Пример потоковой передачи Apache Spark (DStream) с использованием Apache Kafka в HDInsight
Узнайте об использовании Apache Spark для двунаправленного потокового обмена данными с Apache Kafka в HDInsight с помощью DStreams. В этом примере используется средство Jupyter Notebook, которое выполняется на кластере Spark.
Примечание.
Вы узнаете, как создать группу ресурсов Azure, которая содержит кластеры Spark и Kafka в HDInsight. Оба этих кластера находятся в виртуальной сети Azure, что позволяет кластеру Spark напрямую обмениваться данными с кластером Kafka.
Выполнив инструкции, не забудьте удалить кластеры, чтобы избежать ненужных расходов.
Внимание
В этом примере используется DStreams (старая технология потоковой передачи Spark). Пример, использующий новые функции потоковой передачи Spark, см. в статье Использование структурированной потоковой передачи Spark с Apache Kafka в HDInsight.
Создание кластеров
Apache Kafka в HDInsight не предоставляет доступ к брокерам Kafka через общедоступный сегмент Интернета. Все объекты, обращающиеся к Kafka, должны находиться в той же виртуальной сети Azure, что и узлы в кластере Kafka. В этом примере кластеры Kafka и Spark расположены в виртуальной сети Azure. На следующей схеме показано, как взаимодействуют кластеры.
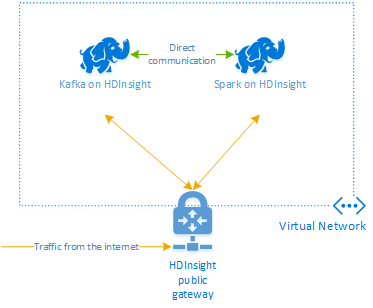
Примечание.
Хотя само решение Kafka ограничено связью в пределах виртуальной сети, другие службы в кластере, например SSH и Ambari, доступны через Интернет. Дополнительные сведения об общих портах, доступных в HDInsight, см. в статье Порты и универсальные коды ресурсов (URI), используемые кластерами HDInsight.
Хотя виртуальную сеть Azure, а также кластеры Kafka и Spark можно создать вручную, проще использовать шаблон Azure Resource Manager. Выполните следующие действия, чтобы развернуть виртуальную сеть Azure, а также кластеры Kafka и Spark в подписке Azure.
Нажмите эту кнопку, чтобы войти в Azure и открыть шаблон на портале Azure.

Предупреждение
Чтобы гарантировать доступность Kafka в HDInsight, кластер должен содержать не менее четырех рабочих узлов. Этот шаблон создает кластер Kafka, содержащий четыре рабочих узла.
Этот шаблон создает кластер HDInsight 4.0 для Kafka и Spark.
Используйте следующие сведения, чтобы заполнить раздел Настраиваемое развертывание:
Свойство Значение Группа ресурсов Создайте новую группу или выберите существующую. Расположение Выберите географически близкое к вам расположение. Базовое имя кластера Это значение будет использоваться в качестве базового имени для кластеров Spark и Kafka. Например, если ввести hdistreaming, будет создан кластер Spark с именем spark-hdistreaming и кластер Kafka с именем kafka-hdistreaming. Имя пользователя для входа в кластер Имя администратора для кластеров Spark и Kafka. Пароль для входа в кластер Пароль администратора для кластеров Spark и Kafka. Имя пользователя SSH Создаваемый пользователь SSH для кластеров Spark и Kafka. Пароль SSH Пароль пользователя SSH для кластеров Spark и Kafka. 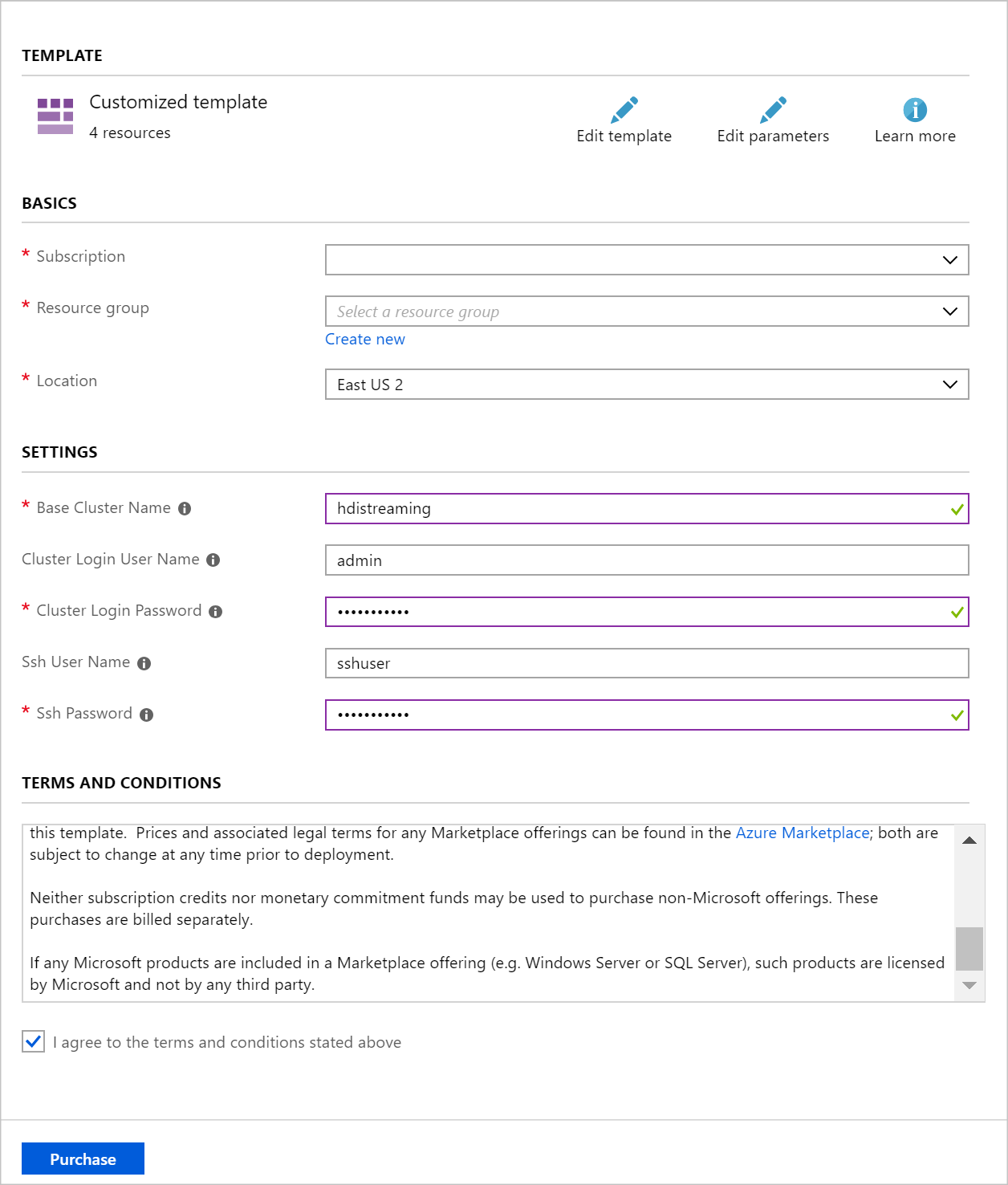
Прочтите условия использования и установите флажок Я принимаю указанные выше условия.
Наконец, щелкните Приобрести. Процесс создания кластеров занимает около 20 минут.
Когда ресурсы будут созданы, отобразится страница со сводными сведениями.
Внимание
Обратите внимание, что кластерам HDInsight присвоены имена spark-BASENAME и kafka-BASENAME, где BASENAME — имя, указанное в шаблоне. Эти имена будут использоваться позже при подключении к кластерам.
Использование записных книжек
Код для примера, описанного в этом документе: https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Удаление кластера
Предупреждение
Счета за кластеры HDInsight выставляются пропорционально в минутах, независимо от их использования. Обязательно удалите кластер, когда завершите его использование. Дополнительные сведения см. в статье Удаление кластера HDInsight с помощью браузера, PowerShell или классического интерфейса Azure CLI.
Выполнив описанные здесь инструкции, вы создадите два кластера в одной группе ресурсов Azure. Следовательно, вы можете удалить эту группу ресурсов на портале Azure. При этом будут удалены все созданные в рамках этого руководства и используемые в кластерах ресурсы, виртуальная сеть Azure и учетная запись хранения.
Следующие шаги
В этом примере описано, как использовать Spark для чтения и записи данных в Kafka. Другие материалы, посвященные работе с Kafka, доступны по следующим ссылкам:
- Get started with Apache Kafka on HDInsight (preview) (Приступая к работе с Apache Kafka в HDInsight (предварительная версия))
- Репликация разделов Apache Kafka с помощью Kafka в HDInsight и MirrorMaker