Устранение ошибки нехватки памяти Apache Hive в Azure HDInsight
Узнайте, как устранить ошибку нехватки памяти Apache Hive при обработке больших таблиц в настройках памяти Hive.
Выполнение запроса Apache Hive к большим таблицам
Клиент выполнил запрос Hive.
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Некоторые особенности этого запроса:
- T1 является псевдонимом для большой таблицы TABLE1, которая содержит множество столбцов типа STRING.
- Другие таблицы не так велики, но имеют большое число столбцов.
- Все таблицы соединяются друг с другом, в некоторых случаях с несколькими столбцами в TABLE1 и др.
На выполнение запроса Hive в кластере HDInsight A3 с 24 узлами ушло 26 минут. Клиент заметил следующие предупреждения:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
С механизмом выполнения Apache Tez. выполнение того же запроса заняло 15 минут, после чего появилась следующая ошибка:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
Ошибка не устраняется при использовании виртуальной машины большего размера (например, D12).
Отладка ошибки нехватки памяти
Наша инженерная команда и команда поддержки обнаружили, что одна из проблем, которые приводят к ошибке нехватки памяти, представляет собой известную проблему, описанную в Apache JIRA.
"Если hive.auto.convert.join.noconditionaltask = true, мы проверяем noconditionaltask.size, и если сумма размеров таблиц в соединении с сопоставлением меньше noconditionaltask.size, то планом будет создано соединение с сопоставлением. Проблема в том, что при вычислении не учитываются дополнительные затраты из разных реализаций HashTable в виде результатов, если сумма размеров входных данных немного меньше, чем размер noconditionaltask, запросы будут выдавать ошибку нехватки памяти".
Для свойства hive.auto.convert.join.noconditionaltask в файле hive-site.xml задано значение true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Вполне вероятно, что источником ошибки нехватки памяти в пространстве кучи Java был Map Join. Как описано в записи блога Hadoop Yarn memory settings in HDInsight (Параметры памяти Hadoop Yarn в HDInsight), при использовании модуля Tez используемое пространство кучи на самом деле принадлежит контейнеру Tez. Описание памяти контейнера Tez см. на рисунке ниже.
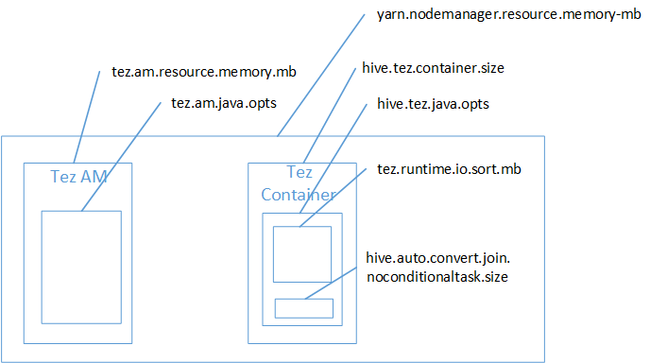
Как следует из записи блога, два следующих параметра памяти определяют контейнер памяти для кучи: hive.tez.container.size и hive.tez.java.opts. Согласно нашему опыту, исключение нехватки памяти не означает, что размер контейнера слишком мал. Оно означает, что размер кучи Java (hive.tez.java.opts) слишком мал. Поэтому каждый раз, когда вы видите ошибку нехватки памяти, можно попытаться увеличить hive.tez.java.opts. При необходимости может потребоваться увеличение параметра hive.tez.container.size. Параметр Java.opts должен составлять около 80 % от container.size.
Примечание.
Параметр hive.tez.java.opts всегда должен быть меньше, чем hive.tez.container.size.
Так как виртуальная машина размера D12 имеет 28 ГБ памяти, мы решили использовать контейнер размером 10 ГБ (10 240 МБ) и назначить 80 % от этого размера параметру java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
С новыми настройками запрос был выполнен успешно за 10 минут.
Следующие шаги
Ошибка нехватки памяти не обязательно означает, что размер контейнера слишком мал. Вместо этого следует настроить параметры памяти, увеличив размер кучи, так чтобы он составлял не менее 80 % от размера памяти контейнера. Дополнительные сведения см. в статье Оптимизация запросов Hive в Azure HDInsight.