Apache Phoenix в Azure HDInsight
Apache Phoenix — это уровень реляционной базы данных на основе Apache HBase с открытым кодом и высоким уровнем параллелизма. Phoenix позволяет использовать запросы на базе SQL для HBase. Phoenix использует драйверы JDBC. Это позволяет создавать, удалять, изменять SQL-таблицы, индексы, представления и последовательности, а также вставлять строки по одной или в пакетном режиме. Phoenix использует для сборки запросов компиляцию в машинный код noSQL, а не MapReduce, что позволяет создавать на основе HBase приложения с низким уровнем задержки. Кроме того, Phoenix поддерживает сопроцессоры для выполнения пользовательского кода в адресном пространстве сервера, то есть прямо в месте размещения данных. Такой подход сводит к минимуму трафик между клиентом и сервером.
Apache Phoenix позволяет использовать запросы больших данных обычным пользователям, которые могут использовать синтаксис типа SQL вместо программирования. Phoenix оптимизирован для HBase в отличие от других инструментов, таких как Apache Hive и Apache Spark SQL. Преимущество для разработчиков заключается в написании высокоэффективных запросов с гораздо меньшим объемом кода.
Когда вы отправляете SQL-запрос, Phoenix компилирует запрос на собственные вызовы HBase и параллельно запускает сканирование (или план) для оптимизации. Этот уровень абстракции освобождает разработчика от написания заданий MapReduce. Теперь он может сосредоточиться на бизнес-логике и рабочем процессе приложения хранилища больших данных Phoenix.
Оптимизация производительности запроса и другие функции
Apache Phoenix добавляет несколько улучшений производительности и функций для запросов HBase.
Вторичные индексы
HBase имеет единственный индекс, который лексикографически сортируется по ключу первой строки. Доступ к этим записям возможен только через ключ строки. Доступ к записям через любой другой столбец требует сканирования всех данных с применением необходимого фильтра. Во вторичном индексе столбцы или выражения, которые индексируются, образуют альтернативный ключ строки, что позволяет просматривать и сканировать диапазон по этому индексу.
Создайте вторичный индекс с помощью команды CREATE INDEX:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Такой подход может повысить производительность при выполнении одноиндексных запросов. Этот тип вторичного индекса является охватывающим индексом, содержащим все столбцы, включенные в запрос. Поэтому просмотр таблицы не нужен. Индекс удовлетворяет весь запрос.
Представления
Представления Phoenix дают возможность преодолеть ограничение HBase, когда при создании более 100 физических таблиц производительность начинает ухудшаться. Представления Phoenix позволяют нескольким виртуальным таблицам совместно использовать одну базовую физическую таблицу HBase.
Создание представления Phoenix аналогично представлению синтаксиса SQL. Единственное отличие состоит в том, что вы можете определять столбцы для своего представления в дополнение к столбцам, унаследованным от базовой таблицы. Вы также можете добавить новые столбцы KeyValue.
Ниже приведена физическая таблица с именем product_metrics со следующим определением:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Определите представление по этой таблице с дополнительными столбцами:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Чтобы добавить дополнительные столбцы позже, используйте инструкцию ALTER VIEW.
Сканирование с пропуском
Сканирование с пропуском использует один или несколько столбцов составного индекса для поиска различных значений. В отличие от сканирования по диапазону, сканирование с пропуском реализует сканирование внутри строк, повышая производительность. Во время сканирования значение первого совпадения пропускается вместе с индексом до тех пор, пока не будет найдено следующее значение.
Сканирование с пропуском использует перечисление SEEK_NEXT_USING_HINT фильтра HBase. С помощью SEEK_NEXT_USING_HINT при сканировании с пропуском отслеживается набор ключей или диапазон ключей, выполняемый в каждом столбце. Затем определяется, соответствует ли ключ, переданный во время оценки фильтра, одному из сочетаний. Если нет, оценивается следующий ключ с самым высоким значением для перехода.
Транзакции
Не смотря на то, что HBase предоставляет транзакции на уровне строк, Phoenix интегрируется с Tephra, чтобы добавить поддержку транзакций между строками и между таблицами с полной семантикой ACID.
Как и в случае с традиционными транзакциями SQL, транзакции, предоставляемые через диспетчер транзакций Phoenix, позволяют гарантировать, что при сбое операции upsert в любой транзакционной таблице атомарная единица данных будет успешно восстановлена, а транзакция вернется в исходное положение.
Дополнительные сведения о включении транзакций Phoenix см. в документации по транзакциям Apache Phoenix.
Чтобы создать таблицу с включенными транзакциями, для свойства TRANSACTIONAL установите значение true в инструкции CREATE:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Чтобы изменить имеющуюся таблицу на транзакционную, используйте одно и то же свойство в инструкции ALTER:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Примечание.
Транзакционную таблицу невозможно обратно переключить на нетранзакционную.
Таблицы случайных данных
При фиксировании записей с последовательными ключами в HBase может возникнуть перегрузка региональных серверов Не смотря на то, что у вас может быть несколько региональных серверов в кластере, ваши записи обрабатываются только на одном. Эта концентрация создает проблему "гиперобъекта". Только один сервер обрабатывает всю рабочую нагрузку вместо ее распределения по всем доступным региональным серверам. Каждый регион имеет предопределенный максимальный размер, и при достижении этого предела он разбивается на два небольших региона. После этого один из новых регионов принимает все новые записи, становясь новым гиперобъектом.
Чтобы решить эту проблему и добиться большей производительности, предварительно разделите таблицы так, чтобы все региональные серверы использовались одинаково. Phoenix предоставляет таблицы случайных данных, прозрачно добавляя байт случайных данных к ключу строки для конкретной таблицы. Таблица предварительно разделена на границы байта случайных данных, чтобы обеспечить равное распределение нагрузки между региональными серверами во время начальной фазы таблицы. При этом рабочая нагрузка операций записи распределяется между всеми доступными региональными серверами, улучшая производительность записи и чтения. Чтобы создать таблицу случайных данных, при ее создании укажите свойство SALT_BUCKETS:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Включение и настройка Phoenix с Apache Ambari
Кластер HDInsight An HBase включает в себя пользовательский интерфейс Ambari для внесения изменений в конфигурацию.
Чтобы включить или отключить Phoenix и управлять настройками времени ожидания запроса Phoenix, войдите в веб-интерфейс Ambari (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) с помощью учетных данных пользователя Hadoop.Из списка служб в меню слева выберите HBase, а затем выберите вкладку Конфигурация.
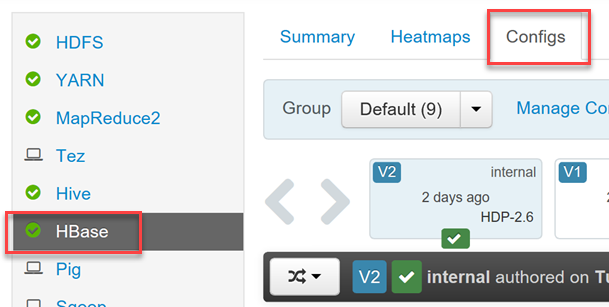
Найдите раздел конфигурации Phoenix SQL, чтобы включить или отключить Phoenix и установить время ожидания запроса.