Обработка текстовых файлов фиксированной длины с помощью потоков данных сопоставления Фабрики данных
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
С помощью потоков данных для сопоставления в Фабрике данных Azure можно преобразовывать данные из текстовых файлов фиксированной ширины. В следующей задаче мы определим набор данных для текстового файла без разделителя, а затем настроим разбиение подстроки по порядковому номеру.
Создание конвейера
Выберите + Создать конвейер, чтобы создать новый конвейер.
Добавьте действие потока данных, которое будет использоваться для обработки файлов фиксированной ширины:
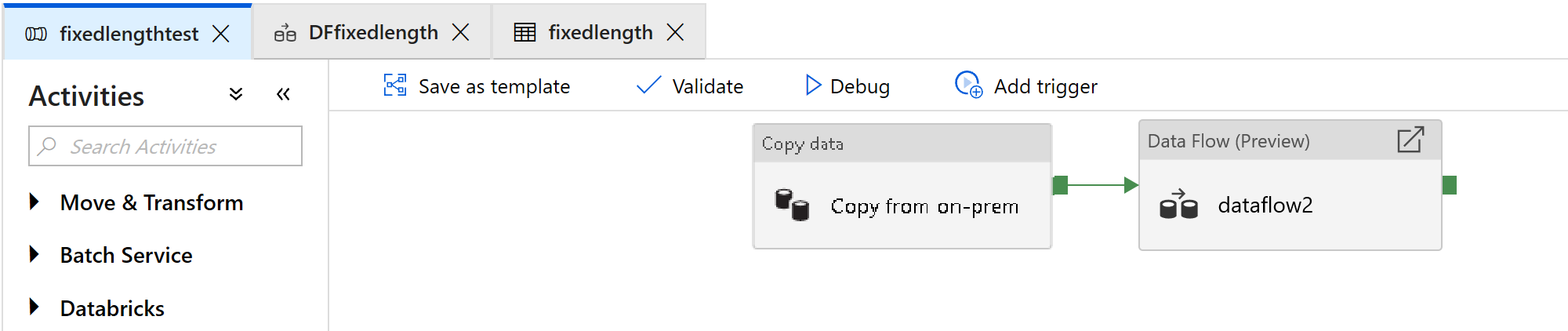
В действии потока данных выберите Создать поток данных для сопоставления.
Добавьте преобразование "Источник", "Производный столбец", "Выбор" и "Приемник".
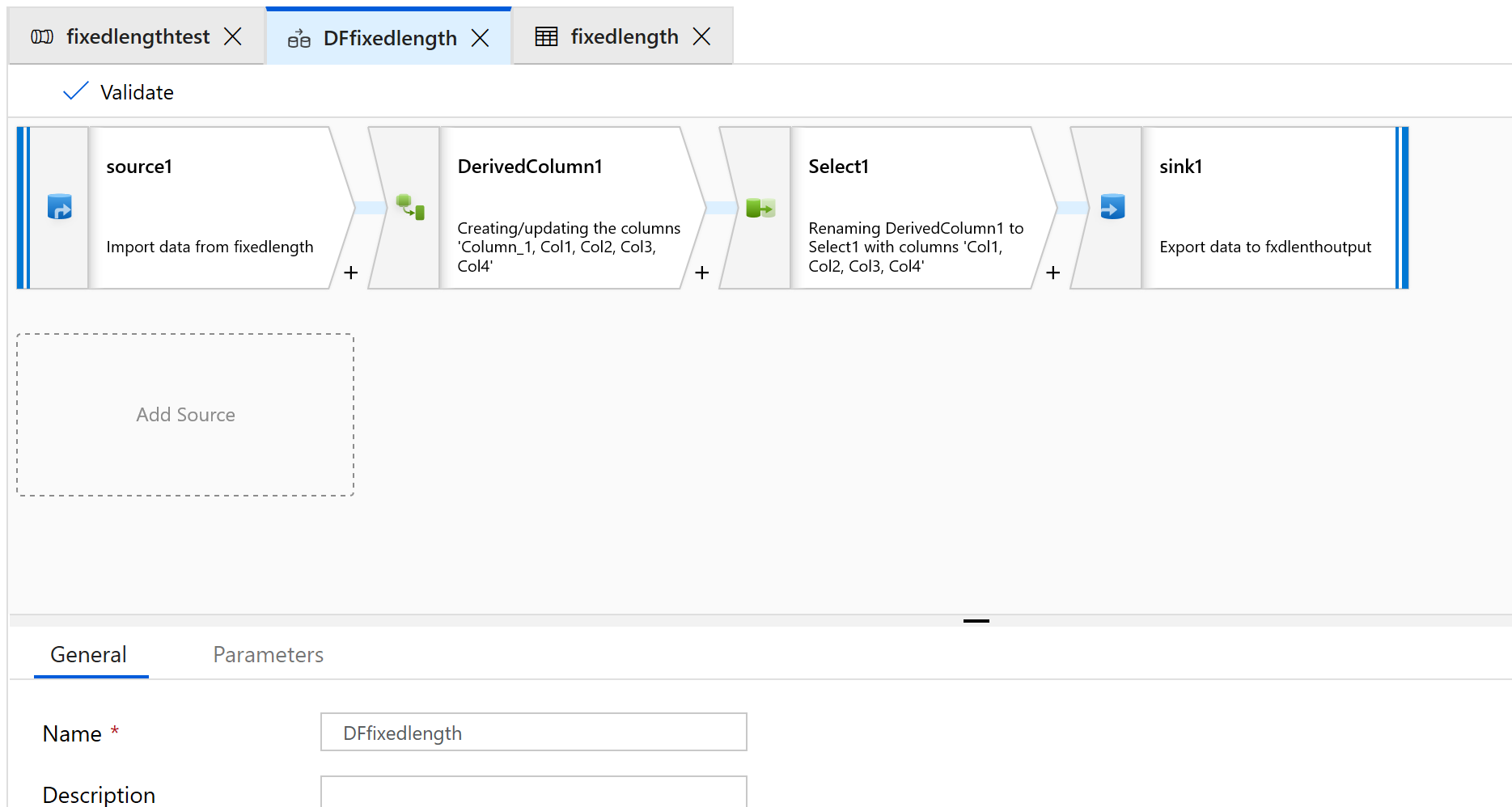
Настройте преобразование "Источник" для использования нового набора данных, который будет иметь тип текста с разделителями.
Не устанавливайте разделителей столбцов или заголовков.
Теперь установим начальные и числовые значения полей для содержимого этого файла:
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468На вкладке Проекция преобразования "Источник" показан строковый столбец с именем column_1.
В производном столбце создайте новый столбец.
Мы предоставим простые имена столбцов, такие как col1.
В построителе выражений введите:
substring(Column_1,1,4)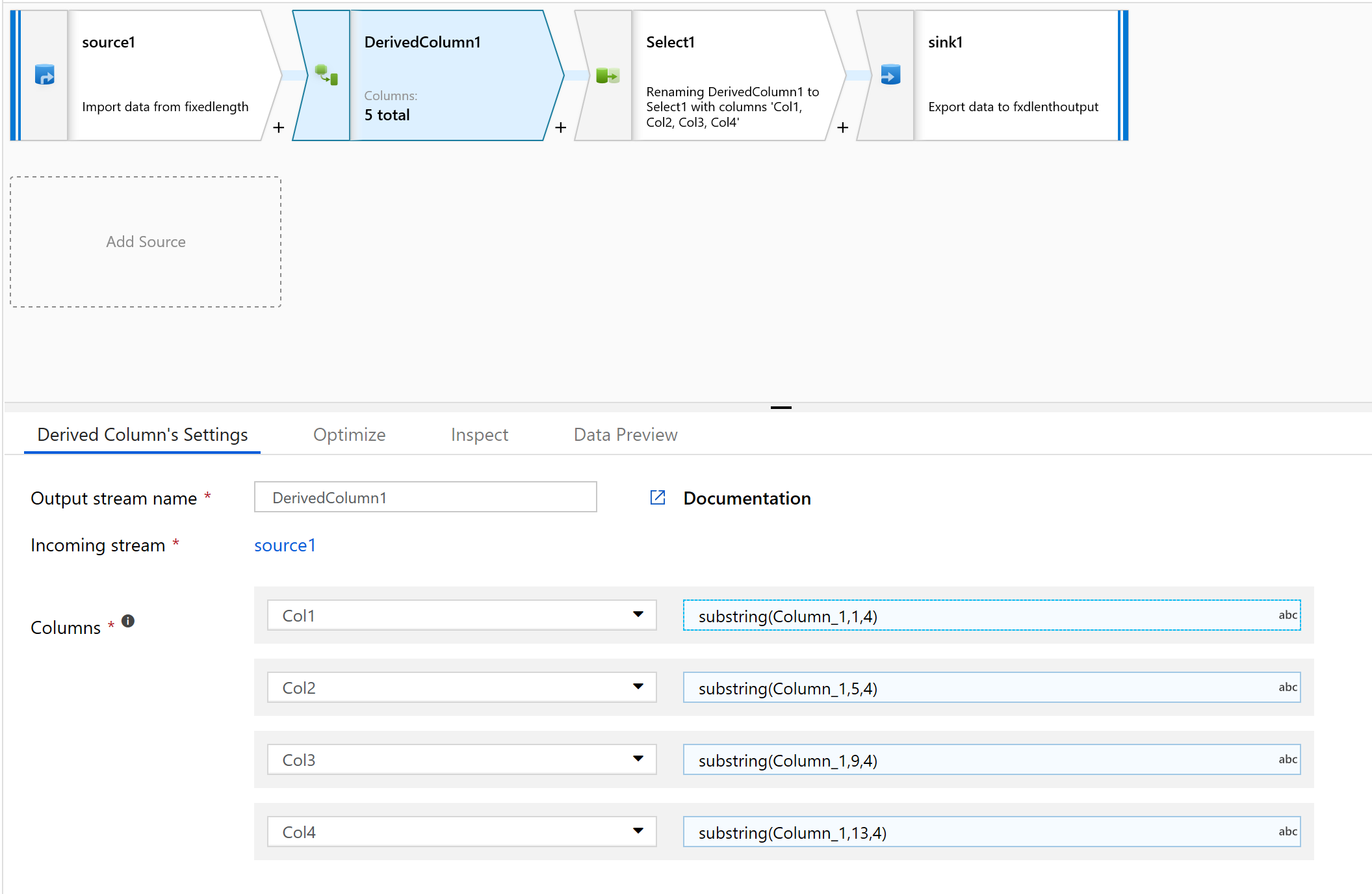
Повторите шаг 10 для всех столбцов, которые необходимо проанализировать.
Перейдите на вкладку Проверка, чтобы просмотреть новые столбцы, которые будут созданы:
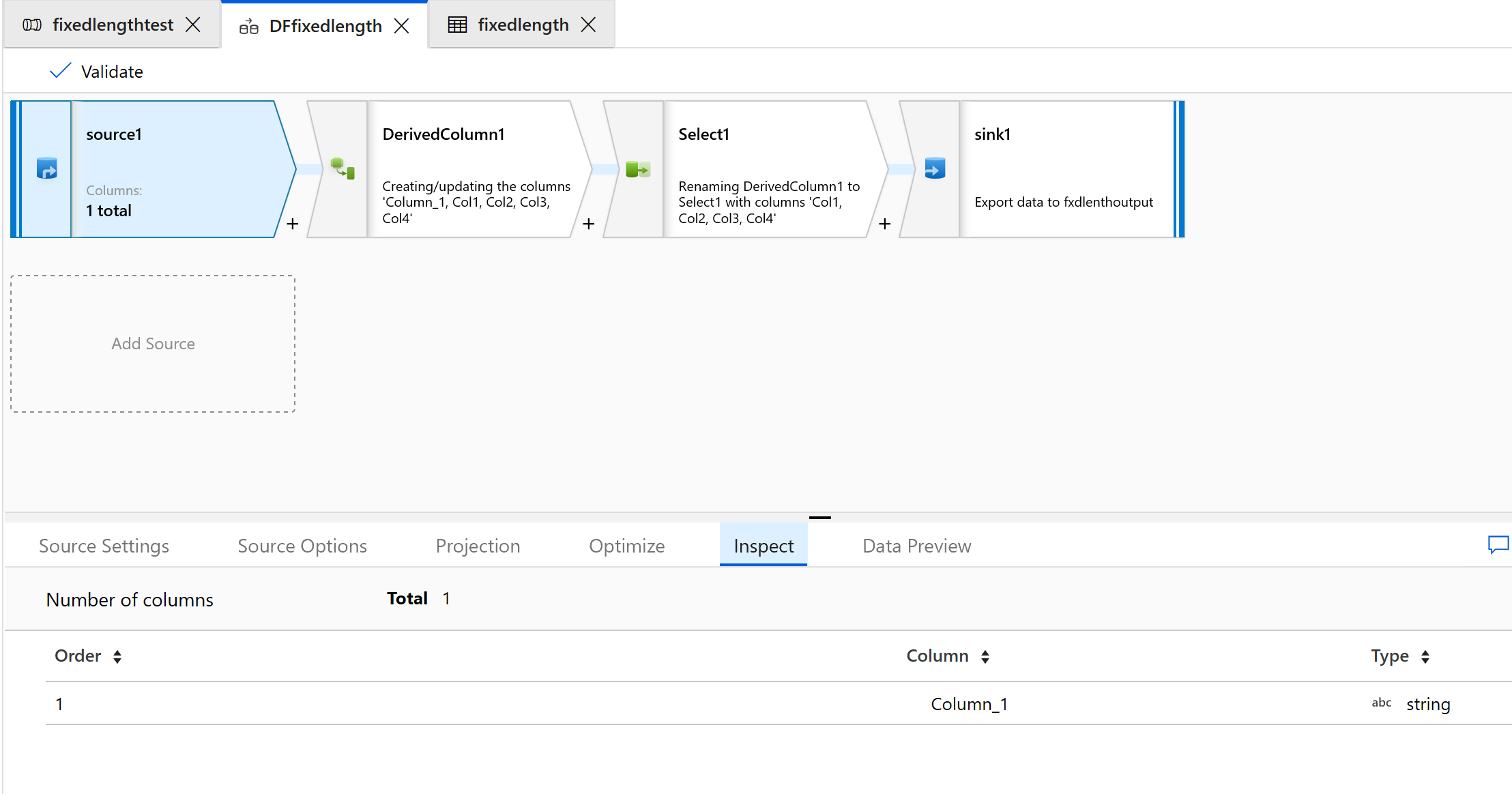
Используйте преобразование "Выбор", чтобы удалить столбцы, которые не требуются для преобразования.
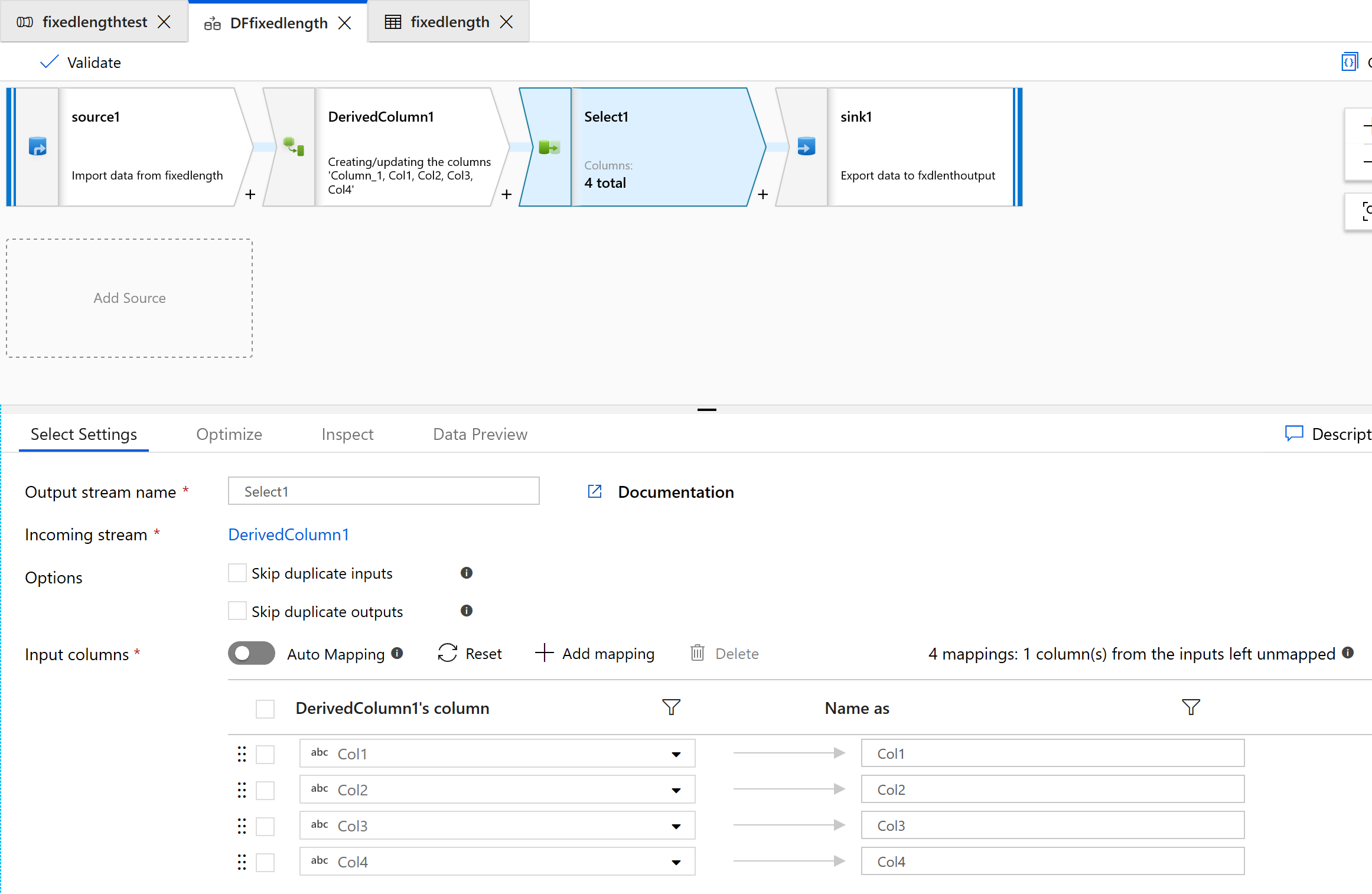
Используйте приемник для вывода данных в папку:
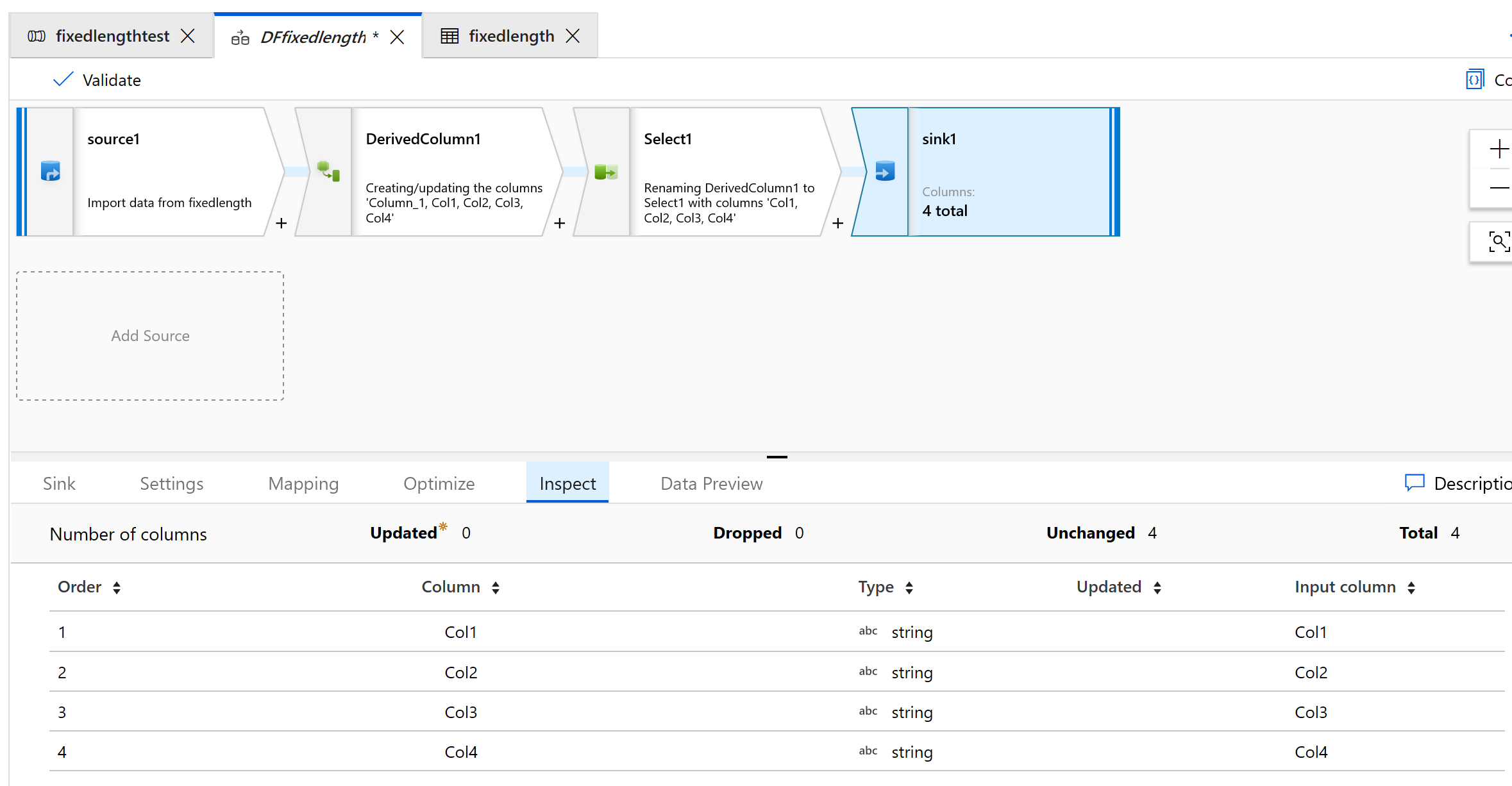
Эти выходные данные имеют следующий вид.
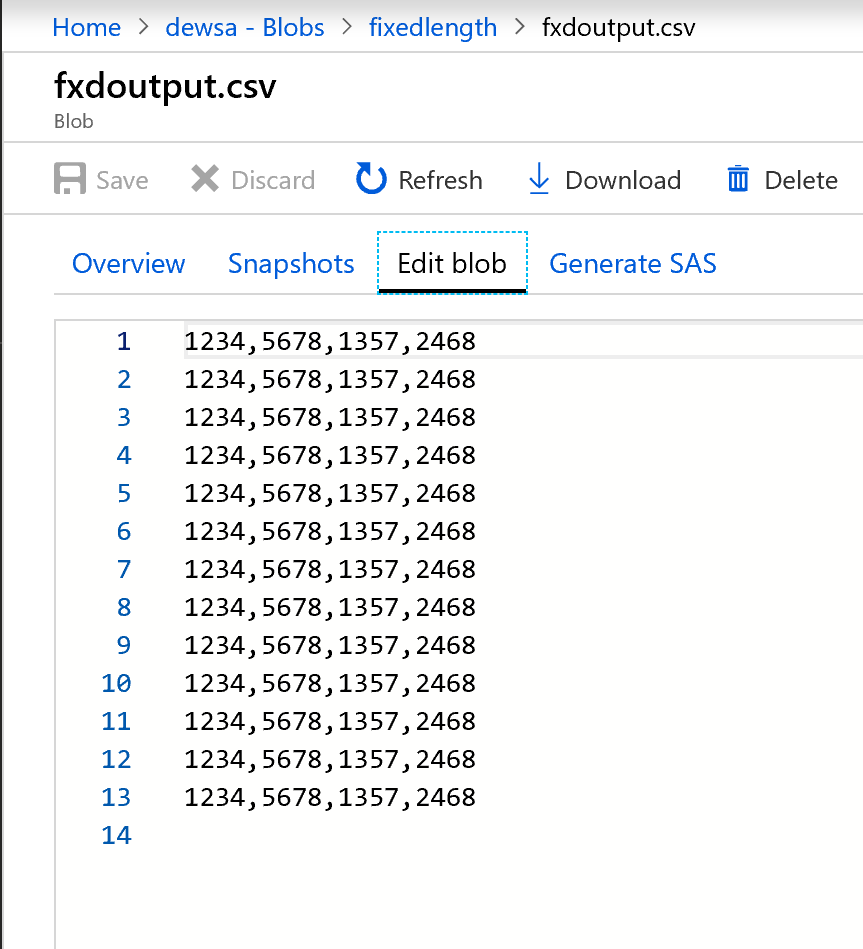
Теперь данные с фиксированной шириной разбиваются на четыре символа, и им присваиваются значения Col1, Col2, Col3, Col4 и т. д. На основе предыдущего примера данные разбиваются на четыре столбца.
Связанный контент
- Создайте оставшуюся часть логики потока данных с помощью преобразований потоков данных для сопоставления.