Spark для Azure Data Explorer см. в статье Подключение к Azure Data Explorer с помощью Apache Spark для Azure Synapse Analytics.
В этом разделе описывается, как установить и настроить соединитель Spark Azure Data Explorer и перемещать данные между кластерами обозревателя данных Azure и Apache Spark.
Примечание
Хотя некоторые из приведенных ниже примеров относятся к кластеру Azure Databricks Spark, соединитель Azure Data Explorer Spark не имеет прямых зависимостей от Databricks или любого другого дистрибутива Spark.
Предварительные требования
- Подписка Azure. Создайте бесплатную учетную запись Azure.
- Кластер и база данных Azure Data Explorer. Создайте кластер и базу данных.
- Кластер Spark
- Установите библиотеку соединителя Azure Data Explorer:
- Предварительно созданные библиотеки для Spark 2.4+Scala 2.11 или Spark 3+scala 2.12
- Репозиторий Maven
- Maven 3.x установлен
Совет
Версии Spark 2.3.x также поддерживаются, но могут потребоваться некоторые изменения в зависимостях pom.xml.
Как собрать соединитель Spark
Начиная с версии 2.3.0, мы вводим новые идентификаторы артефактов, заменяющие spark-kusto-connector: kusto-spark_3.0_2.12, предназначенные для Spark 3.x и Scala 2.12, и kusto-spark_2.4_2.11, предназначенные для Spark 2.4.x и scala 2.11.
Примечание
Версии до 2.5.1 больше не работают для вставки в существующую таблицу, пожалуйста, обновите до более поздней версии. Это необязательный шаг. Если вы используете готовые библиотеки, например Maven, см. раздел Настройка кластера Spark.
Предварительные требования к сборке
Если вы не используете готовые библиотеки, вам необходимо установить библиотеки, перечисленные в зависимостях, включая следующие библиотеки Kusto Java SDK. Чтобы найти нужную версию для установки, загляните в pom соответствующего выпуска.
Обратитесь к этому источнику для создания Spark Connector.
Для приложений Scala/Java, использующих определения проектов Maven, свяжите свое приложение со следующим артефактом (последняя версия может отличаться):
<dependency> <groupId>com.microsoft.azure</groupId> <artifactId>kusto-spark_3.0_2.12</artifactId> <version>2.5.1</version> </dependency>
Команды сборки
Для создания JAR-файла и выполнения всех тестов выполните команду:
mvn clean package
Чтобы собрать jar, запустите все тесты и установите jar в локальный репозиторий Maven:
mvn clean install
Для получения дополнительной информации см. использование соединителя.
Настройка кластера Spark
Примечание
При выполнении следующих действий рекомендуется использовать последнюю версию соединителя Azure Data Explorer Spark.
Настройте следующие параметры кластера Spark на основе кластера Azure Databricks с использованием Spark 2.4.4 и Scala 2.11 или Spark 3.0.1 и Scala 2.12.

Установите последнюю версию библиотеки spark-kusto-connector от Maven.
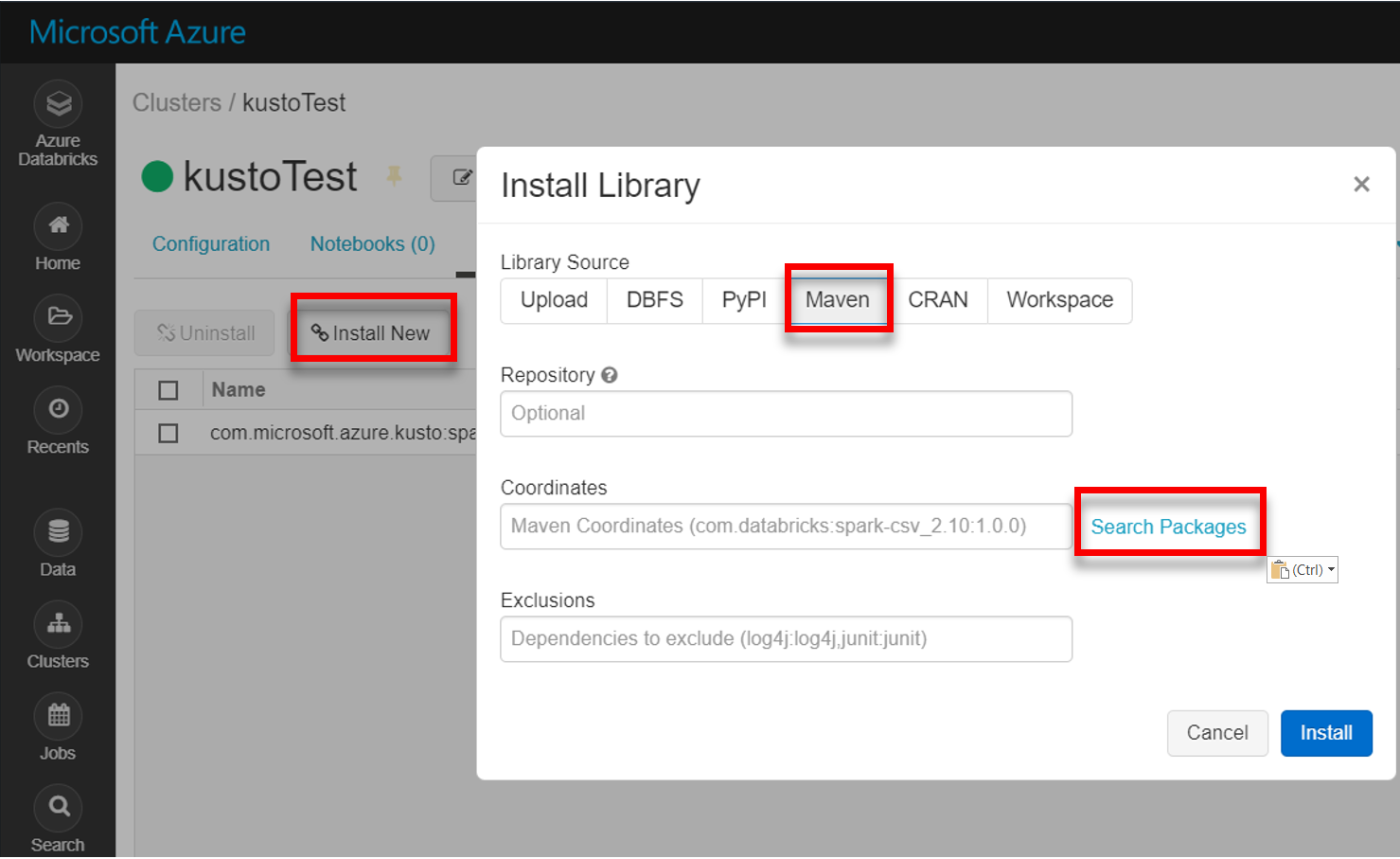
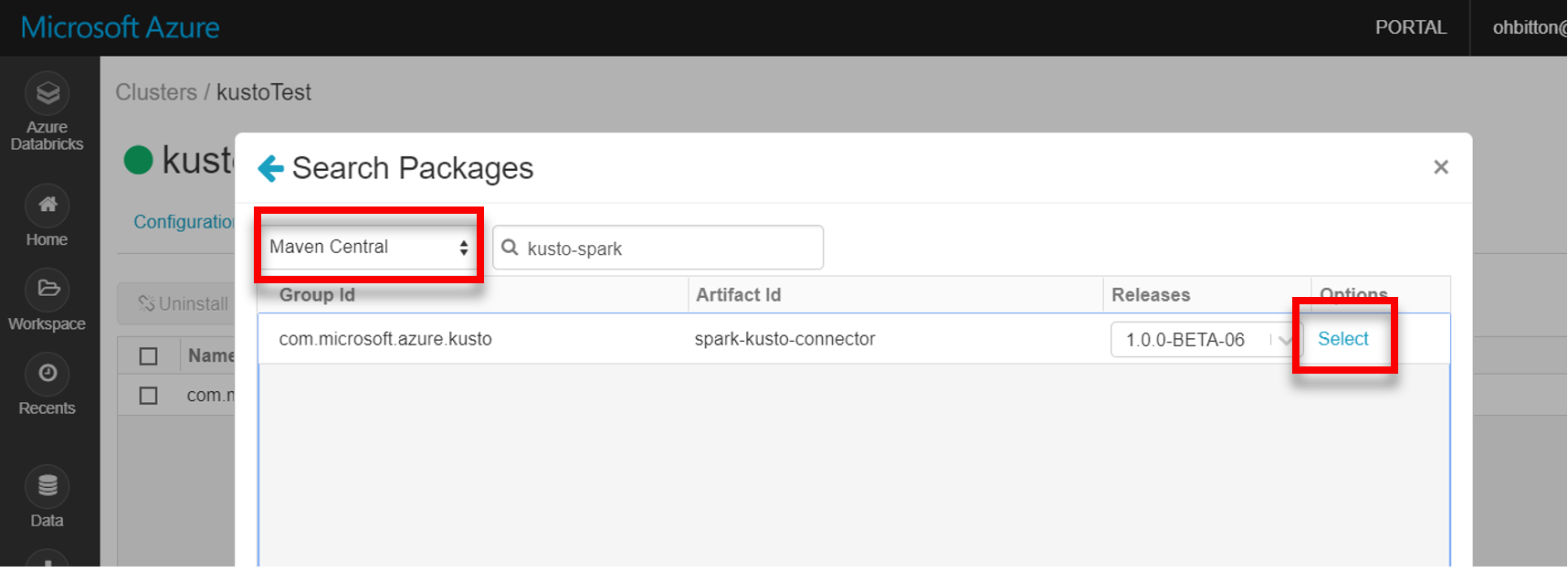
Убедитесь, что установлены все необходимые библиотеки:
Для установки с использованием файла JAR убедитесь, что были установлены дополнительные зависимости:

Аутентификация
Соединитель Azure Data Explorer Spark позволяет выполнять проверку подлинности с помощью идентификатора Microsoft Entra одним из следующих методов:
- Приложение Microsoft Entra
- Маркер доступа Microsoft Entra
- Аутентификация устройства (для непроизводственных сценариев)
- Azure Key Vault: чтобы получить доступ к ресурсу хранилища ключей, установите пакет azure-keyvault и укажите учетные данные приложения.
проверка подлинности приложения Microsoft Entra
Microsoft Entra проверка подлинности приложения — это самый простой и распространенный метод проверки подлинности, который рекомендуется использовать для соединителя Azure Data Explorer Spark.
| Свойства | Строка параметра | Описание |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra идентификатор приложения (клиента). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra центра проверки подлинности. Microsoft Entra идентификатор каталога (клиента). Необязательно. По умолчанию используется microsoft.com. Дополнительные сведения см. в разделе центр Microsoft Entra. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra ключ приложения для клиента. |
Примечание
Более старые версии API (менее 2.0.0) имеют следующие наименования: kustoAADClientID, kustoClientAADClientPassword, kustoAADAuthorityID
Привилегии Azure Data Explorer
Предоставьте следующие права в кластере Azure Data Explorer.
- Для чтения (источник данных) удостоверение Microsoft Entra должно иметь права просмотра в целевой базе данных или права администратора в целевой таблице.
- Для записи (приемник данных) удостоверение Microsoft Entra должно иметь привилегии ingestor в целевой базе данных. Он также должен иметь права пользователя в целевой базе данных для создания новых таблиц. Если целевая таблица уже существует, вы должны настроить права администратора для целевой таблицы.
Дополнительные сведения о ролях субъектов Azure Data Explorer см. в статье Управление доступом на основе ролей. Для управления ролями безопасности см. Управление ролями безопасности.
Приемник Spark: запись в Azure Data Explorer
Настроить параметры приемника:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Запишите фрейм данных Spark в кластер Azure Data Explorer как пакет:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Или используйте упрощенный синтаксис:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Запись потоковых данных:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Источник Spark: чтение из Azure Data Explorer
При чтении небольших объемов данных определите запрос данных:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Необязательно: если вы предоставляете временное хранилище больших двоичных объектов (а не Azure Data Explorer), большие двоичные объекты создаются под ответственность вызывающего объекта. Это включает в себя предоставление хранилища, ротацию ключей доступа и удаление временных артефактов. Модуль KustoBlobStorageUtils содержит вспомогательные функции для удаления больших двоичных объектов на основе координат учетной записи и контейнера и учетных данных либо полного URL-адреса SAS с разрешениями на запись, чтение и список. Когда соответствующий RDD больше не нужен, каждая транзакция сохраняет временные артефакты больших двоичных объектов в отдельном каталоге. Этот каталог записывается как часть журналов с информацией о транзакциях чтения, передаваемых на узле Spark Driver.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")В приведенном выше примере доступ к Key Vault через интерфейс соединителя отсутствует; используется более простой метод использования секретов Databricks.
Читайте из Azure Data Explorer.
Если вы предоставляете временное хранилище BLOB-объектов, выполните чтение из Azure Data Explorer следующим образом:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Если Azure Data Explorer предоставляет временное хранилище больших двоичных объектов, прочтите из Azure Data Explorer следующим образом:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)
См. также
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по