Установка кластеров в HDInsight с использованием Apache Hadoop, Apache Spark, Apache Kafka и других технологий
Узнайте, как установить и настроить Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query или Apache HBase в HDInsight. Кроме того, вы узнаете, как повысить безопасность кластеров путем их присоединения к домену.
Кластер Hadoop включает в себя несколько виртуальных машин (узлов), которые используются для распределенной обработки задач. Azure HDInsight управляет сведениями об установке и настройке отдельных узлов, поэтому вам нужно указать только общие сведения о конфигурации.
Внимание
Начисление оплаты начинается после создания кластера HDInsight и прекращается только после его удаления. Кластеры оплачиваются поминутно, поэтому всегда следует удалять кластер, когда он больше не нужен. Узнайте, как удалить кластер.
Если вы используете несколько кластеров вместе, вам нужно создать виртуальную сеть. Если же вы используете кластер Spark, вы также можете использовать Hive Warehouse Connector. См. сведения о планировании виртуальной сети для Azure HDInsight и интеграции Apache Spark и Apache Hive с Hive Warehouse Connector.
Способы установки кластера
В приведенной ниже таблице представлены различные способы установки кластера HDInsight.
| Метод создания кластеров | Веб-браузер | Командная строка | REST API | SDK |
|---|---|---|---|---|
| Портал Azure | ✅ | |||
| Фабрика данных Azure | ✅ | ✅ | ✅ | ✅ |
| Azure CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Шаблоны диспетчера ресурсов Azure | ✅ |
В этой статье приводятся пошаговые инструкции по выполнению установки на портале Azure, где можно создать кластер HDInsight.
Основные сведения
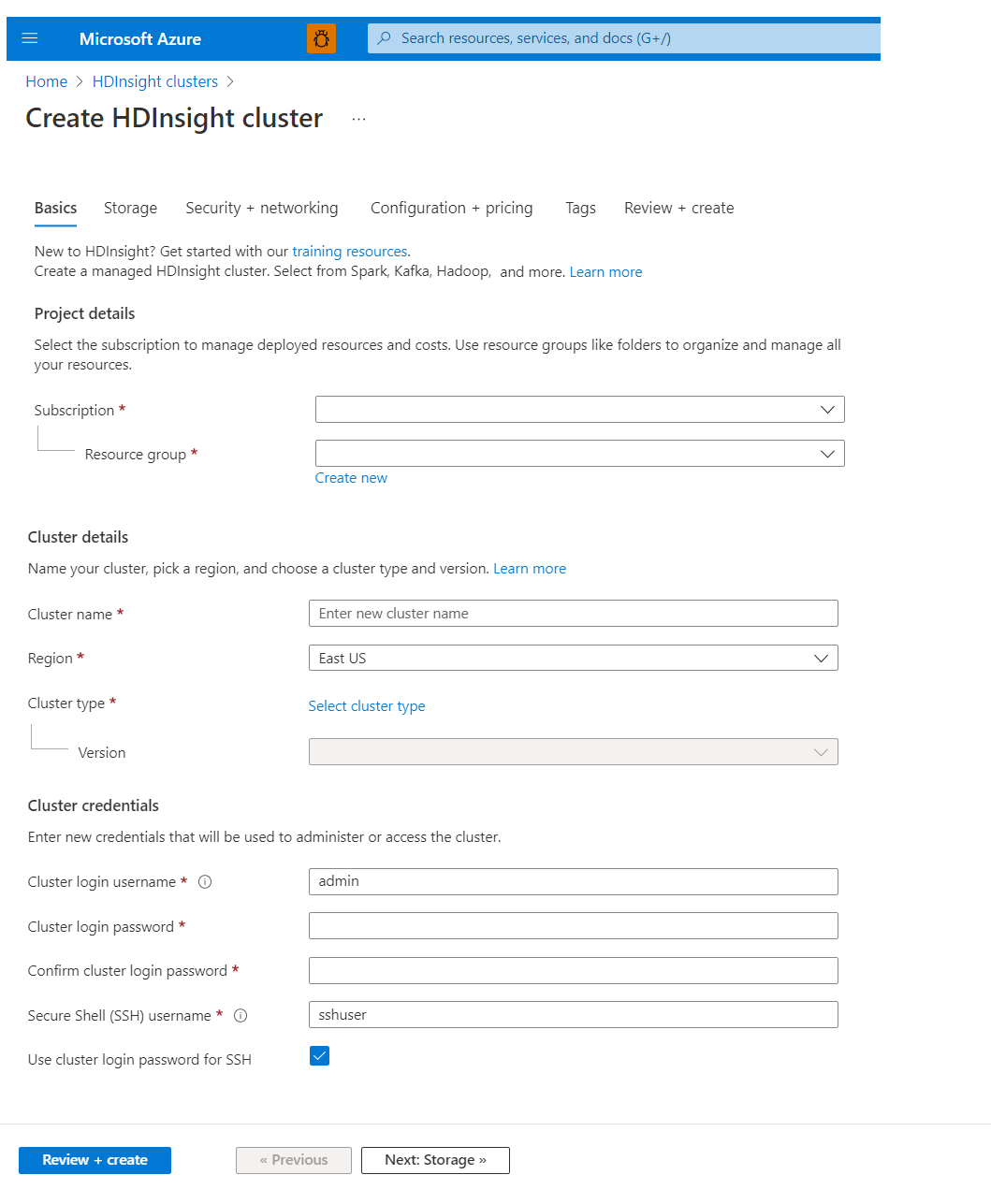
Сведения о проекте
Azure Resource Manager позволяет работать с ресурсами в приложении в виде группы, которая называется группой ресурсов Azure. Вы можете развертывать, обновлять, отслеживать или удалять все ресурсы для приложения в рамках одной скоординированной операции.
Сведения о кластере
Имя кластера
На имена кластеров HDInsight налагаются указанные ниже ограничения.
- Допустимые символы: a–z, 0–9, A–Z
- Максимальная длина: 59 символов
- Зарезервированные имена: apps
- Имена кластеров должны быть уникальными в рамках всех подписок Azure. То есть имя кластера должно быть уникальным по всему миру.
- Первые шесть символов должны быть уникальными в рамках виртуальной сети.
Область/регион
Расположение кластера не требуется указывать явно: кластер находится в том же расположении, что и хранилище по умолчанию. Просмотреть поддерживаемые регионы можно в раскрывающемся списке Регион на странице Цены на HDInsight.
Тип кластера
В настоящее время Azure HDInsight предоставляет указанные ниже типы кластеров, каждый из которых имеет набор компонентов для предоставления определенных функциональных возможностей.
Внимание
Доступны различные типы кластеров HDInsight, каждый из которых предназначен для отдельной рабочей нагрузки или технологии. Создать кластер, в котором бы объединились несколько типов, например, HBase, нельзя. Если для решения нужны технологии, распределенные по нескольким типам кластеров HDInsight, виртуальная сеть Azure может объединять необходимые типы кластеров.
| Тип кластера | Функция |
|---|---|
| Hadoop | Пакетный запрос и анализ хранимых данных |
| HBase | Обработка больших объемов данных NoSQL без схемы |
| Интерактивный запрос | Кэширование в памяти для обеспечения интерактивных и ускоренных запросов Hive |
| Kafka | Распределенная платформа потоковой передачи с открытым кодом, которую можно использовать для создания конвейеров и приложений потоковой передачи данных в режиме реального времени. |
| Spark | Обработка в памяти, интерактивные запросы, обработка потоков микро-пакетов |
Версия
Выберите версию HDInsight для этого кластера. Дополнительные сведения см. в разделе Поддерживаемые версии HDInsight.
Учетные данные кластера
Во время создания кластера HDInsight можно настроить две учетные записи пользователя.
- Имя пользователя для входа в кластер. Имя пользователя по умолчанию — admin. Для него используется базовая конфигурация на портале Azure. Иногда его называют "пользователем кластера" или "пользователем HTTP".
- Имя пользователя Secure Shell (SSH). Используется для подключения к кластеру по протоколу SSH. Дополнительные сведения см. в статье Подключение к HDInsight (Hadoop) с помощью SSH.
Имя пользователя HTTP имеет следующие ограничения:
- Разрешенные специальные символы:
_и@ - Символы не разрешены:
#;."',/:!*?$(){}[]<>|&--=+%~^space' - Максимальная длина: 20
Имя пользователя SSH имеет следующие ограничения:
- Разрешенные специальные символы:
_и@ - Символы не разрешены:
#;."',/:!*?$(){}[]<>|&--=+%~^space' - Максимальная длина: 64
- Зарезервированные имена: hadoop, users, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, admin, user1, user1, test2, test1, user3, admin1, 1, 123, a
actuser, adm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Хранилище
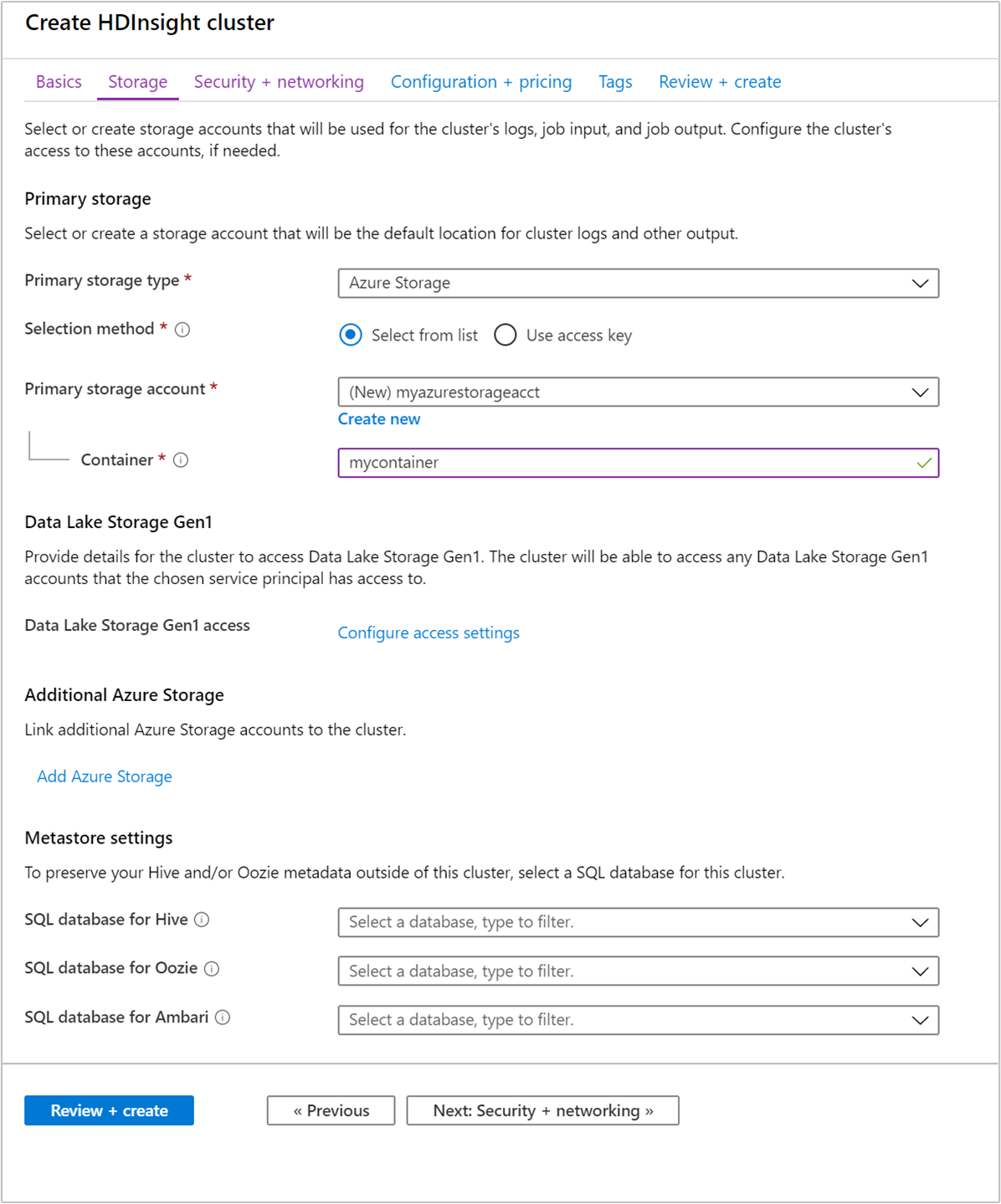
Хотя при локальной установке кластера Hadoop для хранилища используется распределенная файловая система Hadoop (HDFS), в облаке применяются конечные точки хранилища, подключенные к кластеру. Использование облачного хранилища означает, что вы можете спокойно удалять кластеры HDInsight, используемые для расчета, не теряя данные.
Кластеры HDInsight могут использовать следующие варианты хранилищ:
- Azure Data Lake Storage 2-го поколения
- Хранилище Azure Data Lake Storage 1-го поколения
- Служба хранилища Azure общего назначения версии 2.
- Служба хранилища Azure общего назначения версии 1.
- Служба хранилища Azure для блочных BLOB-объектов (поддерживается только в качестве дополнительного хранилища).
Дополнительные сведения о вариантах хранилищ с HDInsight см. в статье Сравнение вариантов хранилищ для использования с кластерами Azure HDInsight.
Предупреждение
Использование дополнительной учетной записи хранения, местоположение которой отличается от местоположения кластера HDInsight, не поддерживается.
Во время настройки вы указываете контейнер BLOB-объектов в учетной записи хранения Azure или хранилище Data Lake Storage для конечной точки хранилища по умолчанию. Хранилище по умолчанию содержит журналы приложений и системный журнал. При необходимости вы можете указать дополнительные связанные учетные записи хранения Azure и учетные записи Data Lake Storage, к которым кластер может получать доступ. Кластер HDInsight должен находиться в том же расположении Azure, что и зависимые учетные записи хранения.
Примечание.
Функция, требующая безопасной передачи, обеспечивает принудительную передачу всех запросов к вашей учетной записи через безопасное подключение. Только кластер HDInsight версии 3.6 или более новой поддерживает эту функцию. Дополнительные сведения см. в статье Создание кластера Apache Hadoop с помощью учетных записей хранения с безопасной передачей в Azure HDInsight.
Внимание
Включение безопасного перемещения хранилища после создания кластера может привести к ошибкам при использовании учетной записи хранения, а поэтому не рекомендуется. Лучше создать кластер, используя учетную запись хранения с уже включенным безопасным перемещением.
Примечание.
Azure HDInsight автоматически не перемещает и не копирует хранимые данные в службе хранилища Azure из одного региона в другой.
Параметры хранилища метаданных
Вы можете создать дополнительные хранилища метаданных Hive или Apache Oozie. Однако не все типы кластеров поддерживают хранилища метаданных, а служба Azure Synapse Analytics несовместима с хранилищами метаданных.
Дополнительную информацию см. в статье Использование внешних хранилищ метаданных в Azure HDInsight.
Внимание
Создавая пользовательское хранилище метаданных, не используйте в имени базы данных тире, дефисы и пробелы. Это может привести к сбою при создании кластера.
База данных SQL для Hive
Если вы хотите сохранить таблицы Hive после удаления кластера HDInsight, используйте пользовательское хранилище метаданных. Затем можно будет подключить это хранилище к другому кластеру HDInsight.
Хранилище метаданных HDInsight, созданное для одной версии кластера HDInsight, не может использоваться в других версиях такого кластера. Список версий HDInsight см. в разделе Поддерживаемые версии HDInsight.
Внимание
По умолчанию хранилище метаданных предоставляет базу данных SQL Azure с базовым лимитом единиц передачи данных (DTU) уровня 5 (не обновляется)! Оно подходит для базового тестирования. Для больших или производственных рабочих нагрузок рекомендуется перейти на внешнее хранилище метаданных.
База данных SQL для Oozie
Для повышения производительности Oozie используйте пользовательское хранилище метаданных. Хранилище метаданных также позволяет осуществлять доступ к данным задания Oozie после удаления кластера.
База данных SQL для Ambari
Ambari используется для мониторинга кластеров HDInsight, внесения изменений в конфигурацию и хранения информации об управлении кластерами, а также журнала заданий. Функция пользовательской базы данных Ambari DB позволяет развернуть новый кластер и настроить Ambari во внешней управляемой вами базе данных. Подробнее см. в статье Пользовательская база данных Ambari DB.
Внимание
Повторно использовать хранилище метаданных Oozie невозможно. Чтобы использовать пользовательское хранилище метаданных Oozie, при создании кластера HDInsight необходимо предоставить пустую базу данных SQL Azure.
Безопасность и сеть
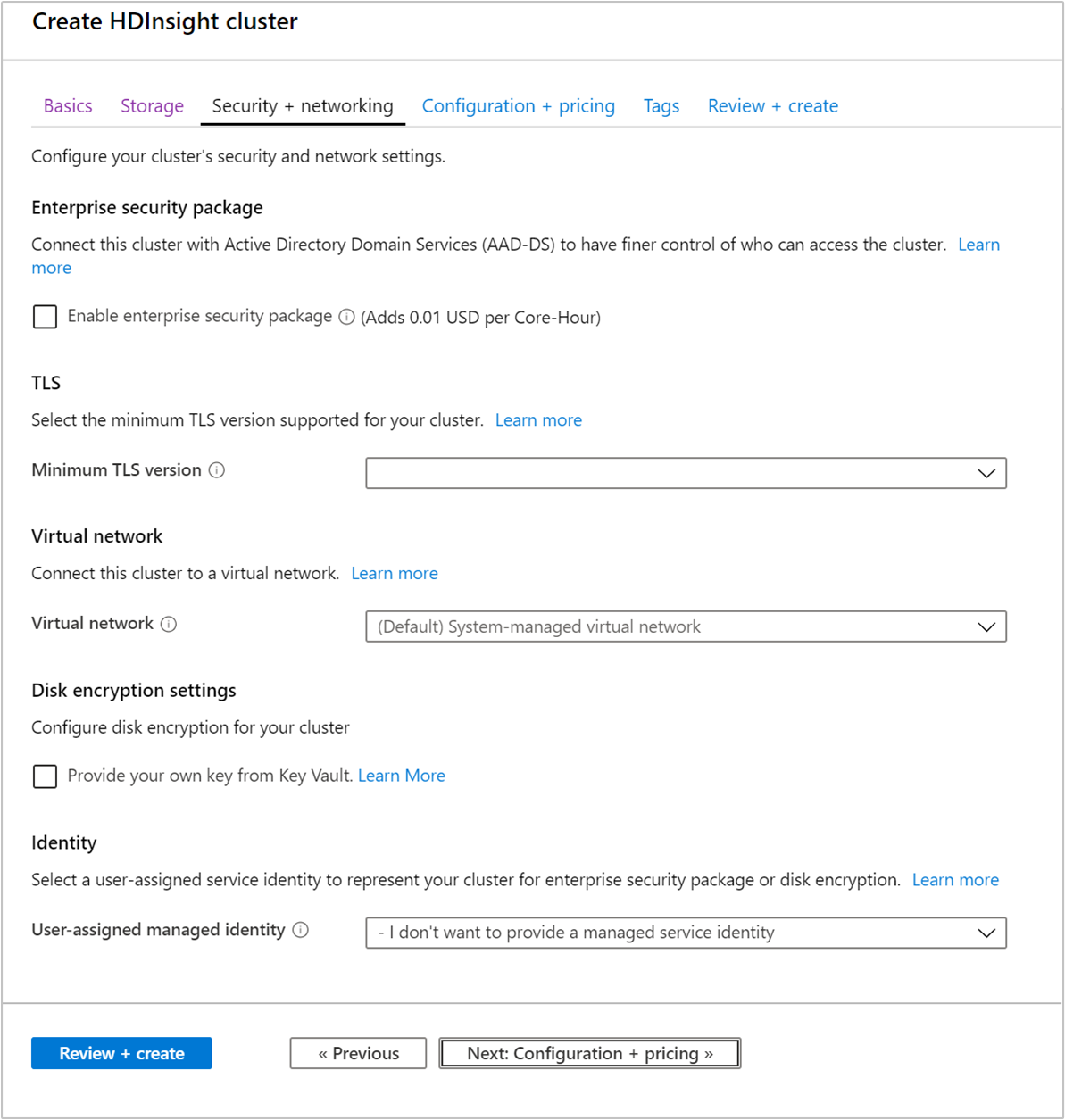
Корпоративный пакет безопасности
Для кластеров типа Hadoop, Spark, HBase, Kafka и Interactive Query вы можете включить Корпоративный пакет безопасности. Этот пакет предоставляет возможность более безопасной настройки кластера с помощью Apache Ranger и интеграции с идентификатором Microsoft Entra. Дополнительные сведения см. в статье Общие сведения о корпоративной безопасности в Azure HDInsight.
Пакет безопасности предприятия позволяет интегрировать HDInsight с Active Directory и Apache Ranger. При помощи пакета безопасности корпоративного уровня можно создать нескольких пользователей.
Дополнительные сведения о создании присоединенного к домену кластера HDInsight см. в статье о создании присоединенной к домену среды песочницы HDInsight.
TLS
Дополнительные сведения см. в статье о протоколе TLS.
Виртуальная сеть
Если для решения нужны технологии, распределенные по нескольким типам кластеров HDInsight, виртуальная сеть Azure может объединять необходимые типы кластеров. Благодаря такой конфигурации кластеры и любой развернутый в них код могут взаимодействовать друг с другом напрямую.
Подробные сведения об использовании виртуальных сетей Azure в HDInsight см. в статье Планирование виртуальной сети для Azure HDInsight.
Пример использования двух типов кластера в виртуальной сети Azure см. в статье об использовании структурированного потока Apache Spark при помощи Apache Kafka. Дополнительные сведения об использовании HDInsight в виртуальной сети, включая требования к конфигурации виртуальной сети, см. в статье Планирование виртуальной сети для Azure HDInsight.
Параметр шифрования диска
Подробнее см. статью о шифровании диска с управляемыми клиентом ключами.
Прокси-сервер REST для Kafka
Этот параметр доступен только для типа кластера Kafka. Дополнительные сведения см. в статье со сведениями об использовании прокси-сервера REST.
Идентификация
Дополнительные сведения см. в статье Управляемые удостоверения в Azure HDInsight.
Конфигурация и цены
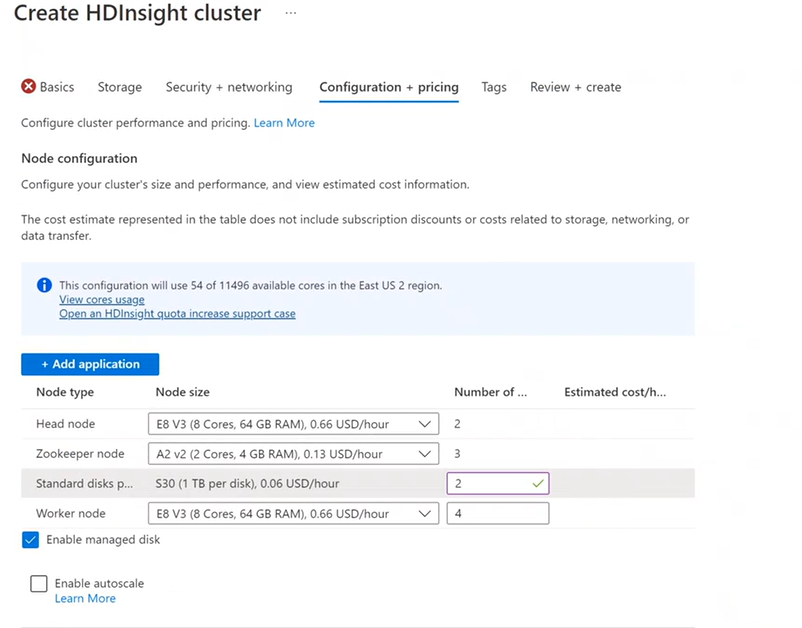
Плата за использование узлов взимается, пока существует кластер. Начисление оплаты начинается после создания кластера и прекращается только после его удаления. Перевести кластер в режим ожидания или отменить его выделение невозможно.
конфигурация узла;
Для каждого типа кластера используется своя терминология. Кроме того, типы отличаются количеством узлов и стандартными размерами виртуальных машин. В следующей таблице число узлов каждого типа указано в скобках.
| Тип | Узлы | Схема |
|---|---|---|
| Hadoop | Головной узел (2), рабочий узел (от 1) | 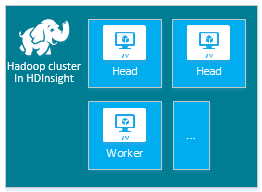
|
| HBase | Головной сервер (2), региональный сервер (от 1), основной узел или узел Zookeeper (3) | 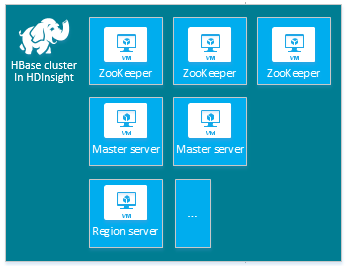
|
| Spark | Головной узел (2), рабочий узел (от 1), узел ZooKeeper (3) (кат. "Бесплатный" для размера виртуальной машины ZooKeeper A1) | 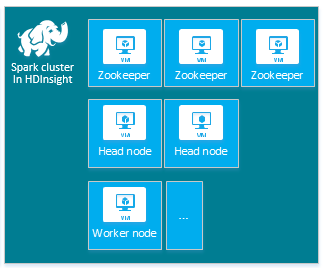
|
Дополнительные сведения см. в разделе Конфигурация узлов и размеры виртуальных машин по умолчанию для кластеров статьи "Что представляют собой компоненты и версии Hadoop, доступные в HDInsight?"
Затраты на кластеры HDInsight определяются числом узлов и размерами виртуальных машин на узлах.
Кластеры разных типов отличаются типами, количеством и размерами узлов.
- Тип кластера Hadoop по умолчанию:
два головных узла;
четыре рабочих узла.
При пробном использовании HDInsight рекомендуем применять один рабочий узел. Подробные сведения о ценах на HDInsight см. на этой странице.
Примечание.
Максимальный размер кластера зависит от подписки Azure. Чтобы увеличить лимит, обратитесь в службу поддержки по вопросам выставления счетов Azure.
При настройке кластера на портале Azure размер узла можно выбрать на вкладке Конфигурация и цены. На портале также отображаются расценки на узлы разных размеров.
Размеры виртуальных машин
При развертывании кластеров выберите вычислительные ресурсы в зависимости от решения, которое планируется развернуть. Для кластеров HDInsight используются следующие виртуальные машины:
- виртуальные машины серий A и D1–4: Размеры виртуальных машин Linux общего назначения;
- виртуальные машины серии D11–14: Размеры виртуальных машин Linux, оптимизированных для памяти.
Сведения о том, какие значения следует указывать для размера виртуальной машины при создании кластера с помощью различных пакетов SDK или Azure PowerShell, см. в разделе Таблицы размеров. Используйте значение из столбца Размер таблиц, приведенных в этой статье.
Внимание
Если в кластере требуется более 32 рабочих узлов, для головного узла следует выбрать размер как минимум с 8 ядрами и 14 ГБ ОЗУ.
Дополнительные сведения см. в разделе Размеры виртуальных машин. Сведения о расценках на разные размеры см. здесь.
Добавление дисков
Примечание.
Добавленные диски настраиваются только для локальных каталогов диспетчера узлов, а не для каталогов datanode
Кластер HDInsight поставляется с предварительно заданным дисковым пространством на основе номера SKU. При выполнении некоторых крупных приложений может привести к нехватке места на диске с ошибкой полного диска и LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE сбоями заданий.
С помощью новой функции, локального каталога NodeManager, в кластер можно добавить дополнительные диски. Во время создания кластеров Hive и Spark можно выбрать количество дисков и добавить их на рабочие узлы. Выбранный диск (размер каждого из них — 1 ТБ) становится частью локальных каталогов NodeManager.
- Перейдите на вкладку Конфигурация и цены
- Выберите параметр Включить управляемый диск
- В разделе дисках уровня "Стандартный" введите Количество дисков
- Выберите свой Рабочий узел
Количество дисков можно проверить на вкладке Просмотр и создание в разделе Конфигурация кластера
Добавить приложение
Пользователи могут устанавливать приложения HDInsight в кластере HDInsight под управлением Linux. Можно использовать приложения, предоставляемые корпорацией Майкрософт, сторонними производителями или разработанные самостоятельно. Дополнительные сведения см. в статье Установка сторонних приложений Apache Hadoop в Azure HDInsight.
Большинство приложений HDInsight устанавливаются в пустой граничный узел. Пустой граничный узел — это виртуальная машина Linux, на которой установлены и настроены те же клиентские инструменты, что и на головном узле. Граничный узел можно использовать для доступа к кластеру, а также тестирования и размещения клиентских приложений. Подробные сведения см. в статье Использование пустых граничных узлов в HDInsight.
Действия скрипта
Можно установить дополнительные компоненты или настроить конфигурацию кластера с помощью сценариев во время создания. Такие скрипты вызываются с помощью действия скрипта — параметра конфигурации, который может использоваться с помощью портала Azure, командлетов HDInsight PowerShell или пакета SDK для HDInsight .NET. Дополнительные сведения см. в статье Настройка кластеров HDInsight под управлением Linux с помощью действия сценария.
Некоторые собственные компоненты Java, такие как Apache Mahout и Cascading, могут выполняться в кластере как архивные файлы (JAR) Java. Эти JAR-файлы можно распространить в службе хранилища Azure и отправить в кластеры HDInsight с помощью механизмов отправки заданий Hadoop. См. дополнительные сведения об отправке заданий Apache Hadoop программными средствами.
Примечание.
Если при развертывании или вызове JAR-файлов в кластерах HDInsight возникают проблемы, обратитесь в службу поддержки Майкрософт.
Компонент Cascading не поддерживается службой HDInsight и на него не распространяется техническая поддержка Майкрософт. Списки поддерживаемых компонентов см. в статье Что представляют собой различные компоненты Hadoop, доступные в HDInsight?
В некоторых случаях требуется изменить следующие файлы конфигурации в процессе создания:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- Hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Подробные сведения см. в статье Настройка кластеров HDInsight с помощью начальной загрузки.
Следующие шаги
- Устранение сбоев, возникающих при создании кластера с помощью Azure HDInsight
- Что такое Azure HDInsight и стек технологий Apache Hadoop
- Краткое руководство. Использование Apache Hadoop и Apache Hive в Azure HDInsight с шаблоном Resource Manager
- Работа в экосистеме Hadoop в HDInsight на компьютере с Windows