Настройка параметров Apache Spark
Кластер HDInsight Spark включает в себя установку библиотеки Apache Spark. Каждый кластер HDInsight содержит параметры конфигурации по умолчанию для всех установленных служб, в том числе для Spark. Ключевым аспектом управления кластером Apache HDInsight Hadoop является мониторинг рабочей нагрузки, включая задания Spark. Чтобы добиться оптимального выполнения заданий Spark, при определении логической конфигурации кластера рассмотрите его физическую конфигурацию.
По умолчанию кластер HDInsight Apache Spark содержит следующие узлы: три узла Apache ZooKeeper, два головных узла и один или несколько рабочих узлов:
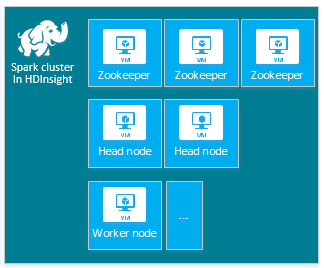
Также на конфигурацию Spark могу влиять количество и размеры виртуальных машин для узлов кластера HDInsight. Нестандартные значения конфигурации HDInsight часто требуют нестандартных значений конфигурации Spark. При создании кластера HDInsight Spark отображаются предлагаемые размеры виртуальной машины для каждого из компонентов. Сейчас размерами виртуальных машин Azure с Linux, оптимизированными для памяти, являются экземпляры D12 версии 2 или выше.
Версии Apache Spark
Используйте наиболее подходящую версию Spark для кластера. Служба HDInsight включает в себя несколько версий Spark и HDInsight. Каждая версия Spark содержит набор стандартных параметров кластера.
Ниже приведены разные версии Spark. Вы можете выбрать одну из них для создания кластера. См. полный список версий и компонентов HDInsight.
Примечание.
Версия по умолчанию Apache Spark в службе HDInsight может измениться без предварительного уведомления. Если используется зависимость версии, корпорация Майкрософт рекомендует указать конкретную версию при создании кластеров с использованием пакета SDK для .NET, Azure PowerShell и классического Azure CLI.
В Apache Spark системная конфигурация находится в трех расположениях.
- Свойства Spark управляют большинством параметров приложения. Их можно установить с помощью объекта
SparkConfили свойств системы Java. - Переменные среды можно использовать для установки параметров (например, IP-адреса) отдельного компьютера на каждом узле с помощью скрипта
conf/spark-env.sh. - Ведение журнала можно настроить с помощью
log4j.properties.
Кластер Spark любой версии содержит параметры конфигурации по умолчанию. Вы можете изменить их, используя настраиваемый файл конфигурации Spark. Ниже приведен соответствующий пример.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
В примере выше переопределяется несколько значений по умолчанию для пяти параметров конфигурации Spark. Это кодеки сжатия, минимальный размер разделения заданий MapReduce в Apache Hadoop и размеры блоков Parquet, а также раздел Spark SQL и значения по умолчанию для размеров открытых файлов. Мы выбрали эти изменения конфигурации, так как используемые данные и задания (в этом примере геномные данные) имеют определенные характеристики, для которых лучше подходят эти специальные параметры конфигурации.
Просмотр параметров конфигурации кластера
Прежде чем выполнять оптимизацию производительности кластера, проверьте текущие параметры конфигурации кластера HDInsight. Запустите панель мониторинга HDInsight на портале Azure, щелкнув ссылку Панель мониторинга в области кластера Spark. Войдите с помощью имени и пароля администратора кластера.
Отобразится веб-интерфейс Apache Ambari с панелью мониторинга ключевых метрик потребления ресурсов кластера. На панели мониторинга Ambari отображается конфигурация Apache Spark и другие установленные службы. Также на ней есть вкладка Журнал конфигурации, содержащая сведения о конфигурации всех установленных служб, включая Spark.
Чтобы просмотреть значения конфигурации для Apache Spark, выберите Config History (История конфигураций), а затем — Spark2. Перейдите на вкладку Configs (Конфигурации), а затем в списке служб щелкните ссылку Spark (или Spark2 в зависимости от вашей версии). Отобразится список значений конфигурации для вашего кластера:

Чтобы просмотреть и изменить отдельные значения конфигурации Spark, щелкните ссылку со словом "spark" в названии. Конфигурации для Spark содержат как пользовательские, так и расширенные значения конфигурации в следующих категориях:
- Custom Spark2-defaults;
- Custom Spark2-metrics-properties;
- Advanced Spark2-defaults;
- Advanced Spark2-env;
- Advanced spark2-hive-site-override;
При создании набора нестандартных значений конфигурации отображается журнал обновлений. В истории конфигурации можно увидеть, какая нестандартная конфигурация имеет оптимальную производительность.
Примечание.
Чтобы увидеть (но не изменять) общие параметры конфигурации кластера Spark, выберите вкладку Environment (Среда) в интерфейсе верхнего уровня Spark Job UI (Пользовательский интерфейс задания Spark).
Настройка исполнителей Spark
На следующей схеме показаны ключевые объекты Spark. К ним относятся программа драйвера и связанный с ней контекст Spark, а также диспетчер кластера и его рабочие узлы n. Каждый рабочий узел включает в себя исполнитель, кэш и экземпляры задач n.

Задания Spark используют рабочие ресурсы, в частности память, поэтому для исполнителей рабочего узла необходимо настроить значения конфигурации Spark.
Существует три ключевых параметра — spark.executor.instances, spark.executor.cores и spark.executor.memory. Их часто изменяют, чтобы настроить конфигурации Spark в соответствии с требованиями приложения. Исполнитель — это процесс, запущенный для приложения Spark. Он выполняется на рабочем узле и отвечает за выполнение задач этого приложения. Количество рабочих узлов и размер рабочего узла определяют количество исполнителей и их размер. Эти значения хранятся в файле spark-defaults.conf в головных узлах кластера. Вы можете отредактировать эти значения в работающем кластере, выбрав ссылку Настраиваемые значения Spark по умолчанию в пользовательском интерфейсе Ambari. После внесения изменений пользовательский интерфейс запрашивает перезапуск всех затронутых служб.
Примечание.
Эти три параметра конфигурации можно настроить на уровне кластера (для всех приложений, работающих в кластере) или для каждого отдельного приложения.
Также о ресурсах, используемых исполнителями Spark, можно узнать из пользовательского интерфейса приложения Spark. В пользовательском интерфейсе на экране Исполнители отображаются сводные и подробные данные о конфигурации и потребляемых ресурсах. Определите, нужно ли изменить значения исполнителей для всего кластера или только для определенного набора заданий.
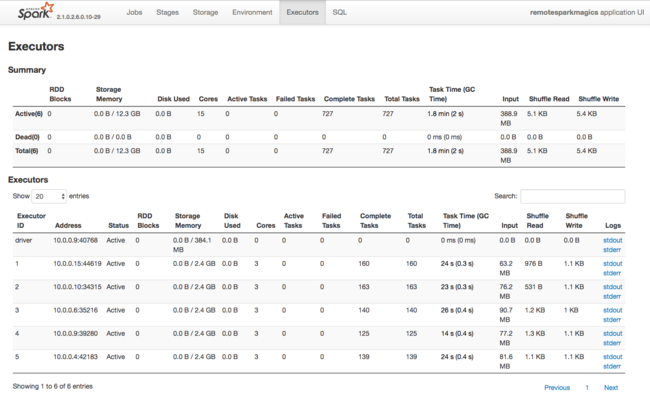
Или можно использовать REST API Ambari для проверки параметров конфигурации кластера HDInsight и Spark программным способом. Дополнительные сведения см. в справочнике по API Apache Ambari на сайте GitHub.
В зависимости от рабочей нагрузки Spark может выясниться, что нестандартная конфигурация Spark оптимизирует выполнение задания. Выполните тестирование производительности с примерами рабочих нагрузок, чтобы проверить все нестандартные конфигурации кластера. Можно настроить такие общие параметры:
| Параметр | Описание |
|---|---|
| --num-executors | Задает количество исполнителей. |
| --executor-cores | Задает количество ядер для каждого исполнителя. Мы советуем выбирать исполнителей среднего размера, так как некоторые процессы используют доступную память. |
| --executor-memory | Управляет размером памяти (размером кучи) каждого исполнителя в Apache Hadoop YARN. Вам нужно оставить определенный объем памяти для выполнения служебных программ. |
Ниже приведен пример двух рабочих узлов с разными значениями конфигурации.

Ниже приведен список ключевых параметров памяти исполнителя Spark.
| Параметр | Описание |
|---|---|
| spark.executor.memory. | Определяет общий объем памяти, доступный для исполнителя. |
| spark.storage.memoryFraction | (по умолчанию ~ 60 %) определяет объем памяти, доступный для хранения сохраненных удаленных удаленных рабочих машин. |
| spark.shuffle.memoryFraction | (по умолчанию ~ 20%) определяет объем памяти, зарезервированный для перетасовки. |
| spark.storage.unrollFraction и spark.storage.safetyFraction | (примерно 30 % от общей памяти). Эти значения используются внутри Spark и не должны меняться. |
YARN управляет максимальным объемом памяти, используемой контейнерами на всех узлах Spark. На следующей схеме показаны отношения между объектами конфигурации YARN и Spark для каждого узла.

Изменение параметров для приложения, запущенного в записной книжке Jupyter Notebook
Кластеры Spark в HDInsight включают в себя несколько компонентов по умолчанию. Каждый из этих компонентов содержит значения конфигурации по умолчанию, которые можно переопределить при необходимости.
| Компонент | Description |
|---|---|
| Ядро Spark | Spark Core, Spark SQL, API потоковой передачи Spark, GraphX и Apache Spark MLlib. |
| Anaconda | Диспетчер пакетов Python. |
| Apache Livy | Удаленная отправка заданий Spark в кластер Azure HDInsight с помощью Apache Spark REST API. |
| Записные книжки Jupyter Notebook и Apache Zeppelin | Интерактивный браузерный интерфейс для взаимодействия с кластером Spark. |
| Драйвер ODBC | Соединяет кластеры Spark в HDInsight со средствами бизнес-аналитики, такими как Microsoft Power BI и Tableau. |
Чтобы изменить конфигурацию для приложений, запущенных в записной книжке Jupyter Notebook, можно использовать команду %%configure. Эти изменения конфигурации будут применены к заданиям Spark, запущенным из экземпляра записной книжки. Такие изменения вносятся на раннем этапе выполнения приложения, перед запуском первой ячейки кода. Измененная конфигурация будет применена к сеансу Livy, когда он будет создан.
Примечание.
Чтобы изменить конфигурацию на более позднем этапе выполнения приложения, используйте параметр -f (принудительное выполнение). Но при этом будут потеряны все результаты, полученные в приложении.
В приведенном ниже примере кода показано, как изменить конфигурацию для приложения, работающего в Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Заключение
Отслеживайте основные параметры конфигурации, чтобы задания Spark выполнялись прогнозируемым и эффективным образом. Эти параметры помогают определить лучшую конфигурацию кластера Spark для конкретных рабочих нагрузок. Вам также необходимо следить за выполнением длительных или ресурсоемких выполнений заданий Spark. Чаще все проблемы связаны с нехваткой памяти из-за неправильных конфигураций, например, из-за исполнителей неподходящего размера. Кроме того, долго выполняемые операции и задачи могут приводить к декартовым операциям.