Копирование данных из Azure Data Lake Storage 1-го поколения в Azure Data Lake Storage 2-го поколения с помощью Фабрики данных Azure
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Хранилище Azure Data Lake Storage 2-го поколения — это набор возможностей аналитики больших данных, который создан на основе хранилища BLOB-объектов Azure. С его помощью можно работать с данными с использованием парадигмы файловой системы или хранилища объектов.
Если в настоящее время используется Azure Data Lake Storage 1-го поколения, то можно оценить Azure Data Lake Storage 2-го поколения, скопировав данные из Data Lake Storage 1-го поколения во 2-е поколения с помощью фабрики данных Azure.
Фабрика данных Azure — это полностью управляемая облачная служба интеграции данных. Эту службу можно использовать для заполнения озера данными из богатого набора локальных и облачных хранилищ данных и экономии времени при создании аналитических решений. Список поддерживаемых соединителей см. в таблице Поддерживаемые хранилища данных.
Фабрика данных Azure предлагает масштабируемое и управляемое решение для перемещения данных. Архитектура фабрики данных является масштабируемой, поэтому она может принимать данные с высокой пропускной способностью. Дополнительные сведения см. в статье Производительность операции копирования.
В этой статье показано, как с помощью средства копирования данных фабрики данных скопировать данные из Azure Data Lake Storage 1-го поколения в Azure Data Lake Storage 2-го поколения. Чтобы копировать данные из других типов хранилищ, необходимо выполнить аналогичные шаги.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
- Учетная запись Azure Data Lake Storage 1-го поколения с сохраненными в ней данными.
- Включена учетная запись хранения Azure с поддержкой Data Lake Storage 2-го поколения. При отсутствии учетной записи хранения создайте ее.
Создание фабрики данных
Если вы еще не создали фабрику данных, выполните действия, описанные в кратком руководстве по созданию фабрики данных с помощью портала Azure и студии Фабрики данных Azure. После создания перейдите к фабрике данных на портале Azure.
Выберите Открыть на плитке Открыть Azure Data Factory Studio, чтобы запустить приложение интеграции данных в отдельной вкладке.
Загрузка данных в Azure Data Lake Storage 2-го поколения
На домашней странице выберите команду Принять, чтобы запустить средство копирования данных.
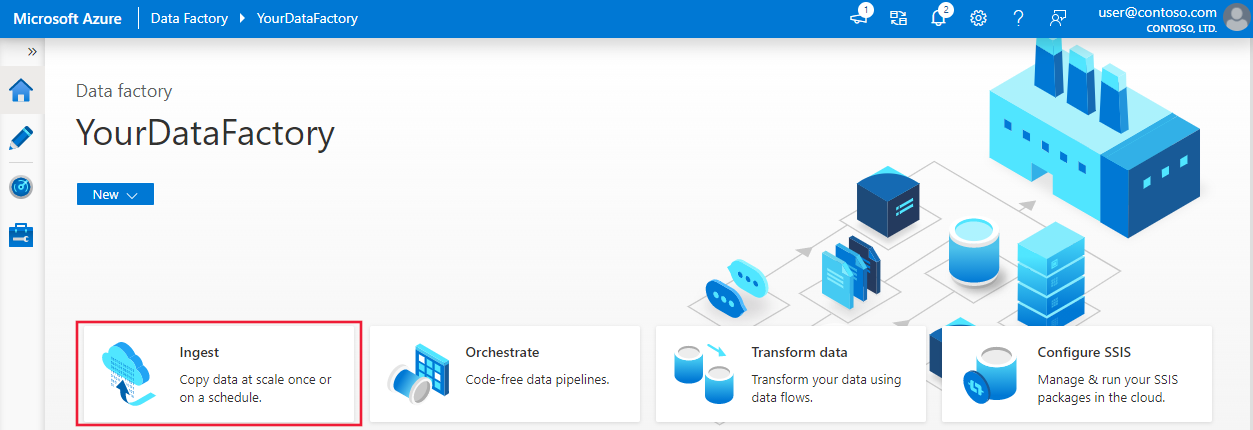
На странице Свойства в разделе Тип задачи выберите Встроенная задача копирования. Затем в разделе Периодичность или расписание задач выберите Запустить сейчас один раз, после чего щелкните Далее.
На странице Исходное хранилище данных нажмите кнопку + Создать новое подключение.
В коллекции соединителя выберите Azure Data Lake Storage 1-го поколения и щелкните Продолжить.
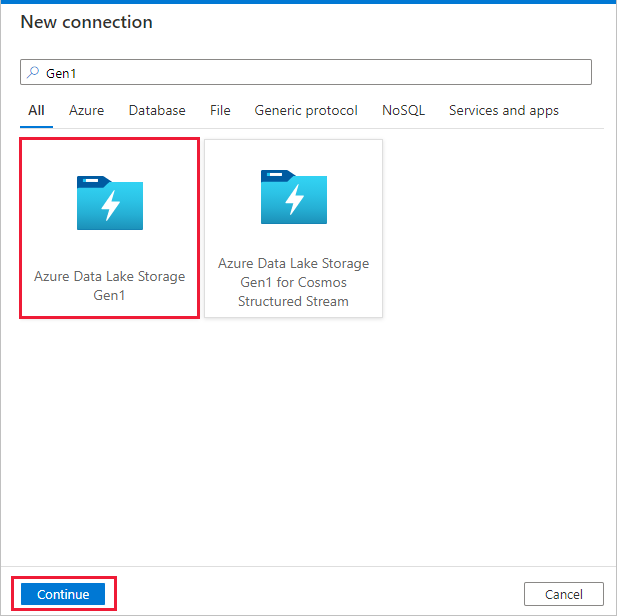
На странице Новое подключение к Azure Data Lake Storage 1-го поколения выполните следующие действия:
- Выберите имя учетной записи Data Lake Storage 1-го поколения и укажите или подтвердите имя клиента.
- Выберите Проверить подключение для проверки настроек. Затем выберите Создать.
Важно!
В этом руководстве используется управляемое удостоверение для ресурсов Azure в целях аутентификации в Azure Data Lake Storage 1-го поколения. Для предоставления соответствующих разрешений управляемому удостоверению в Azure Data Lake Storage 1-го поколения выполните следующие инструкции.
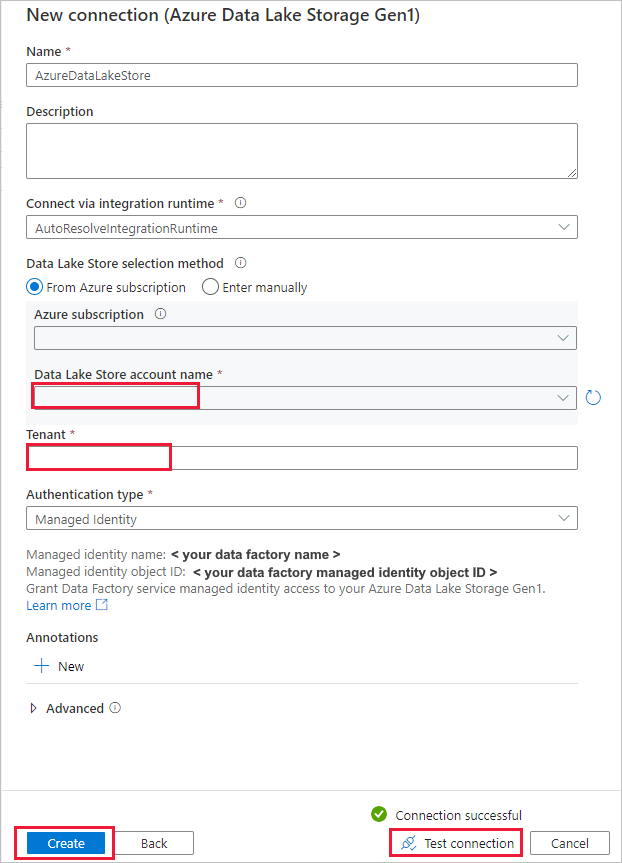
На странице Исходное хранилище данных выполните следующие действия:
- Выберите только что созданное подключение в разделе Подключение.
- В разделе Файл или папка перейдите к папке и файлу, которые необходимо скопировать. Выберите папку или файл и нажмите кнопку ОК.
- Задайте поведение копирования, выбрав параметры Рекурсивное копирование и Двоичное копирование. Выберите Далее.
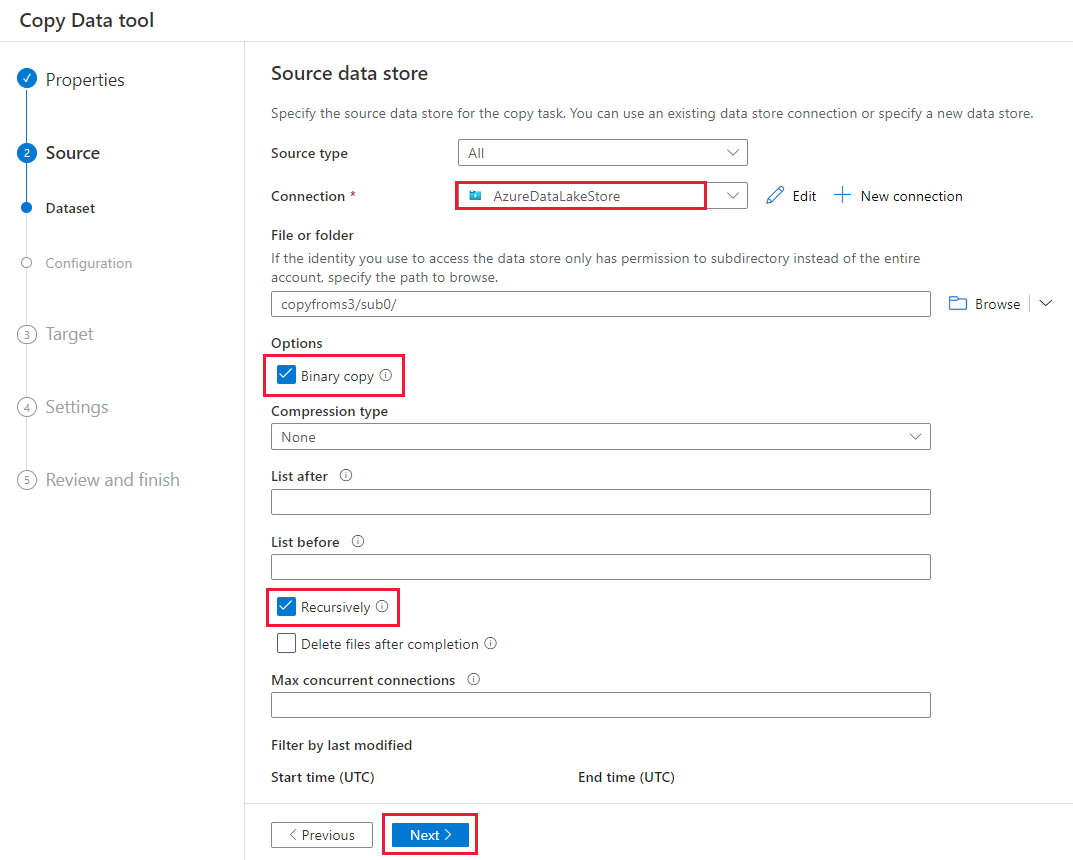
На странице Целевое хранилище данных выберите + Создать подключение>Azure Data Lake Storage 2-го поколения>Продолжить.

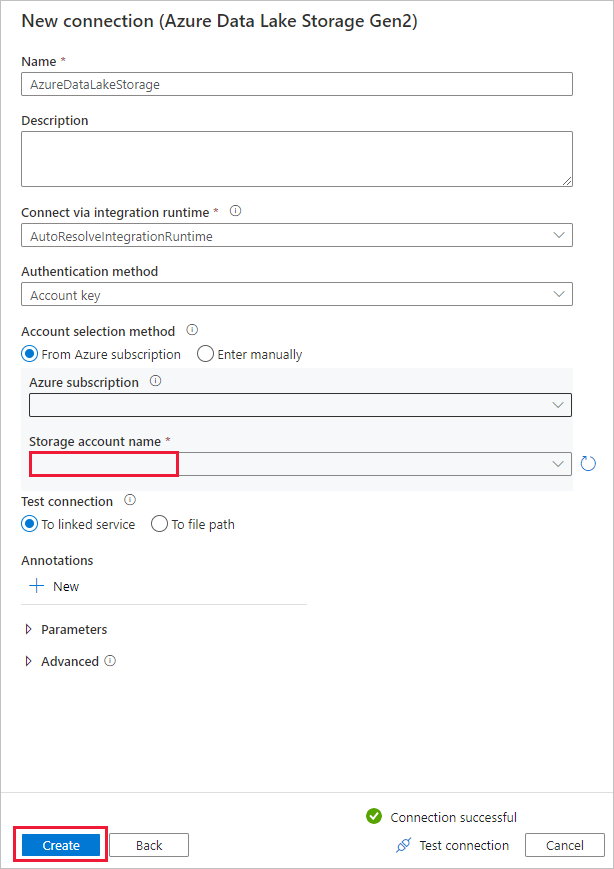
На странице Новое подключение к Azure Data Lake Storage 2-го поколения выполните следующие действия:
- Из раскрывающегося списка Имя учетной записи хранения выберите соответствующую учетную запись Data Lake Storage 2-го поколения.
- Выберите Создать, чтобы создать подключение.
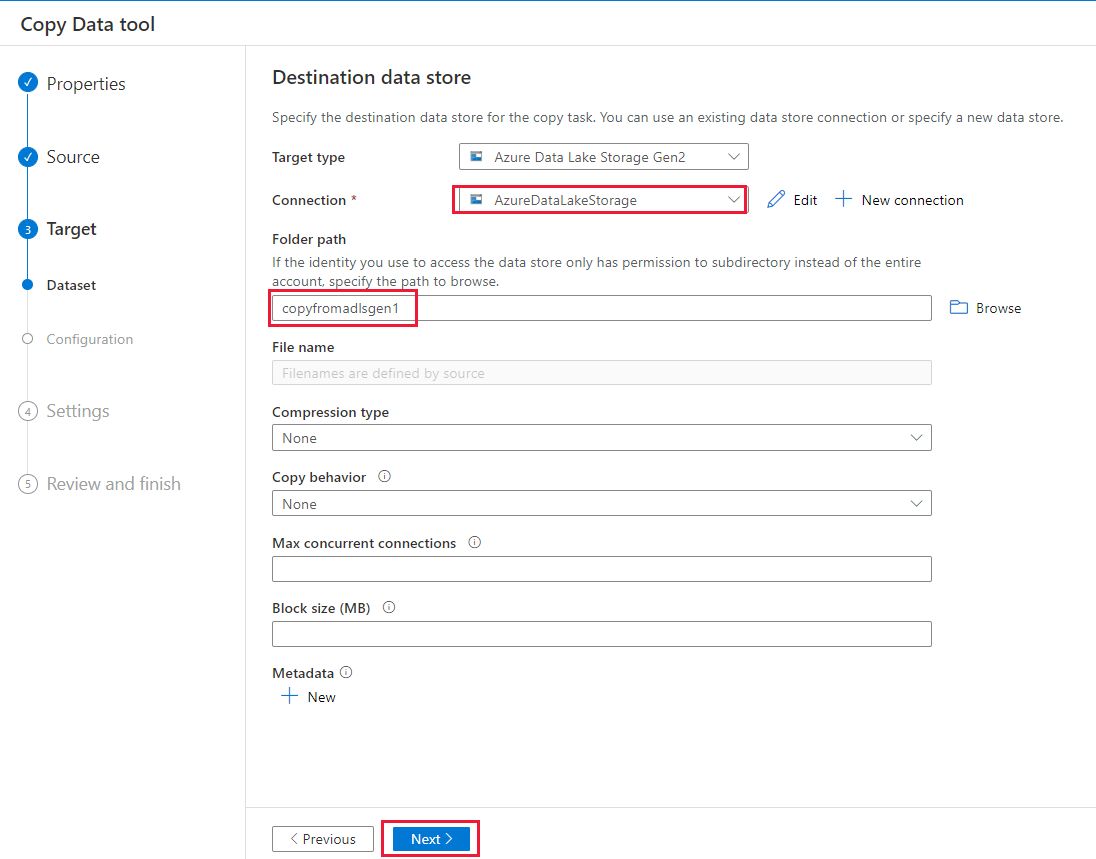
На странице Целевое хранилище данных выполните следующие действия:
- Выберите только что созданное подключение в блоке Подключение.
- В разделе Путь к папке введите copyfromadlsgen1 в качестве имени папки с выходными данными, а затем выберите Далее. Фабрика данных создает соответствующую файловую систему Azure Data Lake Storage 2-го поколения и вложенные папки во время копирования, если они не существуют.
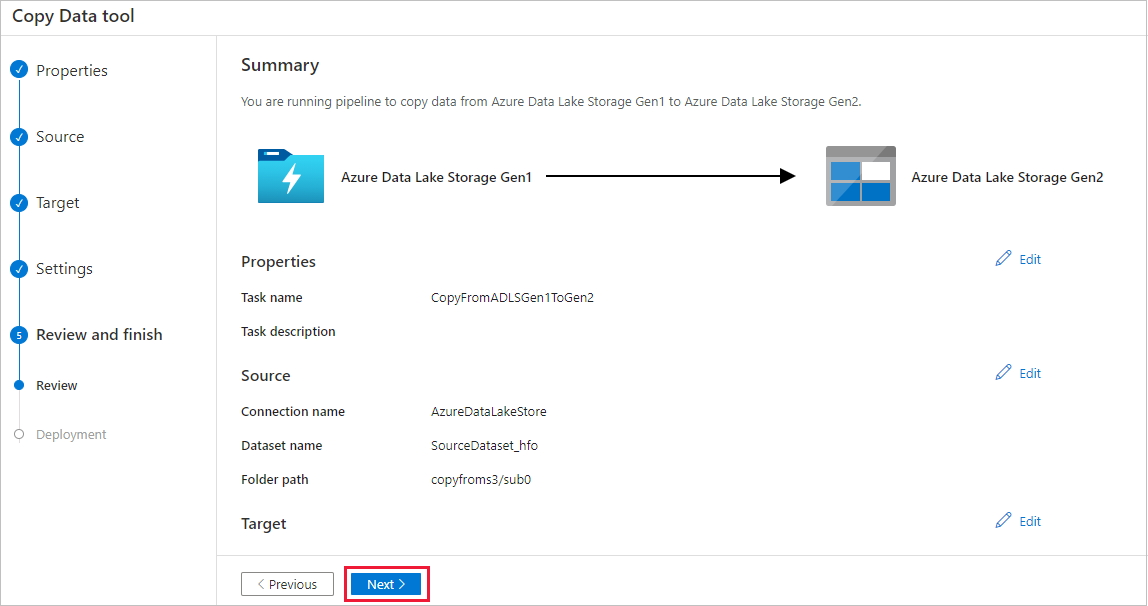
На странице Параметры укажите CopyFromADLSGen1ToGen2 в поле Имя задачи и выберите Далее, чтобы использовать настройки по умолчанию.
Просмотрите параметры на странице Сводка, затем нажмите кнопку Далее.
На странице Deployment (Развертывание) нажмите кнопку Monitor (Отслеживать), чтобы отслеживать конвейер.
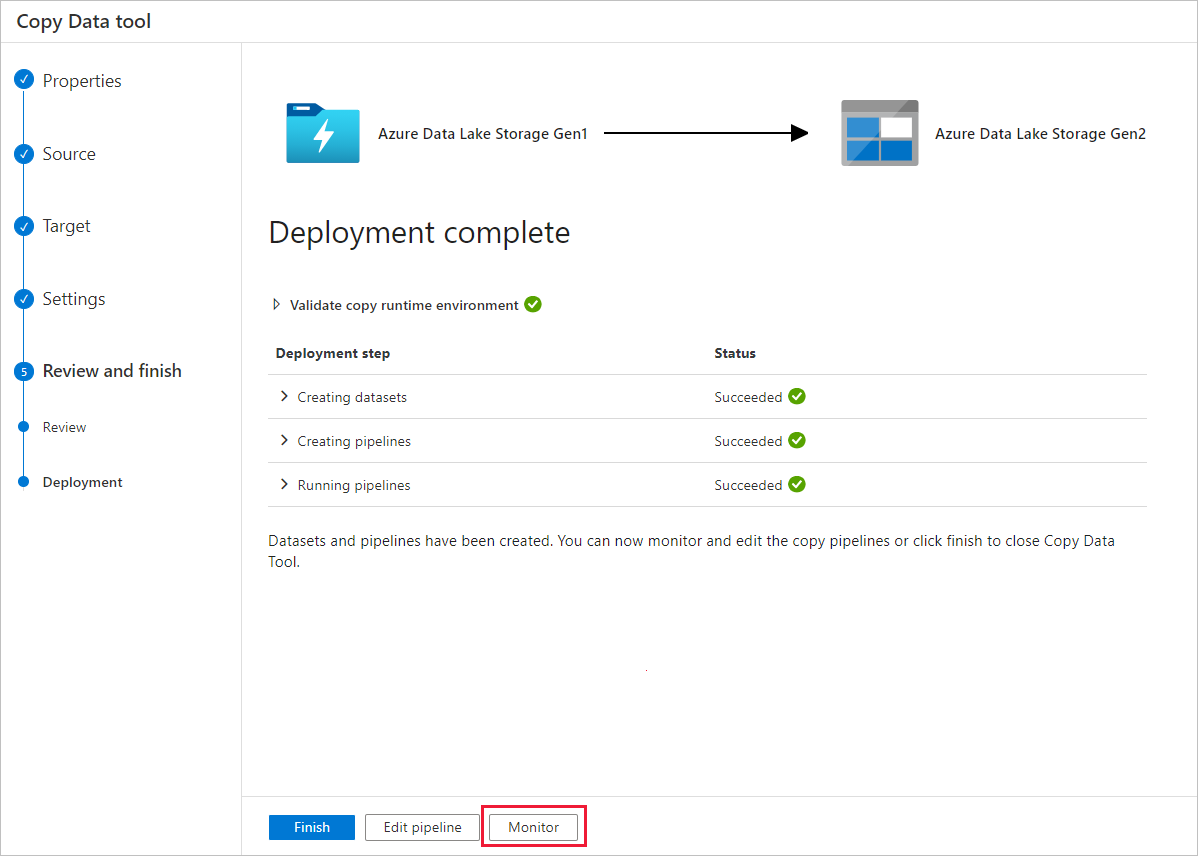
Обратите внимание, что слева автоматически выбирается вкладка Мониторинг. В столбце Имя конвейера содержатся ссылки для просмотра сведений о выполнении действий и повторного запуска конвейера.
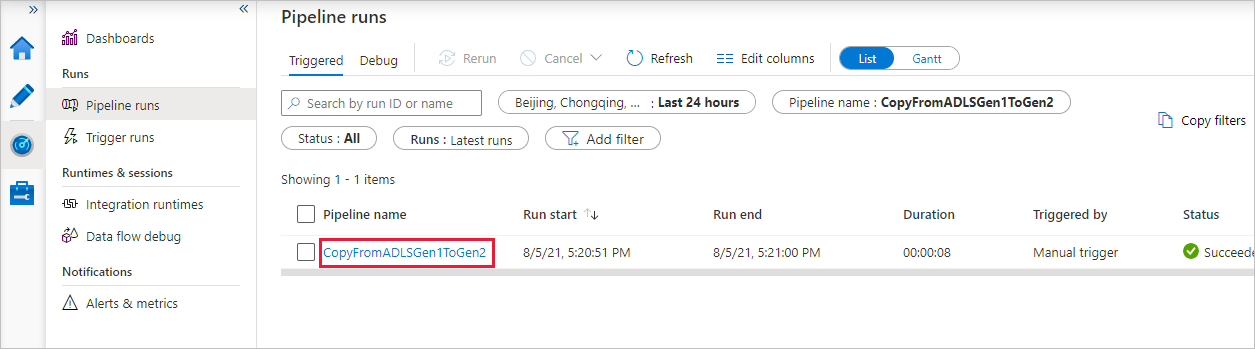
Чтобы просмотреть сведения о выполнении действий, связанных с выполнением конвейера, выберите ссылку в столбце Имя конвейера. В этом конвейере определено только одно действие (действие копирования), поэтому вы увидите только одну запись. Чтобы вернуться к представлению "Запуски конвейера", в меню навигации вверху выберите ссылку Все запуски конвейеров. Щелкните Обновить, чтобы обновить список.
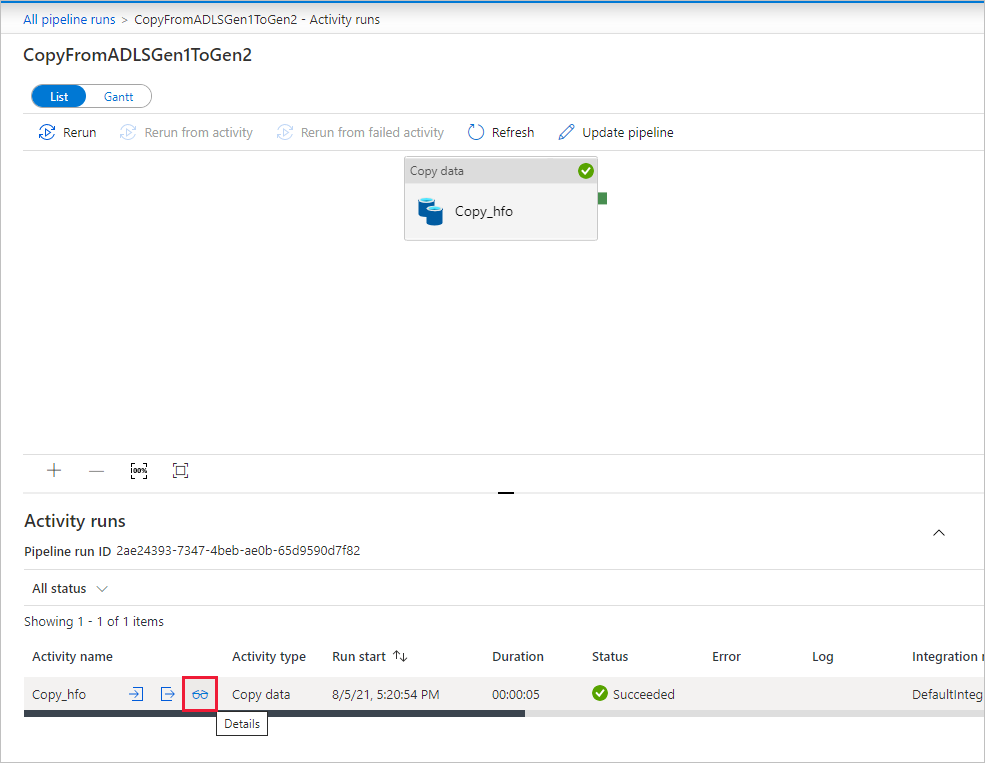
Чтобы отслеживать сведения о выполнении каждого действия копирования, выберите ссылку Сведения (изображение очков) в столбце Имя действия в представлении мониторинга действия. Вы можете отслеживать такие сведения, как объем данных, копируемых из источника в приемник, пропускная способность данных, шаги выполнения с длительностью и используемые параметры.
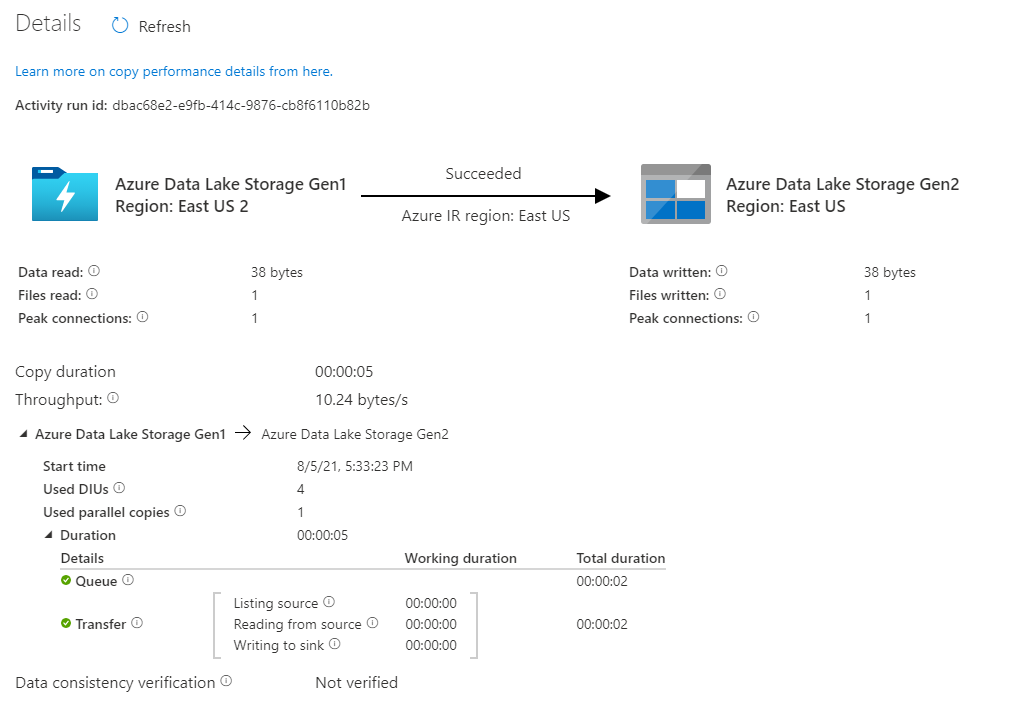
Убедитесь, что данные скопированы в Data Lake Storage 2-го поколения.
Рекомендации
Чтобы оценить обновление от Azure Data Lake Storage 1-го поколения до Azure Data Lake Storage 2-го поколения в целом, см. статью Обновление решений аналитики больших данных из Azure Data Lake Storage 1-го поколения в Azure Data Lake Storage 2-го поколения. В следующих разделах представлены рекомендации по использованию Фабрики данных для обновления данных с Data Lake Storage 1-го поколения до Data Lake Storage 2-го поколения.
Перенос исходных моментальных снимков
Производительность
Фабрика данных Azure имеет бессерверную архитектуру, которая обеспечивает параллелизм на разных уровнях. Это позволяет разработчикам создавать конвейеры для полного использования пропускной способности сети и хранилища с целью передачи данных в среде с максимальной скоростью.
Клиенты успешно выполнили перенос сотен миллионов файлов, общий объем которых измеряется петабайтами, из Data Lake Storage 1-го поколения в версию 2-го поколения со стабильной пропускной способностью 2 Гбит/с и выше.
Вы можете достичь большей скорости перемещения данных, применяя различные уровни параллелизма:
- Для одного действия копирования можно использовать масштабируемые вычислительные ресурсы: при использовании Azure Integration Runtime можно указать до 256 единиц интеграции данных (DIU) для каждого бессерверного действия копирования. При использовании локальной среды выполнения интеграции можно вертикально увеличить масштаб компьютера вручную или горизонтально увеличить масштаб до нескольких компьютеров (до 4 узлов), и действие копирования разделит набор файлов по всем узлам.
- Одно действие копирования считывает данные из хранилища данных и записывает их в него с помощью нескольких потоков.
- Поток управления Фабрики данных Azure может запускать несколько операций копирования параллельно, например с помощью цикла For Each.
Секции данных
Если общий размер данных в Data Lake Storage 1-го поколения меньше 10 ТБ, а число файлов меньше 1 млн, можно скопировать все данные в рамках одного выполнения действия копирования. Если требуется скопировать данные большего объема или обеспечить гибкое управление переносом данных в пакетах и выполнение каждого из них в течение определенного промежутка времени, разбейте данные на разделы. Разбивка данных на разделы, кроме всего прочего, уменьшает риск возникновения любой непредвиденной проблемы.
Для секционирования файлов в свойстве действия копирования можно использовать параметр name range- listAfter/listBefore. Каждое действие копирования можно настроить для копирования одного раздела за раз, чтобы несколько операций копирования могли одновременно копировать данные из одной учетной записи Data Lake Storage 1-го поколения.
Ограничение частоты
Рекомендуется провести оценку производительности с помощью репрезентативного образца набора данных, чтобы можно было определить подходящий размер секции.
Начните с одной секции и одного действия копирования с количеством единиц интеграции данных по умолчанию. Для параметра параллельного копирования предлагается всегда выбирать вариант Пусто (по умолчанию). Если пропускная способность копирования вам не подходит, для поиска и устранения узких мест производительности воспользуйтесь инструкциями по настройке производительности.
Постепенно увеличивайте количество единиц интеграции данных, пока не будет достигнуто ограничение пропускной способности и скорости ввода-вывода сети или хранилищ данных либо максимальное количество единиц интеграции данных (256), разрешенное для одного действия копирования.
Если вы максимизировали производительность одного действия копирования, но еще не вышли на максимальную пропускную способность своей среды, можно параллельно выполнять несколько действий копирования.
Если при мониторинге действий копирования возникает много ошибок регулирования, это означает, что достигнуто ограничение по емкости для учетной записи хранения. ADF будет автоматически повторять попытку для каждой ошибки регулирования, чтобы исключить потерю данных, однако слишком большое число попыток может ухудшить пропускную способность копирования. В таком случае количество выполняемых параллельно операций копирования рекомендуется уменьшить, чтобы уменьшить число ошибок регулирования. Если данные копируются с помощью одного действия копирования, рекомендуется уменьшить количество DIU.
Перенос разностных данных
Можно использовать несколько подходов для загрузки только новых или обновленных файлов из Data Lake Storage 1-го поколения.
- Загрузка новых или обновленных файлов с разбивкой по времени имен папок или файлов. Например, /2019/05/13*.
- Загрузка новых или обновленных файлов по параметру LastModifiedDate. При копировании большого количества файлов сначала выполните секционирование, чтобы избежать снижения пропускной способности, когда одно действие копирования проверяет всю вашу учетную запись Data Lake Storage 1-го поколения в поиске новых файлов.
- Выявление новых или обновленных файлов с помощью любого стороннего средства или решения. Затем передайте имя файла или папки конвейеру Фабрики данных с помощью параметра, таблицы или файла.
Надлежащая частота выполнения добавочной загрузки зависит от общего количества файлов в хранилище данных Azure Data Lake Storage 1-го поколения и объема новых или обновленных файлов, загружаемых каждый раз.
Сетевая безопасность
По умолчанию Фабрика данных Azure передает данные из Azure Data Lake Storage 1-го поколения в версию 2-го поколения через зашифрованное подключение по протоколу HTTPS. HTTPS обеспечивает шифрование данных при передаче и предотвращает прослушивание трафика и атаки типа "злоумышленник в середине".
Кроме того, если вы не хотите, чтобы данные передавались через общедоступный Интернет, вы можете повысить уровень безопасности, передавая данные через частную сеть.
Сохранение списков управления доступом (ACL)
Если решено реплицировать списки ACL вместе с файлами данных при переносе с Data Lake Storage 1-го поколения на Data Lake Storage 2-го поколения, см. статью Сохранение списков ACL из Data Lake Storage 1-го поколения.
Устойчивость
Фабрика данных Azure имеет встроенный механизм повтора в рамках одного действия копирования, позволяющий справляться с определенным количеством временных сбоев в хранилищах данных или в базовой сети. Если переносится более 10 ТБ данных, рекомендуется секционировать данные, чтобы уменьшить риск непредвиденных проблем.
Вы также можете включить отказоустойчивость в действии копирования, чтобы пропустить предварительно определенные ошибки. Вы также можете включить проверку согласованности данных в действии копирования, чтобы гарантировать, что данные не только успешно копируются из исходного в целевое хранилище, но и согласованы между ними.
Разрешения
В Фабрике данных соединитель Data Lake Storage 1-го поколения поддерживает субъект-службу и управляемое удостоверение для проверки подлинности ресурсов Azure. Соединитель Data Lake Storage 2-го поколения поддерживает ключ учетной записи, субъект-службу и управляемое удостоверение для проверки подлинности ресурсов Azure. Чтобы фабрика данных могла перемещаться и копировать все файлы или списки управления доступом (ACL), необходимо предоставить достаточное количество разрешений учетной записи для доступа, чтения или записи всех файлов и задания списков управления доступом, если вы решили. Вы должны предоставить учетной записи роль супер-пользователя или владельца во время миграции и удалить повышенные разрешения после завершения миграции.