Run Apache Hive queries using the Data Lake tools for Visual Studio (Выполнение запросов Apache Hive с использованием средств Data Lake для Visual Studio)
Узнайте, как использовать Средства Data Lake для Visual Studio с целью выполнения запросов Apache Hive. Средства Data Lake позволяют легко создавать, отправлять и отслеживать запросы Hive к Apache Hadoop в Azure HDInsight.
Необходимые компоненты
Кластер Apache Hadoop в HDInsight. Сведения о создании этого элемента см. в статье Создание кластера Apache Hadoop в Azure HDInsight с помощью шаблона ARM.
Visual Studio. Для выполнения инструкций из этой статьи используется Visual Studio 2019.
Средства HDInsight для Visual Studio или инструменты Azure Data Lake Tools для Visual Studio. Сведения об установке и настройке средств см. в разделе Установка инструментов Data Lake для Visual Studio.
Выполнение запросов Apache Hive с помощью Visual Studio
Есть два способа создания и выполнения запросов Hive.
- Создание нерегламентированных запросов.
- Создание приложения Hive.
Создание нерегламентированного запроса Hive
Нерегламентированные запросы можно выполнять в пакетном или интерактивном режиме.
Запустите Visual Studio и выберите Продолжить без кода.
В окне Обозреватель серверов щелкните правой кнопкой мыши Azure, выберите Подключиться к подписке Microsoft Azure… и завершите процесс входа.
Разверните вкладку HDInsight, правой кнопкой мыши щелкните кластер, в котором вы хотите выполнить запрос, и выберите Написать запрос Hive.
Выполните следующий запрос Hive:
SELECT * FROM hivesampletable;Выберите Выполнить. Режим выполнения по умолчанию — Интерактивный.
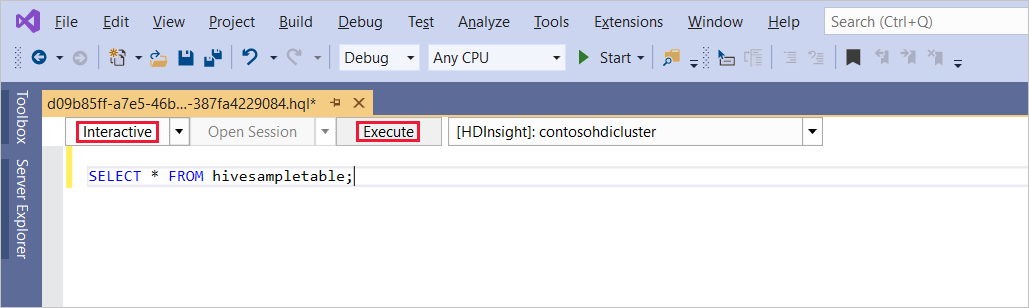
Чтобы выполнить тот же запрос в пакетном режиме, переключите раскрывающийся список с интерактивного на пакетный. Кнопка выполнения изменится с Выполнить на Отправить.

Редактор Hive поддерживает технологию IntelliSense. Средства Data Lake для Visual Studio поддерживают загрузку удаленных метаданных при редактировании скрипта Hive. Например, если ввести
SELECT * FROM, IntelliSense отобразит все предлагаемые имена таблиц. Если указано имя таблицы, IntelliSense выведет список имен столбцов. Эти инструменты поддерживают почти все инструкции, подзапросы и встроенные определяемые пользователем функции Hive DML. IntelliSense предлагает только метаданные кластеров, выбранных на панели инструментов HDInsight.На панели инструментов запроса (область под вкладкой запросов над текстом запроса) нажмите кнопку Отправить либо щелкните стрелку раскрывающегося списка рядом с пунктом Отправить и выберите пункт Дополнительно в раскрывающемся списке. Если выбрать второй вариант:
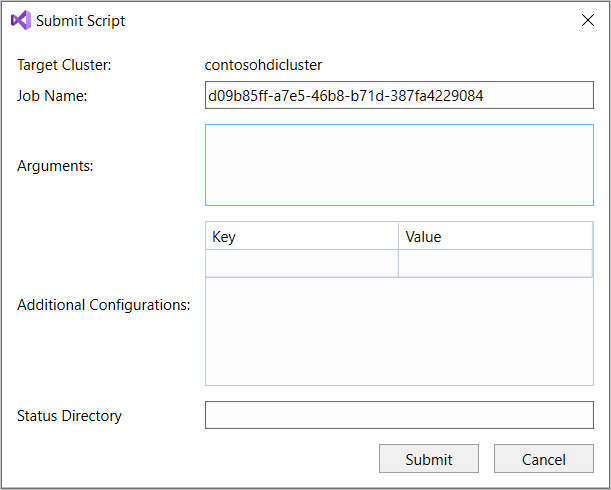
Если выбран вариант "Дополнительно", в диалоговом окне Отправить скрипт укажите значения для полей Имя задания, Аргументы, Дополнительные конфигурации и Каталог состояния. Затем щелкните Отправить.
Создание приложения Hive
Чтобы выполнить запрос Hive путем создания приложения Hive, выполните приведенные ниже действия.
Откройте Visual Studio.
В окне Начало работы выберите Создать проект.
В окне Создание проекта в поле Поиск шаблонов введите Hive. Затем выберите Hive Application (Приложение Hive) и нажмите кнопку Далее.
В окне Настроить новый проект введите имя проекта, выберите или создайте расположение для проекта, а затем нажмите кнопку Создать.
Откройте файл Script.hql , созданный в этом проекте, и вставьте следующие операторы HiveQL:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Эти инструкции выполняют описанные ниже действия.
DROP TABLE: удаляет таблицу, если она существует.CREATE EXTERNAL TABLE: создает новую "внешнюю" таблицу в Hive. Внешние таблицы хранят только определения таблицы в Hive. (Данные остаются в исходном расположении.)Примечание.
Внешние таблицы следует использовать, если предполагается, что базовые данные будут обновляться внешним источником, например заданием MapReduce или службой Azure.
Удаление внешней таблицы не приводит к удалению данных, будет удалено только определение таблицы.
ROW FORMAT: инструкции по форматированию данных для Hive. В данном случае поля всех журналов разделены пробелом.STORED AS TEXTFILE LOCATION: указывает Hive, что данные хранятся в каталоге example/data и их формат — текст.SELECT: подсчитывает количество строк, в которых столбецt4содержит значение[ERROR]. Эта инструкция должна вернуть значение3, так как данное значение содержат три строки.INPUT__FILE__NAME LIKE '%.log': указывает Hive, что вернуть нужно только данные из файлов с расширением LOG. Это предложение ограничивает поиск до файла sample.log, который содержит данные.
На панели инструментов файла запроса (похожая на панель инструментов нерегламентированных запросов) выберите кластер HDInsight, который вы хотите использовать для этого запроса. Затем измените значение параметра Интерактивный на Пакетный (при необходимости) и нажмите кнопку Отправить, чтобы выполнить инструкции в качестве задания Hive.
Отобразится сводка по заданию Hive и информация о его выполнении. Воспользуйтесь ссылкой Обновить, чтобы обновить информацию о задании. Обновляйте ее до тех пор, пока состояние задания не изменится на Завершено.
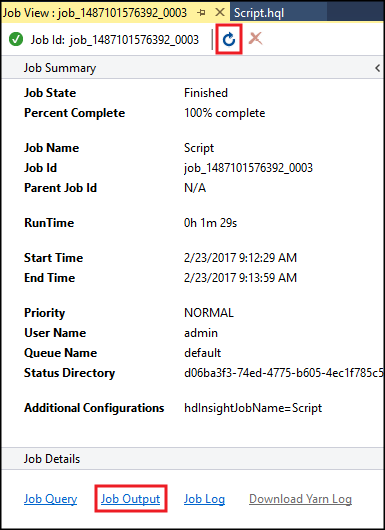
Воспользуйтесь ссылкой Выходные данные задания, чтобы просмотреть выходные данные этого задания. Они содержат
[ERROR] 3. Это значение, возвращенное данным запросом.
Дополнительный пример
В следующем примере используется таблица log4jLogs, созданная в предыдущей процедуре Создание приложения Hive.
В окне Обозреватель серверов щелкните правой кнопкой мыши кластер и выберите Написать запрос Hive.
Выполните следующий запрос Hive:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Эти инструкции выполняют описанные ниже действия.
CREATE TABLE IF NOT EXISTS: создает таблицу, если ее нет. Так как ключевое словоEXTERNALне используется, эта инструкция создает внутреннюю таблицу. Внутренние таблицы хранятся в хранилище данных Hive и управляются Hive.Примечание.
В отличие от таблиц
EXTERNAL, удаление внутренней таблицы приводит к удалению ее базовых данных.STORED AS ORC: позволяет сохранить данные в формате ORC. Это высокооптимизированный и эффективный формат для хранения данных Hive.INSERT OVERWRITE ... SELECT: выбирает строки из таблицыlog4jLogs, которые содержат[ERROR], а затем вставляет эти данные в таблицуerrorLogs.
При необходимости измените значение режима Интерактивный на Пакетный, а затем нажмите кнопку Отправить.
Чтобы убедиться, что задание создало таблицу, перейдите в обозреватель сервера и разверните узел Azure>HDInsight. Разверните кластер HDInsight, а затем разверните Базы данных Hive>По умолчанию. Должны быть отображены таблицы errorLogs и log4jLogs.
Следующие шаги
Как вы видите, средства HDInsight для Visual Studio упрощают работу с запросами Hive в HDInsight.
Дополнительные сведения о Hive см. в статье Обзор Apache Hive и HiveQL в Azure HDInsight.
Дополнительные сведения о других способах работы с Hadoop в HDInsight см. в статье Использование MapReduce в Apache Hadoop в HDInsight.
Дополнительные сведения о средствах HDInsight для Visual Studio см. в статье Подключение к Azure HDInsight и выполнение запросов Apache Hive с помощью средств Data Lake для Visual Studio