Интеграция Apache Spark и Apache Hive с помощью Hive Warehouse Connector в Azure HDInsight
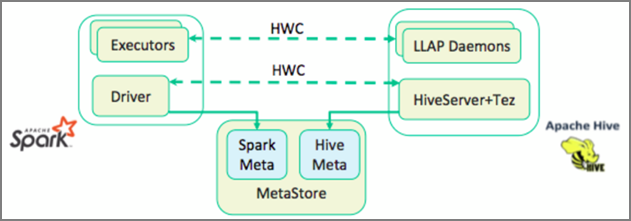
Apache Hive Warehouse Connector — это библиотека, которая позволяет быстрее работать с Apache Spark и Apache Hive. Она поддерживает такие задачи, как перемещение данных между кадрами и таблицами Hive в Spark. А также направление данных потоковой передачи Spark в таблицы Hive. Hive Warehouse Connector работает как мост между Spark и Hive. Он также поддерживает Scala, Java и Python в качестве языков программирования для разработки.
Hive Warehouse Connector позволяет использовать преимущества уникальных функций Hive и Spark для создания мощных приложений для работы с большими данными.
Apache Hive предлагает поддержку для транзакций базы данных, которые являются атомарными, постоянными, изолированными и устойчивыми (ACID). Дополнительные сведения о ACID и транзакциях в Hive см. в разделе Транзакции Hive. Hive также предлагает подробные элементы управления безопасностью с помощью Apache Ranger и аналитической обработки с низкой задержкой (LLAP), которая недоступна в Apache Spark.
Apache Spark имеет API структурированной потоковой передачи, который предоставляет возможности потоковой передачи, недоступные в Apache Hive. Начиная с HDInsight 4.0, Apache Spark 2.3.1 и выше, и Apache Hive 3.1.0 имеют отдельные каталоги хранилища метаданных, что затрудняет взаимодействие.
Hive Warehouse Connector (HWC) упрощает совместное использование Spark и Hive. Библиотека HWC загружает данные из управляющих программ LLAP в исполнители Spark параллельно. Этот процесс повышает эффективность и адаптацию по сравнению со стандартным соединением JDBC для Spark к Hive. Это приводит к двум различным режимам выполнения для HWC:
- Режим JDBC Hive через HiveServer2
- Режим LLAP Hive с использованием управляющих программ LLAP [рекомендуется]
По умолчанию HWC настроен для использования управляющих программ Hive LLAP. Инструкции по выполнению запросов Hive (чтение и запись) с использованием указанных выше режимов с соответствующими API-интерфейсами см. в разделе HWC API.
Операции, поддерживаемые Hive Warehouse Connector:
- описание таблицы;
- создание таблицы для данных в формате ORC;
- выбор данных Hive и получение кадра данных;
- пакетная запись кадров данных в Hive;
- выполнение инструкции обновления Hive;
- чтение данных таблицы из Hive, их преобразование в Spark и запись в новую таблицу Hive;
- запись кадра данных или потока Spark в Hive с помощью HiveStreaming.
Настройка Hive Warehouse Connector
Внимание
- Экземпляр HiveServer2 Interactive, установленный в кластерах корпоративного пакета безопасности для Spark 2.4, не поддерживает работу с Hive Warehouse Connector. Вместо этого вам следует настроить отдельный кластер HiveServer2 Interactive, чтобы размещать рабочие нагрузки HiveServer2 Interactive. Конфигурация Hive Warehouse Connector с одним кластером Spark 2.4 не поддерживается.
- Также не поддерживается использование библиотеки HWC (Hive Warehouse Connector) с кластером Interactive Query, для которого включена возможность управления рабочей нагрузкой (WLM).
Если в вашем сценарии используются только рабочие нагрузки Spark и вам нужна библиотека HWC, отключите для кластера Interactive Query возможность управления рабочей нагрузкой (параметр конфигурацииhive.server2.tez.interactive.queueне должен быть задан в конфигурациях Hive).
Если в вашем сценарии есть и рабочие нагрузки Spark (HWC), и собственные рабочие нагрузки LLAP, вам потребуются два отдельных кластера Interactive Query с общей базой данных для метаданных. Один из этих кластеров будет выполнять рабочие нагрузки LLAP, и для него можно применять WLM по мере необходимости, а второй будет выделен для рабочих нагрузок HWC, и для него нельзя настраивать возможность WLM. Важно отметить, что вы можете просматривать планы ресурсов WLM из обоих кластеров, даже если он включен только в одном кластере. Не вносите никаких изменений в планы ресурсов в том кластере, где отключена возможность WLM. Эти изменения могут повлиять на работу WLM в другом кластере. - Хотя Spark поддерживает язык вычислений R для упрощения анализа данных, Библиотека соединителя хранилища Hive (HWC) не поддерживается для использования с R. Для выполнения рабочих нагрузок HWC можно выполнять запросы из Spark в Hive с помощью API HiveWarehouseSession в стиле JDBC, поддерживающего только Scala, Java и Python.
- Исполнение запросов (чтение и запись) через HiveServer2 в режиме JDBC не поддерживается для сложных типов данных, таких как массивы, структуры и типы карт.
- HWC поддерживает запись только в форматах файлов ORC. Запись в форматах, отличных от ORC (например, форматы Parquet и текстовые файлы), не поддерживается через HWC.
Для Hive Warehouse Connector требуются отдельные кластеры для рабочих нагрузок Spark и Interactive Query. Выполните следующие действия, чтобы настроить эти кластеры в Azure HDInsight.
Поддерживаемые типы кластеров и версии
| Версия HWC | Версия Spark | Версия InteractiveQuery |
|---|---|---|
| Версия 1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| Версия 2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
Создание кластеров
Создайте кластер HDInsight Spark 4.0 с учетной записью хранения и настраиваемой виртуальной сетью Azure. Сведения о создании кластера в виртуальной сети Azure см. в статье Добавление HDInsight в существующую виртуальную сеть.
Создайте кластер HDInsight Interactive Query (LLAP) 4.0 с той же учетной записью хранения и виртуальной сетью Azure, что и кластер Spark.
Настройка параметров HWC
Сбор предварительных сведений
В веб-браузере перейдите по адресу
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE, указав вместо LLAPCLUSTERNAME имя кластера Interactive Query.Перейдите в раздел Сводка>URL-адрес HiveServer2 Interactive JDBC и запишите значение. Значение может выглядеть следующим образом:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Перейдите в раздел Конфигурации>Дополнительно>Расширенный hive-site>hive.zookeeper.quorum и запишите значение. Значение может выглядеть следующим образом:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Перейдите в раздел Конфигурации>Дополнительно>Общие>hive.metastore.uris и запишите значение. Значение может выглядеть следующим образом:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Перейдите в раздел Конфигурации>Дополнительно>Расширенный hive-interactive-site>hive.llap.daemon.service.hosts и запишите значение. Значение может выглядеть следующим образом:
@llap0.
Настройка параметров кластера Spark
В веб-браузере перейдите на страницу с адресом
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs, заменив CLUSTERNAME именем кластера Apache Spark.Разверните Custom spark2-defaults.
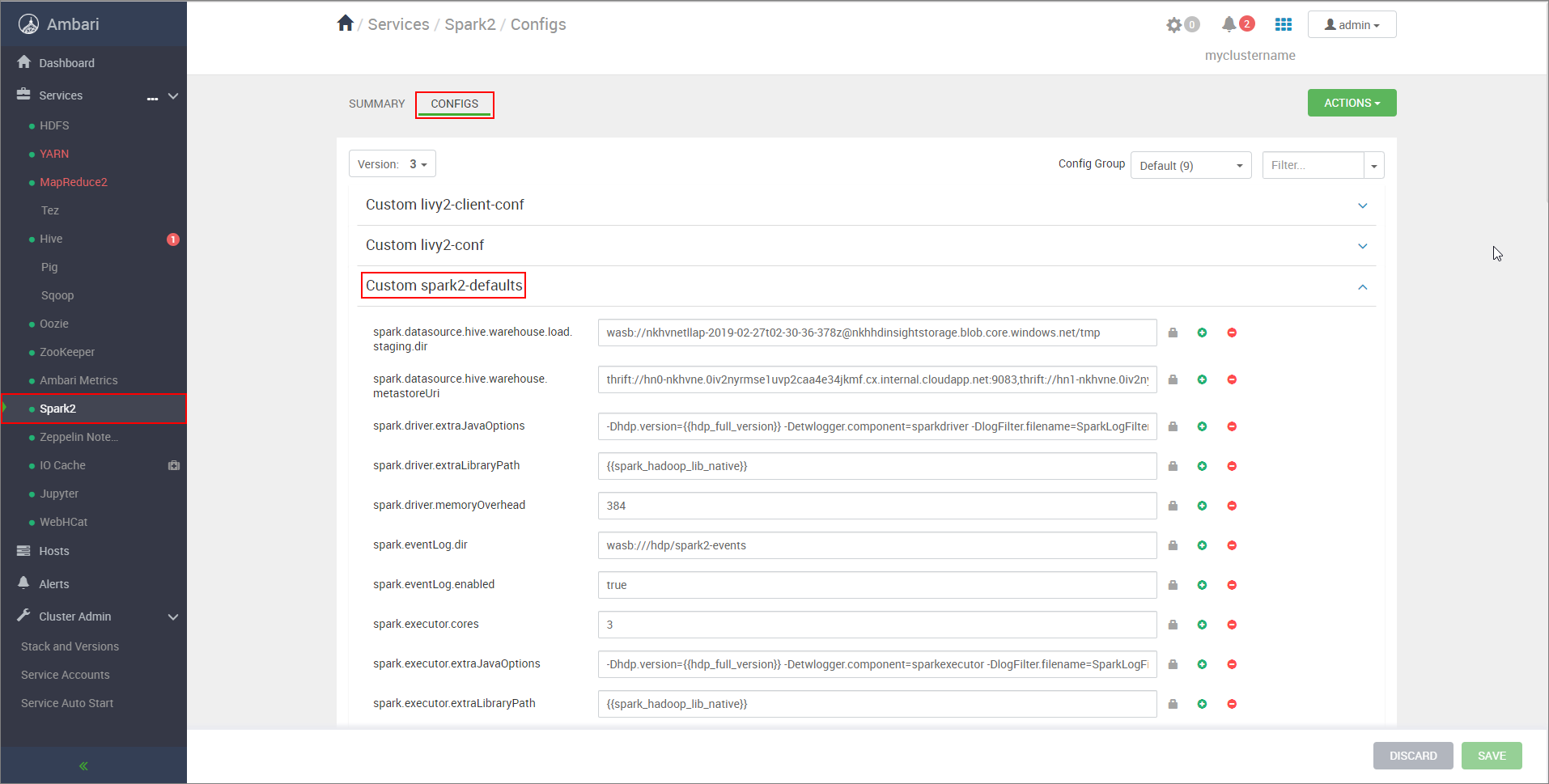
Щелкните Add Property... (Добавить свойство...), чтобы добавить следующие конфигурации:
Настройка Значение spark.datasource.hive.warehouse.load.staging.dirЕсли вы используете ADLS 2-го поколения служба хранилища учетной записи, используйте abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Если вы используете Хранилище BLOB-объектов Azure учетную запись, используйтеwasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Задайте подходящий каталог временного размещения, совместимый с HDFS. Если у вас есть два разных кластера, промежуточный каталог должен быть папкой в промежуточном каталоге учетной записи хранения кластера LLAP, чтобы у HiveServer2 был доступ к нему. ЗаменитеSTORAGE_ACCOUNT_NAMEименем учетной записи хранения, используемой кластером, аSTORAGE_CONTAINER_NAME— именем контейнера хранилища.spark.sql.hive.hiveserver2.jdbc.urlЗначение, полученное ранее из URL-адреса HiveServer2 Interactive JDBC spark.datasource.hive.warehouse.metastoreUriЗначение, полученное ранее из hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtrueдля режима кластера YARN иfalseдля режима клиента YARN.spark.hadoop.hive.zookeeper.quorumЗначение, полученное ранее из hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsЗначение, полученное ранее из hive.llap.daemon.service.hosts. Сохраните изменения и перезапустите все затронутые компоненты.
Настройка HWC для кластеров с Корпоративным пакетом безопасности (ESP).
Корпоративный пакет безопасности (ESP) обеспечивает возможности корпоративного класса, например проверку подлинности на основе Active Directory, многопользовательскую поддержку и управление доступом на основе ролей для кластеров Apache Hadoop в Azure HDInsight. Дополнительные сведения о Корпоративном пакете безопасности см. в статье Использование Корпоративного пакета безопасности в HDInsight.
Помимо конфигураций, упомянутых в предыдущем разделе, добавьте следующую конфигурацию для использования HWC в кластерах ESP.
Из веб-интерфейса Ambari в кластере Spark перейдите в раздел Spark2>Конфигурации>Custom spark2-defaults.
Обновите следующее свойство.
Настройка Значение spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>В веб-браузере перейдите по адресу
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, указав вместо CLUSTERNAME реальное имя кластера Interactive Query. Щелкните элемент HiveServer2 Interactive. Вы увидите полное доменное имя головного узла, на котором выполняется LLAP, как показано на снимке экрана. Укажите это значение вместо<llap-headnode>.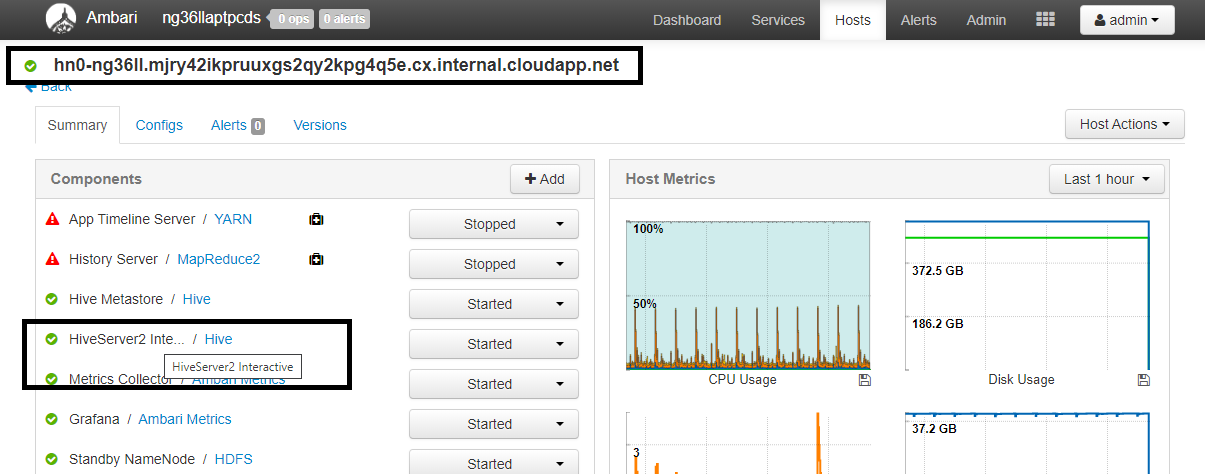
С помощью команды ssh подключитесь к кластеру Interactive Query. Найдите параметр
default_realmв файле/etc/krb5.conf. Укажите это значение вместо<AAD-DOMAIN>, используя буквы верхнего регистра. Иначе учетные данные не будут найдены.
Например,
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Сохраните изменения и перезапустите необходимые компоненты.
Использование Hive Warehouse Connector
Вы можете выбрать один из нескольких методов подключения к кластеру Interactive Query и выполнения запросов с помощью Hive Warehouse Connector. Поддерживаемые методы включают следующие инструменты:
Ниже приведено несколько примеров для подключения к HWC из Spark.
Spark-shell
Это способ интерактивного запуска Spark через измененную версию оболочки Scala.
С помощью команды ssh command подключитесь к кластеру Apache Spark. Измените приведенную ниже команду, заменив CLUSTERNAME именем своего кластера, а затем введите команду:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netВ сеансе SSH выполните следующую команду, чтобы отметить версию
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorИзмените приведенный ниже код, указав версию
hive-warehouse-connector-assembly, указанную выше. Затем выполните команду, чтобы запустить оболочку Spark:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseПосле запуска оболочки Spark экземпляр хранилища Hive Подключение or можно запустить с помощью следующих команд:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit — это служебная программа для отправки любой программы (или задания) Spark в кластеры Spark.
Задание spark-submit настроит и настроит Подключение spark и Hive Warehouse Подключение or в соответствии с нашими инструкциями, выполните программу, которую мы передаем, а затем чисто освобождает используемые ресурсы.
После сборки кода Scala/Java вместе с зависимостями в JAR-файл сборки используйте приведенную ниже команду, чтобы запустить приложение Spark. Замените <VERSION> и <APP_JAR_PATH> соответствующими значениями.
Режим клиента YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarРежим кластера YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Эта программа также используется при написании всего приложения в pySpark и пакете .py в файлы (Python), чтобы мы могли отправить весь код в кластер Spark для выполнения.
Для приложений Python передайте файл .py вместо /<APP_JAR_PATH>/myHwcAppProject.jarэтого и добавьте приведенный ниже файл конфигурации (Python .zip) в путь поиска.--py-files
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Запуск запросов на кластерах с Корпоративным пакетом безопасности (ESP)
Используйте kinit перед запуском spark-shell или spark-submit. Замените USERNAME именем учетной записи домена, имеющей разрешения на доступ к кластеру, а затем выполните следующую команду:
kinit USERNAME
Защита данных в кластерах Spark ESP
Создайте таблицу
demoс образцами данных, введя следующие команды:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Просмотрите содержимое таблицы с помощью следующей команды. Перед применением политики таблица
demoотображает полный столбец.hive.executeQuery("SELECT * FROM demo").show()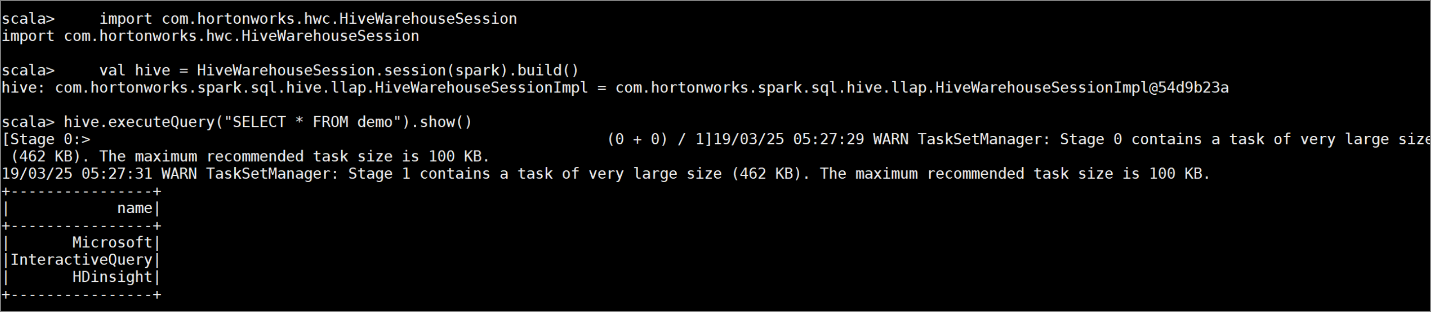
Примените политику маскирования столбцов, которая будет показывать только последние четыре символа столбца.
Перейдите в пользовательский интерфейс администратора Ranger по адресу
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Щелкните службу Hive для кластера в разделе Hive.
Щелкните вкладку Маскирование и нажмите Добавить новую политику
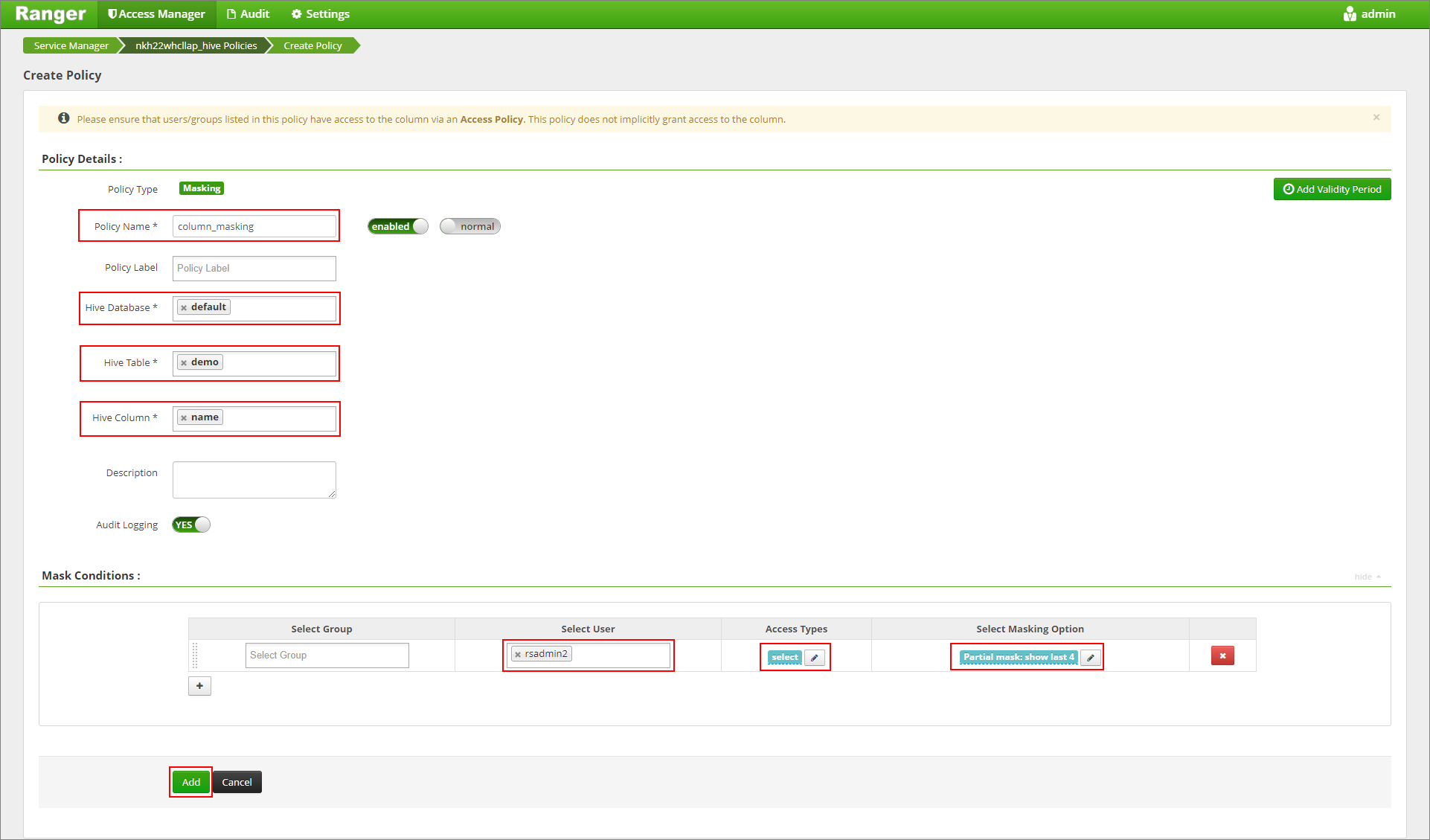
Укажите имя нужной политики. Выбор базы данных: по умолчанию, таблица Hive: демонстрация, столбец Hive: имя, пользователь: rsadmin2, Типы доступа: выбор и частичное маскирование: отображение последних 4 в меню "Выбрать маскирование". Нажмите кнопку Добавить.
Снова просмотрите содержимое таблицы. После применения политики Ranger вы увидите только последние четыре символа столбца.
