Выполнение задания Azure Databricks с бессерверными вычислениями для рабочих процессов
Внимание
Бессерверные вычисления для рабочих процессов доступны в общедоступной предварительной версии. Сведения о доступности и включении см. в разделе "Включение общедоступной предварительной версии бессерверных вычислений".
Внимание
Так как общедоступная предварительная версия бессерверных вычислений для рабочих процессов не поддерживает управление исходящим трафиком, ваши задания имеют полный доступ к Интернету.
Бессерверные вычисления для рабочих процессов позволяют выполнять задание Azure Databricks без настройки и развертывания инфраструктуры. Благодаря бессерверным вычислениям вы можете сосредоточиться на реализации конвейеров обработки и анализа данных, а Azure Databricks эффективно управляет вычислительными ресурсами, включая оптимизацию и масштабирование вычислительных ресурсов для рабочих нагрузок. Автомасштабирование и фотона автоматически включены для вычислительных ресурсов, выполняющих задание.
Бессерверные вычисления для рабочих процессов автоматической оптимизации автоматически оптимизируют вычисления путем выбора соответствующих ресурсов, таких как типы экземпляров, память и обработчики обработки на основе рабочей нагрузки. Автоматическая оптимизация также автоматически повторяет неудачные задания.
Databricks автоматически обновляет версию Среды выполнения Databricks для поддержки улучшений и обновлений до платформы, обеспечивая стабильность заданий Azure Databricks. Сведения о текущей версии среды выполнения Databricks, используемой бессерверными вычислениями для рабочих процессов, см. в заметках о выпуске бессерверных вычислений.
Так как разрешение на создание кластера не требуется, все пользователи рабочей области могут использовать бессерверные вычисления для выполнения рабочих процессов.
В этой статье описывается использование пользовательского интерфейса заданий Azure Databricks для создания и запуска заданий, использующих бессерверные вычисления. Вы также можете автоматизировать создание и выполнение заданий, использующих бессерверные вычисления с ПОМОЩЬЮ API заданий, пакетов ресурсов Databricks и пакета SDK Databricks для Python.
- Дополнительные сведения об использовании API заданий для создания и запуска заданий, использующих бессерверные вычисления, см. в справочнике по REST API.
- Сведения об использовании пакетов ресурсов Databricks для создания и запуска заданий, использующих бессерверные вычисления, см. в статье "Разработка задания в Azure Databricks с помощью пакетов ресурсов Databricks".
- Сведения об использовании пакета SDK Databricks для Python для создания и запуска заданий, использующих бессерверные вычисления, см. в пакете SDK Databricks для Python.
Требования
- Рабочая область Azure Databricks должна включать каталог Unity.
- Так как бессерверные вычисления для рабочих процессов используют режим общего доступа, рабочие нагрузки должны поддерживать этот режим доступа.
- Рабочая область Azure Databricks должна находиться в поддерживаемом регионе. Ознакомьтесь с регионами Azure Databricks.
Создание задания с помощью бессерверных вычислений
Бессерверные вычисления поддерживаются с помощью записных книжек, скрипта Python, dbt и типов задач колеса Python. По умолчанию бессерверные вычисления выбираются в качестве типа вычислений при создании нового задания и добавляют один из этих поддерживаемых типов задач.
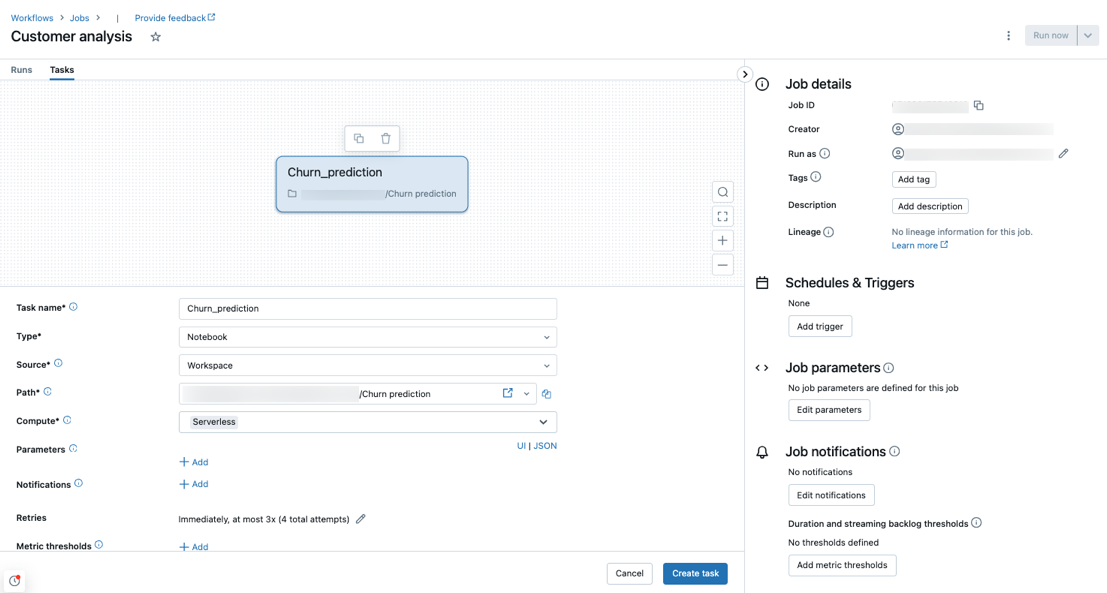
Databricks рекомендует использовать бессерверные вычисления для всех задач задания. Можно также указать различные типы вычислений для задач в задании, которые могут потребоваться, если тип задачи не поддерживается бессерверными вычислениями для рабочих процессов.
Настройка существующего задания для использования бессерверных вычислений
При изменении задания можно переключить существующее задание на использование бессерверных вычислений для поддерживаемых типов задач. Чтобы переключиться на бессерверные вычисления, выполните указанные действия.
- На боковой панели сведений о задании щелкните "Переключиться" в разделе "Вычисления", нажмите кнопку "Создать", введите или обновите все параметры и нажмите кнопку "Обновить".
- Щелкните
 в раскрывающемся меню "Вычисления" и выберите "Бессерверный".
в раскрывающемся меню "Вычисления" и выберите "Бессерверный".

Планирование записной книжки с помощью бессерверных вычислений
Помимо использования пользовательского интерфейса заданий для создания и планирования задания с помощью бессерверных вычислений, можно создать и запустить задание, использующее бессерверные вычисления непосредственно из записной книжки Databricks. См. статью "Создание запланированных заданий записной книжки и управление ими".
Настройка параметров конфигурации Spark
Чтобы автоматизировать настройку Spark на бессерверных вычислениях, Databricks позволяет задавать только определенные параметры конфигурации Spark. Список допустимых параметров см. в разделе "Поддерживаемые параметры конфигурации Spark".
Параметры конфигурации Spark можно задать только на уровне сеанса. Для этого задайте их в записной книжке и добавьте записную книжку в задачу, включенную в то же задание, которое использует параметры. См. статью "Получить и задать свойства конфигурации Apache Spark" в записной книжке.
Настройка сред записной книжки и зависимостей
Чтобы управлять зависимостями библиотеки и конфигурацией среды для задачи записной книжки, добавьте конфигурацию в ячейку записной книжки. В следующем примере устанавливаются библиотеки Python, использующиеся pip install из файлов рабочей области и с файлом requirements.txt , и задает переменную сеанса spark.sql.session.timeZone :
%pip install -r ./requirements.txt
%pip install simplejson
%pip install /Volumes/my/python.whl
%pip install /Workspace/my/python.whl
%pip install https://some-distro.net/popular.whl
spark.conf.set('spark.sql.session.timeZone', 'Europe/Amsterdam')
Чтобы задать одну среду для нескольких записных книжек, можно использовать одну записную книжку для настройки среды, а затем использовать %run магическую команду для запуска этой записной книжки из любой записной книжки, требующей настройки среды. См. раздел %run для импорта записной книжки.
Настройка сред и зависимостей для задач, не относящихся к записной книжке
Для других поддерживаемых типов задач, таких как скрипт Python, колесо Python или задачи dbt, среда по умолчанию включает установленные библиотеки Python. Чтобы просмотреть список установленных библиотек, ознакомьтесь с разделом "Установленные библиотеки Python" в заметках о выпуске версии Databricks Runtime, на которой основаны бессерверные вычисления для развертывания рабочих процессов. Сведения о текущей версии среды выполнения Databricks, используемой бессерверными вычислениями для рабочих процессов, см. в заметках о выпуске бессерверных вычислений. Вы также можете установить библиотеки Python, если для задачи требуется библиотека, которая не установлена. Библиотеки Python можно установить из файлов рабочей области, томов каталога Unity или репозиториев общедоступных пакетов. Чтобы добавить библиотеку при создании или изменении задачи, выполните следующие действия.
В раскрывающемся меню "Среда и библиотеки" щелкните
 рядом с средой по умолчанию или нажмите кнопку "Добавить новую среду".
рядом с средой по умолчанию или нажмите кнопку "Добавить новую среду".
В диалоговом окне "Настройка среды" нажмите кнопку +Добавить библиотеку.
Выберите тип зависимости в раскрывающемся меню в разделе "Библиотеки".
В текстовом поле "Путь к файлу" введите путь к библиотеке.
Для колеса Python в файле рабочей области путь должен быть абсолютным и начинаться с
/Workspace/.Для колеса Python в томе каталога Unity путь должен быть
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.requirements.txtДля файла выберите PyPi и введите-r /path/to/requirements.txt.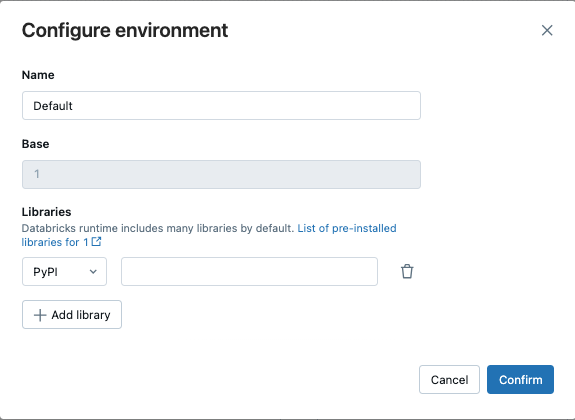
- Нажмите кнопку "Подтвердить" или "Добавить библиотеку", чтобы добавить другую библиотеку.
- Если вы добавляете задачу, нажмите кнопку "Создать задачу". Если вы редактировать задачу, нажмите кнопку "Сохранить".
Настройка автоматической оптимизации бессерверных вычислений для запрета повторных попыток
Бессерверные вычисления для автоматический оптимизации рабочих процессов оптимизируют вычислительные ресурсы, используемые для выполнения заданий и повторных попыток неудачных заданий. Автоматическая оптимизация включена по умолчанию, и Databricks рекомендует оставить ее включено, чтобы обеспечить успешное выполнение критически важных рабочих нагрузок по крайней мере один раз. Однако если у вас есть рабочие нагрузки, которые должны выполняться по крайней мере один раз, например задания, которые не идемпотентны, можно отключить автоматическую оптимизацию при добавлении или редактировании задачи:
- Рядом с повторными попытками нажмите кнопку "Добавить" (или если политика повторных попыток уже существует).
- В диалоговом окне политики повторных попыток не проверка Включить автоматическую оптимизацию без сервера (может включать дополнительные повторные попытки).
- Нажмите кнопку Подтвердить.
- Если вы добавляете задачу, нажмите кнопку "Создать задачу". Если вы редактировать задачу, нажмите кнопку "Сохранить".
Мониторинг затрат на задания, использующие бессерверные вычисления для рабочих процессов
Вы можете отслеживать затраты на задания, использующие бессерверные вычисления для рабочих процессов, запрашивая оплачиваемую системную таблицу использования. Эта таблица обновляется, чтобы включить атрибуты пользователей и рабочей нагрузки о бессерверных затратах. См . справочник по системной таблице с выставлением счетов.
Просмотр сведений о запросах Spark
Бессерверные вычисления для рабочих процессов имеют новый интерфейс для просмотра подробных сведений о среде выполнения для инструкций Spark, таких как метрики и планы запросов. Чтобы просмотреть аналитические сведения о запросах для инструкций Spark, включенных в задания, выполняемые на бессерверных вычислениях:
- Щелкните
 рабочие процессы на боковой панели.
рабочие процессы на боковой панели. - В столбце "Имя" щелкните имя задания, для которого нужно просмотреть аналитические сведения.
- Щелкните конкретный запуск, для которого нужно просмотреть аналитические сведения.
- В разделе вычислений на боковой панели запуска задачи щелкните журнал запросов.
- Вы перенаправляетесь в журнал запросов, префильтрованный на основе идентификатора выполнения задачи, в который вы находились.
Сведения об использовании журнала запросов см. в разделе "Журнал запросов".
Ограничения
Список бессерверных вычислений для ограничений рабочих процессов см. в заметках о выпуске бессерверных вычислений без сервера .
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по