За последние несколько лет страховщики и компании, предоставляющие страховые продукты, установили несколько новых правил. Эти новые правила потребовали более масштабного финансового моделирования для страховщиков. Европейский союз принял Решение II. Этот закон требует страховщиков продемонстрировать, что они сделали свой правильный анализ, чтобы проверить, что страховщик будет платежеспособным в конце года. Страховщики, которые предоставляют переменные аннуитеты, должны следовать Actuarial Guideline XLIII с подробным анализом активов и пассивов денежных потоков. К 2021 году всем типам страховщиков, включая тех, кто распределяет страховые продукты, придется реализовать международный стандарт финансовых отчетов 17 (IFRS 17) к 2021 году. (IFRS обозначает международные стандарты отчетности о финансировании.) Существуют другие правила, в зависимости от юрисдикций, в которых работают страховщики. Эти стандарты и правила требуют, чтобы актуарии использовали методы интенсивного вычисления при моделировании активов и пассивов. Большая часть анализа будет использовать стохастически сгенерированные данные сценария через последовательно введенные входные данные, например, активы и пассивы. Помимо нормативных потребностей, актуарии делают справедливое количество финансового моделирования и вычислений. Они создают входные таблицы для моделей, создающих нормативные отчеты. Внутренние сетки не удовлетворяют вычислительным потребностям, поэтому актуарии постоянно перемещаются в облако.
Актуарии перемещаются в облако, чтобы получить больше времени для проверки, оценки и подтверждения результатов. Когда регулирующие органы проверяют страховщиков, результаты актуариев должны быть понятны. Переход в облако дает им доступ к вычислительным ресурсам для запуска 20 000 часов анализа в 24–120 часов времени с помощью возможности параллелизации. Для облегчения этой потребности масштабирования многие компании, которые создают страховое программное обеспечение, предоставляют решения, позволяющие выполнять вычисления в Azure. Некоторые из этих решений основаны на технологиях, работающих локально и в Azure, таких как высокопроизводительные вычислительные решения PowerShell, пакет HPC. Другие решения предназначены для Azure и используют пакетная служба Azure, Масштабируемые наборы виртуальных машин или пользовательское решение масштабирования.
В этой статье мы рассмотрим, как актуариальные разработчики могут использовать Azure, в сочетании с пакетами моделирования, для анализа риска. В этой статье описываются некоторые технологии Azure, используемые пакетами моделирования для масштабирования в Azure. Ту же технологию можно использовать для выполнения дальнейшего анализа данных. Рассмотрим следующие элементы:
- запуск в Azure более крупных моделей за меньшее время;
- отчеты о результатах;
- управление хранением данных.
Независимо от того, являетесь ли вы службой жизни, имуществом и жертвой, здоровьем или другим страхованием, необходимо создать финансовые и рискованные модели ваших активов и обязательств. Затем вы можете настроить свои инвестиции и премии, чтобы вы оставались платежеспособными в качестве страховщика. Отчеты IFRS 17 добавляют изменения в модели, создаваемые актуариями, например вычисление маржи договорной службы (CSM), что изменяет способ управления их прибылью страховщиками по времени.
Запуск в Azure более крупных моделей за меньшее время
Доверьтесь возможностям облака: оно может быстрее и проще управлять вашими моделями финансового риска. Для многих страховщиков примерные расчеты становятся проблемой: им нужны годы или даже десятилетия последовательного времени для запуска этих вычислений от начала до конца. Вам нужны технологии для решения проблемы среды выполнения. Давайте рассмотрим эти стратегии.
- Подготовка данных. Некоторые данные изменяются редко. Как только контракт политики или службы подействует, утверждения будут перемещаться в прогнозируемом темпе. Вы можете подготовить данные, необходимые для выполнения модели, по мере их поступления, устраняя необходимость планирования много времени для очистки и подготовки данных. Вы также можете использовать кластеризацию, чтобы создать резервные копии для последовательно введенных данных через взвешенные представления. Меньше записей обычно приводят к сокращению времени вычисления.
- Параллелизация. Если вам нужно сделать один и тот же анализ для двух или более элементов, можно выполнить анализ одновременно.
Давайте рассмотрим эти элементы по отдельности.
Подготовка данных
Данные поступают из различных источников. У вас есть частично структурированные данные политики в книгах бизнеса. Кроме того, у вас есть информация о застрахованных людях, компаниях и элементах, которые отображаются в различных формах приложений. Генераторы экономических сценариев (ESG) создают данные в различных форматах, которые могут потребовать перевода в форму, которую может использовать ваша модель. Текущие данные о стоимости активов также нуждаются в нормализации. Данные фондового рынка, данные денежного потока по аренде, платежная информация об ипотеке и другие данные активов нуждаются в некоторой подготовке при переходе от источника к модели. Наконец, необходимо обновить любые предположения, основанные на последних данных о взаимодействии. Для ускорения выполнения модели подготовьте данные заранее. Во время выполнения все необходимые обновления для добавления изменений с момента последнего запланированного обновления.
Так как подготовить данные? Давайте сначала рассмотрим общие биты, а затем посмотрим, как работать с разными способами отображения данных. Во-первых, вам нужен механизм для получения всех изменений со времени последней синхронизации. Этот механизм должен включать значение, которое можно сортировать. Для последних изменений это значение должно быть больше, чем любое предыдущее изменение. Двумя наиболее распространенными механизмами являются постоянно увеличивающееся поле идентификатора или метка времени. Если запись имеет растущий ключ идентификатора, но остальная часть записи содержит поля, которые можно обновить, то для поиска изменений необходимо использовать что-то подобное метку времени последнего изменения. После обработки записей запишите сортируемое значение последнего обновленного элемента. Это значение, вероятно, метка времени в поле с именем lastModified, становится вашим водяным знаком, используемым для последующих запросов в хранилище данных. Изменения данных могут обрабатываться разными способами. Ниже приведены два распространенных механизма, которые используют минимальные ресурсы:
- Если в процессе есть сотни или тысячи изменений, отправьте данные в хранилище BLOB-объектов. Используйте триггер события в Фабрике данных Azure для обработки набора изменений.
- Если в процессе есть небольшие наборы изменений или вы хотите обновить данные сразу после изменения, поместите каждое изменение в сообщение очереди, размещенное служебная шина или служба хранилища очередях. Эта статья содержит большое объяснение компромиссов между двумя технологиями очередей. Когда сообщение находится в очереди, можно использовать триггер в Функциях Azure или фабрике данных Azure для обработки сообщения.
На следующем рисунке показан типичный сценарий. Во-первых, запланированное задание собирает некоторый набор данных и помещает файл в хранилище. Запланированным заданием может быть задание CRON, выполняемое в локальной среде, Задача планировщика, Приложение логики или все, что работает по таймеру. После загрузки файла может быть запущен экземпляр Функций Azure или Фабрика данных для обработки данных. Если файл можно обработать за короткий период времени, используйте Функцию. Если обработка сложная, требует AI или другого сложного сценария, вы можете обнаружить, что HDInsight, Azure Databricks или что-то другое работает лучше. По завершении файл закроется в удобной форме в виде нового файла или в виде записей в базе данных.
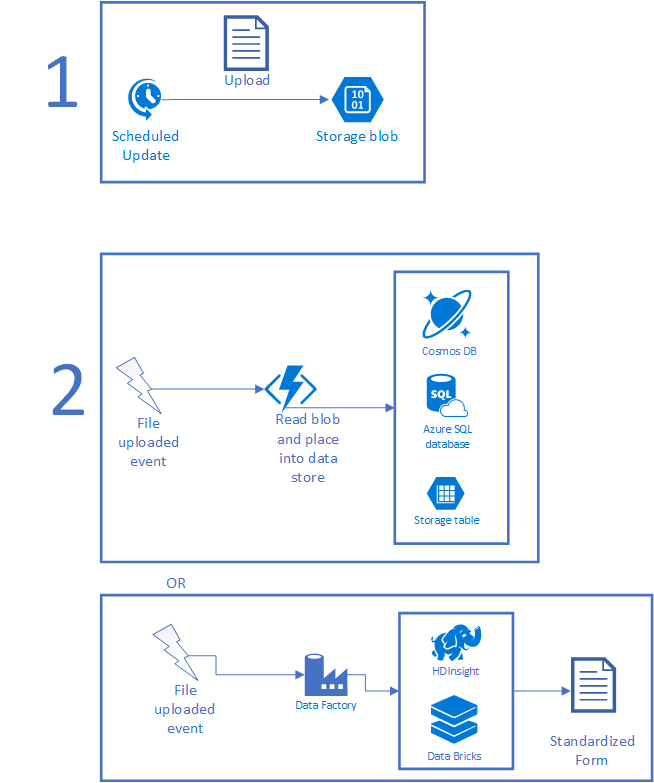
После передачи данных в Azure необходимо сделать их доступными для использования приложением моделирования. Вы можете написать код для выполнения пользовательских преобразований, запустить элементы через HDInsight или Azure Databricks, чтобы получать более крупные элементы или скопировать данные в нужные наборы данных. Использование средств больших данных также помогает выполнять такие действия, как преобразование неструктурированных данных в структурированные данные, а также выполнение любых ИИ и машинного обучения по полученным данным. Вы также можете размещать виртуальные машины, отправлять данные прямо к источникам данных из локальной среды, напрямую вызывать Функции Azure и т. д.
Позже данные должны потребляться вашими моделями. То, как вы это делаете, во многом зависит от доступа вычислений к данным. В некоторых системах моделирования все файлы данных должны находиться на узле, который выполняет вычисления. Другие могут использовать базы данных, такие как База данных SQL Azure, MySQL или PostgreSQL. Можно использовать недорогую версию любого из этих элементов, а затем увеличить масштаб производительности во время выполнения моделирования. Это дает вам цену, необходимую для повседневной работы. Кроме того, это обеспечивает дополнительную скорость, когда тысячи ядер запрашивают данные. Как правило, эти данные будут доступны только для чтения во время выполнения моделирования. Если вычисления выполняются в нескольких регионах, рассмотрите возможность использования Azure Cosmos DB или гео-реплика azure SQL. Оба механизма обеспечивают автоматическую репликацию данных по регионам с низкой задержкой. Выбор зависит от средств, которые разработчики знают, как вы моделировали данные и количество регионов, используемых для выполнения моделирования.
Потратьте некоторое время на размышления о том, где хранить данные. Поймите, сколько одновременных запросов на одни и те же данные будут существовать. Подумайте о том, как распределить информацию:
- Получает ли каждый вычислительный узел собственную копию?
- Скопирована ли копия через некоторое место с высокой пропускной способностью?
Если вы храните данные централизованно с помощью SQL Azure, скорее всего, вы будете хранить базу данных на более низкой цене большую часть времени. Если данные используются только во время выполнения моделирования и не обновляются очень часто, клиенты Azure будут выполнять резервное копирование данных и отключать их экземпляры базы данных между выполнением. Возможная экономия достаточно большая. Клиенты также могут использовать Эластичные пулы SQL Azure. Они предназначены для управления затратами на базу данных, особенно если вы не знаете, какие базы данных будут находиться под большой нагрузкой в разное время. Эластичные пулы позволяют коллекции баз данных использовать столько энергии, сколько им нужно, а затем выполнить обратное масштабирование после переноса запроса в другие места системы.
Возможно, вам придется отключить синхронизацию данных во время выполнения моделирования, чтобы вычисления, полученные в ходе этого процесса, использовали одни и те же данные. Если вы используете очередь, отключите обработчики сообщений, но разрешите очереди получать данные.
Вы также можете использовать время до запуска для генерации экономических сценариев, обновления актуарных предположений и, как правило, обновления других статических данных. Давайте рассмотрим создание экономического сценария (ESG). Общество актуариев предоставляет генератор процентных ставок Академии (AIRG), ESG, который моделирует доходность казначейства США. AIRG назначается для использования в таких элементах, как вычисления оценки 20 (VM-20). Другие ESG могут моделировать фондовый рынок, ипотечные кредиты, цены на сырьевые товары и т. д.
Так как среда предварительно обрабатывает данные, вы также можете запустить другие части. Например, у вас могут быть вещи, которые используют записи для представления большего числа населения. Обычно это происходит путем кластеризации записей. Если набор данных обновляется нерегулярно, например, один раз в день, можно уменьшить набор записей, который будет использоваться в модели как часть процесса приема.
Давайте рассмотрим практический пример. При использовании IFRS-17 необходимо объединить контракты таким образом, чтобы максимальное расстояние между датами начала для любых двух контрактов было меньше одного года. Предположим, что вы делаете это простым способом и используете контрактный год в качестве механизма группировки. Эту сегментацию можно выполнить, когда данные загружаются в Azure, просматривая файл и перемещая записи в соответствующие группы года.
Сосредоточение внимания на подготовке данных сокращает время, необходимое для запуска компонентов модели. Получив данные на раннем этапе, вы можете сэкономить время для выполнения ваших моделей.
Параллелизация
Правильная параллелизация шагов может значительно сократить время выполнения. Это ускорение происходит за счет оптимизации фрагментов, которые вы реализуете, и знаний, как выразить свою модель таким образом, чтобы одновременно запускать два или больше действий. Хитрость заключается в том, чтобы найти баланс между размером рабочего запроса и производительностью отдельного узла. Если задача тратит больше времени на настройку и очистку, чем на оценку, вы сделали что-то не так. Если задача слишком велика, время выполнения не улучшается. Требуется, чтобы действие было достаточно небольшим для распространения по нескольким узлам и положительной разницы в затраченном времени выполнения.
Чтобы получить большую часть системы, необходимо понять рабочий процесс для модели и как вычисления взаимодействуют с возможностью горизонтального масштабирования. Ваше программное обеспечение может иметь представление о заданиях, задачах или что-то подобное. Используйте эти знания для разработки чего-то, что может разделить работу. Если у вас есть некоторые настраиваемые действия в вашей модели, спроектируйте те, которые позволят разделить входные данные на небольшие группы для обработки. Эта конструкция часто называется шаблоном точечной сборки.
- Точечная: разделение входных данных по естественным линиям и разрешение выполнения отдельных задач.
- Сбор: по завершении задач соберите их выходные данные.
При разделении вещей также помните, где процесс должен синхронизироваться перед продолжением. Есть несколько распространенных мест, где люди разделяют вещи. Для вложенных стохастических выполнений у вас может быть тысяча внешних циклов с набором точек перегиба, которые запускают внутренние цикли из ста сценариев. Каждый внешний цикл может выполняться одновременно. Вы останавливаетесь в точке перегиба, затем выполняете внутренние цикли одновременно, возвращаете информацию, чтобы отрегулировать данные для внешнего цикла, и переходите далее. На следующем рисунке показан рабочий процесс. При достаточном объеме вычислений вы можете запустить 100 000 внутренних циклов на 100 000 ядер, доведя время обработки до суммы следующих случаев.

Распределение будет увеличиваться немного в зависимости от того, как это делается. Это может быть так же просто, как создание небольшого задания с правильными параметрами или как сложное копирование файлов 100K в нужные места. Результаты обработки можно даже скругировать, если можно распространить агрегирование результатов с помощью Apache Spark из Azure HDInsight, Azure Databricks или собственного развертывания. Например, вычисления средних значений — это просто вопрос запоминания количества элементов, которые были просмотрены до сих пор, и суммы. Другие вычисления могут работать лучше на одной машине с тысячью ядер. Для них можно использовать компьютеры с поддержкой GPU в Azure.
Большинство актуарных команд начинают действовать с перемещения своих моделей в Azure. Затем они собирают данные о времени для различных шагов в процессе. Затем они сортируют время часов для каждого шага от самого длинного до самого короткого истекшего времени. Они не будут смотреть на общее время выполнения, так как что-то может потреблять тысячи основных часов, но только 20 минут истекло время. Для каждого из самых длительных шагов задания актуариальные разработчики ищут способы уменьшения истекшего времени при получении правильных результатов. Этот процесс повторяется регулярно. Некоторые актуарные команды установят целевое время выполнения, скажем, анализ хеджирования за одну ночь, и цель будет достигнута менее чем за 8 часов. Как только время достигнет 8,25 часа, часть актуарной команды переключится, чтобы сократить время самого длинного фрагмента в анализе. Как только они вернут время на менее 7,5 часов, они переключатся в разработку. Эвристика для возвращения и оптимизации зависит от актуариев.
Чтобы запустить все это, у вас есть несколько вариантов. Большинство актуарных программ работает с сетками вычислений. Сетки, работающие в локальной среде и в Azure, используют пакет HPC, пакет партнера или что-то пользовательское. Сетки, оптимизированные для Azure, будут использовать Масштабируемые наборы виртуальных машин, Пакетную службу или что-то другое. Если вы решили использовать масштабируемые наборы или пакетную службу, убедитесь, что их поддержка поддерживает виртуальные машины с низким приоритетом (виртуальные машины) (документы с низким приоритетом масштабируемых наборов, документы с низким приоритетом пакетной службы). Виртуальная машина с низким приоритетом — это виртуальная машина, запущенная на оборудовании, которое можно арендовать на долю обычной цены. Более низкая цена доступна, поскольку низкоприоритетные виртуальные машины могут быть замещены, когда этого требует емкость. Если у вас есть некоторая гибкость в бюджете времени, виртуальные машины с низким приоритетом предоставляют отличный способ снизить цену выполнения моделирования.
Если вам нужно координировать выполнение и развертывание на многих компьютерах, возможно, с некоторыми компьютерами, работающими в разных регионах, вы можете воспользоваться преимуществами CycleCloud. Сервер CycleCloud бесплатный. Он координирует перемещение данных, когда это необходимо. Он включает в себя распределение, мониторинг и завершение работы машин. Он даже может обрабатывать низкоприоритетные машины, гарантируя, что расходы будут ограничены. Вы также можете описать типы необходимых машин. Например, может быть, вам нужен класс машины, но при этом можете хорошо работать на любой версии с 2 или более ядрами. Цикл может выделять ядра для этих типов машин.
Отчеты о результатах
После выполнения актуариальных пакетов и их результатов вы получите несколько готовых к регулированию отчетов. У вас также будет гора новых данных, которые могут потребоваться проанализировать для создания аналитических сведений, не необходимых регуляторам или аудиторам. Возможно, вы хотите понять профиль своих лучших клиентов. Используя полезные сведения, вы можете указать то, как выглядят недорогие клиенты, чтобы маркетинг и продажи могли быстрее их найти. Аналогичным образом можно использовать данные, чтобы узнать, какие группы больше всего выигрывают от страхования. Например, вы можете обнаружить, что люди, которые пользуются ежегодным медицинским обследованием, узнают о ранних проблемах со здоровьем раньше. Это сохраняет деньги и время страховой компании. Эти данные можно использовать для управления поведением в вашей клиентской базе.
Для этого вам потребуется доступ к большому набору средств обработки и анализа данных, а также к некоторым частям для визуализации. В зависимости от того, сколько исследований вы хотите сделать, вы можете начать с Виртуальной машины для обработки и анализа данных, которую можно подготовить к работе из Azure Marketplace. Эти виртуальные машины имеют как версии Windows, так и Linux. Установлено, вы найдете Microsoft R Open, Microsoft Машинное обучение Server, Anaconda, Jupyter и другие средства, готовые к работе. Добавьте R или Python, чтобы визуализировать данные и поделиться полезными сведениями со своими коллегами.
Если вам нужно выполнить углубленный анализ, можно использовать инструменты обработки и анализа данных Apache, такие как Spark, Hadoop и другие, используя либо HDInsight, либо Databricks. Используйте эти дополнительные возможности для анализа, который необходимо выполнять регулярно, и если вы хотите автоматизировать рабочий процесс. Они также полезны для динамического анализа больших наборов данных.
Когда вы нашли что-то интересное, вам нужно представить результаты. Многие актуарии начнут с извлечения результатов образца и подключения их в Excel для создания диаграмм, графиков и других визуализаций. Если вы хотите что-то, что также имеет хороший интерфейс для детализации данных, взгляните на Документацию Power BI. Power BI может сделать некоторые хорошие визуализации, отображать исходные данные и позволит объяснить данные читателю путем добавления упорядоченных и аннотированных закладок.
Хранение данных
Значительная часть данных, которые вы добавляете в систему, должна быть сохранена для будущих аудитов. Требования к хранению данных обычно находятся в диапазоне от 7 до 10 лет, но требования различаются. Минимальный период удержания включает следующие элементы.
- Моментальный снимок исходных входных данных модели. Сюда входят активы, пассивы, предположения, ESG и другие входные данные.
- Моментальный снимок конечных выходных данных. К ним относятся все данные, используемые для создания отчетов, представленных нормативным органам.
- Также важны промежуточные результаты. Аудитор спросит, почему ваша модель придумала некоторый результат. Необходимо сохранить свидетельство о причине, почему модель сделала определенные выборы или придумала конкретные цифры. Многие страховщики предпочтут сохранить двоичные файлы, используемые для получения конечных выходных данных с исходных входных данных. Затем, когда их спрашивают, они повторно запускают модель, чтобы получить обновленную копию промежуточных результатов. Если выходные данные совпадают, промежуточные файлы должны также содержать необходимые объяснения.
Во время выполнения модели актуарии используют механизмы доставки данных, которые могут обрабатывать нагрузку запросов от выполнения. После завершения выполнения данные больше не используются, они сохраняют некоторые данные. Как минимум, страховщик должен сохранять входные данные и конфигурацию среды выполнения для любых требований о воспроизводимости. Базы данных сохраняются для резервного копирования в хранилище BLOB-объектов Azure, а серверы завершат работу. Данные о хранении с высокой скоростью также перемещаются в хранилище BLOB-объектов Azure с более низкой стоимостью. В хранилище BLOB-объектов вы можете выбрать уровень данных, используемый для каждого BLOB: "горячий", "холодный" или "архивный". "Горячее" хранилище хорошо работает для часто используемых файлов. "Холодное" хранилище оптимизировано для нечастого доступа к данным. "Архивное" хранилище лучше всего подходит для хранения файлов для аудита, но экономия затрат происходит за счет задержки: задержка в архивных уровнях данных измеряется в часах. Дополнительные сведения об уровнях доступности см. в статье Хранилище BLOB-объектов Azure: горячий, холодный, архивный уровни хранилища и уровень "Премиум" (предварительная версия). Вы можете управлять данными от создания до удаления с помощью управления жизненным циклом. Коды URI для BLOB-объектов остаются статическими, но место, где сохраняется объект, со временем становится все дешевле. Эта функция сэкономит много денег и предотвратит головные боли многих пользователей службы хранилища Azure. Дополнительные сведения о входных и выходных данных см. в статье Управление жизненным циклом хранилища BLOB-объектов Azure (предварительная версия). Тот факт, что вы можете автоматически удалять файлы: это означает, что вы не случайно развернете аудит, ссылаясь на файл, который не область, так как сам файл можно удалить автоматически.
Рекомендации
Если у выполняемой актуариальной системы есть локальная реализация сетки, реализация сетки, скорее всего, будет выполняться в Azure. Некоторые поставщики имеют специализированные реализации Azure, которые выполняются на гипермасштабировании. В рамках перехода в Azure также переместите внутренние средства. Актуарии в любом месте обнаруживают, что их навыки обработки и анализа данных хорошо работают на их ноутбуке или в большой среде. Попробуйте найти вещи, которые ваша команда уже делает: возможно, у вас есть что-то, что использует глубокое обучение, но для работы на одном GPU требуется несколько часов или дней. Попробуйте запустить ту же рабочую нагрузку на компьютере с четырьмя высокоуровневыми графическими процессорами и посмотреть время выполнения; коэффициенты хороши, вы увидите значительные скорости для вещей, которые у вас уже есть.
По мере усовершенствования убедитесь, что вы также создали некоторую синхронизацию данных для передачи данных моделирования. Запуск модели не может начаться до тех пор, пока данные не будут готовы. Это может быть связано с добавлением некоторых усилий для отправки измененных данных. Фактический подход зависит от размера данных. Обновление нескольких МБ, возможно, не является большим делом, но сокращение количества гигабайт отправляет скорость вещей много.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Автор субъекта:
- Скотт Силли | Архитектор программного обеспечения
Следующие шаги
- Разработчики R: Руководство. Параллельное моделирование на R с помощью пакетной службы Azure
- Извлечение, преобразование и загрузка с помощью Databricks: Руководство. Извлечение, преобразование и загрузка данных с помощью Azure Databricks
- Извлечение, преобразование и загрузка с помощью HDInsight: Руководство. Извлечение, преобразование и загрузка данных с помощью Apache Hive в Azure HDInsight
- Обработка и анализ данных виртуальных машин (Linux)
- Обработка и анализ данных виртуальных машин (Windows)