Копирование данных из Amazon RDS для SQL Server с помощью Фабрики данных Azure или Azure Synapse Analytics
В этой статье описывается, как с помощью действия копирования в конвейерах Фабрики данных Azure или Azure Synapse копировать данные из базы данных Amazon RDS для SQL Server. Дополнительные сведения см. в вводной статье о Фабрике данных Azure или Azure Synapse Analytics.
Поддерживаемые возможности
Данный соединитель Amazon RDS для SQL Server поддерживается для следующих возможностей:
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/-) | (1) (2) |
| Действие поиска | (1) (2) |
| Действие получения метаданных в Фабрике данных Azure | (1) (2) |
| Действие хранимой процедуры | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования, приведен в таблице Поддерживаемые хранилища данных и форматы.
В частности, этот соединитель Amazon RDS для SQL Server поддерживает:
- SQL Server версии 2005 и выше.
- копирование данных с проверкой подлинности SQL или Windows;
- В качестве источника — извлечение данных с использованием SQL-запроса или хранимой процедуры. Можно также выбрать параллельное копирование из источника Amazon RDS для SQL Server. Дополнительные сведения см. в разделе Параллельное копирование из базы данных SQL.
SQL Server Express LocalDB не поддерживается.
Необходимые компоненты
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешений.
Вы также можете использовать функцию среды выполнения интеграции в управляемой виртуальной сети в Фабрике данных Azure для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Начать
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы Amazon RDS для SQL Server с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу Amazon RDS для SQL Server в пользовательском интерфейсе портала Azure.
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск "Amazon RDS for SQL Server" и выберите соединитель Amazon RDS для SQL Server.
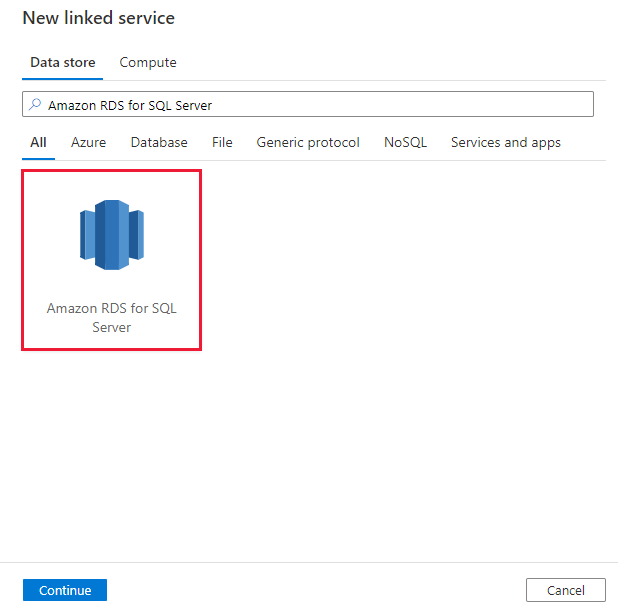
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
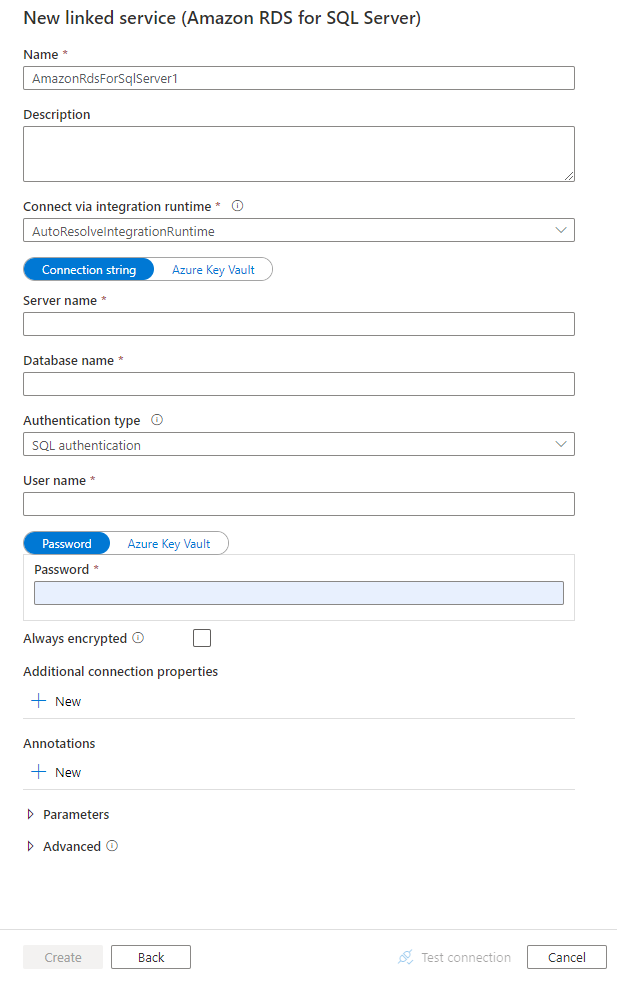
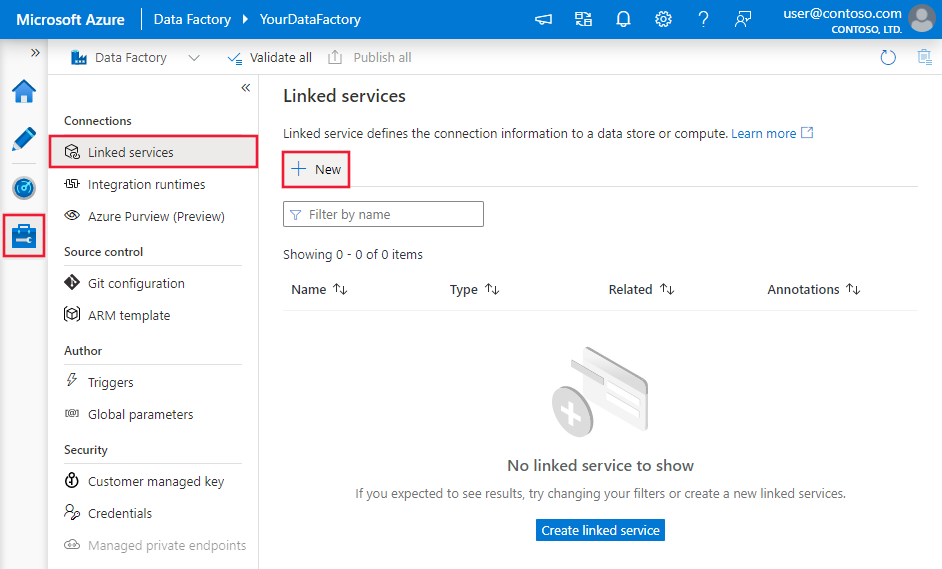
Сведения о конфигурации соединителя
В приведенных ниже разделах представлены подробные сведения о свойствах, которые используются для определения сущностей конвейеров Фабрики данных и Synapse, характерных для соединителя базы данных Amazon RDS для SQL Server.
Свойства связанной службы
Для связанной службы Amazon RDS для SQL Server поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AmazonRdsForSqlServer. | Да |
| connectionString | Укажите сведения о параметре connectionString, необходимые для подключения к базе данных Amazon RDS для SQL Server с помощью проверки подлинности SQL или Windows. Ознакомьтесь с приведенными ниже примерами. Можно также добавить пароль в Azure Key Vault. Если это проверка подлинности SQL, извлеките конфигурацию password из строки подключения. Дополнительные сведения см. в примере JSON после таблицы и в разделе Хранение учетных данных в Azure Key Vault. |
Да |
| userName | При использовании проверки подлинности Windows укажите имя пользователя. Например, имя_домена\имя_пользователя. | No |
| password | Введите пароль для учетной записи пользователя, указанной для выбранного имени пользователя. Пометьте это поле как SecureString для безопасного хранения. Вы можете также указать секрет, хранящийся в Azure Key Vault. | No |
| alwaysEncryptedSettings | Укажите информацию alwaysencryptedsettings, которая необходима для включения Always Encrypted для защиты конфиденциальных данных, хранящихся в Amazon RDS для SQL Server, с помощью управляемого удостоверения или субъекта-службы. Дополнительные сведения см. в примере JSON после таблицы и в разделе Использование Always Encrypted. Если не указано иное, параметр Always Encrypted по умолчанию отключен. | No |
| connectVia | Это среда выполнения интеграции для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано другое, используется среда выполнения интеграции Azure по умолчанию. | No |
Примечание.
Функция Always Encrypted Amazon RDS для SQL Server не поддерживается в потоке данных.
Совет
Если вы получили ошибку с кодом ошибки UserErrorFailedToConnectToSqlServer и сообщение типа "Достигнут установленный предел сеанса для базы данных XXX", добавьте Pooling=false в строку подключения и повторите попытку.
Пример 1. Использование проверки подлинности SQL
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример 2. Использование проверки подлинности SQL с паролем в Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример 3. Использование проверки подлинности Windows
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=True;",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример 4. Использование Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных Amazon RDS для SQL Server.
Поддерживаются следующие свойства для копирования данных из базы данных Amazon RDS для SQL Server.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для набора данных должно иметь значение AmazonRdsForSqlServerTable. | Да |
| schema | Имя схемы. | No |
| table | Имя таблицы или представления. | No |
| tableName | Имя таблицы или представления со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новой рабочей нагрузки используйте schema и table. |
No |
Пример
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, доступных для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых Amazon RDS для SQL Server в качестве источника и приемника.
Amazon RDS для SQL Server в качестве источника
Совет
Чтобы эффективно загружать данные из Amazon RDS для SQL Server с использованием секционирования данных, изучите дополнительные сведения из статьи Параллельное копирование из базы данных SQL Server.
Чтобы скопировать данные из Amazon RDS для SQL Server, задайте тип источника AmazonRdsForSqlServerSource в действии копирования. В разделе source для действия копирования поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение AmazonRdsForSqlServerSource. | Да |
| sqlReaderQuery | Используйте пользовательский SQL-запрос для чтения данных. Например, select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Это свойство содержит имя хранимой процедуры, которая считывает данные из исходной таблицы. Последней инструкцией SQL должна быть инструкция SELECT в хранимой процедуре. | No |
| storedProcedureParameters | Это параметры для хранимой процедуры. Допустимые значения: пары имен или значений. Имена и регистр параметров должны совпадать с именами и регистром параметров хранимой процедуры. |
No |
| isolationLevel | Задает режим блокировки транзакций для источника данных SQL. Допустимые значения: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Если значение не указано, используется уровень изоляции базы данных по умолчанию. Дополнительные сведения см. в этом документе. | No |
| partitionOptions | Задает параметры секционирования данных, используемые для загрузки данных из Amazon RDS для SQL Server Допустимые значения: Нет (по умолчанию), PhysicalPartitionsOfTable и DynamicRange. Если параметр секционирования включен (любое значение, кроме None), степень параллелизма для параллельной загрузки данных из Amazon RDS для SQL Server управляется параметром parallelCopies в действии копирования. |
No |
| partitionSettings | Позволяет указать группу параметров для секционирования данных. Применяется, если параметр секционирования имеет значение, отличное от None. |
No |
В разделе partitionSettings: |
||
| partitionColumnName | Укажите имя исходного столбца в виде целого числа или типа date/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 или datetimeoffset), которое будет использоваться для секционирования по диапазонам при параллельном копировании. Если значение не указано, автоматически определяется индекс или первичный ключ таблицы и используется в качестве столбца секционирования.Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?DfDynamicRangePartitionCondition в предложении WHERE. Пример можно найти в разделе Параллельное копирование из базы данных SQL. |
No |
| partitionUpperBound | Максимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для выбора шага секционирования, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически определяет значение. Применяется, если параметр секции имеет значение DynamicRange. Пример можно найти в разделе Параллельное копирование из базы данных SQL. |
No |
| partitionLowerBound | Минимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для выбора шага секционирования, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически определяет значение. Применяется, если параметр секции имеет значение DynamicRange. Пример можно найти в разделе Параллельное копирование из базы данных SQL. |
No |
Обратите внимание на следующие моменты.
- Если для sqlReaderQuery указано AmazonRdsForSqlServerSource, то действие копирования выполняет этот запрос с целью получения данных из источника базы данных Amazon RDS для SQL Server. Есть и другой вариант: создать хранимую процедуру, указав ее имя в sqlReaderStoredProcedureName и параметры в storedProcedureParameters, если она принимает параметры.
- При использовании в источнике хранимой процедуры для получения данных посмотрите, разработана ли хранимая процедура таким образом, чтобы возвращать разные схемы при передаче разных значений параметра. При импорте схемы из пользовательского интерфейса или при копировании данных в базу данных SQL путем автоматического создания таблиц может возникнуть сбой или появиться непредвиденный результат.
Пример. Использование SQL-запроса
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Пример. Использование хранимой процедуры
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Определение хранимой процедуры
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Параллельное копирование из базы данных SQL
Соединитель Amazon RDS для SQL Server в действии копирования обеспечивает встроенное секционирование данных для параллельного копирования данных. Параметры секционирования данных можно найти на вкладке Источник действия Copy.
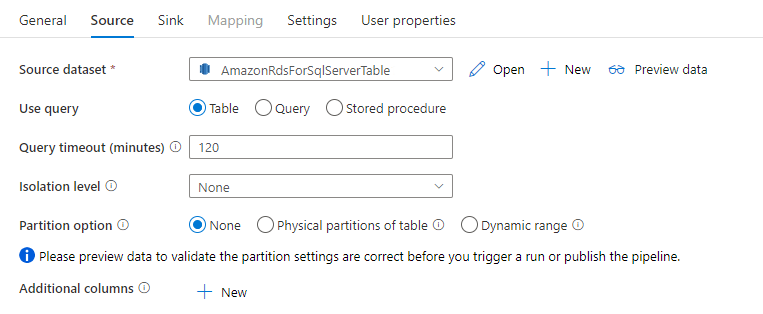
Если включено копирование с секционированием, то действие копирования выполняет параллельные запросы к источнику Amazon RDS для SQL Server для загрузки данных по секциям. Степень параллелизма определяется с помощью параметра parallelCopies для действия копирования. Например, если вы установите для parallelCopies значение 4, служба одновременно генерирует и запускает четыре запроса на основе указанного вами параметра и настроек раздела, и каждый запрос извлекает часть данных из вашего источника Amazon RDS для SQL Server.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при загрузке большого объема данных из Amazon RDS для SQL Server. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Сценарий | Предлагаемые параметры |
|---|---|
| Полная загрузка из большой таблицы с физическими секциями. | Параметр секционирования. Физические секции таблицы. Во время выполнения служба автоматически определяет физические секции и копирует данные по секциям. Чтобы проверить, имеет ли таблица физическую секцию, выполните следующий запрос. |
| Полная загрузка из большой таблицы без физических секций, когда таблица содержит столбец целочисленного типа или типа даты и времени для секционирования данных. | Параметры секции: секция динамического диапазона. Столбец секционирования (необязательно). Укажите столбец для секционирования данных. Если значение не указано, то используется столбец с первичным ключом. Верхняя граница секционирования и Нижняя граница секционирования (необязательно). Указывайте, если необходимо определить шаг секционирования. Эти значения не предназначены для фильтрации строк в таблице. Все строки в таблице будут секционированы и скопированы. Если не указано иное, копирование автоматически определяет значения, и это может занять много времени в зависимости от значений MIN и MAX. Рекомендуется указывать верхнюю и нижнюю границы. К примеру, если ваш столбец раздела "Идентификатор" имеет диапазон значений от 1 до 100 и вы установили нижнюю границу как 20, а верхнюю границу как 80 с параллельным копированием как 4, служба извлекает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80] и >=81 соответственно. |
| Загрузка большого объема данных пользовательским запросом без использования физических секций, однако с использованием столбца целочисленного типа или типа даты/даты и времени для секционирования данных. | Параметры секции: секция динамического диапазона. Запрос: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. Верхняя граница секционирования и Нижняя граница секционирования (необязательно). Указывайте, если необходимо определить шаг секционирования. Эти значения не предназначены для фильтрации строк в таблице. Все строки в результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически определяет значение. К примеру, если ваш столбец раздела "Идентификатор" имеет диапазон значений от 1 до 100, и вы установили нижнюю границу как 20, а верхнюю границу как 80, с параллельным копированием как 4, служба извлекает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80] и >=81 соответственно. Ниже приведены дополнительные примеры запросов для различных сценариев. 1. Запросите всю таблицу: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Запрос из таблицы с выделенным столбцом и дополнительными фильтрами предложения where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Запрос с вложенными запросами: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Запрос с разделом в вложенных запросах: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Ниже приведены рекомендации по загрузке данных с параметром секционирования.
- Чтобы избежать неравномерного распределения данных, выбирайте в качестве столбца секционирования отличительный столбец (например, первичный ключ или уникальный ключ).
- Если таблица имеет встроенную секцию, используйте параметр секционирования "Физические секции таблицы" для повышения производительности.
- Если для копирования данных используется Azure Integration Runtime, то в параметре Единицы интеграции данных (DIU) можно задать большее значение (>4), чтобы задействовать больше вычислительных ресурсов. Ознакомьтесь со сценариями использования этого механизма.
- Параметр "Степень параллелизма копирования" контролирует номера секций. Если это число слишком велико, это может существенно сказаться на производительности. Рекомендуется задавать это число следующим образом: (DIU или число узлов локальной среды IR) * (от 2 до 4).
Пример. Полная загрузка из большой таблицы с физическими секциями
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Пример: запрос с секционированием по динамическому диапазону
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Пример запроса для проверки физической секции
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Если таблица содержит физическую секцию, параметр HasPartition имеет значение yes, как показано ниже.

Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Свойства действия GetMetadata
Подробные сведения об этих свойствах см. в статье Действие GetMetadata.
Использование Always Encrypted
При копировании данных из базы данных Amazon RDS для SQL Server или в нее при помощи функции Always Encrypted выполняйте следующие действия.
Сохраните главный ключ столбца (CMK) в Azure Key Vault. Ознакомьтесь с порядком настройки функции Always Encrypted при помощи Azure Key Vault
Обязательно предоставьте доступ к хранилищу ключей, в котором хранится главный ключ столбца (CMK). В данной статье приведен список необходимых разрешений.
Создайте связанную службу для подключения к базе данных SQL и включите функцию "Always Encrypted", используя либо управляемое удостоверение, либо субъект-службу.
Устранение неполадок с подключением
Настройте экземпляр Amazon RDS для SQL Server для приема удаленных подключений. Запустите Amazon RDS for SQL Server Management Studio, щелкните правой кнопкой мыши свой сервер и выберите Properties (Свойства). Выберите в списке пункт Подключения и Allow remote connections to this server (Разрешить удаленные подключения к этому серверу).

Подробные инструкции см. в статье Настройка параметра конфигурации сервера удаленного доступа.
Запустите диспетчер конфигурации Amazon RDS для SQL Server. Разверните узел Amazon RDS for SQL Server Network Configuration (Сетевая конфигурация Amazon RDS для SQL Server) для соответствующего экземпляра и выберите Protocols for MSSQLSERVER (Протоколы для MSSQLSERVER). Протоколы появятся в области справа. Включите TCP/TP, щелкнув правой кнопкой мыши по имени протокола TCP/IP и выбрав пункт Включить.
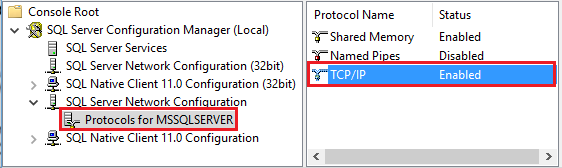
Подробные сведения и альтернативные способы включения протокола TCP/IP см. в статье Включение или отключение сетевого протокола сервера.
В этом же окне дважды щелкните TCP/IP, чтобы открыть окно TCP/IP Properties (Свойства TCP/IP).
Перейдите на вкладку IP-адреса. Прокрутите вниз до раздела IPAll. Запишите порт TCP. Значение по умолчанию — 1433.
Создайте на компьютере правило брандмауэра Windows , чтобы разрешить входящий трафик через этот порт.
Проверьте подключение. Чтобы подключиться к Amazon RDS для SQL Server, указав полное имя, используйте Amazon RDS for SQL Server Management Studio на другом компьютере. Например,
"<machine>.<domain>.corp.<company>.com,1433".
Связанный контент
Список хранилищ данных, поддерживаемых в рамках функции копирования в качестве источников и приемников, см. в разделе Поддерживаемые хранилища данных.