Управление журналами для кластера HDInsight
Кластер HDInsight создает различные файлы журналов. Например, Apache Hadoop и связанные с ним службы, такие как Apache Spark, создают подробные журналы выполнения заданий. Управление файлами журналов является частью поддержания работоспособности кластера HDInsight. Кроме того, к архивации журналов могут применяться нормативные требования. Из-за количества и размера файлов журналов оптимизация хранения и архивирования журналов помогает в управлении затратами на обслуживание.
Управление журналами кластера HDInsight включает в себя хранение информации обо всех аспектах среды кластера. Эти сведения включают все связанные журналы служб Azure, конфигурацию кластера, сведения о выполнении заданий, любые состояния ошибок и другие данные по мере необходимости.
Типичные шаги в управлении журналом HDInsight:
- Шаг 1. Определение политики хранения журналов
- Шаг 2. Управление журналами конфигурации версий службы кластера
- Шаг 3. Управление файлами журнала выполнения заданий кластера
- Шаг 4. Прогнозирование размера хранилища журналов и затрат
- Шаг 5. Определение политик архивации журнала процессов
Шаг 1. Определение политики хранения журналов
Первым шагом при создании стратегии управления журналом кластера HDInsight является сбор сведений о бизнес-сценариях и требованиях хранения истории выполнения заданий.
Сведения о кластере
Следующие сведения о кластере полезны для сбора информации в вашей стратегии управления журналами. Собирайте эти сведения из всех кластеров HDInsight, созданных в определенной учетной записи Azure.
- Имя кластера
- Регионы кластеров и зоны доступности Azure
- Состояние кластера, включая сведения о последнем изменении состояния
- Тип и количество экземпляров HDInsight для головного узла, узлов ядра и задач
Вы можете получить большую часть этих сведений верхнего уровня, используя портал Azure. Кроме того, можно получить сведения о кластерах HDInsight с помощью Azure CLI:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Чтобы просмотреть эти сведения, можно также использовать PowerShell. Дополнительные сведения см. в статье Управление кластерами Apache Hadoop в HDInsight с помощью Azure PowerShell.
Общие сведения о рабочих нагрузках в кластерах
Важно понимать типы рабочих нагрузок, выполняемых в вашем кластере HDInsight, для разработки соответствующих стратегий ведения журналов для каждого типа.
- Являются ли рабочие нагрузки экспериментальными (для разработки или тестирования) или рабочего уровня?
- Как часто обычно выполняются рабочие нагрузки рабочего уровня?
- Являются ли какие-либо из рабочих нагрузок ресурсоемкими или долгосрочными?
- Используется ли в какой-либо из рабочих нагрузок сложный набор служб Hadoop, для которых создается несколько типов журналов?
- Имеет ли какая-либо из рабочих нагрузок соответствующие нормативные требования к выполнению преобразования?
Пример журнала хранения шаблонов и рекомендации по работе с ним
Рассмотрите возможность отслеживания преобразования данных путем добавления идентификатора к каждой записи в журнале или с помощью других методов. Это позволит отследить исходный источник данных и операцию и наблюдать за данными на каждом этапе, чтобы понять их последовательность и допустимость.
Подумайте, как вы можете получать журналы из кластера или из нескольких кластеров для таких целей, как аудит, мониторинг, планирование и оповещение. Вы можете использовать пользовательское решение для регулярного доступа к файлам журналов и их объединения и анализа для отображения панели мониторинга. Вы также можете добавить другие возможности для оповещения об обнаружении безопасности или сбоя. Вы можете создавать эти программы с помощью PowerShell, SDK HDInsight или кода, который обращается к классической модели развертывания Azure.
Подумайте, будет ли решение для мониторинга или служба полезной. Microsoft System Center предоставляет пакет управления HDInsight. Вы также можете использовать сторонние средства, такие как Apache Chukwa и Ganglia, для сбора и централизации журналов. Многие компании предлагают услуги для мониторинга решений больших данных на основе Hadoop, например
Centerity: Compuware APM, Sematext SPM и Zettaset Orchestrator.
Шаг 2. Управление версиями журналов конфигурации и просмотр журналов
Типичный кластер HDInsight использует несколько служб и программные пакеты с открытым кодом (такие как Apache HBase, Apache Spark и т. д.). Для некоторых рабочих нагрузок, таких как биоинформатика, вам может потребоваться сохранить историю журналов конфигурации службы в дополнение к журналам выполнения заданий.
Просмотр параметров конфигурации кластера в пользовательском интерфейсе Ambari
Apache Ambari упрощает конфигурацию кластера HDInsight, управление им и его мониторинг за счет пользовательского веб-интерфейса и интерфейса REST API. Ambari есть в кластерах HDInsight на основе Linux. Выберите область Панель мониторинга кластера на странице HDInsight на портале Azure, чтобы открыть страницу со ссылкой на панели мониторинга кластера. Выберите область Панель мониторинга кластера HDInsight, чтобы открыть пользовательский интерфейс Ambari. Введите учетные данные для входа в кластер.
Чтобы открыть список просмотров службы, на странице портала Azure для HDInsight выберите область Просмотры Ambari. Этот список меняется в зависимости от установленных библиотек. Например, в нем могут быть диспетчер очередей YARN, представления Hive и Tez. Выберите ссылку на службу для просмотра сведений о конфигурации и службе. На странице стека и версии пользовательского интерфейса Ambari содержатся сведения о конфигурации служб в кластере и история версий служб. Чтобы перейти к этому разделу, в пользовательском интерфейсе Ambari выберите меню Администратор, а затем — Stacks and Versions (Стеки и версии). Выберите вкладку версий, чтобы просмотреть сведения о версии службы:
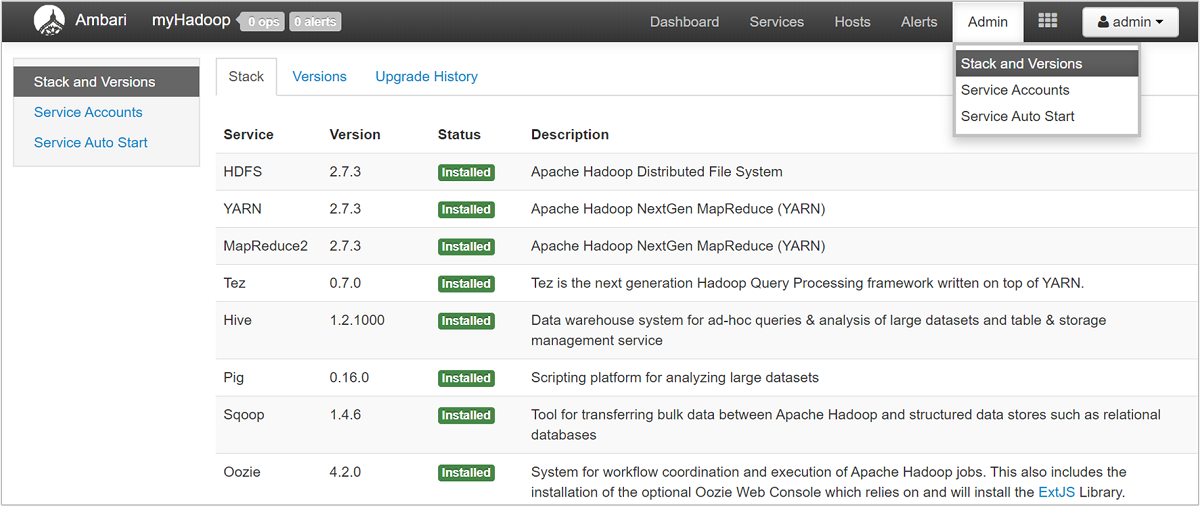
С помощью пользовательского интерфейса Ambari вы можете загрузить конфигурацию для любых служб, запущенных на конкретном узле в кластере. Выберите меню Узлы, а затем перейдите по ссылке на нужный узел. На странице этого узла выберите Host Actions (Действия на узле), а затем Download Client Configs (Скачать конфигурацию клиента).

Просмотр журналов действий сценария
С помощью действий сценария HDInsight можно запустить сценарии в кластере вручную или в соответствии с указанным временем. Например, действия скрипта можно использовать для установки другого программного обеспечения в кластере или изменения параметров конфигурации из значений по умолчанию. Журналы сценариев действий могут помочь понять ошибки, возникшие во время настройки кластера, а также изменения настроек конфигурации, которые могут повлиять на производительность и доступность кластера. Чтобы увидеть состояние действия сценария, нажмите кнопку Операции в пользовательском интерфейсе Ambari или получите доступ к журналам состояний в учетной записи хранения по умолчанию. Журналы хранилища находятся в /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Просмотр журналов состояния для предупреждений Ambari
Apache Ambari сохраняет изменения состояния предупреждений в ambari-alerts.log. Полный путь выглядит так: /var/log/ambari-server/ambari-alerts.log. Чтобы включить отладку для этого журнала, измените свойство в файле /etc/ambari-server/conf/log4j.properties. Затем измените запись под строкой # Log alert state changes следующим образом:
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Шаг 3. Управление файлами журнала выполнения заданий кластера
Следующий шаг заключается в анализе файлов журнала выполнения заданий для различных служб, таких как Apache HBase, Apache Spark и т. д. Кластер Hadoop создает большое количество подробных журналов. Чтобы определить, какие журналы используются (и какие не используются), может потребоваться время. Важно понимать систему ведения журналов для целевого управления файлами журналов. Приведенное ниже изображение содержит пример файла журнала.

Доступ к файлам журналов Hadoop
HDInsight хранит файлы журналов в файловой системе кластера и в хранилище Azure. Файлы журналов в кластере можно изучить, открыв SSH-подключение к кластеру и просмотрев файловую систему, или с помощью портала состояния Hadoop YARN на сервере удаленного головного узла. Файлы журналов можно изучить в хранилище Azure с помощью любых инструментов, которые могут обращаться к данным в хранилище Azure и скачивать их оттуда. Например, AZCopy, CloudXplorer и обозреватель серверов Visual Studio. Кроме того, можно использовать PowerShell и библиотеки клиента хранилища Azure или пакеты SDK .NET Azure для доступа к данным в хранилище BLOB-объектов.
Hadoop выполняет работу заданий в виде попыток завершения задач на различных узлах в кластере. HDInsight может инициировать попытки спекулятивных задач, завершая все остальные попытки, которые не будут выполнены раньше. Это создает множество операций, которые регистрируются в файлах журнала контроллера, stderr и syslog в режиме реального времени. Кроме того, несколько попыток выполняются одновременно, но файл журнала может отображать результаты только линейно.
Журналы HDInsight, записываемые в хранилище BLOB-объектов Azure
Кластеры HDInsight сконфигурированы для записи журналов задач в учетную запись хранения BLOB-объектов Azure для любого задания, которое отправляется с помощью командлетов Azure PowerShell или API-интерфейсов отправки .NET. При отправке задания через SSH в кластер сведения о регистрации выполнения хранятся в таблицах Azure, как описано в предыдущем разделе.
В дополнение к основным файлам журнала, созданным HDInsight, установленные службы, такие как YARN, также создают файлы журналов выполнения задач. Число и тип файлов журналов зависит от установленных служб. Стандартные службы — Apache HBase Apache Spark и т. д. Просмотрите файлы выполнения журнала заданий для каждой службы, чтобы понять общие сведения о файлах ведения журналов, доступных в вашем кластере. Каждая служба имеет собственный уникальный метод ведения журналов и расположение для хранения файлов журналов. Примеры подробных сведений о доступе к наиболее распространенным файлам журналов служб (из YARN) обсуждаются в следующем разделе.
Журналы HDInsight, формируемые службой YARN
Служба YARN объединяет журналы со всех контейнеров на рабочем узле и хранит их как один сводный файл журнала на рабочем узле. Этот журнал хранится в файловой системе по умолчанию после завершения приложения. Ваше приложение может использовать сотни или тысячи контейнеров, но журналы для всех контейнеров, выполненных на одном рабочем узле, всегда объединяются в один файл. На каждый рабочий узел, используемый приложением, приходится один файл журнала. Объединение журналов включено по умолчанию на кластерах HDInsight версии 3.0 и более поздних версий. Объединенные журналы находятся в хранилище по умолчанию для кластера.
/app-logs/<user>/logs/<applicationId>
Агрегированные журналы не доступны напрямую для чтения, так как они записываются в двоичном TFile формате, индексированном контейнером. Чтобы отобразить эти журналы для интересующих вас приложений или контейнеров в виде обычного текста, используйте журналы YARN ResourceManager или средства CLI.
Средства CLI для YARN
Чтобы использовать инструменты интерфейса командной строки для YARN, необходимо сначала подключиться к кластеру HDInsight с помощью SSH. Укажите сведения <applicationId>, <user-who-started-the-application>, <containerId> и <worker-node-address> при выполнении этих команд. Эти журналы можно отобразить в виде обычного текста, запустив одну из указанных ниже команд.
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
Пользовательский интерфейс YARN Resource Manager
Пользовательский интерфейс YARN Resource Manager выполняется на головном узле кластера и осуществляется через веб-интерфейс Ambari. Чтобы просмотреть журналы YARN, выполните следующие действия:
- Откройте браузер и перейдите по адресу
https://CLUSTERNAME.azurehdinsight.net. Замените CLUSTERNAME именем кластера HDInsight. - В списке служб в левой части страницы выберите YARN.
- В раскрывающемся списке "Быстрые ссылки" выберите один из головного узла кластера и выберите журналы Resource Manager. Отобразится список ссылок на журналы YARN.
Шаг 4. Прогнозирование размера хранилища журналов и затрат
После завершения предыдущих шагов у вас появится представление о типах и объемах файлов журналов, которые создаются кластерами HDInsight.
Далее проанализируйте объем данных журнала в местах хранения ключей журнала за период времени. Например, вы можете анализировать увеличение объема в течение 30, 60 или 90 дней. Запишите эти сведения в электронную таблицу или используйте другие инструменты, такие как Visual Studio, обозреватель хранилища Azure или Power Query для Excel. ```
Теперь у вас достаточно информации для создания стратегии управления ключевыми журналами. Используйте электронную таблицу (или другой инструмент) для прогнозирования роста объема журналов и затрат на хранение в Azure. Кроме того, учитывайте требования к хранению журналов для изучаемого набора журналов. Теперь вы можете спрогнозировать будущие расходы на хранение журналов, определив, какие файлы журналов можно удалить, а какие журналы следует сохранить и заархивировать в менее затратной службе хранилища Azure.
Шаг 5. Определение политик архивации журнала процессов
Определив файлы журналов для удаления, вы можете настроить параметры ведения журнала во многих службах Hadoop для автоматического удаления файлов журнала по истечении заданного периода времени.
Для некоторых файлов журнала можно использовать более экономный подход архивирования файлов журналов. Для журналов действий Azure Resource Manager вы можете изучить этот подход, используя портал Azure. Настройте архивацию журналов Resource Manager, выбрав ссылку Журнал действий на портале Azure для своего экземпляра HDInsight. В верхней части страницы поиска журналов действий выберите пункт меню Экспорт, чтобы открыть область Экспорт журнала действий. Укажите подписку, регион, необходимость экспорта в учетную запись хранения и количество дней хранения журналов. В этой же области можно также указать, следует ли экспортировать журналы в концентратор событий.
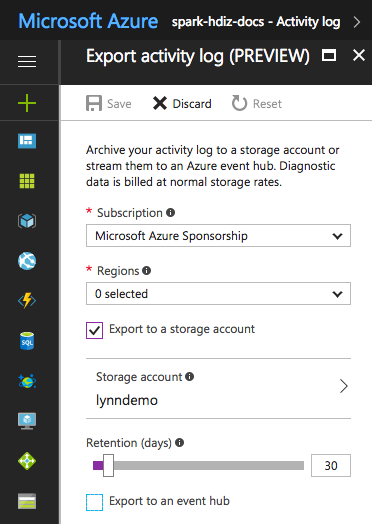
Кроме того, можно создать сценарий архивации журнала с помощью PowerShell.
Доступ к метрикам службы хранилища Azure
Хранилище Azure можно настроить для регистрации операций хранения и доступа. Эти подробные журналы можно использовать для мониторинга емкости и планирования, а также для аудита запросов к хранилищу. Зарегистрированная информация включает в себя детали задержки, позволяющие отслеживать и точно настраивать производительность ваших решений. Пакет SDK .NET для Hadoop позволяет проанализировать файлы журналов, созданные для хранилища Azure, которые содержат данные для кластера HDInsight.
Управление размером и числом индексов резервного копирования для старых файлов журнала
Чтобы контролировать размер и количество хранимых файлов журналов, задайте следующие свойства RollingFileAppender:
maxFileSize— это критический размер файла, который выполняется свертывания файла. Значение по умолчанию — 10 МБ.maxBackupIndexуказывает количество создаваемых файлов резервных копий, по умолчанию 1.
Другие способы управления журналами
Чтобы избежать переполнения дискового пространства, можно использовать некоторые средства ОС, такие как logrotate для управления обработкой файлов журналов. logrotate можно настроить для ежедневного запуска для сжатия файлов журналов и удаления старых файлов. Подход зависит от требований, например, как долго следует хранить файлы на локальных узлах.
Кроме того, можно проверка, включено ли ведение журнала ОТЛАДКи для одной или нескольких служб, что значительно увеличивает размер выходного журнала.
Чтобы собирать журналы со всех узлов в централизованном месте, можно создать поток данных, такой как получение всех записей журнала в Solr.
Следующие шаги
- Monitoring and logging (Мониторинг и ведение журнала)
- Доступ к журналам приложений Apache Hadoop YARN в HDInsight под управлением Linux