Использование пользовательского контейнера для развертывания модели в сетевой конечной точке
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Узнайте, как использовать пользовательский контейнер для развертывания модели в веб-конечной точке в Машинное обучение Azure.
В пользовательских развертываниях контейнеров могут применяться веб-серверы, отличные от сервера Python Flask по умолчанию, используемого в Машинном обучении Azure. В этих развертываниях по-прежнему можно пользоваться преимуществами мониторинга, масштабирования, оповещения и проверки подлинности Машинного обучения Azure.
В следующей таблице перечислены различные примеры развертывания, использующие настраиваемые контейнеры, такие как TensorFlow Service, TorchServe, Triton Inference Server, пакет Plumber R и Машинное обучение Azure минимальное изображение вывода.
| Пример | Скрипт (CLI) | Description |
|---|---|---|
| минимальное или многомодельное | deploy-custom-container-min-multimodel | Разверните несколько моделей в одном развертывании, расширив Машинное обучение Azure минимальное изображение вывода. |
| минимальная/одна модель | deploy-custom-container-min-single-model | Разверните одну модель, расширив Машинное обучение Azure минимальное изображение вывода. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Разверните две модели MLFlow с различными требованиями Python к двум отдельным развертываниям за одной конечной точкой с помощью минимального образа вывода Машинное обучение Azure. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Развертывание трех моделей регрессии в одной конечной точке с помощью пакета Plumber R |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Разверните модель Half Plus Two с помощью настраиваемого контейнера TensorFlow, используя стандартный процесс регистрации модели. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Разверните модель Half Plus Two с помощью настраиваемого контейнера TensorFlow Для обслуживания с моделью, интегрированной в образ. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Разверните одну модель с помощью пользовательского контейнера TorchServe. |
| torchserve/huggingface-textgen | deploy-custom-container-torchserve-huggingface-textgen | Разверните модели распознавания лиц в сети и следуйте примеру Hugging Face Transformers TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Развертывание модели Triton с помощью пользовательского контейнера |
В этой статье рассматривается обслуживание модели TensorFlow с помощью TensorFlow (TF).
Предупреждение
Возможно, корпорация Майкрософт не сможет устранить неполадки, вызванные пользовательским изображением. Если возникают проблемы, может потребоваться использовать образ по умолчанию или один из образов Майкрософт, чтобы узнать, относится ли проблема к изображению.
Необходимые компоненты
Перед выполнением действий, описанных в этой статье, убедитесь, что выполнены следующие необходимые условия:
Рабочая область Машинного обучения Azure. Если у вас ее нет, создайте ее по инструкциям, приведенным в кратком руководстве по созданию ресурсов рабочей области.
Azure CLI и
mlрасширение или пакет SDK для Python версии 2 Машинное обучение Azure:Чтобы установить Azure CLI и расширение, см. статью "Установка,настройка" и использование интерфейса командной строки (версии 2).
Внимание
В примерах CLI в этой статье предполагается, что вы используете оболочку Bash (или совместимый вариант). Например, из системы Linux или подсистемы Windows для Linux.
Чтобы установить пакет SDK для Python версии 2, используйте следующую команду:
pip install azure-ai-ml azure-identityЧтобы обновить существующую установку пакета SDK до последней версии, выполните следующую команду:
pip install --upgrade azure-ai-ml azure-identityДополнительные сведения см. в статье "Установка пакета SDK для Python версии 2 для Машинное обучение Azure".
Вы или субъект-служба, который вы используете, должны иметь доступ участника к группе ресурсов Azure, содержащей рабочую область. У вас есть такая группа ресурсов, если вы настроили рабочую область с помощью статьи краткого руководства.
Для локального развертывания необходимо, чтобы подсистема Docker запускалась локально. Настоятельно рекомендуется выполнить этот этап. Это помогает отлаживать проблемы.
Скачивание исходного кода
Чтобы следовать этому руководству, клонируйте исходный код из GitHub.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Инициализация переменных среды
Определение переменных среды:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Загрузите модель TensorFlow.
Загрузите и распакуйте модель, которая делит входные данные на два и добавляет 2 к результату:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Запустите образ TF Serving локально, чтобы проверить, работает ли он.
Используйте Docker, чтобы локально запустить образ для тестирования:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Убедитесь, что вы можете отправлять запросы на активность и оценку образа.
Во-первых, проверка, что контейнер жив, то есть процесс внутри контейнера по-прежнему выполняется. Вы должны получить ответ "200 (ОК)".
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Затем убедитесь, что вы можете получать прогнозы о немаркированных данных:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Остановка образа
Теперь, когда вы проверили локально, остановите изображение:
docker stop tfserving-test
Развертывание сетевой конечной точки в Azure
Теперь следует развернуть сетевую конечную точку в Azure.
Создайте файл YAML для конечной точки и развертывания
С помощью YAML можно настроить облачное развертывание. Взгляните на выборку YAML для этого примера:
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
В этом параметре YAML/Python следует отметить несколько важных концепций:
Маршрут готовности в сравнении с маршрутом активности
HTTP-сервер определяет пути как для активности, так и для готовности. С помощью маршрут активности проверяют, работает ли сервер. С помощью маршрута готовности проверяют, готов ли сервер к выполнению работы. В выводе машинного обучения сервер может выдать ответ "200 (ОК)" на запрос об активности перед загрузкой модели. Сервер может ответить 200 OK на запрос готовности только после загрузки модели в память.
Дополнительные сведения о пробах активности и готовности см. в документации по Kubernetes.
Обратите внимание, что в этом развертывании используется один и тот же путь как для активности, так и для готовности, поскольку TF Serving определяет только маршрут активности.
Определение местоположения подключенной модели
При развертывании модели в качестве подключенной конечной точки Машинное обучение Azure подключает эту модель к конечной точке. Подключение модели позволяет развертывать новые версии модели, не создавая новый образ Docker. По умолчанию модель, зарегистрированная с именем foo и версией 1 , будет находиться по следующему пути внутри развернутого контейнера: /var/azureml-app/azureml-models/foo/1
Например, если у вас есть структура каталога /azureml-examples/cli/endpoints/online/custom-container на локальном компьютере, где модель называется half_plus_two:
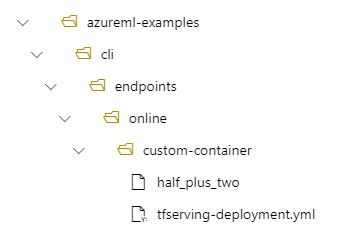
И tfserving-deployment.yml содержит следующее:
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
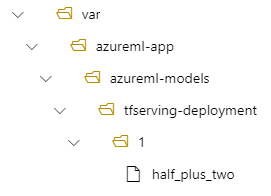
Затем модель будет находиться в разделе /var/azureml-app/azureml-models/tfserving-deployment/1 в развертывании:
При необходимости можно настроить model_mount_path. Он позволяет изменить путь, в котором подключена модель.
Внимание
model_mount_path должен быть допустимым абсолютным путем в Linux (ОС образа контейнера).
Например, можно иметь параметр model_mount_path в tfserving-deployment.yml:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
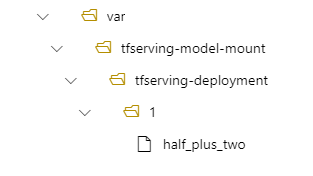
Затем модель находится в папке /var/tfserving-model-mount/tfserving-deployment/1 в развертывании. Обратите внимание, что он больше не находится в azureml-app/azureml-models, но в указанном пути подключения:
Создание конечной точки и развертывания
Теперь, когда вы узнаете, как был создан YAML, создайте конечную точку.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
Создание развертывания может занять несколько минут.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
Вызов конечной точки
После развертывания проверьте, можете ли вы сделать запрос на оценку для развернутой конечной точки.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Удаление конечной точки
Теперь, когда вы успешно забили конечную точку, ее можно удалить:
az ml online-endpoint delete --name tfserving-endpoint