Управление кодом обучения с помощью запусков MLflow
В этой статье описывается запуск MLflow для управления обучением машинного обучения. В ней также содержатся рекомендации по управлению и сравнению запусков между экспериментами.
Запуск MFlflow соответствует однократному выполнению кода модели. При каждом запуске записываются следующие сведения:
- Источник: имя записной книжки, которая инициировала запуск, или имя проекта и точка входа для запуска.
- Версия: хэш фиксации Git, если записная книжка хранится в папке Databricks Git или запускается из проекта MLflow. В противном случае редакция записной книжки.
- Время начала и окончания: время начала и окончания выполнения.
- Параметры: параметры модели, сохраненные в виде пар "ключ-значение". Ключи и значения являются строками.
- Метрики: метрики оценки модели, сохраненные в виде пар "ключ-значение". Значение является числом. Каждая метрика может быть обновлена в течение всего запуска (например, для отслеживания сходимости функции потерь модели), и MLflow фиксирует эти изменения, позволяя визуализировать их историю.
- Теги: метаданные запуска, сохраненные в виде пар "ключ-значение". Теги можно обновлять во время и после завершения запуска. Ключи и значения являются строками.
- Артефакты: выходные файлы в любом формате. В частности, в качестве артефактов можно записывать изображения, модели (например, сериализованную модель обучения scikit-learn) и файлы данных (например, файл Parquet).
Все запуски (циклы) MLflow регистрируются в активном эксперименте. Если вы не установили эксперимент явным образом в качестве активного, запуски регистрируются в эксперименте записной книжки.
Просмотреть запуски
Вы можете просмотреть сведения о запуске со страницы соответствующего родительского эксперимента или непосредственно из записной книжки, создавшей этот запуск.
На странице эксперимента в таблице запусков щелкните время начала запуска.
В записной книжке щелкните ![]() рядом с датой и временем выполнения на боковой панели "Эксперимент".
рядом с датой и временем выполнения на боковой панели "Эксперимент".
На экране запуска отображаются параметры этого, полученные в результате метрики, а также все теги и примечания. Чтобы отобразить заметки, параметры, метрики или теги для этого запуска, щелкните ![]() слева от метки.
слева от метки.
На этом экране также можно просмотреть артефакты, сохраненные в результате запуска.
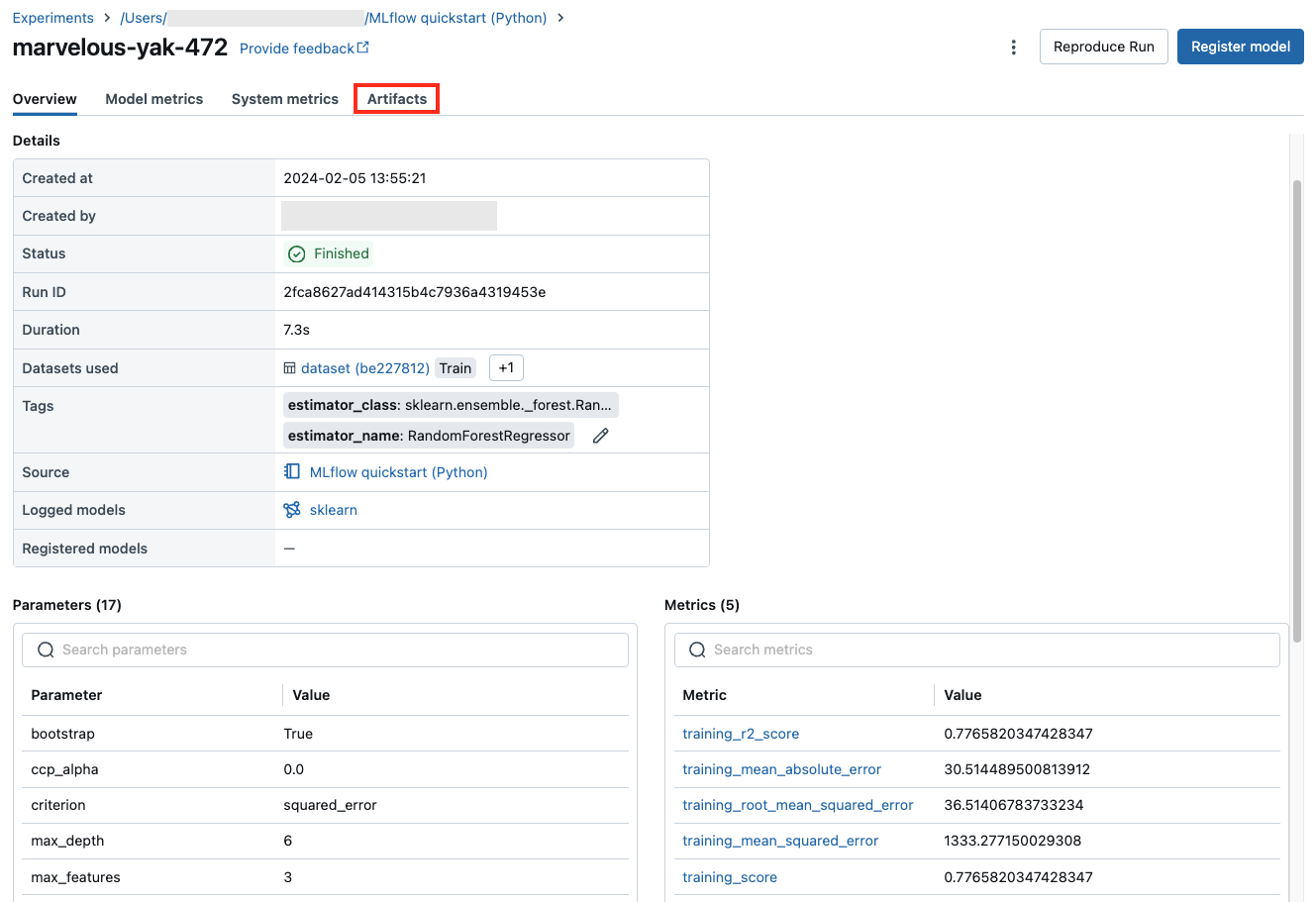
Фрагменты кода для прогнозирования
Если вы регистрируете модель из запуска, модель появится в разделе артефактов этой страницы . Чтобы посмотреть фрагменты кода, демонстрирующие загрузку и использование модели для прогнозирования в кадрах данных DataFrame Spark и pandas, щелкните имя модели.
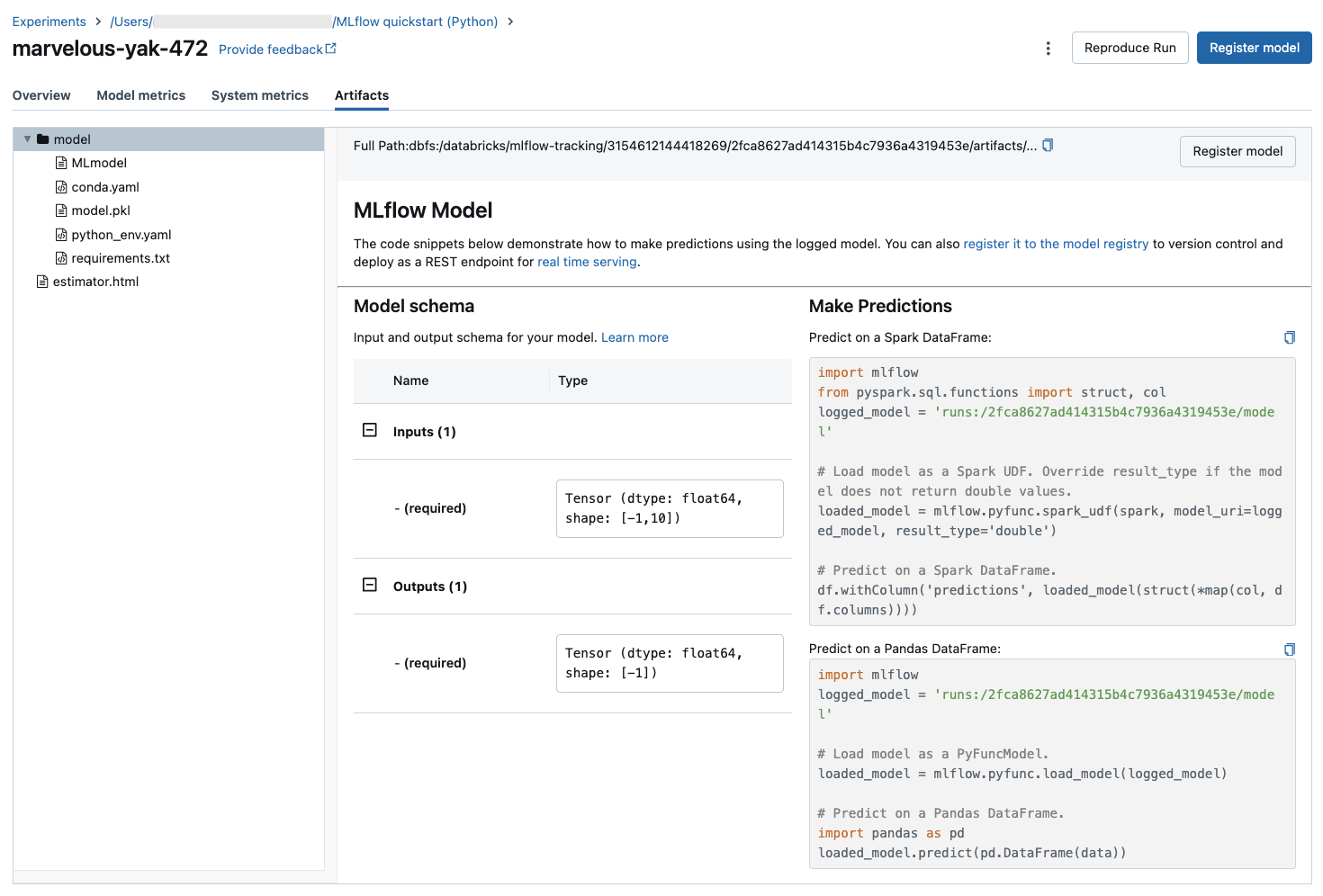
Просмотр записной книжки или проекта Git, используемого для запуска
Чтобы просмотреть версию записной книжки, в которой был создан запуск, выполните указанные ниже действия.
- На странице эксперимента щелкните ссылку в столбце Source (Источник).
- На странице запуска щелкните ссылку рядом с пунктом Source (Источник).
- В записной книжке на боковой панели "Эксперимент запускается" щелкните значок
 записной книжки в поле для выполнения эксперимента.
записной книжки в поле для выполнения эксперимента.
В главном окне отобразится версия связанной с этим запуском записной книжки, а на панели выделения будут указаны его дата и время.
Если запуск был инициирован удаленно из проекта Git, щелкните ссылку в поле Git Commit (Фиксация Git), чтобы открыть версию проекта, используемую в этом запуске. Ссылка в поле Source (Источник) открывает главную ветвь проекта Git, используемого в запуске.
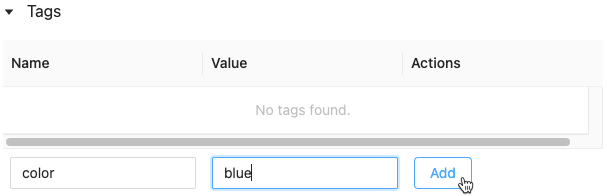
Добавление тега для запуска
Теги — это пары "ключ-значение", которые можно создавать и использовать для поиска запусков.
На странице запуска щелкните
 , если он еще не открыт. Отобразится таблица тегов.
, если он еще не открыт. Отобразится таблица тегов.
Щелкните поля Имя и Значение и введите ключ и значение для тега.
Нажмите кнопку Добавить.
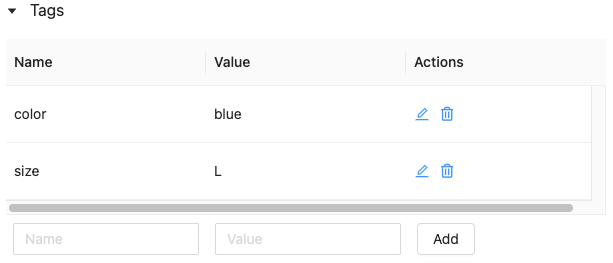
Изменение или удаление тега для запуска
Чтобы изменить или удалить существующий тег, используйте значки в столбце Действия.
Воспроизведение программной среды запуска
Вы можете в точности воспроизвести программную среду запуска, выбрав Reproduce Run (Воспроизвести запуск). Откроется следующее диалоговое окно:
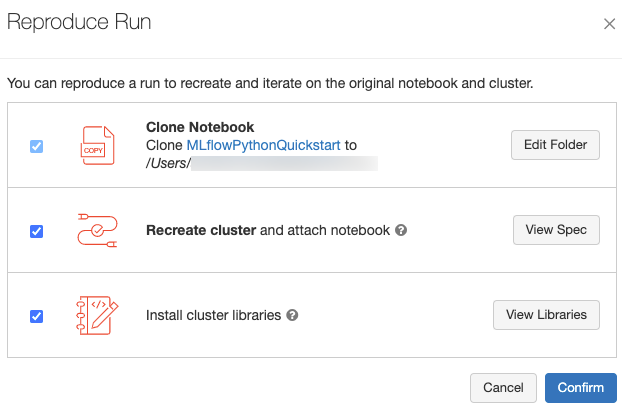
Если выбраны параметры по умолчанию, при нажатии кнопки Confirm (Подтвердить):
- Записная книжка клонируется в расположении, которое отображается в диалоговом окне.
- Если исходный кластер по-прежнему существует, то клонированная записная книжка присоединяется к нему, и кластер запускается.
- Если исходный кластер больше не существует, создается и запускается новый кластер с такой же конфигурацией, включая все установленные библиотеки. Записная книжка присоединяется к новому кластеру.
Вы можете выбрать для клонированной записной книжки другое расположение и проверить конфигурацию кластера и установленные библиотеки:
- Чтобы выбрать другую папку для сохранения клонированной записной книжки, щелкните Edit Folder (Изменить папку).
- Чтобы просмотреть спецификацию кластера, щелкните View Spec (Просмотр спецификации). Чтобы клонировать только записную книжку, но не кластер, снимите этот флажок.
- Чтобы просмотреть библиотеки, установленные в исходном кластере, щелкните View Libraries (Просмотр библиотек). Если устанавливать те же библиотеки, что и в исходном кластере, не требуется, снимите этот флажок.
Управление запусками
Переименование запуска
Чтобы переименовать выполнение, щелкните ![]() в правом верхнем углу страницы запуска и выберите "Переименовать".
в правом верхнем углу страницы запуска и выберите "Переименовать".
Фильтрация запусков
Запуски можно искать по значениям параметров или метрик. Также можно искать запуски по тегам.
Чтобы найти запуски, соответствующие выражению с определенными значениями параметров и метрик, введите запрос в поле поиска и щелкните Search (Поиск). Ниже приведены примеры синтаксиса запросов.
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3Чтобы найти запуски по тегу, введите теги в таком формате:
tags.<key>="<value>". Как видно, строковые значения заключаются в кавычки.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Ключи и значения могут содержать пробелы. Если ключ содержит пробелы, его необходимо заключить в обратные кавычки, как показано в примере.
tags.`my custom tag` = "my value"
Также можно отфильтровать запуски по признаку их состояния (активный или удаленный) и в зависимости от того, связана ли с запуском определенная версия модели. Для этого в раскрывающихся меню "Состояние и время создания" выберите нужные элементы.

Скачивание запусков
Выберите один или несколько запусков.
Щелкните Download CSV (Скачать CSV-файл). Будет скачан CSV-файл, содержащий следующие поля:
Run ID,Name,Source Type,Source Name,User,Status,<parameter1>,<parameter2>,...,<metric1>,<metric2>,...
Удаление запусков
Вы можете удалить запуски с помощью пользовательского интерфейса Databricks Машинное обучение, выполнив следующие действия.
- В эксперименте выберите один или несколько запусков, установив флажки слева от них.
- Нажмите Удалить.
- Если запуск является родительским, решите, нужно ли также удалить запуски-потомки. Этот параметр выбирается по умолчанию.
- Нажмите кнопку Удалить, чтобы подтвердить операцию. Удаленные запуски сохраняются в течение 30 дней. Чтобы отобразить удаленные запуски, в поле State (Состояние) выберите Deleted (Удаленные).
Выполнение массового удаления на основе времени создания
Для массового удаления экспериментов, созданных до или в метке времени UNIX, можно использовать Python.
Используя Databricks Runtime 14.1 или более поздней версии, вы можете вызвать mlflow.delete_runs API для удаления запусков и вернуть число удаленных запусков.
Ниже приведены mlflow.delete_runs параметры:
experiment_id: идентификатор эксперимента, содержащего запуски для удаления.max_timestamp_millis: максимальная метка времени создания в миллисекундах с эпохи UNIX для удаления запусков. Удаляются только запуски, созданные до или в данный момент времени.max_runs: необязательный параметр. Положительное целое число, указывающее максимальное количество запусков для удаления. Максимально допустимое значение для max_runs равно 10000. Если значение не указано,max_runsпо умолчанию используется значение 10000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
С помощью Databricks Runtime 13.3 LTS или более ранней версии можно запустить следующий клиентский код в записной книжке Azure Databricks.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
См. документацию по API экспериментов Azure Databricks для параметров и спецификаций возвращаемых значений для удаления запусков на основе времени создания.
Восстановление запусков
Вы можете восстановить ранее удаленные запуски с помощью пользовательского интерфейса Databricks Машинное обучение.
- На странице "Эксперимент" выберите "Удалить" в поле "Состояние", чтобы отобразить удаленные запуски.
- Выберите один или несколько запусков, щелкнув в поле проверка box слева от запуска.
- Щелкните Восстановить.
- Нажмите кнопку " Восстановить ", чтобы подтвердить. Чтобы отобразить восстановленные запуски, выберите "Активный " в поле "Состояние".
Выполнение массового восстановления на основе времени удаления
Вы также можете использовать Python для массового восстановления экспериментов, которые были удалены или после метки времени UNIX.
Используя Databricks Runtime 14.1 или более поздней версии, вы можете вызвать mlflow.restore_runs API для восстановления запусков и вернуть количество восстановленных запусков.
Ниже приведены mlflow.restore_runs параметры:
experiment_id: идентификатор эксперимента, содержащего запуски для восстановления.min_timestamp_millis: минимальная метка времени удаления в миллисекундах с момента эпохи UNIX для восстановления запусков. Восстанавливаются только удаленные или после этого метки времени.max_runs: необязательный параметр. Положительное целое число, указывающее максимальное количество запусков для восстановления. Максимально допустимое значение для max_runs равно 10000. Если значение не указано, max_runs по умолчанию — 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
С помощью Databricks Runtime 13.3 LTS или более ранней версии можно запустить следующий клиентский код в записной книжке Azure Databricks.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Сведения о параметрах и спецификациях возвращаемых значений для восстановления на основе времени удаления см. в документации по API экспериментов Azure Databricks.
Сравнение запусков
Вы можете сравнить выполнения из одного или нескольких экспериментов. На странице Сравнение выполнений представлены сведения о выбранных выполнениях в графическом и табличном форматах. Вы также можете создавать визуализации результатов выполнения и таблиц сведений о выполнении, параметров выполнения и метрик.
Чтобы создать визуализацию:
- Выберите тип графика (График с параллельными координатами, Точечная диаграмма или Контурная диаграмма).
Для варианта График с параллельными координатами выберите параметры и метрики для построения графика. Здесь можно определить связи между выбранными параметрами и метриками, что помогает лучше определить пространство настройки гиперпараметров для моделей.
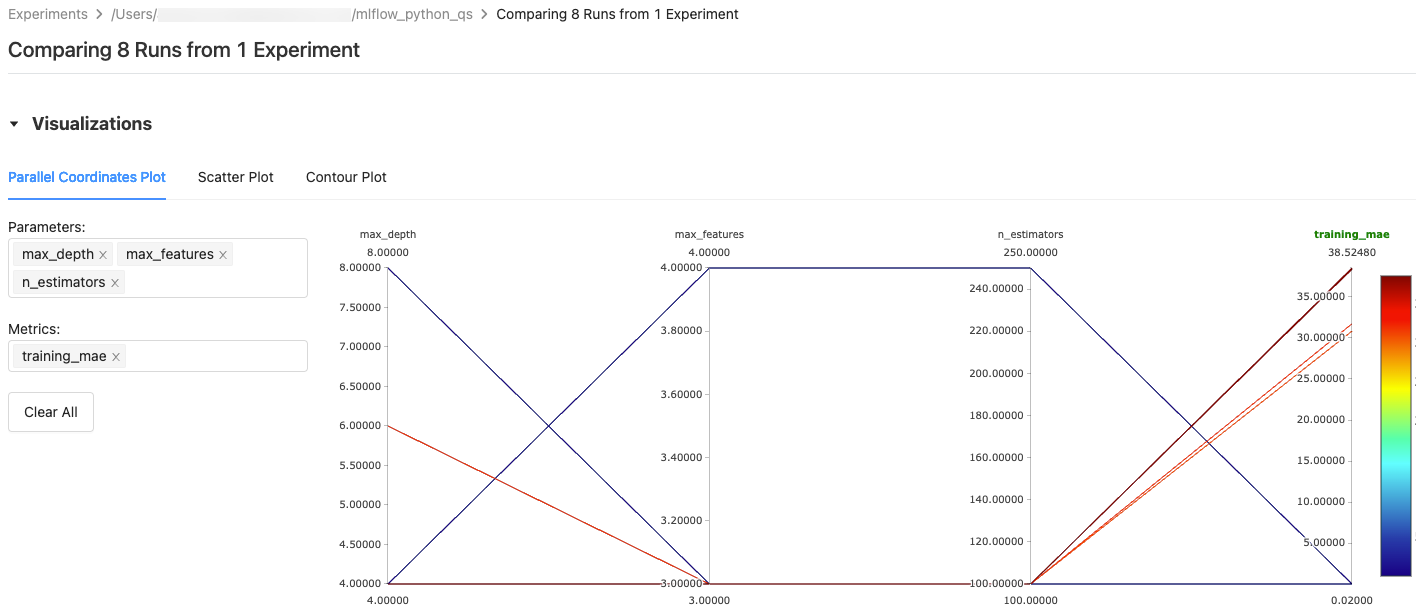
Для вариантов Точечная диаграмма или Контурная диаграмма выберите параметр или метрику для отображения на каждой оси.
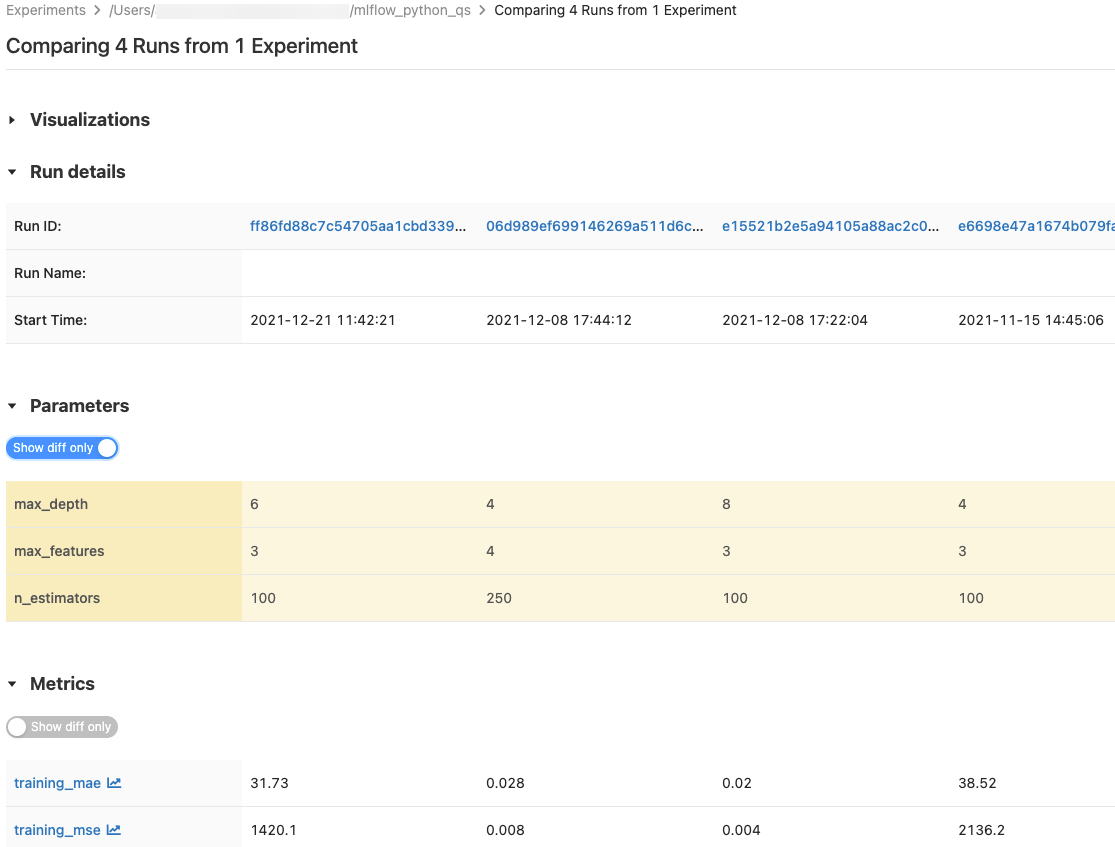
В таблицах Параметры и Метрики отображаются параметры выполнения и метрики из всех выбранных выполнений. Столбцы в этих таблицах определяются таблицей Сведения о выполнении выше. Для простоты можно скрыть параметры и метрики, идентичные во всех выбранных запусках, переключив переключатель  .
.
Сравнение выполнений из одного эксперимента
- На странице эксперимента выберите два или несколько выполнений, установив флажок слева от выполнения, или выберите все выполнения, установив флажок в верхней части столбца.
- Щелкните Compare (Сравнить). Откроется экран сравнения
<N>запусков.
Сравнение выполнений из нескольких экспериментов
- На странице экспериментов выберите эксперименты, которые вы хотите сравнить, щелкнув поле слева от имени эксперимента.
- Щелкните Сравнить (n) (n — количество выбранных экспериментов). Откроется экран со всеми выполнениями из выбранных экспериментов.
- Выберите два или несколько выполнений, установив флажок слева от выполнения, или выберите все выполнения, установив флажок в верхней части столбца.
- Щелкните Compare (Сравнить). Откроется экран сравнения
<N>запусков.
Копирование выполнений между рабочими областями
Чтобы импортировать или экспортировать выполнения MLflow в рабочую область Databricks или из нее, вы можете использовать управляемый сообществом проект с открытым кодом MLflow Export-Import.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по