Доступ к данным из облачного хранилища Azure во время интерактивной разработки
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Пакет SDK для Python azure-ai-ml версии 2 (current)
Проект машинного обучения обычно начинается с анализа аналитических данных (EDA), предварительной обработки данных (очистка, проектирование признаков) и включает в себя создание прототипов моделей машинного обучения для проверки гипотез. Этот этап создания прототипов является очень интерактивным в природе, и он дает возможность разрабатывать в записной книжке Jupyter или интегрированной среде разработки с интерактивной консолью Python. Из этой статьи вы узнаете о следующем.
- Доступ к данным из URI хранилища данных Машинное обучение Azure, как будто это файловая система.
- Материализуйте данные в Pandas с помощью
mltableбиблиотеки Python. - Материализуйте ресурсы данных Машинное обучение Azure в Pandas с помощью
mltableбиблиотеки Python. - Материализуйте данные с помощью явной загрузки с помощью служебной
azcopyпрограммы.
Необходимые компоненты
- Рабочая область Машинного обучения Azure. Дополнительные сведения см. в статье "Управление рабочими областями Машинное обучение Azure на портале" или с помощью пакета SDK для Python версии 2.
- Хранилище данных Машинное обучение Azure. Дополнительные сведения см. в разделе "Создание хранилищ данных".
Совет
В этом руководстве описывается доступ к данным во время интерактивной разработки. Он применяется к любому узлу, который может запускать сеанс Python. Это может включать локальный компьютер, облачную виртуальную машину, пространство Кода GitHub и т. д. Рекомендуется использовать Машинное обучение Azure вычислительный экземпляр — полностью управляемую и предварительно настроенную облачную рабочую станцию. Дополнительные сведения см. в статье "Создание Машинное обучение Azure вычислительного экземпляра".
Важно!
Убедитесь, что в среде Python установлены последние и mltable последние azure-fsspec библиотеки Python:
pip install -U azureml-fsspec mltable
Доступ к данным из URI хранилища данных, например файловой системы
Хранилище данных Машинное обучение Azure — это ссылка насуществующую учетную запись хранения Azure. Преимущества создания и использования хранилища данных включают:
- Общий, простой API для взаимодействия с различными типами хранилища (BLOB-объекты/файлы/ADLS).
- Простое обнаружение полезных хранилищ данных в операциях группы.
- Поддержка доступа к данным на основе учетных данных (например, маркер SAS) и на основе удостоверений (используйте идентификатор Microsoft Entra или удостоверение Manged).
- Для доступа на основе учетных данных информация о подключении защищена, чтобы пустота воздействия ключа в скриптах.
- Просмотрите URI хранилища данных и скопируйте их в URI хранилища данных в пользовательском интерфейсе Studio.
URI хранилища данных — это универсальный идентификатор ресурса, который является ссылкой на расположение хранилища (путь) в учетной записи хранения Azure. Универсальный код ресурса (URI) хранилища данных имеет следующий формат:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Эти URI хранилища данных представляют собой известную реализацию спецификации файловой системы (fsspec): унифицированный pythonic интерфейс для локальных, удаленных и внедренных файловых систем и хранилища байтов.
Вы можете установить azureml-fsspec пакет и его пакет зависимостей azureml-dataprep . Затем можно использовать реализацию хранилища fsspec данных Машинное обучение Azure.
Реализация хранилища fsspec данных Машинное обучение Azure автоматически обрабатывает сквозное руководство по учетным данным или удостоверениям, которое использует Машинное обучение Azure хранилище данных. Вы можете избежать воздействия ключа учетной записи в скриптах и дополнительных процедур входа в вычислительном экземпляре.
Например, вы можете напрямую использовать URI хранилища данных в Pandas. В этом примере показано, как считывать CSV-файл:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Совет
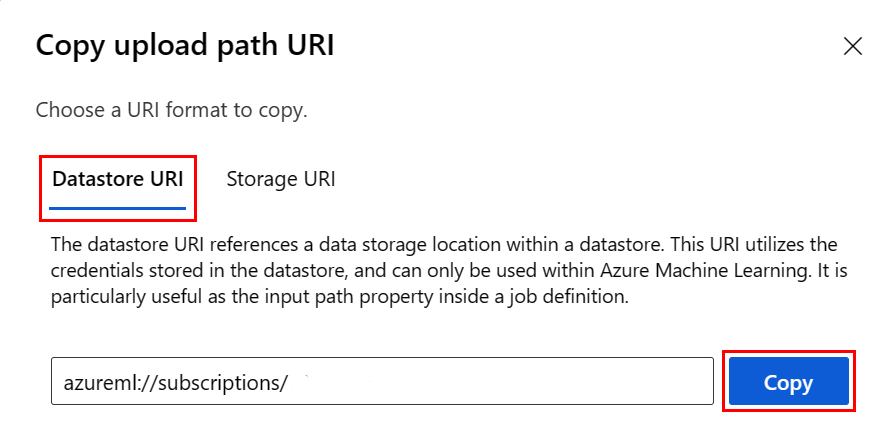
Вместо того чтобы помнить формат URI хранилища данных, можно скопировать и вставить универсальный код ресурса (URI) хранилища данных из пользовательского интерфейса Студии, выполнив следующие действия.
- Выберите данные из меню слева, а затем перейдите на вкладку "Хранилища данных".
- Выберите имя хранилища данных и перейдите к ней.
- Найдите файл или папку, которую вы хотите прочитать в Pandas, и выберите многоточие (...) рядом с ним. Выберите URI копирования в меню. Вы можете выбрать универсальный код ресурса (URI ) хранилища данных для копирования в записную книжку или скрипт.
Вы также можете создать экземпляр файловой системы Машинное обучение Azure для обработки файловой системы, например ls, glob. existsopen
- Метод
ls()перечисляет файлы в определенном каталоге. Для перечисления файлов можно использовать ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>). Мы поддерживаем как ".", так и ".". В относительных путях. - Метод
glob()поддерживает глоббирование "*" и "**". - Метод
exists()возвращает логическое значение, указывающее, существует ли указанный файл в текущем корневом каталоге. - Метод
open()возвращает объект, похожий на файл, который можно передать в любую другую библиотеку, которая ожидает работы с файлами Python. Код также может использовать этот объект, как если бы это был обычный файловый объект Python. Эти объекты, подобные файлам, уважают использованиеwithконтекстов, как показано в этом примере:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Отправка файлов с помощью AzureMachine Обучение FileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath — это локальный путь и rpath удаленный путь.
Если указанные папки rpath еще не существуют, мы создадим для вас папки.
Мы поддерживаем три режима перезаписи:
- APPEND: если файл с тем же именем существует в пути назначения, он сохраняет исходный файл.
- FAIL_ON_FILE_CONFLICT: если файл с тем же именем существует в пути назначения, это вызывает ошибку.
- MERGE_WITH_OVERWRITE: если файл с тем же именем существует в пути назначения, он перезаписывает существующий файл новым файлом.
Скачивание файлов с помощью AzureMachine Обучение FileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Примеры
В этих примерах показано использование спецификации файловой системы в распространенных сценариях.
Чтение одного CSV-файла в Pandas
Вы можете прочитать один CSV-файл в Pandas, как показано ниже.
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Чтение папки CSV-файлов в Pandas
Метод Pandas read_csv() не поддерживает чтение папки CSV-файлов. Необходимо сцепить csv-пути и сцепить их с кадром данных с помощью метода Pandas concat() . В следующем примере кода показано, как достичь этого объединения с файловой системой Машинное обучение Azure:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Чтение CSV-файлов в Dask
В этом примере показано, как считывать CSV-файл в кадр данных Dask:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Чтение папки файлов Parquet в Pandas
В рамках процесса ETL файлы Parquet обычно записываются в папку, которая затем может выдавать файлы, относящиеся к ETL, таким как ход выполнения, фиксации и т. д. В этом примере показаны файлы, созданные из процесса ETL (файлы, начиная с _), которые затем создают файл parquet данных.
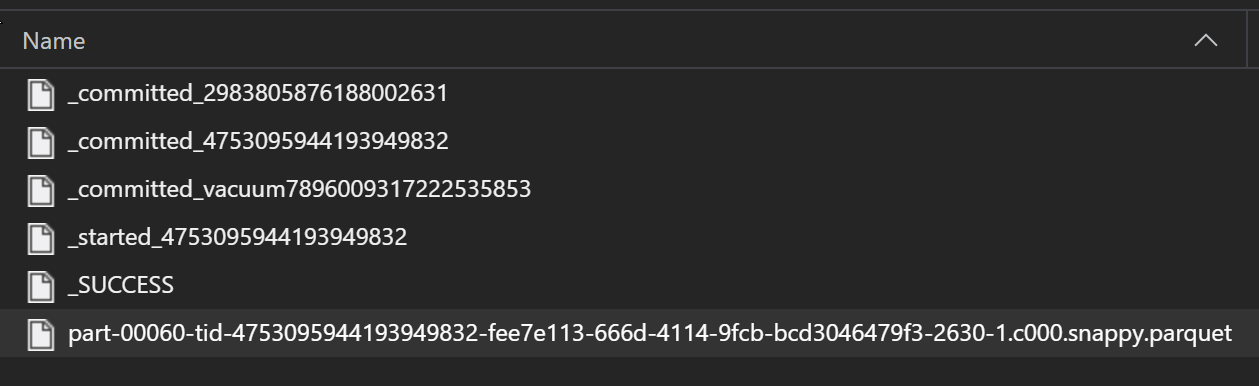
В этих сценариях вы считываете только файлы parquet в папке и игнорируете файлы процесса ETL. В этом примере кода показано, как шаблоны глобов могут считывать только файлы parquet в папке:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Доступ к данным из файловой системы Azure Databricks (dbfs)
Спецификация файловой системы (fsspec) имеет ряд известных реализаций, включая файловую систему Databricks (dbfs).
Чтобы получить доступ к данным из dbfs вас, выполните следующие действия.
- Имя экземпляра
adb-<some-number>.<two digits>.azuredatabricks.netв виде . Это значение можно найти в URL-адресе рабочей области Azure Databricks. - Личный маркер доступа (PAT); дополнительные сведения о создании PAT см. в статье "Проверка подлинности с помощью персональных маркеров доступа Azure Databricks"
С этими значениями необходимо создать переменную среды в вычислительном экземпляре для токена PAT:
export ADB_PAT=<pat_token>
Затем вы можете получить доступ к данным в Pandas, как показано в этом примере:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Чтение изображений с помощью pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Пример пользовательского набора данных PyTorch
В этом примере создается настраиваемый набор данных PyTorch для обработки изображений. Предполагается, что файл заметок (в формате CSV) существует с этой общей структурой:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Вложенные папки хранят эти изображения в соответствии с их метками:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Пользовательский класс набора данных PyTorch должен реализовать три функции: __init__, __len__и __getitem__, как показано ниже:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Затем можно создать экземпляр набора данных, как показано здесь:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Материализация данных в Pandas с помощью mltable библиотеки
Библиотека mltable также может помочь получить доступ к данным в облачном хранилище. Чтение данных в Pandas с mltable таким общим форматом:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Поддерживаемые пути
Библиотека mltable поддерживает чтение табличных данных из разных типов путей:
| Местонахождение | Примеры |
|---|---|
| Путь к локальному компьютеру | ./home/username/data/my_data |
| Путь к общедоступному HTTP(S)-серверу | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Путь к службе хранилища Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Хранилище данных с длинной формой Машинное обучение Azure | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Примечание.
mltableвыполняет передачу учетных данных пользователя для путей к хранилищам данных служба хранилища Azure и Машинное обучение Azure. Если у вас нет разрешения на доступ к данным в базовом хранилище, доступ к данным невозможен.
Файлы, папки и глобы
mltable поддерживает чтение из:
- File(s) — например:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - Папки — например,
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - Шаблоны glob - например,
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - сочетание файлов, папок и (или) шаблонов глоббинга
mltable гибкость позволяет материализации данных в один кадр данных из сочетания локальных и облачных ресурсов хранилища, а также сочетания файлов, папок и глобов. Например:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Поддерживаемые типы файлов
mltable поддерживает следующие форматы файлов:
- Разделительный текст (например, CSV-файлы):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Дельта:
mltable.from_delta_lake(paths=[path]) - Формат строк JSON:
mltable.from_json_lines_files(paths=[path])
Примеры
Чтение CSV-файла
Обновите заполнители (<>) в этом фрагменте кода с конкретными сведениями:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Чтение файлов Parquet в папке
В этом примере показано, как mltable использовать шаблоны глобов ( например, дикие карта, чтобы убедиться, что считываются только файлы parquet.
Обновите заполнители (<>) в этом фрагменте кода с конкретными сведениями:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Чтение ресурсов данных
В этом разделе показано, как получить доступ к ресурсам данных Машинное обучение Azure в Pandas.
Ресурс таблицы
Если вы ранее создали ресурс таблицы в Машинное обучение Azure (или mltableV1TabularDataset), вы можете загрузить этот ресурс таблицы в Pandas с помощью этого кода:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Файловый ресурс
Если вы зарегистрировали файловый ресурс (CSV-файл, например), вы можете считывать этот ресурс в кадр данных Pandas с помощью этого кода:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Ресурс папки
Если вы зарегистрировали ресурс папки (uri_folder или V1 FileDataset), например папку, содержащую CSV-файл, можно считывать этот ресурс в кадр данных Pandas с помощью этого кода:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Примечание о чтении и обработке больших томов данных с помощью Pandas
Совет
Pandas не предназначен для обработки больших наборов данных. Pandas может обрабатывать только данные, которые могут помещаться в память вычислительного экземпляра.
Для больших наборов данных рекомендуется использовать Машинное обучение Azure управляемый Spark. Это обеспечивает API PySpark Pandas.
Перед масштабированием до удаленного асинхронного задания может потребоваться быстро выполнить итерацию в меньшем подмножестве большого набора данных. mltable предоставляет встроенные функции для получения примеров больших данных с помощью метода take_random_sample :
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Вы также можете принимать подмножества больших данных с помощью следующих операций:
Скачивание данных с помощью служебной azcopy программы
Используйте служебную azcopy программу для скачивания данных на локальный SSD узла (локальный компьютер, облачная виртуальная машина, Машинное обучение Azure вычислительный экземпляр) в локальную файловую систему. Эта azcopy программа, предварительно установленная на Машинное обучение Azure вычислительном экземпляре, будет обрабатывать эту программу. Если вы не используете вычислительный экземпляр Машинное обучение Azure или Виртуальная машина для обработки и анализа данных (DSVM), может потребоваться установитьazcopy. Дополнительные сведения см. в azcopy .
Внимание
Мы не рекомендуем загружать данные в /home/azureuser/cloudfiles/code расположение в вычислительном экземпляре. Это расположение предназначено для хранения артефактов записной книжки и кода, а не данных. Чтение данных из этого расположения приведет к значительным затратам на производительность при обучении. Вместо этого рекомендуется хранить данные в home/azureuserлокальном SSD вычислительного узла.
Откройте терминал и создайте новый каталог, например:
mkdir /home/azureuser/data
Войдите в azcopy using:
azcopy login
Затем можно скопировать данные с помощью универсального кода ресурса (URI) хранилища
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST