Ядра для Jupyter Notebook в кластерах Apache Spark в Azure HDInsight
Кластеры HDInsight Spark предоставляют ядра, которые можно использовать с Jupyter Notebook в Apache Spark для тестирования приложений. Ядра — это программа, которая выполняет и интерпретирует ваш код. Вот эти ядра:
- PySpark — для приложений, написанных на языке Python2. (Применимо только для кластеров Spark версии 2.4)
- PySpark3 — для приложений, написанных на языке Python3.
- Spark — для приложений, написанных на языке Scala.
В этой статье вы узнаете, как использовать эти ядра, а также преимущества их использования.
Необходимые компоненты
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark.
Создание Jupyter Notebook в Spark HDInsight
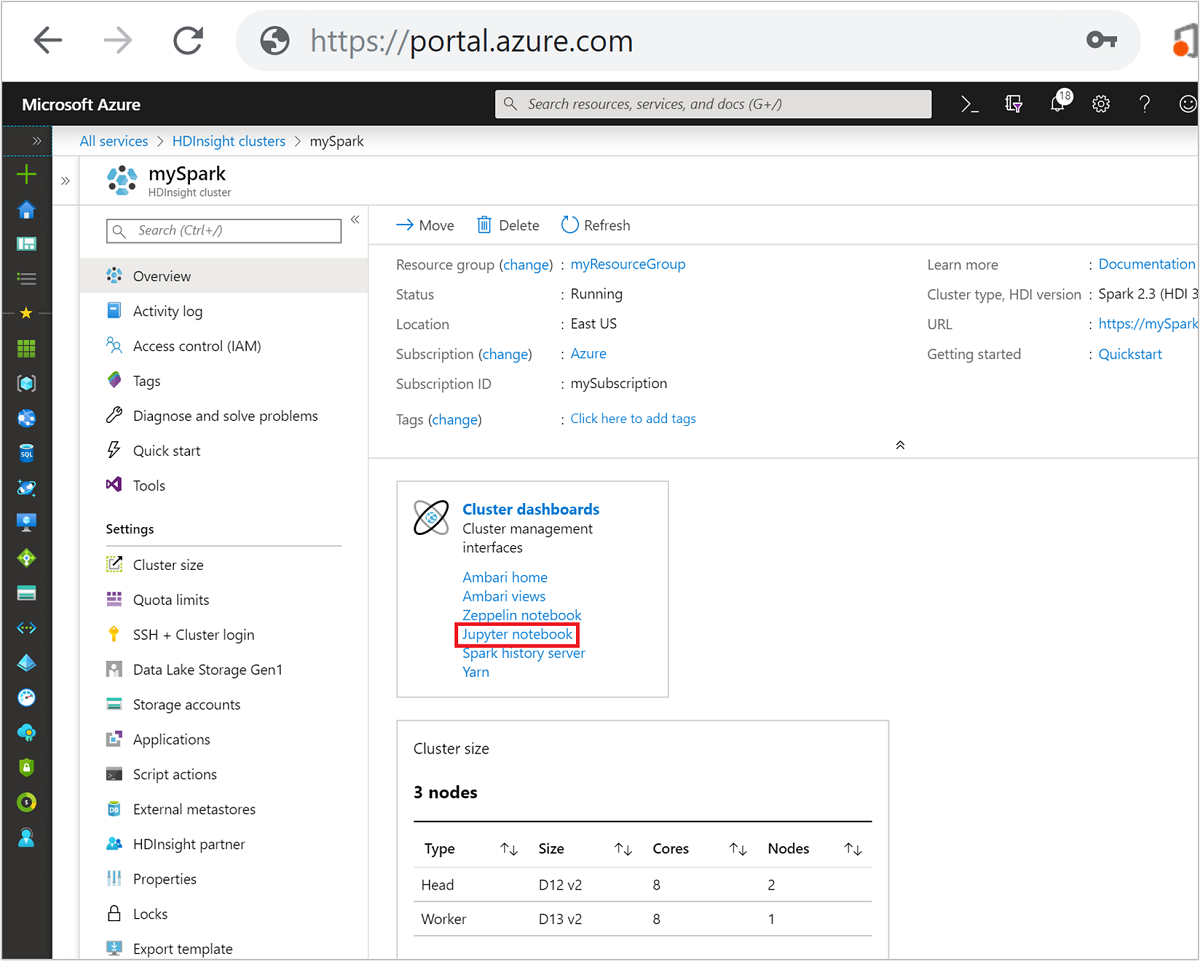
На портале Azure выберите свой кластер Spark. Инструкции см. в разделе Отображение кластеров. Откроется представление Обзор.
В представлении Обзор в поле Панели мониторинга кластера выберите Jupyter Notebook. При появлении запроса введите учетные данные администратора для кластера.
Примечание.
Вы также можете получить доступ к Jupyter Notebook в кластере Spark, открыв следующий URL-адрес в браузере. Замените CLUSTERNAME именем кластера:
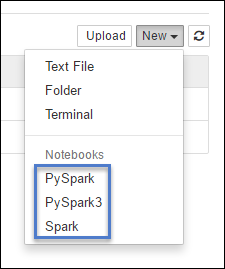
https://CLUSTERNAME.azurehdinsight.net/jupyterЩелкните Создать, а затем — Pyspark, PySpark3 или Spark, чтобы создать записную книжку. Для приложений Scala используйте ядро Spark, для приложений Python2 — ядро PySpark, а для приложений Python3 — ядро PySpark3.
Примечание.
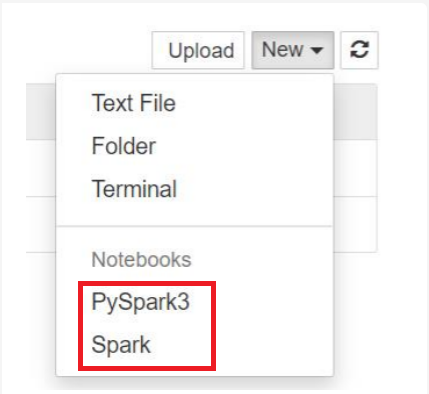
Для Spark версии 3.1 будет доступен только PySpark3 или Spark.
- Объект Notebook должен открыться с помощью выбранного ядра.
Преимущества использования ядер
Ниже приведены некоторые преимущества использования новых ядер для Jupyter Notebook в кластерах Spark HDInsight.
Предустановленные контексты. Благодаря ядрам PySpark, PySpark3 и Spark вам не требуется явно настраивать контексты Spark или Hive перед началом работы с приложениями. Эти контексты доступны по умолчанию, а именно:
sc для контекста Spark;
sqlContext для контекста Hive.
Это значит, что для настройки этих контекстов вам не придется выполнять операторы следующего вида:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Вместо этого вы сможете сразу использовать в своем приложении предустановленные контексты.
Волшебные команды. Ядро PySpark предоставляет несколько "магических команд". Это специальные команды, которые можно вызывать с помощью
%%(например,%%MAGIC<args>). Волшебная команда должна быть первым словом в ячейке кода и может состоять из нескольких строк содержимого. Волшебное слово должно быть первым словом в ячейке. Любые другие слова перед магической командой, даже комментарии, приведут к ошибке. Дополнительные сведения о волшебных командах см. здесь.В следующей таблице перечислены различные магические команды, доступные для ядер.
Волшебная команда Пример Description Справка %%helpФормирует таблицу из всех доступных волшебных слов с примерами и описанием. info %%infoВыводит сведения о сеансе для текущей конечной точки Livy. Настройка %%configure -f{"executorMemory": "1000M","executorCores": 4}Настраивает параметры для создания сеанса. Флаг force ( -f) является обязательным, если сеанс уже был создан, иначе сеанс будет удален и создан заново. Список допустимых параметров приведен в разделе, посвященном тексту запроса сеансов POST Livy . Параметры должны передаваться в виде строки JSON, следующей после волшебной команды, как показано в столбце примера.sql %%sql -o <variable name>
SHOW TABLESВыполняет запрос Hive к sqlContext. Если передан параметр -o, результат запроса сохраняется в контексте Python %%local в качестве таблицы данных Pandas .Локальная среда %%locala=1Весь код в последующих строках выполняется локально. Код должен представлять собой допустимый код Python2 независимо от того, какое ядро вы используете. Таким образом, даже если при создании объекта записной книжки было выбрано ядро PySpark3 или Spark, то при использовании в ячейке магической команды %%localв этой ячейке должен содержаться только допустимый код Python2.журналы %%logsВыводит журналы для текущего сеанса Livy. удалить %%delete -f -s <session number>Удаляет указанный сеанс для текущей конечной точки Livy. Удалить сеанс, который был запущен самим ядром, невозможно. cleanup %%cleanup -fУдаляет все сеансы для текущей конечной точки Livy, включая сеанс этой записной книжки. Флаг -f является обязательным. Примечание.
Помимо магических команд, добавленных ядром PySpark, можно также использовать встроенные магические команды IPython, в том числе
%%sh. Можно использовать магическую команду%%shдля выполнения сценариев и блоков кода на головном узле кластера.Автоматическая визуализация. Ядро Pyspark автоматически визуализирует выходные данные запросов Hive и SQL. Вы можете выбрать различные типы средства визуализации, включая таблицы, круговые диаграммы, графики, диаграммы с областями и линейчатые диаграммы.
Параметры, поддерживаемые волшебной командой %%sql
Магическая команда %%sql поддерживает различные параметры, позволяющие управлять результатом выполнения запросов. Возможные результаты показаны в следующей таблице.
| Параметр | Пример | Description |
|---|---|---|
| o- | -o <VARIABLE NAME> |
При использовании этого параметра результат запроса сохраняется в контексте Python %%local в качестве таблицы данных Pandas . Именем переменной таблицы данных служит указанное вами имя переменной. |
| -q | -q |
Этот параметр позволяет отключить визуализации для ячейки. Если вам не нужна автоматическая визуализация содержимого ячейки и вы хотите только записать ее как таблицу данных, используйте параметр -q -o <VARIABLE>. Если вы хотите отключить визуализацию, не записывая результаты (например, для выполнения запроса SQL, такого как инструкция CREATE TABLE), то используйте параметр -q без аргумента -o. |
| -m | -m <METHOD> |
Параметр METHOD имеет значение take или sample (по умолчанию используется значение take). Если используется метод take, то ядро выбирает элементы из верхней части результирующего набора данных, который определяется параметром MAXROWS (описывается далее в этой таблице). Если используется метод sample, то ядро выбирает элементы из набора данных случайным образом в соответствии с параметром -r, описанным далее в этой таблице. |
| -r | -r <FRACTION> |
Здесь FRACTION — это число с плавающей запятой от 0,0 до 1,0. Если для SQL-запроса используется метод выборки sample, то ядро выбирает заданную долю элементов из результирующего набора случайным образом. Например, при выполнении SQL-запроса с аргументами -m sample -r 0.01 из результирующего набора данных случайным образом отбирается 1 % строк. |
| -n | -n <MAXROWS> |
MAXROWS должно быть выражено целым числом. Число выходных строк для параметра MAXROWS ограничивается ядром. Если значение параметра MAXROWS выражено отрицательным числом, например -1, то число строк в результирующем наборе не ограничивается. |
Пример:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
Приведенная выше инструкция выполняет следующие действия.
- Выбирает все записи из таблицы hivesampletable.
- Отключает автоматическую визуализацию, так как используется параметр -q.
- Случайным образом выбирает 10 % строк из таблицы hivesampletable и ограничивает размер результирующего набора 500 строками, так как используется параметр
-m sample -r 0.1 -n 500. - И наконец, сохраняет выходные данные в таблицу данных query2, так как включает параметр
-o query2.
Рекомендации по использованию новых ядер
Какое бы ядро вы ни использовали, работающие объекты Notebook потребляют ресурсы кластера. При использовании этих ядер (так как контексты заданы предварительно) в случае простого выхода из записных книжек контекст не завершается. Таким образом, ресурсы кластера продолжают использоваться. После завершения работы с записной книжкой рекомендуется выбрать Close and Halt (Закрыть и остановить) в меню File (Файл) записной книжки. Это действие аннулирует контекст и закроет записную книжку.
Где хранятся записные книжки?
Если кластер использует службу хранилища Azure в качестве учетной записи хранения по умолчанию, объекты Jupyter Notebook сохраняются в папке /HdiNotebooks в учетной записи хранения. Доступ к объектам Notebook, текстовым файлам и папкам, создаваемым в Jupyter, можно получить через учетную запись хранения. Например, если Jupyter используется для создания папки myfolder и записной книжки myfolder/mynotebook.ipynb, то доступ к этой записной книжке можно получить в расположении /HdiNotebooks/myfolder/mynotebook.ipynb в учетной записи хранения. Верно и обратное: если вы передаете объект Notebook непосредственно в свою учетную запись хранения в /HdiNotebooks/mynotebook1.ipynb, то этот объект также отображается в Jupyter. Объекты Notebook хранятся в учетной записи хранения даже после удаления кластера.
Примечание.
Для кластеров HDInsight, использующих Azure Data Lake Storage в качестве хранилища по умолчанию, записные книжки не сохраняются в связанном хранилище.
Записные книжки сохраняются в учетной записи хранения, совместимой с Apache Hadoop HDFS. Подключаясь к кластеру по SSH, вы можете использовать команды управления файлами:
| Команда | Description |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Включить в список все элементы корневого каталога: все элементы в этом каталоге доступны Jupyter на домашней странице. |
hdfs dfs –copyToLocal /HdiNotebooks |
# Скачать содержимое папки HdiNotebooks. |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Загрузить записную книжку example.ipynb в корневую папку, чтобы она была видна из Jupyter. |
Вне зависимости от того, использует ли кластер в качестве учетной записи хранения по умолчанию службу хранилища Azure или Azure Data Lake Storage, записные книжки также сохраняются на головном узле кластера в /var/lib/jupyter.
Поддерживаемый браузер
Объекты Jupyter Notebook, выполняемые в кластерах HDInsight Spark, поддерживаются только браузером Google Chrome.
Предложения
Новые ядра находятся в стадии развития и будут улучшаться со временем. Таким образом, по мере развития этих ядер API могут измениться. Мы будем признательны вам за любые отзывы о работе с новыми ядрами. Отзывы помогут нам оформить финальную версию этих ядер. Комментарии и отзывы оставляйте в разделе Отзывы под данной статьей.
Следующие шаги
- Обзор: Apache Spark в Azure HDInsight
- Использование записных книжек Zeppelin с кластером Apache Spark в Azure HDInsight
- Использование внешних пакетов с Jupyter Notebook
- Установка записной книжки Jupyter на компьютере и ее подключение к кластеру Apache Spark в Azure HDInsight (предварительная версия)