Создание и запуск конвейеров машинного обучения с помощью пакета SDK для Машинное обучение Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python для ML Azure версии 1
Пакет SDK для Python для ML Azure версии 1
В этой статье вы узнаете, как создать и запустить конвейер машинного обучения с помощью пакета SDK Машинного обучения Azure. Используйте конвейеры Машинного обучения для создания рабочего процесса, который объединяет разные этапы машинного обучения. Затем опубликуйте этот конвейер, чтобы использовать его позднее или предоставить другим пользователям. Отслеживайте конвейеры Машинного обучения, чтобы оценивать эффективность работы модели в реальных условиях и обнаруживать смещение данных. Конвейеры Машинного обучения идеально подходят для сценариев пакетной оценки с использованием разных вычислений, позволяя повторно использовать действия без их повторного создания, а также предоставить рабочие процессы Машинного обучения другим пользователям.
Эта статья не является учебником. Рекомендации по созданию первого конвейера см. в разделе Учебник. Создание конвейера Машинного обучения Azure для пакетной оценки или Использование автоматизированного Машинного обучения в конвейере Машинного обучения Azure в Python.
Для автоматизации задач машинного обучения в процессах CI/CD можно использовать и другой тип конвейера, именуемый конвейером Azure, но этот тип конвейера не хранится в рабочей области. Сравните эти типы конвейеров.
Созданные вами конвейеры Машинного обучения видны всем участникам вашей рабочей области в Службе машинного обучения Azure.
Конвейеры Машинного обучения выполняются в целевых объектах вычислений (см. раздел Что такое целевые объекты вычислений в Машинном обучении Azure). Конвейеры могут выполнять чтение и запись данных в поддерживаемых расположениях службы хранилища Azure.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе. Попробуйте бесплатную или платную версию Машинного обучения Azure.
Необходимые компоненты
Рабочая область Машинного обучения Azure. Создание ресурсов рабочей области.
Настройте среду разработки для установки пакета SDK Машинного обучения Azure или используйте вычислительный экземпляр Машинного обучения Azure с уже установленным пакетом SDK.
Для начала подключите рабочую область:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Настройка ресурсов машинного обучения
Создайте ресурсы, необходимые для запуска конвейера Машинного обучения.
Настройте хранилище данных для хранения данных, необходимых для выполнения шагов конвейера.
Настройте объект
Dataset, чтобы он указывал на данные, которые хранятся в хранилище данных или могут быть через него получены. Настройте объектOutputFileDatasetConfigдля временных данных, передаваемых между этапами конвейера.Настройте целевые объекты вычислений для выполнения шагов вашего конвейера.
Настройка хранилища данных
Хранилище данных содержит данные, которые использует конвейер. У каждой рабочей области есть хранилище данных по умолчанию. Вы можете зарегистрировать дополнительные хранилища данных.
При создании рабочей области к ней подключаются Файлы Azure и хранилище BLOB-объектов Azure. Регистрируется хранилище данных по умолчанию для подключения к хранилищу BLOB-объектов. Дополнительные сведения см. в статье Выбор между большими двоичными объектами Azure, службой файлов Azure и дисками Azure.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Шаги обычно потребляют некоторые данные и создают выходные данные. Шаг может создать данные, такие как модель, каталог с моделью и зависимыми файлами или временные данные. Эти данные становятся доступными для последующих шагов в конвейере. Дополнительные сведения о подключении конвейера к данным см. в статьях о доступе к данным и о регистрации наборов данных.
Настройка данных с помощью объектов Dataset и OutputFileDatasetConfig
Для передачи данных в конвейер лучше всего использовать объект DataSet. Объект Dataset указывает на данные, которые хранятся в хранилище данных или доступны через него. Класс Dataset является абстрактным, то есть вы по сути создаете экземпляр FileDataset (который ссылается на один или несколько файлов) или TabularDataset, который создается из одного или нескольких файлов с разделенными столбцами данных.
Для создания Dataset вы примените методы from_files или from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Промежуточные данные (или выходные данные шага) представлены объектом OutputFileDatasetConfig. Объект output_data1 создается как выходные данные шага. При необходимости эти данные можно зарегистрировать в качестве набора данных, вызвав register_on_complete. Если вы создаете объект OutputFileDatasetConfig на одном шаге и используете его в качестве входных данных для другого шага, зависимость данных между шагами создает неявный порядок выполнения в конвейере.
Объекты OutputFileDatasetConfig возвращают каталог и по умолчанию записывают выходные данные в хранилище данных по умолчанию рабочей области.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Важно!
Azure не выполняет автоматическое удаление промежуточных данных, сохраненных с помощью OutputFileDatasetConfig.
Вы должны либо удалить промежуточные данные в конце выполнения конвейера программными средствами, либо использовать хранилище данных с политикой короткого хранения, либо регулярно выполнять очистку вручную.
Совет
Отправляйте только файлы, относящиеся к заданию. Любые изменения в файлах в каталоге данных будут рассматриваться как основание для повторного выполнения шага при следующем запуске конвейера, даже если указано повторное использование.
Настройка целевой среды для вычислений
В Машинном обучении Azure вычислительной средой (или целевым объектом вычислений) считаются компьютеры или кластеры, которые выполняют вычислительные операции в конвейере машинного обучения. Полный список целевых объектов вычислений см. в разделе Целевые объекты вычислений для обучения моделей, а сведения об их создании и подключении к рабочей области см. в разделе Создание целевых объектов вычислений. Процесс создания и (или) подключения целевого объекта вычислений будет одинаковым как при обучении модели, так и при выполнении шага конвейера. После того как вы создадите и присоедините свой целевой объект вычислений, используйте объект ComputeTarget на шаге конвейера.
Важно!
Выполнение операций управления на целевых объектах вычислений не поддерживается внутри удаленных заданий. Так как конвейеры машинного обучения передаются в качестве удаленного задания, не используйте операции управления на целевых объектах вычислений внутри конвейера.
Вычислительная среда Машинного обучения Azure
Для выполнения шагов конвейера можно создать вычислительную среду Машинного обучения Azure. Код для других целевых объектов вычислений аналогичный, с небольшими отличиями в параметрах, в зависимости от типа.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Настройка среды для обучающего запуска
Далее вам нужно убедиться, что удаленный обучающий запуск имеет все зависимости, необходимые для этапов обучения. Зависимости и контекст среды выполнения задаются путем создания и настройки объекта RunConfiguration.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
В приведенном выше коде показано два варианта обработки зависимостей. Как показано, при USE_CURATED_ENV = True конфигурация основывается на курированной среде. Курированными называют среды, заранее дополненные типичными библиотеками взаимозависимостей, благодаря чему их можно быстрее перевести в оперативный режим. Курированные среды содержат предварительно созданные образы Docker в Microsoft Container Registry. Дополнительные сведения см. в разделе Курированные среды Машинного обучения Azure.
Путь, выбранный при изменении USE_CURATED_ENV на False, демонстрирует шаблон для явного задания зависимостей. В этом сценарии новый пользовательский образ Docker будет создан и зарегистрирован в вашей группе ресурсов в Реестре контейнеров Azure (см. раздел Общие сведения о частных реестрах контейнеров Docker в Azure). Создание и регистрация этого образа может занять несколько минут.
Создание шагов конвейера
Создав вычислительный ресурс и среду, вы можете приступить к определению шагов конвейера. В пакете SDK Машинного обучения Azure доступно множество встроенных шагов, как представлено в справочной документации по пакету azureml.pipeline.steps. Наиболее гибким является класс PythonScriptStep, который запускает скрипт Python.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
В приведенном выше коде показан типичный начальный шаг конвейера. Код подготовки данных находится в подкаталоге (в нашем примере это "prepare.py" в каталоге "./dataprep.src"). В процессе создания конвейера этот каталог упаковывается и передается в compute_target, а этап конвейера выполняет скрипт, указанный в качестве значения для параметра script_name.
Значения arguments определяют входные и выходные данные для этого шага. В приведенном выше примере базовые данные представлены набором данных my_dataset. Соответствующие данные будут загружены вычислительный ресурс, так как в коде для них указано as_download(). Скрипт prepare.py выполняет все задачи преобразования данных, соответствующие поставленной задаче, и выводит данные в output_data1 с типом OutputFileDatasetConfig. Дополнительные сведения см. в разделе Перемещение данных в этапы конвейера Машинного обучения и между ними (Python).
Этот шаг будет выполняться на компьютере, определенном параметром compute_target, при использовании конфигурации aml_run_config.
Повторное использование предыдущих результатов (allow_reuse) является ключевым при использовании конвейеров в среде совместной работы, так как устранение ненужных повторных запусков обеспечивает гибкость. Повторное использование — это поведение по умолчанию, когда имя скрипта, входные данные и параметры шага остаются неизменными. Если повторное использование разрешено, результаты предыдущего запуска немедленно отправляются в следующий шаг. Если параметр allow_reuse имеет значение False, для этого шага всегда будет создаваться новый запуск во время выполнения конвейера.
Возможно создать конвейер из одного шага, но почти всегда вы захотите разделить общий процесс на несколько шагов. Например, могут быть шаги для подготовки данных, обучения, сравнения моделей и развертывания. В частности, можно предположить, что после указанного выше шага data_prep_step следующим шагом будет обучение:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Приведенный выше код похож на код в шаге подготовки данных. Обучающий код находится в каталоге, отдельном от каталога кода подготовки данных. Выходные данные OutputFileDatasetConfig шага подготовки данных output_data1 используются в качестве входных данных для шага обучения. Создается новый объект OutputFileDatasetConfig (training_results) для хранения результатов последующего сравнения или шага развертывания.
Другие примеры кода см. в разделах о создании двухшагового конвейера машинного обучения и записи данных обратно в хранилища данных после завершения выполнения.
После определения шагов следует создать конвейер, добавив в него некоторые созданные шаги (или все).
Примечание.
При определении шагов или создании конвейера никакие файлы или данные в Машинное обучение Azure не отправляются. Файлы отправляются при вызове Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Использование набора данных
Наборы данных, созданные из хранилища BLOB-объектов Azure, Файлов Azure, Azure Data Lake Storage 1-го поколения, Azure Data Lake Storage 2-го поколения, Базы данных SQL Azure и Базы данных Azure для PostgreSQL, можно использовать в качестве входных данных для любого шага конвейера. Вы можете записывать выходные данные в DataTransferStep или DatabricksStep, а если хотите записать данные в определенное хранилище данных, используйте OutputFileDatasetConfig.
Важно!
Запись выходных данных обратно в хранилище данных с помощью OutputFileDatasetConfig поддерживается только для хранилищ данных BLOB-объектов Azure, общей папки Azure, а также ADLS 1-го и 2-го поколений.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Затем вы извлекаете набор данных в своем конвейере с помощью словаря Run.input_datasets.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Следует особо выделить строку Run.get_context(). Эта функция извлекает объект Run, представляющий текущий экспериментальный запуск. В приведенном выше примере мы используем его для получения зарегистрированного набора данных. Кроме того, объект Run часто используется для получения как самого эксперимента, так и рабочей области, в которой находится эксперимент:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Дополнительные сведения, включая другие способы передачи данных и доступа к ним, см. в разделе Перемещение данных в шаги конвейера Машинного обучения и между этими шагами (Python).
Повторное использование и кэширование
Для оптимизации и настройки поведения конвейеров вы можете выполнить несколько действий, связанных с кэшированием и повторным использованием. Например, вы можете:
- Отключить повторное использование по умолчанию выходных данных шага запуска, задав
allow_reuse=Falseво время определения шага. Повторное использование является ключевым при использовании конвейеров в среде совместной работы, так как устранение ненужных повторных запусков обеспечивает гибкость. Однако вы можете отказаться от повторного использования. - Обеспечить принудительное пересоздание для всех шагов с помощью
pipeline_run = exp.submit(pipeline, regenerate_outputs=True).
По умолчанию параметр allow_reuse для шагов включен, и каталог source_directory, указанный в определении шага, хэшируется. Таким образом, если скрипт для конкретного шага остается тем же (script_name, входные данные и параметры), и ничего больше в source_directory не изменилось, выходные данные, полученные в результате выполнения предыдущего шага, используются повторно, задание не отправляется на вычисление, а результаты предыдущего выполнения становятся сразу же доступными для следующего шага.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Примечание.
Если изменятся имена входов данных, этот шаг будет выполнен заново, даже если не изменятся сами базовые данные. Вы можете явным образом задать поле name для входных данных (data.as_input(name=...)). Если вы не укажете явное значение, поле name получит случайное значение идентификатора GUID, и результаты этого шага не будут использоваться повторно.
Отправка конвейера
Когда вы отправляете конвейер, Машинное обучение Azure проверяет зависимости для каждого шага и отправляет моментальный снимок указанного вами исходного каталога. Если исходный каталог не указан, передается текущий локальный каталог. Этот моментальный снимок также сохраняется как часть эксперимента в вашем рабочем пространстве.
Важно!
Чтобы предотвратить включение ненужных файлов в моментальный снимок, создайте файл игнорирования (.gitignore или .amlignore) в каталоге. Добавьте исключаемые файлы и каталоги в этот файл. Дополнительные сведения о синтаксисе, который будет использоваться в этом файле, см. в разделе синтаксис и шаблоны для .gitignore. Файл .amlignore использует тот же синтаксис. Если оба файла существуют, используется файл .amlignore, а файл .gitignore не используется.
Дополнительные сведения см. в разделе о моментальных снимках.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
При первом запуске конвейера служба машинного обучения Azure выполняет следующие действия.
Скачивает моментальный снимок проекта из хранилища BLOB-объектов, связанного с рабочей областью, на целевой объект вычислений.
Создает образ Docker, соответствующий каждому шагу в конвейере.
Загружает образ Docker для каждого шага в целевой объект вычислений из реестра контейнеров.
Настраивает доступ к объектам
DatasetиOutputFileDatasetConfig. В режиме доступаas_mount()для предоставления виртуального доступа используется FUSE. Если подключение не поддерживается, или если пользователь указал режим доступа какas_upload(), данные копируются в целевой объект вычислений.Выполняет шаг на целевом объекте вычислений, указанном в определении этого шага.
Создает артефакты (журналы, stdout и stderr, метрики и выходные данные), указанные в шаге. Затем эти артефакты передаются в хранилище данных пользователя по умолчанию для хранения.
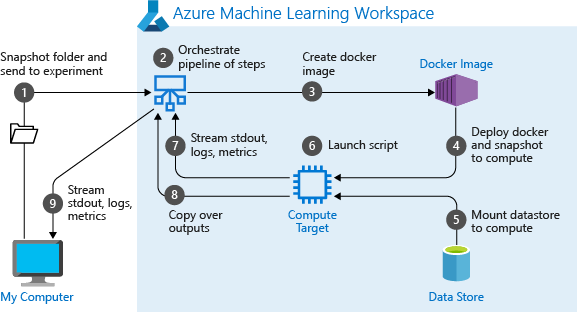
Дополнительные сведения см. в справочной документации по классу Experiment.
Использование параметров конвейера для аргументов, которые изменяются во время вывода
Иногда аргументы для отдельных шагов в конвейере относятся к периоду разработки и обучения. Это могут быть такие вещи, как скорость обучения и импульс, а также пути к данным или файлам конфигурации. Однако при развертывании модели вы захотите динамически передавать аргументы, на основании которых вы делаете вывод (то есть запрос, на котором строится модель для ответа). Вы должны сделать эти типы аргументов параметрами конвейера. Для этого в Python используйте класс azureml.pipeline.core.PipelineParameter, как показано в следующем фрагменте кода.
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Как среды Python работают с параметрами конвейера
Как обсуждалось выше в разделе Настройка среды обучающего запуска, состояние среды и зависимости библиотеки Python задаются с помощью объекта Environment. Как правило, вы можете указать существующий объект Environment, указав его имя и при желании версию:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Однако если вы решили динамически задавать переменные в среде выполнения для шагов конвейера с помощью объектов PipelineParameter, этот метод нельзя использовать для ссылки на существующий объект Environment. Вместо этого, если вы хотите использовать объекты PipelineParameter, необходимо задать в поле environment объекта RunConfiguration значение объекта Environment. Вы отвечаете за правильную настройку получения таким объектом Environment своих зависимостей от внешних пакетов Python.
Просмотр результатов конвейера
Просмотрите список всех своих конвейеров и подробные сведения об их запуске.
Войдите в Студию машинного обучения Azure.
В левой части выберите Конвейеры, чтобы просмотреть все запуски конвейеров.
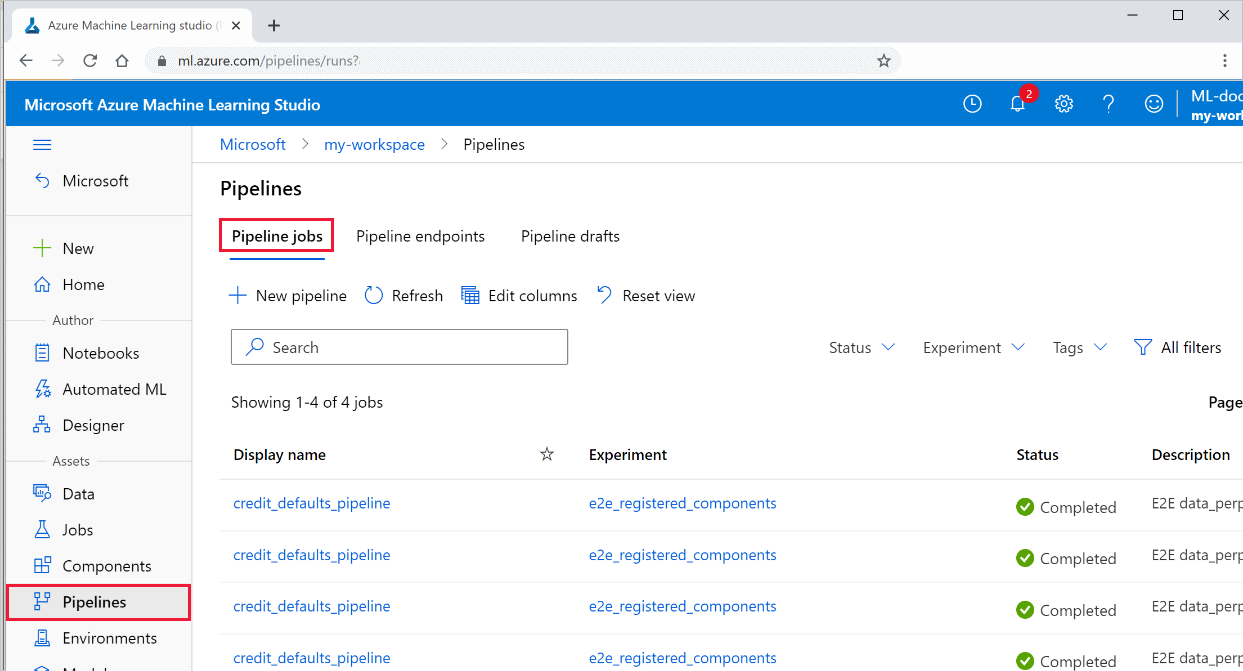
Выберите конкретный конвейер, чтобы просмотреть результаты его запуска.
Отслеживание и интеграция Git
При выполнении запуска обучения, в котором исходный каталог является локальным репозиторием Git, сведения о репозитории хранятся в журнале выполнения. Дополнительные сведения см. в статье Интеграция с Git для Машинного обучения Azure.
Следующие шаги
- Сведения о том, как поделиться конвейером с коллегами или клиентами, см. в разделе Публикация конвейеров машинного обучения.
- Используйте эти записные книжки Jupyter на сайте GitHub, чтобы подробнее изучить конвейеры машинного обучения.
- См. справочные материалы по пакету SDK для пакетов azureml-pipelines-core и azureml-pipelines-steps.
- Советы по отладке и устранению неполадок в конвейерах см. в этих инструкциях.
- Узнайте, как запускать записные книжки, следуя указаниям из статьи Использование записных книжек Jupyter в Машинном обучении Azure.