Что такое ответственный ИИ
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Ответственный искусственный интеллект (ответственный ИИ) — это подход, предполагающий разработку, оценку и развертывание систем ИИ с соблюдением принципов безопасности, надежности и этики. Системы ИИ сочетают в себе множество решений, созданных специалистами по разработке и развертыванию. Ответственный ИИ может заблаговременно направлять процессы принятия решений, чтобы получить более полезные и равно ценные для всех заинтересованных лиц результаты. Это проявляется на всех уровнях: от назначения системы до особенностей взаимодействия человека с ИИ. Это означает, что принятие решений по проектированию должно ориентироваться на потребности и цели людей и такие непреходящие ценности, как справедливость, надежность и прозрачность.
Корпорация Майкрософт разработала стандарт ответственного искусственного интеллекта. Это платформа для создания систем искусственного интеллекта в соответствии с шестью принципами: справедливость, надежность и защищенность, конфиденциальность и безопасность, инклюзивность, прозрачность и подотчетность. Для корпорации Майкрософт эти принципы являются краеугольным камнем ответственного и заслуживающего доверия подхода к использованию ИИ, особенно по мере все большего распространения интеллектуальных технологий в продуктах и услугах, которыми люди пользуются каждый день.
В этой статье показано, как средства поддержки Машинного обучения Azure позволяют разработчикам и специалистам по обработке и анализу данных внедрять и вводить в действие эти шесть принципов.
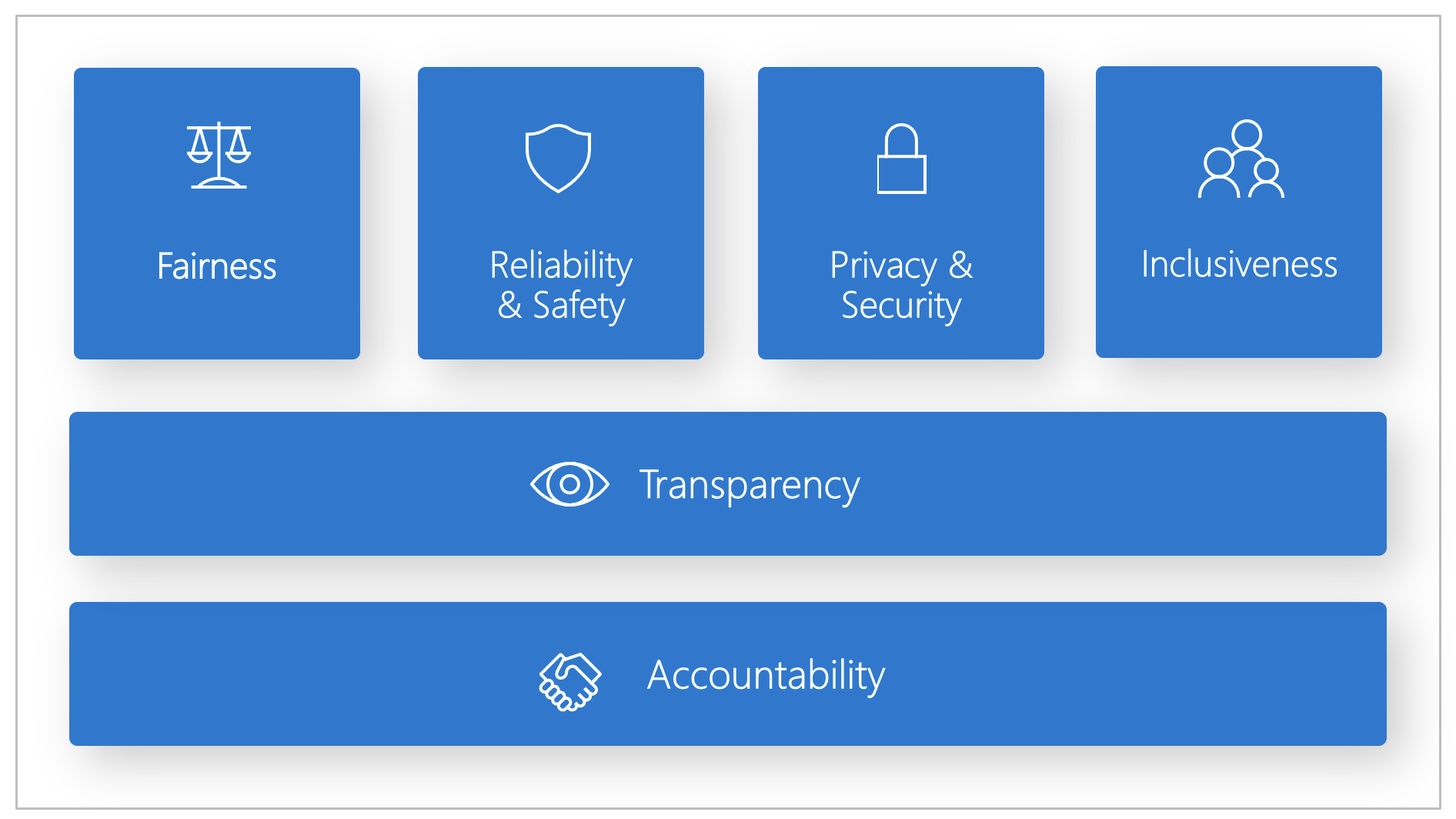
Справедливость и инклюзивность
Системы ИИ должны относиться ко всем справедливо и не воздействовать на схожие группы людей по-разному. Например, когда системы ИИ дают указания по лечению, трудоустройству, подаче заявок на получение кредитов, они должны давать одинаковые рекомендации всем людям со схожими симптомами, профессиональной квалификацией, финансовыми обстоятельствами.
Справедливость и инклюзивность в Машинном обучении Azure: компонент оценки справедливости на панели мониторинга ответственного применения ИИ позволяет специалистам по обработке и анализу данных и разработчикам оценивать справедливость модели между конфиденциальными группами, определенными с точки зрения пола, этнической принадлежности, возраста и других характеристик.
Надежность и защита
Для создания доверия критически важно, чтобы системы ИИ работали надежно, безопасно и согласованно. Эти системы должны функционировать так, как были изначально спроектированы, соблюдать безопасность при реагировании на непредвиденные обстоятельства и противостоять вредоносному манипулированию. Их поведение и различные условия, в которых они могут работать, отражают диапазон ситуаций и обстоятельств, прогнозируемых разработчиками во время проектирования и тестирования.
Надежность и безопасность в Машинном обучении Azure. Компонент анализа ошибокпанели мониторинга ответственного ИИ позволяет специалистам по обработке и анализу данных и разработчикам:
- получить глубокое представление о распределении сбоев для модели;
- определить когорты (подмножества) данных с более высокой частотой ошибок, чем определяет общий тест производительности.
Эти расхождения могут возникать, когда система или модель работает недостаточно эффективно для определенных демографических групп или для нечасто наблюдаемых условий в обучающих данных.
Transparency
Если системы ИИ помогают принимать обоснованные решения, оказывающих сильнейшее влияние на жизнь людей, крайне важно, чтобы люди понимали, как принимались эти решения. Например, банк может использовать систему ИИ для принятия решений о кредитоспособности клиента. Компания может использовать систему ИИ для определения наиболее квалифицированных кандидатов для найма.
Важнейшим элементом прозрачности является интерпретируемость, т. е. практически полезное объяснение поведения систем ИИ и их компонентов. Для улучшения интерпретируемости от заинтересованных лиц требуется понимать, как и почему системы ИИ работают именно так, как они работают. Затем заинтересованные лица могут выявлять потенциальные проблемы с производительностью, проблемы справедливости, методы исключения или непредвиденные результаты.
Прозрачность в Машинном обучении Azure. Компоненты Интерпретируемость модели и Противоречащие фактам предположения "что если" на панели мониторинга ответственного ИИ позволяют специалистам по обработке и анализу данных и разработчикам создавать понятные для человека описания прогнозов модели.
Компонент интерпретируемости модели предоставляет несколько представлений в поведении модели:
- Глобальные объяснения. Например, какие признаки влияют на общее поведение модели распределения кредита?
- Локальные объяснения. Например, почему заявление о кредите клиента утверждено или отклонено?
- Объяснения по модели для выбранной когорты или выбранных точек данных. Например, какие признаки влияют на общее поведение модели распределения кредита для лиц с низким доходом?
Компонент "Противоречащие фактам предположения "что если" позволяет проанализировать и отладить модель машинного обучения с точки зрения того, как она реагирует на изменение признаков и отклонения от нормы.
Машинное обучение Azure также поддерживает систему показателей ответственного ИИ. Эта система показателей представляет собой отчет в формате PDF, который разработчики могут легко настроить, создать, скачать и отправить заинтересованным лицам с технической или иной специализацией, чтобы рассказать им о работоспособности наборов данных и моделей, подтвердить соответствие требованиям и наладить доверительные отношения. Эту систему показателей также можно использовать при аудиторских проверках, чтобы сообщить заинтересованным лицам о характеристиках моделей машинного обучения.
Конфиденциальность и безопасность
По мере широкого распространения ИИ обеспечение конфиденциальности и защита личной и деловой информации становится все более важной и сложной задачей. С развитием ИИ вопросы конфиденциальности и безопасности данных требуют пристального внимания, поскольку системам ИИ доступ к данным необходим для точного и обоснованного прогнозирования и принятия решений, касающихся людей. Системы ИИ должны соответствовать законам о конфиденциальности, которые:
- требуют прозрачности сбора, использования и хранения данных;
- требуют, чтобы у потребителей имелись соответствующие средства, позволяющие контролировать выбор способа использования своих данных.
Конфиденциальность и безопасность в Машинном обучении Azure. Машинное обучение Azure позволяет администраторам и разработчикам создавать безопасную конфигурацию, соответствующую политикам их компаний. Машинное обучение Azure и платформа Azure предоставляют следующие возможности:
- ограничение доступа к ресурсам и операциям по учетным записям или группам пользователей;
- ограничение входящих и исходящих сетевых подключений;
- шифрование передаваемых и неактивных данных;
- проверка на уязвимости;
- применение политик конфигурации и их аудит.
Корпорация Майкрософт также создала два пакета с открытым кодом, которые могут обеспечить дальнейшую реализацию принципов конфиденциальности и безопасности:
SmartNoise: Дифференциальная конфиденциальность — это набор систем и рекомендаций, которые помогают обеспечить безопасность и конфиденциальность данных частных лиц. В решениях машинного обучения для обеспечения соответствия нормативным требованиям может потребоваться дифференциальная конфиденциальность. SmartNoise — это проект с открытым кодом (в разработке которого также участвует корпорация Майкрософт), содержащий компоненты для создания глобальных систем с дифференциальной конфиденциальностью.
Counterfit — это проект с открытым кодом, который включает в себя средство командной строки и универсальный уровень автоматизации, позволяющие разработчикам моделировать кибератаки на системы ИИ. Любой пользователь может скачать это средство и развернуть его с помощью Azure Cloud Shell для запуска в браузере или развернуть его локально в среде Python Anaconda. Это средство может оценивать модели ИИ, размещенные в различных облачных средах, локальной среде или в пограничной среде. Оно не зависит от моделей ИИ и поддерживает различные типы данных, включая текст, изображения и универсальные входные данные.
Отчетность
Специалисты, которые разрабатывают и развертывают системы ИИ, должны нести ответственность за их функционирование. При разработке норм подотчетности организациям следует опираться на отраслевые стандарты. Эти нормы могут гарантировать, что системы ИИ не являются окончательной инстанцией, принимающей любые решения, влияющие на жизнь людей. Они также могут гарантировать, что люди поддерживают осознанный контроль над системами ИИ с высокой степенью автономности.
Подотчетность в Машинном обучении Azure. Операции Машинного обучения (MLOps) основаны на принципах и методиках DevOps, которые повышают эффективность рабочих процессов ИИ. Машинное обучение Azure предоставляет следующие возможности MLOps для повышения подотчетности систем ИИ:
- Регистрация, создание пакетов и развертывание моделей из любого места. Также можно отслеживать связанные метаданные, необходимые для использования модели.
- Фиксация данных управления для комплексного жизненного цикла машинного обучения. Записанные в журнал данные о происхождении могут включать пользователей, которые публикуют модели, причины внесения изменений и время развертывания или использования моделей в рабочей среде.
- Уведомление и оповещение о событиях в жизненном цикле машинного обучения, Примеры включают выполнение эксперимента, регистрацию модели, развертывание модели и обнаружение смещения данных.
- Отслеживайте приложения на наличие операционных проблем и проблем, связанных с машинным обучением. Сравнивайте входные данные модели при обучении и выводе, изучайте метрики, зависящие от модели, и предоставляйте возможности мониторинга и оповещения в инфраструктуре машинного обучения.
Помимо возможностей MLOps система показателей ответственного ИИ в Машинном обучении Azure создает подотчетность, обеспечивая взаимодействие между заинтересованными лицами. Система показателей также создает подотчетность, давая разработчикам возможность настраивать и загружать свою аналитику работоспособности модели и предоставлять к ней совместный доступ для заинтересованных лиц технического и нетехнического профиля, делясь с ними сведениями о данных ИИ и работоспособности модели. Предоставление общего доступа к этим аналитическим сведениям может помочь в установлении доверия.
Платформа машинного обучения также позволяет принимать решения, информируя лиц, принимающих бизнес-решения, следующими способам:
- Аналитика на основе данных позволяет заинтересованным лицам понять причинно-обусловленные последствия обработки результатов, используя только исторические данные. Например, "Как лекарство повлияет на кровяное давление пациента?" Эти аналитические сведения предоставляются с помощью компонента причинного выводапанели мониторинга ответственного ИИ.
- Аналитика на основе модели позволяет ответить на вопросы пользователей, например, "Что можно сделать, чтобы в следующий раз получить другой результат от ИИ?", чтобы пользователи могли принять меры. Эти аналитические сведения предоставляются специалистам по обработке и анализу данных с помощью компонента Противоречащие фактам предположения "что если" на панели мониторинга ответственного применения ИИ.
Следующие шаги
- Дополнительные сведения о реализации принципов ответственного применения ИИ в Машинном обучении Azure см. в разделе Панель мониторинга ответственного применения ИИ.
- Узнайте, как создать панель мониторинга ответственного ИИ с помощью CLI и пакета SDK или пользовательского интерфейса Студии Машинного обучения Azure.
- Узнайте, как создать систему показателей ответственного ИИ на основе аналитических сведений, наблюдаемых на панели мониторинга ответственного ИИ.
- Узнайте о стандарте ответственного ИИ для создания систем ИИ в соответствии с шестью ключевыми принципами.