Преобразование "Соединение" в потоке данных для сопоставления
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Используйте преобразование "Соединение" для объединения данных из двух источников или потоков в поток данных для сопоставления. Поток вывода будет включать все столбцы из обоих источников, сопоставленные на основе условия соединения.
Типы соединений
Потоки данных для сопоставления в настоящее время поддерживают пять различных типов соединений.
Внутреннее соединение
Внутреннее соединение выводит только строки, которые имеют совпадающие значения в обеих таблицах.
Левое внешнее соединение
Левое внешнее соединение возвращает все строки из левого потока и сопоставленные записи из правого потока. Если строка из левого потока не имеет соответствия, выходным столбцам из правого потока задается значение NULL. Выходными данными будут строки, возвращаемые внутренним соединением, а также несовпадающие строки из левого потока.
Примечание.
Модуль Spark, используемый потоками данных, иногда выходит из строя из-за возможных декартовых произведений в условиях соединения. В этом случае вы можете переключиться на пользовательское перекрестное соединение и вручную ввести условие соединения. Это может привести к снижению производительности в потоках данных, так как подсистеме выполнения может потребоваться вычислить все строки с обеих сторон связи, а затем отфильтровать их.
Правое внешнее соединение
Правое внешнее соединение возвращает все строки из правого потока и сопоставленные записи из левого потока. Если строка из правого потока не имеет соответствия, выходным столбцам из левого потока задается значение NULL. Выходными данными будут строки, возвращаемые внутренним соединением, а также несовпадающие строки из правого потока.
Полное внешнее соединение
Полное внешнее соединение выводит все столбцы и строки с обеих сторон со значениями NULL для столбцов, которые не совпадают.
Пользовательское перекрестное соединение
Перекрестное соединение выводит перекрестное произведение двух потоков на основе условия. Если вы используете условие, которое не является равенством, необходимо указать пользовательское выражение в качестве условия перекрестного соединения. Потоком вывода будут все строки, которые соответствуют условию соединения.
Вы можете использовать этот тип соединения для неэквивалентных соединений и условий OR.
Если вы хотите явно создать полный декартов продукт, в каждом из двух независимых потоков перед соединением используйте преобразование "Производный столбец", чтобы создать искусственный ключ для сопоставления. Например, создайте в производном столбце в каждом вызываемом потоке SyntheticKey столбец и присвойте ему значение 1. Затем используйте a.SyntheticKey == b.SyntheticKey в качестве пользовательского выражения соединения.
Примечание.
Обязательно включите хотя бы один столбец с каждой стороны левой и правой связей в пользовательском перекрестном соединении. Выполнение перекрестных соединений со статическими значениями вместо столбцов с каждой стороны приводит к полному сканированию всего набора данных, в результате чего поток данных работает плохо.
Нечеткое соединение
Вы можете выбрать соединение на основе логики нечеткого соединения, а не точного соответствия значений столбцов, установив флажок "Использовать нечеткое соответствие".
- Объединение частей текста: используйте этот параметр для поиска совпадений, удаляя пробел между словами. Например, если этот параметр включен, Data Factory (Фабрика данных) и DataFactory будет считаться соответствием.
- Столбец показателя подобия: при необходимости можно сохранить показатель соответствия для каждой строки в столбце; для этого нужно ввести здесь имя нового столбца, в котором будет сохранено это значение.
- Порог сходства: выберите значение от 60 до 100 в качестве процента соответствия значений в выбранных столбцах.
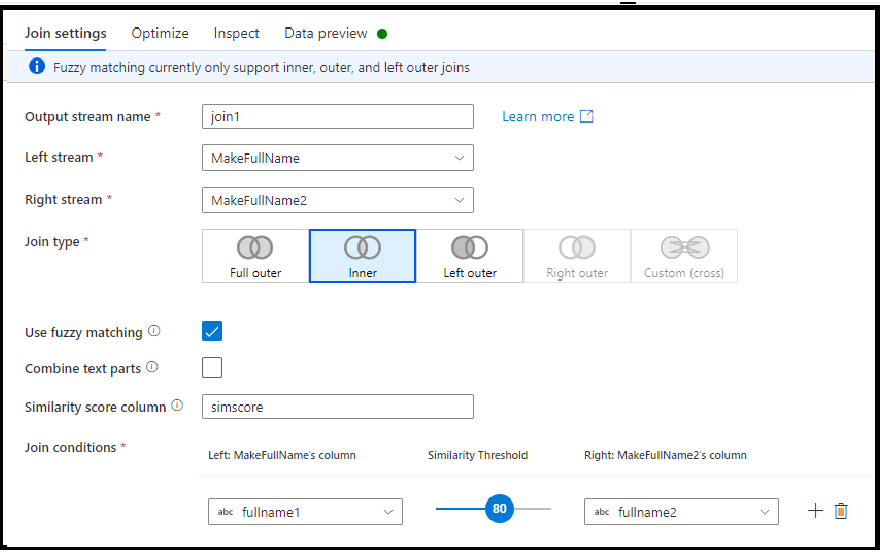
Примечание.
Нечеткое соответствие в настоящее время работает только с типами строковых столбцов и с типами внутренних, левых внешних и полных внешних соединений. При использовании нечетких сопоставленных соединений необходимо отключить оптимизацию трансляции.
Настройка
- Из правого раскрывающегося списка потока выберите, к какому потоку данных вы присоединяетесь.
- Выберите тип соединения.
- Выберите, какие ключевые столбцы будут сопоставляться с помощью условия соединения. По умолчанию поток данных ищет равенство между одним столбцом в каждом потоке. Чтобы выполнить сравнение с помощью вычисленного значения, наведите указатель мыши на раскрывающийся список столбцов и выберите Вычисляемый столбец.
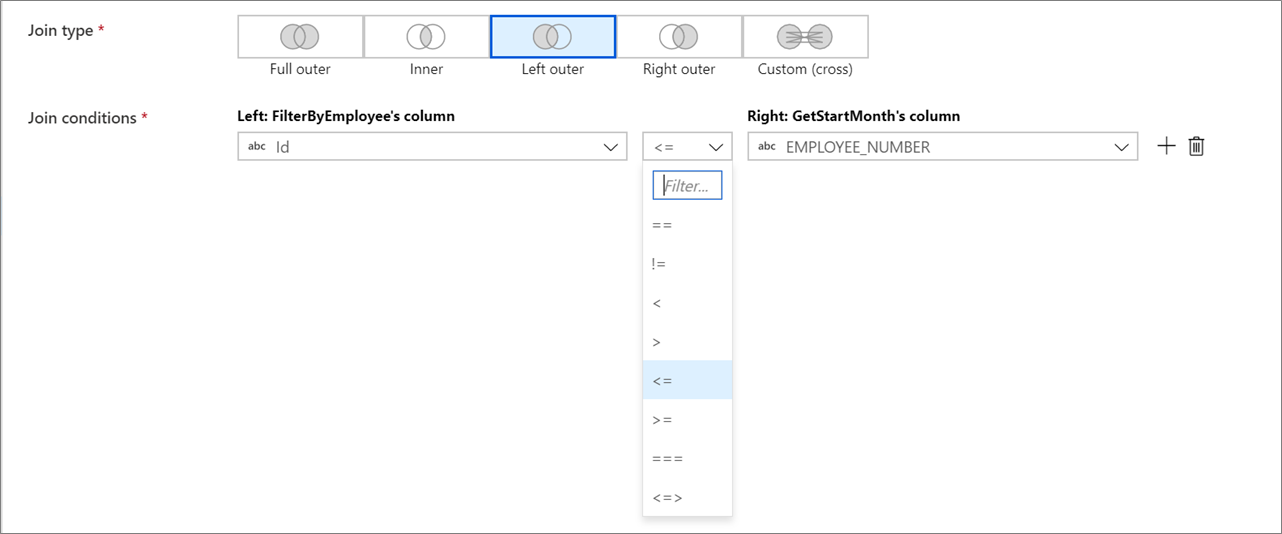
Неэквивалентные соединения
Чтобы использовать условный оператор, например "не равно" (!=) или "больше" (>) в условиях соединения, измените раскрывающийся список операторов между двумя столбцами. Для неэквивалентных соединений требуется широковещательная рассылка по крайней мере одного из двух потоков с помощью Фиксированного вещания на вкладке Оптимизация.
Оптимизация производительности соединения
В отличие от таких инструментов, как SQL Server Integration Services, преобразование "Соединение" необязательно является операцией соединения слиянием. Для ключей соединения не требуется сортировка. Операция соединения происходит на основе оптимальной операции соединения в Spark. Это либо широковещательное соединение, либо соединение на стороне сопоставления.
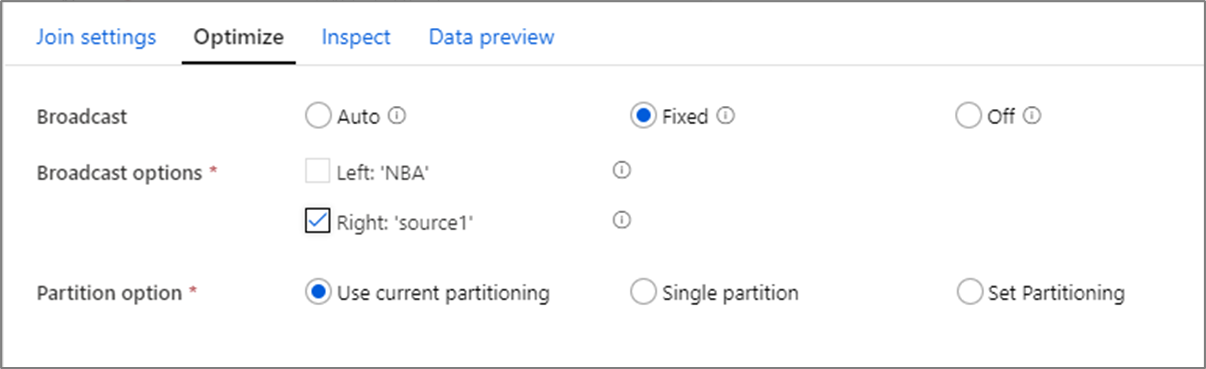
При преобразованиях "Соединения", "Уточняющие запросы" и "Существование", если один или оба потока данных помещаются в память рабочего узла, можно оптимизировать производительность, включив Трансляцию. По умолчанию механизм Spark автоматически решает, следует ли транслировать одну сторону. Чтобы вручную выбрать сторону для трансляции, выберите Фиксированные.
Не рекомендуется отключать широковещательную трансляцию с помощью параметра Выкл., пока соединения не столкнутся с ошибками времени ожидания.
Самосоединение
Чтобы самостоятельно соединить поток данных с самим собой, создайте псевдоним имеющегося потока с преобразованием "Выбор". Создайте ветвь, щелкнув значок плюса рядом с преобразованием и выбрав Новая ветвь. Добавьте преобразование "Выбор" для создания псевдонима исходного потока. Добавьте преобразование "Соединение" и выберите исходный поток в качестве левого потока, а преобразование "Выбор" — в качестве правого потока.

Тестирование условий соединения
При тестировании преобразования "Соединение" с предварительным просмотром данных в режиме отладки используйте небольшой набор известных данных. При выборке строк из большого набора данных нельзя предсказать, какие строки и ключи будут считываться для тестирования. Результат является недетерминированным, то есть условия соединения могут и не возвратить совпадений.
Скрипт потока данных
Синтаксис
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
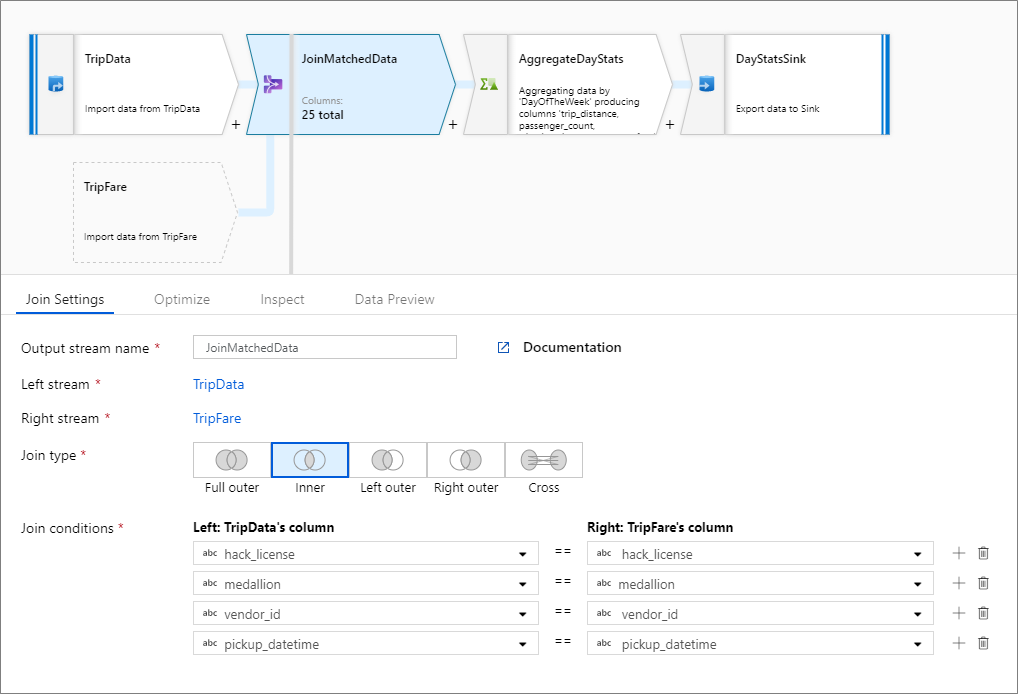
Пример внутреннего соединения
Приведенный ниже пример представляет собой преобразование "Соединение" с именем JoinMatchedData, которое принимает левый поток TripData и правый поток TripFare. Условие соединения является выражением hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime}, которое возвращает значение TRUE, если столбцы hack_license, medallion, vendor_id и pickup_datetime в каждом потоке совпадают. Значение параметра joinType — 'inner'. Мы включаем широковещательную трансляцию только в левом потоке, поэтому broadcast имеет значение 'left'.
В пользовательском интерфейсе это преобразование выглядит следующим образом:
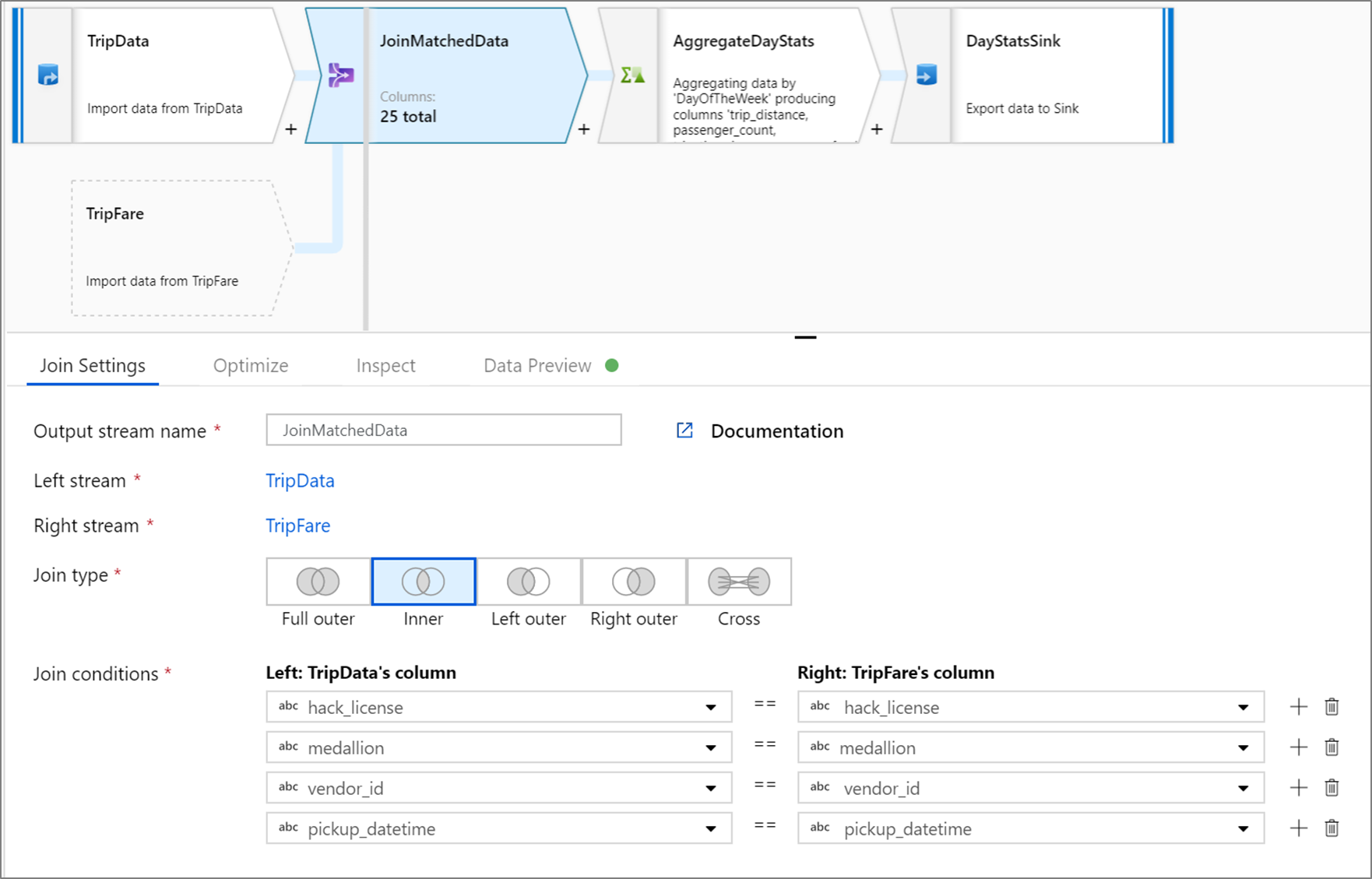
Скрипт потока данных для этого преобразования представлен в следующем фрагменте кода:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Пример пользовательского перекрестного соединения
Приведенный ниже пример представляет собой преобразование "Соединение" с именем JoiningColumns, которое принимает левый поток LeftStream и правый поток RightStream. Это преобразование принимает два потока и объединяет все строки, где столбец leftstreamcolumn больше столбца rightstreamcolumn. Значение параметра joinType — cross. Широковещательная трансляция не включена, broadcast имеет значение 'none'.
В пользовательском интерфейсе это преобразование выглядит следующим образом:
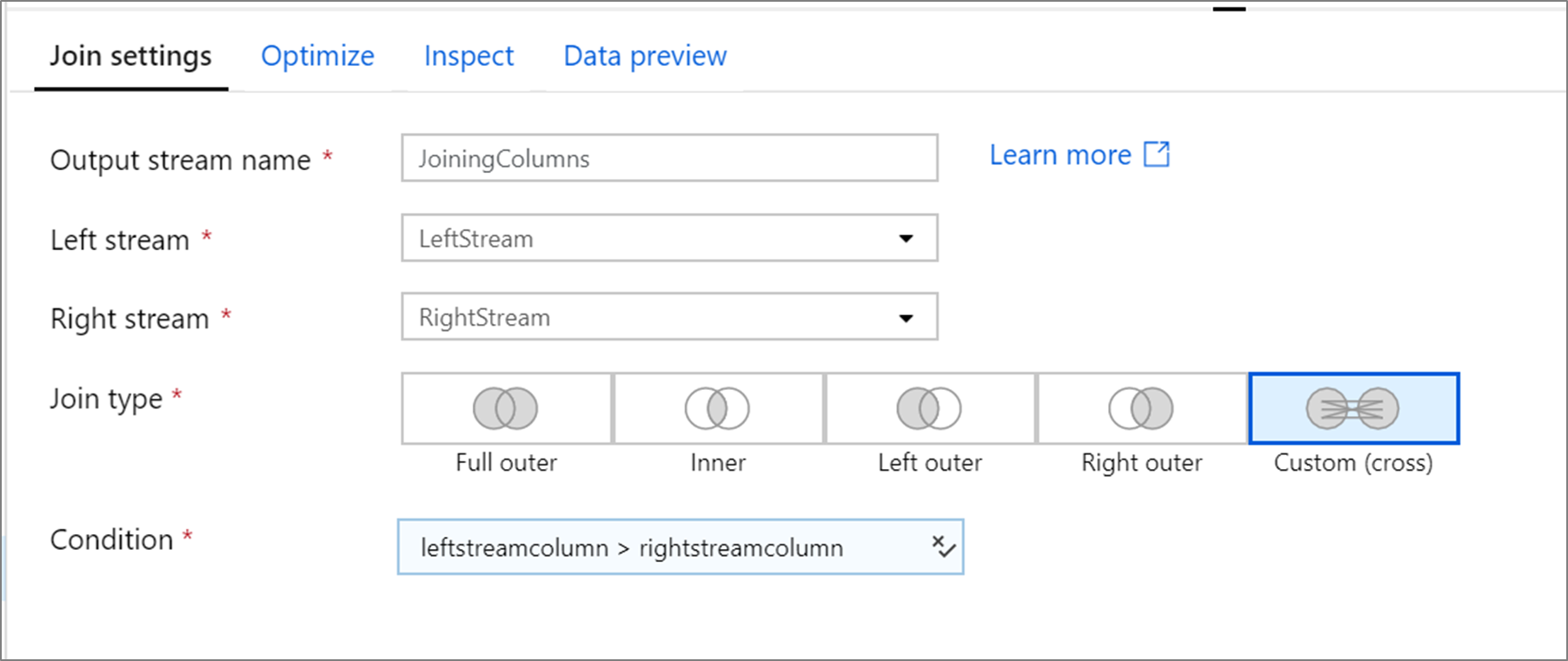
Скрипт потока данных для этого преобразования представлен в следующем фрагменте кода:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Связанный контент
После объединения данных создайте производный столбец и передайте данные в целевое хранилище данных.