Брандмауэр Azure метрик и оповещений
Метрики — это числовые значения, которые описывают конкретный аспект системы в определенный момент времени. Метрики собираются каждую минуту и используются для оповещений, так как такие данные собирать можно чаще чем другие. Предупреждение можно быстро отправить с помощью простой логики.
Метрики брандмауэра
Для брандмауэра Azure доступны следующие метрики:
Подсчет обращений к правилам приложения — количество обращений к правилам приложения.
Единица измерения: число отсчета
Подсчет обращений к правилам сети — количество обращений к правилам сети.
Единица измерения: число отсчета
Обработанные данные — общий объем данных, проходящих через брандмауэр в течение заданного периода.
Единица измерения: байт
Пропускная способность — скорость передачи данных, проходящих через брандмауэр, в секунду.
Единица измерения: бит в секунду
Работоспособность брандмауэра — отображает состояние работоспособности брандмауэра на основе доступности портов SNAT.
Единица измерения: %
В этой метрике есть два измерения.
Состояние: возможные значения Healthy (Работоспособен), Degraded (Снижение работоспособности), Unhealthy (Не работоспособен).
Причина: указывает на причину соответствующего состояния брандмауэра.
Если порты SNAT используются > 95%, они считаются исчерпанными, и работоспособность составляет 50 % с состоянием=Понижение и причина=порт SNAT. Брандмауэр сохраняет обработку трафика и существующие подключения не затрагиваются. Но возможны временные проблемы с установкой новых подключений.
Когда порты SNAT используются менее чем на 95 %, брандмауэр считается работоспособным, уровень работоспособности отображается как 100 %.
Если сведения об использовании портов SNAT отсутствуют, отображается состояние работоспособности 0 %.
Использование портов SNAT указывает на количество портов SNAT (%), используемых брандмауэром.
Единица измерения: %
Добавив дополнительные общедоступные IP-адреса для брандмауэра, вы сделаете доступными больше портов SNAT и снизите уровень их использования. Кроме того, дополнительные порты SNAT станут доступными при масштабировании брандмауэра по любой другой причине (например, для оптимизации работы ЦП или пропускной способности сети). Это означает, что указанный здесь показатель использования портов SNAT может снизиться даже без добавления общедоступных IP-адресов, просто в результате масштабирования службы. Вы можете напрямую управлять доступным количеством общедоступных IP-адресов и увеличивать количество доступных портов в брандмауэре. Но вы не можете напрямую управлять масштабированием брандмауэра.
Если брандмауэр сталкивается с нехваткой портов SNAT, необходимо добавить по крайней мере пять общедоступных IP-адресов. Это увеличивает количество доступных портов SNAT. Дополнительные сведения см. на странице Функции брандмауэра Azure.
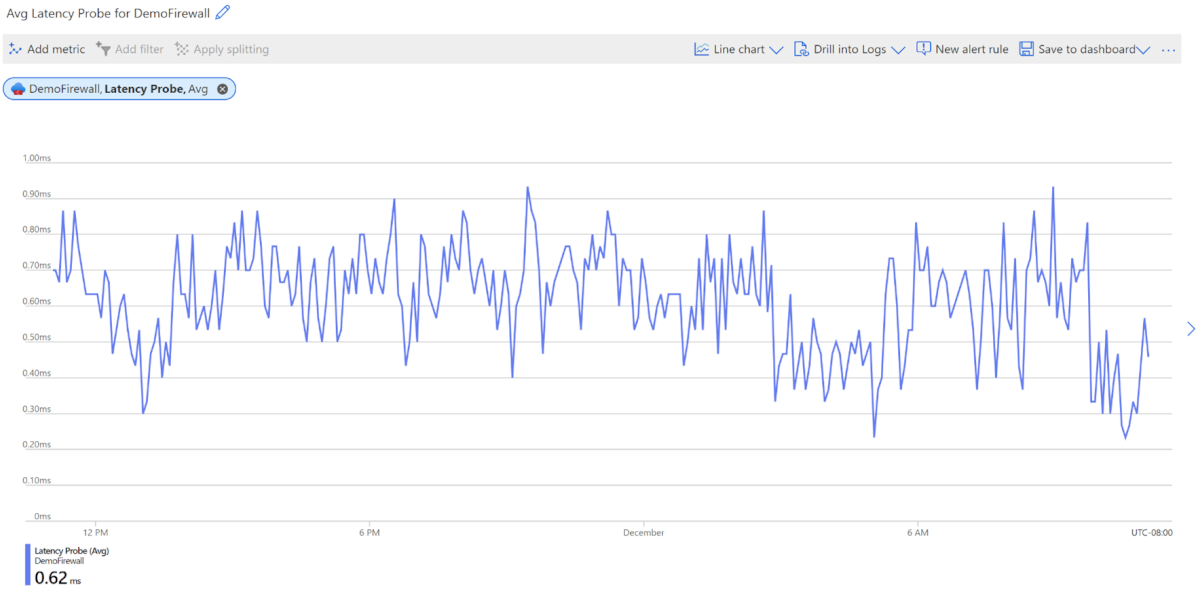
Проба задержки AZFW— оценивается Брандмауэр Azure средней задержкой.
Единица: мс
Эта метрика измеряет общую или среднюю задержку Брандмауэр Azure в миллисекундах. Администратор istrator может использовать эту метрику для следующих целей:
Диагностика того, является ли Брандмауэр Azure причиной задержки в сети
Отслеживайте и оповещайте, если возникают проблемы с задержкой или производительностью, поэтому ИТ-команды могут активно взаимодействовать.
Могут возникнуть различные причины, которые могут привести к высокой задержке в Брандмауэр Azure. Например, высокая загрузка ЦП, высокая пропускная способность или возможная проблема с сетью.
Эта метрика не измеряет сквозную задержку заданного сетевого пути. Другими словами, эта проба работоспособности задержки не измеряет, сколько задержек Брандмауэр Azure добавляет.
Если метрика задержки не работает должным образом, значение 0 отображается на панели мониторинга метрик.
В качестве ссылки средняя ожидаемая задержка для брандмауэра составляет примерно 1 мс. Это может отличаться в зависимости от размера развертывания и среды.
Проба задержки основана на технологии Ping Mesh корпорации Майкрософт. Таким образом, периодические пики в метрике задержки должны быть ожидаемыми. Эти пики являются нормальными и не сигнализируют о проблеме с Брандмауэр Azure. Они входят в стандартную настройку сети узлов, которая поддерживает систему.
В результате, если вы испытываете постоянную высокую задержку, которая длится дольше типичных пиков, рассмотрите возможность подачи запроса в службу поддержки за помощью.
Оповещение о метриках Брандмауэр Azure
Метрики предоставляют критически важные сигналы для отслеживания работоспособности ресурсов. Поэтому важно отслеживать метрики для ресурса и следить за любыми аномалиями. Но что делать, если метрики Брандмауэр Azure перестают поступать? Это может указывать на потенциальную проблему конфигурации или что-то более зловеще, как сбой. Отсутствующие метрики могут произойти из-за публикации маршрутов по умолчанию, которые блокируют Брандмауэр Azure от отправки метрик или количества работоспособных экземпляров, спускающихся до нуля. В этом разделе описано, как настроить метрики в рабочей области Log Analytics и предупредить о отсутствующих метриках.
Настройка метрик в рабочей области Log Analytics
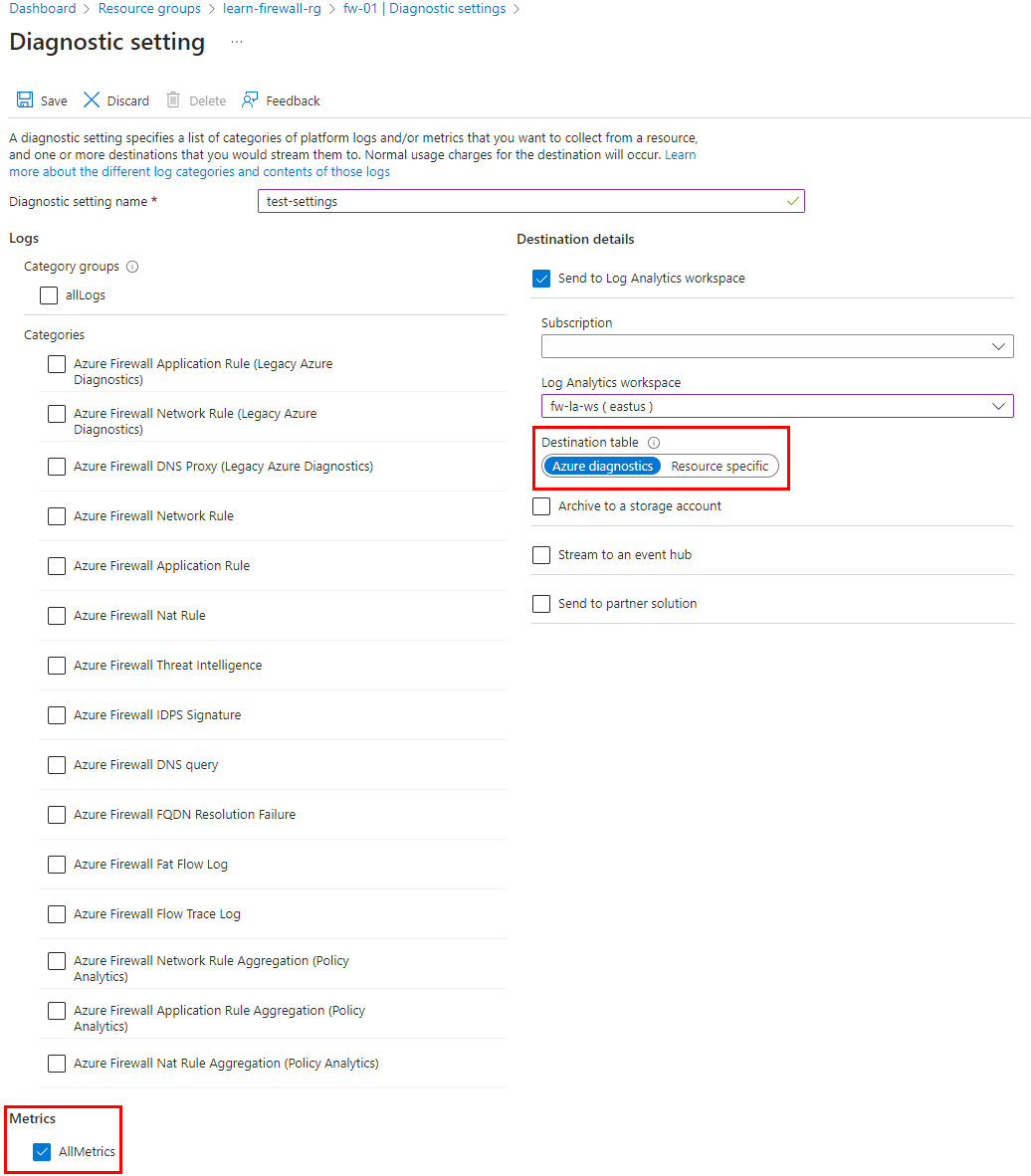
Первым шагом является настройка доступности метрик в рабочей области Log Analytics с помощью параметров диагностика в брандмауэре.
Перейдите на страницу ресурсов Брандмауэр Azure, чтобы настроить параметры диагностики, как показано на следующем снимке экрана. Это отправляет метрики брандмауэра в настроенную рабочую область.
Примечание.
Параметры диагностика для метрик должны быть отдельной конфигурацией, чем журналы. Журналы брандмауэра можно настроить для использования Диагностика Azure или конкретного ресурса. Однако метрики брандмауэра всегда должны использовать Диагностика Azure.
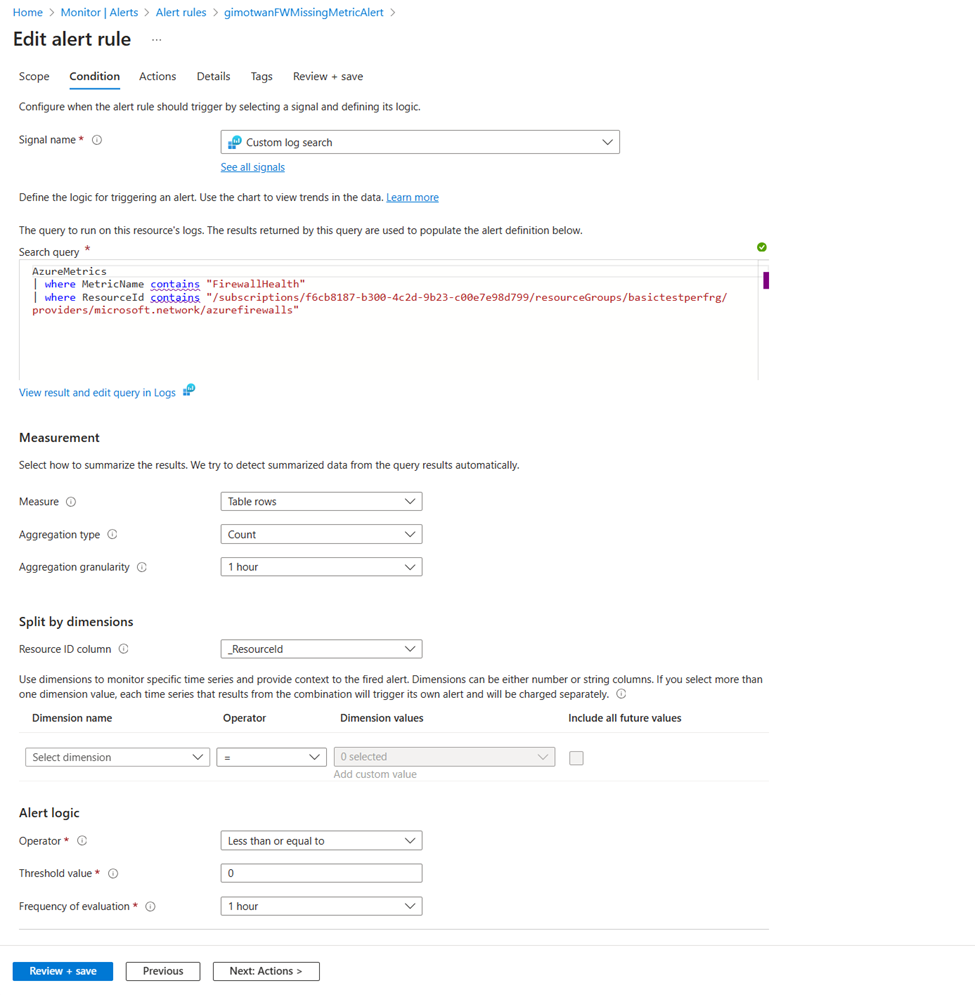
Создание оповещения для отслеживания метрик брандмауэра без сбоев
Перейдите к рабочей области, настроенной в параметрах метрик диагностика. Проверьте, доступны ли метрики с помощью следующего запроса:
AzureMetrics
| where MetricName contains "FirewallHealth"
| where ResourceId contains "/SUBSCRIPTIONS/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/RESOURCEGROUPS/PARALLELIPGROUPRG/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/HUBVNET-FIREWALL"
| where TimeGenerated > ago(30m)
Затем создайте оповещение для отсутствующих метрик в течение 60 минут. Перейдите на страницу "Оповещение" в рабочей области log analytics, чтобы настроить новые оповещения о отсутствующих метриках.