Настройка обучения AutoML без кода для табличных данных с помощью пользовательского интерфейса студии
Из этой статьи вы узнаете, как настраивать задания обучения AutoML без единой строки кода с помощью автоматизированного ML службы "Машинное обучение Azure" в Студии машинного обучения Azure.
Автоматизированное машинное обучение (AutoML) — это процесс выбора оптимального алгоритма машинного обучения для конкретных данных. Этот процесс позволяет быстро создавать модели машинного обучения. Дополнительные сведения о том, как Машинное обучение Azure реализует автоматизированное машинное обучение.
Полный пример см. в учебнике по использованию AutoML для обучения моделей классификации без написания кода.
Чтобы воспользоваться функцией создания кода на Python, настройте эксперименты машинного обучения с помощью пакета SDK для Машинного обучения Azure.
Необходимые компоненты
Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу. Опробуйте бесплатную или платную версию Машинного обучения Azure уже сегодня.
Рабочая область Машинного обучения Azure. См.раздел Создание ресурсов рабочей области.
Начать
Войдите в Студию машинного обучения Azure.
Выберите подписку и рабочую область.
Перейдите в область слева. Выберите автоматизированное машинное обучение в разделе "Разработка ".

Если вы впервые выполняете любые эксперименты, вы увидите пустой список и ссылки на документацию.
В противном случае вы увидите список последних экспериментов автоматизированного машинного обучения, включая созданные с помощью пакета SDK.
Создание и запуск эксперимента
Выберите + Создать задание автоматизированного машинного обучения и заполните форму.
Выберите ресурс данных из контейнера хранилища или создайте новый ресурс. Ресурсы данных можно создавать на основе локальных файлов, URL-адресов в Интернете, хранилищ данных или открытых наборов данных Azure. Дополнительные сведения о создании ресурсов данных см. здесь.
Важно!
Требования к обучающим данным:
- Данные должны иметь табличный формат.
- В данных должно присутствовать прогнозируемое значение (целевой столбец).
Чтобы создать новый набор данных на основе файла на локальном компьютере, нажмите +Создать набор данных, а затем выберите Из локального файла.
Нажмите Далее, чтобы открыть форму выбора хранилища данных и файлов. , вы выбираете место для отправки набора данных; контейнер хранилища по умолчанию, который автоматически создается в рабочей области, или выберите контейнер хранилища, который вы хотите использовать для эксперимента.
- Если данные находятся за виртуальной сетью, необходимо включить функцию пропустить проверку, чтобы убедиться, что рабочая область может получить доступ к данным. Дополнительные сведения см. в статье Использование Студии машинного обучения Azure в виртуальной сети Azure.
Нажмите кнопку Обзор, чтобы отправить файл данных для набора данных.
Проверьте точность заполнения формы параметров и предварительного просмотра. Для формы применяется интеллектуальное заполнение на основе типа файла.
Поле Description File format Свойство определяет структуру и тип данных, хранящихся в файле. Разделитель Один или несколько символов для указания границы между отдельными, независимыми регионами в виде простого текста или других потоков данных. Кодировка Определяет, какой бит следует использовать в таблице схемы символов, чтобы считать набор данных. Заголовки столбцов Указывает, как будут обрабатываться заголовки набора данных, если таковые имеются. Пропустить строки Указывает, сколько строк, если таковые имеются, пропускается в наборе данных. Выберите Далее.
Для формы схемы используется интеллектуальное заполнение с учетом выбора в форме параметров и предварительного просмотра. Здесь можно настроить тип данных для каждого столбца, проверить имена столбцов и выбрать столбцы, которые не следует включать в эксперимент.
Выберите Далее.
В форме подтверждения сведений приведена сводка по данным, которые были ранее введены в формах общих сведений и параметров и предварительного просмотра. С помощью вычислений среды с поддержкой профилирования вы также можете создать профиль данных для набора данных.
Выберите Далее.
Выберите только что созданный набор данных, когда он появится в списке. Вы также можете просмотреть предварительный просмотр набора данных и пример статистики.
В форме Настройка задания нажмите Создать и введите Tutorial-automl-deploy в качестве имени эксперимента.
Выберите целевой столбец. Это столбец, по которому необходимо выполнить прогнозирование.
Выберите тип вычисления для задания профилирования данных и обучения. Можно выбрать вычислительный кластер или вычислительный экземпляр.
Выберите вычисление из раскрывающегося списка существующих вычислений. Чтобы создать вычислительную среду, следуйте инструкциям для шага 8.
Щелкните Create a new compute (Создать вычислительную среду) и настройте контекст вычислений для этого эксперимента.
Поле Description Имя вычислительной среды Введите уникальное имя для идентификации контекста вычислительной среды. Приоритет виртуальной машины Низкоприоритетные виртуальные машины дешевле, но не гарантируют доступность вычислительных узлов. Тип виртуальной машины Выберите ЦП или GPU для типа виртуальной машины. размер виртуальной машины; Выберите размер виртуальной машины для вычислительной среды. Min/Max nodes (Минимальное и максимальное количество узлов) Чтобы профилировать данные, необходимо указать один или несколько узлов. Введите максимальное число узлов для вычислительной среды. Значение по умолчанию — шесть узлов для Машинное обучение Azure вычислений. Дополнительные настройки Эти параметры позволяют настроить учетную запись пользователя и существующую виртуальную сеть для эксперимента. Нажмите кнопку создания. Создание вычислительной среды может занять несколько минут.
Выберите Далее.
В форме типа и параметров задачи выберите тип задачи: классификация, регрессия или прогнозирование. Дополнительные сведения см. в разделе о поддерживаемых типах задач.
Для классификации можно также включить глубокое обучение.
Для прогнозирования можно выполнить следующие действия.
Включить глубокое обучение.
Выбрать столбец времени. Он содержит данные о времени, которые необходимо использовать.
Выбрать горизонт прогнозирования. Он показывает, на сколько единиц времени (минут, часов, дней, недель, месяцев или лет) модель сможет прогнозировать будущее. Далее в будущее модель требуется для прогнозирования, чем меньше точность модели становится. Узнайте больше о прогнозе и горизонте прогнозирования.
Необязательно. Просмотрите дополнительные параметры конфигурации, которые можно использовать для лучшего управления заданием обучения. В противном случае применяются значения по умолчанию, основанные на выборе эксперимента и данных.
Дополнительные конфигурации Description Основная метрика Основная метрика, используемая для оценки модели. Узнайте больше о метриках модели. Включение стека ансамбля Коллективное обучение улучшает результаты машинного обучения и точность прогнозов, объединяя несколько моделей в отличие от использования отдельных моделей. Узнайте больше о моделях ансамбля. Заблокированные модели Выберите модели, которые нужно исключить из задания обучения.
Разрешение моделей доступно только для экспериментов пакета SDK.
См. поддерживаемые алгоритмы для каждого типа задачи.Пояснения для наилучшей модели Автоматически отображается объясняемость для оптимальной модели, созданной автоматизированным машинным обучением. Метка положительного класса Метка, используемая автоматизированным машинным обучением для вычисления двоичных метрик. (Необязательно.) Просмотрите параметры конструирования признаков: если вы решили включить Автоматическое конструирование признаков в форме Дополнительные параметры конфигурации, применяются методики конструирования признаков по умолчанию. В параметрах представления признаков эти значения по умолчанию можно изменить и настроить соответствующим образом. Узнайте, как настроить конструирование признаков.
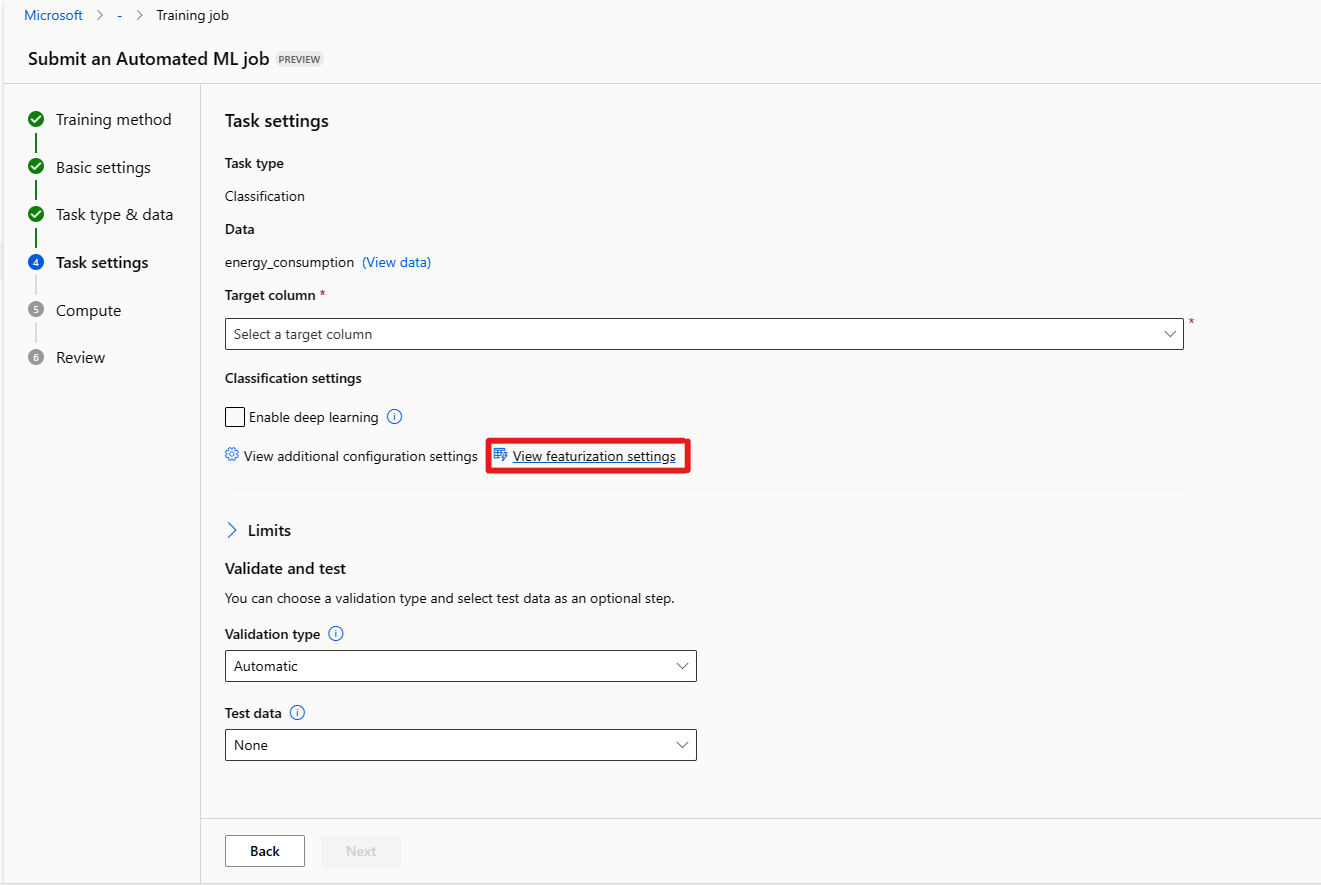
Форма ограничений [необязательно] позволяет выполнять следующие действия.
Параметр Описание Максимальное количество пробных версий Максимальное количество пробных версий, каждое из которых содержит различные сочетания алгоритмов и гиперпараметров, которые необходимо попробовать во время задания AutoML. Требуется целое число от 1 до 1000. Максимальное число параллельных пробных версий Максимальное количество заданий пробной версии, которые могут выполняться параллельно. Требуется целое число от 1 до 1000. Максимальное число узлов Максимальное количество узлов, которые это задание может использовать из выбранного целевого объекта вычислений. Пороговое значение оценки метрик Когда это пороговое значение будет достигнуто для метрики итерации, задание обучения завершится. Помните, что значимые модели имеют корреляцию > 0, в противном случае они так же хорошо, как угадывание среднего порогового значения метрик должны быть между границами [0, 10]. Время ожидания эксперимента (минуты) Максимальное время в минутах, в течение всего эксперимента разрешено выполнять. После достижения этого ограничения система отменит задание AutoML, включая все пробные версии (дочерние задания). Время ожидания итерации (минуты) Максимальное время в минутах для каждого задания пробной версии разрешено выполнять. По достижении этого предела система отменит пробную версию. Включение раннего завершения Выберите, чтобы завершить задание, если оценка не улучшается в краткосрочной перспективе. Форма Проверка и тестирование [необязательно] позволяет выполнять перечисленные ниже действия.
a. Укажите тип проверки для использования в задании обучения. Если параметр validation_data или n_cross_validations не задан явно, автоматический алгоритм ML применяет методы по умолчанию в зависимости от числа строк, предоставленных в одном наборе данных training_data.
| Объем данных обучения | Метод проверки |
|---|---|
| Более 20 000 строк | Применяется разбиение данных по обучению и проверке. Значение по умолчанию — использовать 10 % начального набора данных для обучения в качестве набора проверки. В свою очередь, этот набор проверки используется для вычисления метрик. |
| Меньше 20 000 строк | Применяется подход перекрестной проверки. Стандартное количество сверток зависит от числа строк. Если набор данных содержит менее 1000 строк, то используется 10 сверток. Если имеется от 1000 до 20 000 строк, то используются три свертки. |
b. Предоставьте тестовый набор данных (предварительная версия) для оценки рекомендуемой модели, которую автоматизированное машинное обучение сформирует для вас по окончании эксперимента. Если вы предоставите тестовые данные, по окончании эксперимента будет автоматически активировано тестовое задание. Это тестовое задание — это только задание в лучшей модели, рекомендуемой автоматизированным машинным обучением. Узнайте, как получить результаты выполнения удаленного тестового задания.
Важно!
Предоставление тестового набора данных для оценки созданных моделей доступно как предварительная версия функции. Этот возможность является предварительной версией экспериментальной функции и может быть изменена в любое время.
* Тестовые данные считаются отдельными от обучения и проверки, чтобы не предвзять результаты тестового задания рекомендуемой модели. Дополнительные сведения о смещении при проверке модели.
* Вы можете предоставить собственный набор данных теста или использовать процент от обучающего набора данных. Тестовые данные должны быть представлены в виде табличного набора данных Машинного обучения Azure.
* Схема тестового набора данных должна соответствовать набору обучающих данных. Целевой столбец необязателен, но если целевой столбец не указан, тестовые метрики не вычисляются.
* Тестовый набор данных не должен совпадать с набором данных обучения или набором данных проверки.
* Задания прогнозирования не поддерживают разделение обучения и тестирования.
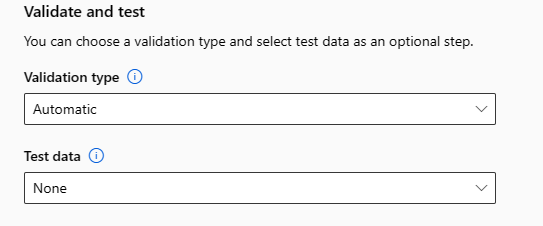
Настройка конструирования признаков
В форме Конструирование признаков можно включить или отключить автоматическое конструирование признаков и настроить его параметры для своего эксперимента. Сведения о том, как открыть эту форму, см. в шаге 10 в разделе Создание и запуск эксперимента.
В следующей таблице приведены сводные данные по настройкам, доступным в данный момент в студии.
| Column | Пользовательская настройка |
|---|---|
| Тип компонента | Изменение типа значения для выбранного столбца. |
| Подстановка | Выбор того, какое значение будет использоваться для подстановки отсутствующих значений в данных. |
Запуск эксперимента и просмотр результатов
Выберите Готово, чтобы запустить эксперимент. Подготовка эксперимента может занять до 10 мин. Выполнение заданий обучения может занять еще 2–3 минуты для завершения работы каждого конвейера. Если вы указали, чтобы создать панель мониторинга RAI для лучшей рекомендуемой модели, это может занять до 40 минут.
Примечание.
Алгоритмы автоматизированного машинного обучения имеют присущую им случайность, которая может вызвать небольшие отклонения в окончательной оценке рекомендованной модели, например в точности. При необходимости автоматическое Машинное обучение также выполняет операции с данными, такие как разбиение на обучающие данные и тестовые данные, разбиение на обучающие и проверочные данные или перекрестная проверка. Поэтому, если вы запускаете эксперимент с одними и теми же настройками конфигурации и основным показателем несколько раз, вы, вероятно, увидите различия в итоговой оценке каждого эксперимента из-за этих факторов.
Просмотр сведений об эксперименте
Откроется экран Сведения о задании на вкладке Сведения. На этом экране отображается сводка по заданию эксперимента, в том числе строка состояния в верхней части рядом с номером задания.
Вкладка Модели содержит список созданных моделей в порядке оценки метрики. По умолчанию модель с наивысшей оценкой, полученной на основе выбранной метрики, будет в верхней части списка. По мере того как задание обучения пытается получить больше моделей, они добавляются в список. Используйте это для быстрого сравнения метрик созданных моделей.
Просмотр сведений о задании обучения
Чтобы просмотреть сведения о задании обучения, откройте детали завершенной модели.
На вкладке "Метрики метрик" можно увидеть диаграммы метрик конкретной модели. Дополнительные сведения о диаграммах.
Здесь также можно найти подробные сведения обо всех свойствах модели вместе с связанным кодом, дочерними заданиями и изображениями.
Просмотр результатов удаленного тестового задания (предварительная версия)
Если вы указали тестовый набор данных или выбрали разделение обучения или теста во время настройки эксперимента в форме проверки и тестирования , автоматизированное машинное обучение автоматически проверяет рекомендуемую модель по умолчанию. В результате автоматизированное машинное обучение вычислит тестовые метрики для оценки качеств рекомендуемой модели и ее прогнозов.
Важно!
Тестирование моделей с помощью тестового набора данных для оценки созданных моделей доступно как предварительная версия функции. Этот возможность является предварительной версией экспериментальной функции и может быть изменена в любое время.
Предупреждение
Эта функция недоступна для следующих сценариев автоматизированного машинного обучения:
- Задачи компьютерного зрения
- Многие модели и обучение прогнозированию иерархических временных рядов (предварительная версия)
- Задачи прогнозирования, в которых активировано использование глубоких нейронных сетей обучения (DNN)
- Задания автоматизированного машинного обучения из локальных вычислений или кластеров Azure Databricks
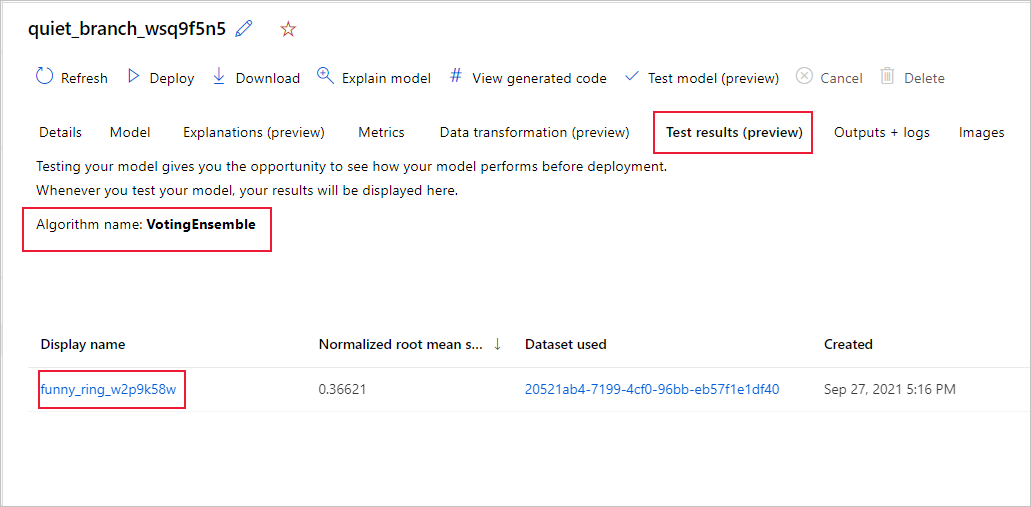
Для просмотра метрик тестового задания рекомендуемой модели выполните указанные ниже действия.
- Перейдите на страницу Модели и выберите наилучшую модель.
- Выберите вкладку Результаты теста (предварительная версия).
- Выберите нужное задание и просмотрите вкладку метрик .
Для просмотра прогнозов тестирования, используемых для вычисления тестовых метрик, выполните следующие действия:
- Прокрутите экран до конца страницы и щелкните ссылку в разделе Набор выходных данных, чтобы открыть набор данных.
- На странице Наборы данных откройте вкладку Обзор, чтобы просмотреть прогнозы из тестового задания.
- Для просмотра и скачивания файла прогноза можно также выбрать вкладку Выходные данные и журналы, развернуть папку Прогнозы и найти файл
predicted.csv.
- Для просмотра и скачивания файла прогноза можно также выбрать вкладку Выходные данные и журналы, развернуть папку Прогнозы и найти файл
Для просмотра и скачивания файла прогноза можно также выбрать вкладку "Выходные данные и журналы", развернуть папку "Прогнозы" и найти файл predictions.csv.
Тестовое задание модели создает файл predictions.csv, который хранится в хранилище данных по умолчанию, созданном с помощью рабочей области. Это хранилище могут видеть все пользователи с одинаковой подпиской. Тестовые задания не рекомендуется использовать для сценариев, если какая-либо информация, используемая для или созданная тестовой задачей, должна оставаться закрытой.
Тестирование существующей модели автоматического машинного обучения (предварительная версия)
Важно!
Тестирование моделей с помощью тестового набора данных для оценки созданных моделей доступно как предварительная версия функции. Этот возможность является предварительной версией экспериментальной функции и может быть изменена в любое время.
Предупреждение
Эта функция недоступна для следующих сценариев автоматизированного машинного обучения:
- Задачи компьютерного зрения
- Многие модели и обучение прогнозированию иерархических временных рядов (предварительная версия)
- Задачи прогнозирования, в которых активировано использование глубоких нейронных сетей обучения (DNN)
- Запуск автоматизированного ML из локальных вычислений или кластеров Azure Databricks
После завершения эксперимента вы можете протестировать модели, созданные автоматизированным машинным обучением. Если вы хотите протестировать другую модель, созданную автоматизированным машинным обучением, а не рекомендуемую модель, это можно сделать, выполнив указанные ниже действия.
Выберите существующее задание автоматизированного машинного обучения.
Откройте вкладку Модели для задания и выберите завершенную модель для тестирования.
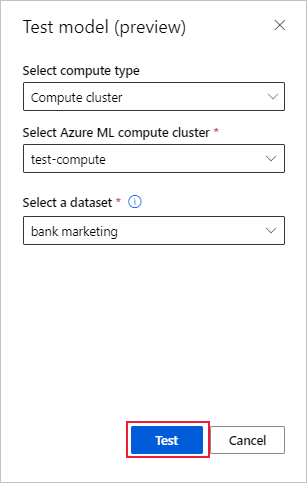
На странице Сведения модели нажмите кнопку Тестовая модель (предварительная версия), чтобы открыть панель Тестовая модель.
На панели Тестовая модель выберите нужный кластер и тестовый набор данных, которые хотите использовать для тестового задания.
Нажмите кнопку Тест. Схема тестового набора данных должна соответствовать учебному набору данных, но целевой столбец является необязательным.
После успешного создания тестового задания модели на странице Сведения появится сообщение об успешном выполнении. Откройте вкладку Результаты теста, чтобы увидеть ход выполнения задания.
Для просмотра результатов тестового задания откройте страницу Сведения и выполните действия, описанные в разделе Просмотр результатов удаленного тестового задания.
Панель мониторинга ответственного искусственного интеллекта (предварительная версия)
Чтобы лучше понять свою модель, вы можете просмотреть различные аналитические сведения о модели с помощью панели мониторинга Ответственного искусственного интеллекта. Она позволяет оценивать и отлаживать лучшую модель автоматизированного машинного обучения. Панель мониторинга ответственного искусственного интеллекта будет оценивать ошибки модели и проблемы справедливости, диагностировать, почему эти ошибки происходят путем оценки данных обучения и (или) тестирования и наблюдения за объяснениями модели. Вместе эти аналитические сведения помогут вам создать доверие с моделью и передать процессы аудита. Не удается создать панели мониторинга ИИ для существующей модели автоматизированного машинного обучения. Он создается только для лучшей рекомендуемой модели при создании нового задания AutoML. Пользователи должны продолжать использовать объяснения модели (предварительная версия) до тех пор, пока поддержка не будет предоставлена для существующих моделей.
Чтобы создать панель мониторинга ответственного искусственного интеллекта для конкретной модели,
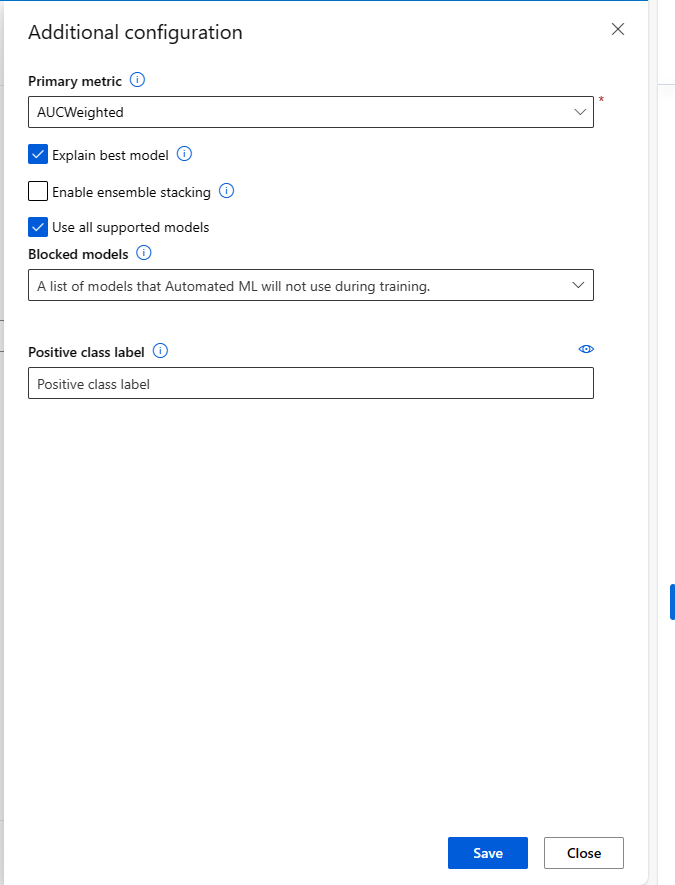
При отправке задания автоматизированного машинного обучения перейдите к разделу "Параметры задачи" на панели навигации слева и выберите параметр "Просмотреть дополнительные параметры конфигурации ".
В новой форме, отображающейся после выбора, выберите пункт "Объяснить лучшую модель" проверка box.
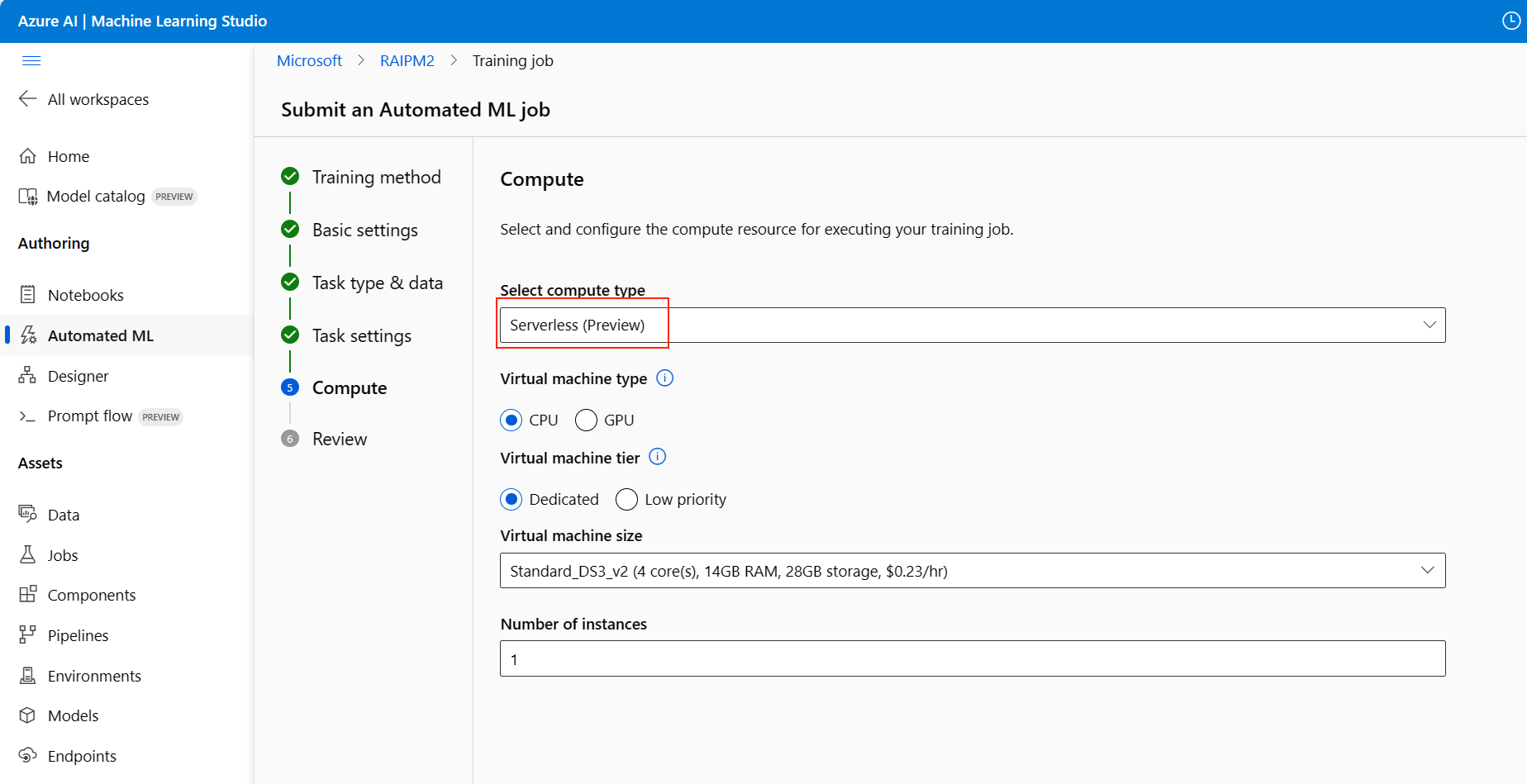
Перейдите на страницу вычислений формы установки и выберите бессерверный параметр для вычислений.
После завершения перейдите на страницу "Модели" задания автоматизированного машинного обучения, которая содержит список обученных моделей. Выберите ссылку панели мониторинга "Просмотр ответственного ИИ":
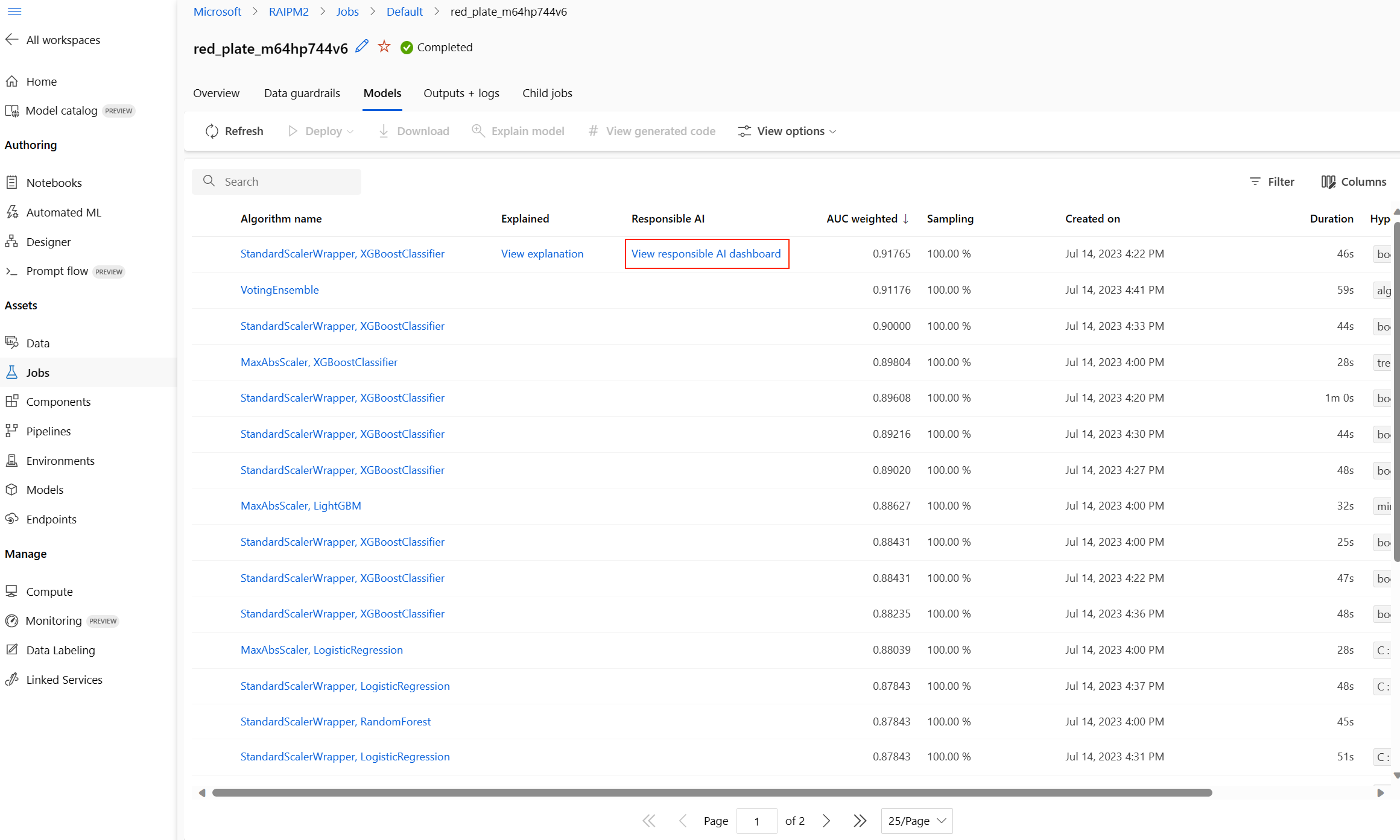
Панель мониторинга ответственного искусственного интеллекта отображается для этой модели, как показано на этом рисунке:
На панели мониторинга вы найдете четыре компонента, активированные для оптимальной модели автоматизированного машинного обучения:
| Компонент | Что показывает компонент? | Как прочитать диаграмму? |
|---|---|---|
| Анализ ошибок | Используйте анализ ошибок при необходимости: Получите глубокое представление о том, как ошибки модели распределяются по набору данных и нескольким измерениям входных данных и функций. Разбиите статистические метрики производительности, чтобы автоматически обнаруживать ошибочные когорты, чтобы сообщить о целевых шагах по устранению рисков. |
Диаграммы анализа ошибок |
| Обзор модели и справедливость | Используйте этот компонент для: Получите глубокое представление о производительности модели в разных типах данных. Ознакомьтесь с проблемами справедливости модели, глядя на метрики неравенства. Эти метрики могут оценивать и сравнивать поведение модели между подгруппами, идентифицированными с точки зрения конфиденциальных (или нечувствительных) функций. |
Общие сведения о модели и диаграммы справедливости |
| Объяснения модели | Используйте компонент объяснения модели для создания понятных для человека описаний прогнозов модели машинного обучения. Глобальные пояснения: например, какие признаки влияют на общее поведение модели предоставления кредита? Местные объяснения: например, почему было одобрено или отклонено заявление о кредите клиента? |
Диаграммы объясняемости модели |
| Анализ данных | Используйте анализ данных при необходимости: изучить статистику набора данных, выбрав различные фильтры, чтобы разделить данные на различные измерения (также называемые когортами); понять процесс распределения набора данных между различными когортами и группами возможностей; Определите, являются ли ваши выводы, связанные с справедливостью, анализом ошибок и причинностью (производными от других компонентов панели мониторинга), результатом распространения набора данных. Определите, в каких областях необходимо собирать больше данных для устранения ошибок, возникающих при возникновении проблем с представлением, шумом меток, шумом признаков, предвзятостью меток и аналогичными факторами. |
Диаграммы Обозреватель данных |
- Кроме того, можно создать когорты (подгруппы точек данных, которые совместно используют указанные характеристики), чтобы сосредоточить анализ каждого компонента на разных когортах. Имя когорты, применяемой в данный момент к панели мониторинга, всегда отображается в левом верхнем углу панели мониторинга. Представление по умолчанию на панели мониторинга — это весь набор данных с названием "Все данные" (по умолчанию). Дополнительные сведения о глобальном контроле панели мониторинга см. здесь.
Изменение и отправка заданий (предварительная версия)
Важно!
Возможность копирования, изменения и отправки нового эксперимента на основе существующего доступна как предварительная версия функции. Этот возможность является предварительной версией экспериментальной функции и может быть изменена в любое время.
Автоматизированное машинное обучение позволяет создать новый эксперимент, используя параметры уже существующего, с помощью кнопки Изменить и отправить в пользовательском интерфейсе студии.
Эта функция доступна только для тех экспериментов, которые инициируются из пользовательского интерфейса студии, и требует, чтобы схема данных для нового эксперимента соответствовала схеме исходного эксперимента.
Кнопка "Изменить и отправить " открывает мастер создания нового задания автоматизированного машинного обучения с предварительно заполненными параметрами данных, вычислений и экспериментов. Вы можете просматривать все формы и изменять настройки, если это потребуется для нового эксперимента.
Развертывание модели
После того как у вас есть лучшая модель, пришло время развернуть ее как веб-службу для прогнозирования новых данных.
Совет
Если вы хотите развернуть модель, созданную с помощью пакета с помощью automl пакета SDK для Python, необходимо зарегистрировать модель) в рабочей области.
После регистрации модели найдите ее в студии, выбрав Модели на левой панели. После открытия модели можно нажать кнопку Развернуть в верхней части экрана, а затем выполнить инструкции, описанные в шаге 2 раздела Развертывание модели.
Автоматизированное машинное обучение позволяет с легкостью развернуть модель без написания кода.
Доступно несколько вариантов развертывания.
Вариант 1. Разверните наилучшую модель в соответствии с заданными критериями метрики.
- После завершения эксперимента перейдите на страницу родительского задания, выбрав Задание 1 в верхней части экрана.
- Выберите модель, указанную в разделе Сводка по лучшей модели.
- Нажмите Развернуть в верхнем левом углу окна.
Вариант 2. Развертывание определенной итерации модели из этого эксперимента.
- Выберите нужную модель на вкладке Модели.
- Нажмите Развернуть в верхнем левом углу окна.
Заполните область Развернуть модель, как показано ниже.
Поле Значение Имя. Введите уникальное имя развертывания. Description Введите описание, чтобы лучше понять, для чего предназначено это развертывание. Тип вычисления Выберите тип конечной точки для развертывания: Azure Kubernetes Service (AKS) или Экземпляр контейнера Azure (ACI). Имя вычислительной среды Применяется только к AKS: выберите имя кластера AKS, в котором вы хотите развернуть. Включение проверки подлинности Выберите этот параметр, чтобы разрешить проверку подлинности на основе токенов или на основе ключей. Использовать настраиваемые ресурсы развертывания Включите эту возможность, если хотите отправить собственный скрипт оценки и файл среды. Если нет, автоматизированное машинное обучение предоставит вам эти ресурсы по умолчанию. Узнайте больше о скриптах оценки. Важно!
Имена файлов должны быть длиной не более 32 символов, а также начинаться и заканчиваться буквой или цифрой. Они могут включать в себя дефисы, символы подчеркивания, точки, буквы и цифры. Пробелы недопустимы.
В меню Дополнительно содержатся признаки развертывания по умолчанию, например коллекция данных и параметры использования ресурсов. Если вы хотите переопределить эти значения по умолчанию, это можно сделать в данном меню.
Выберите Развернуть. Развертывание может занять около 20 минут. После начала развертывания появится вкладка Сводка по модели. Сведения о ходе развертывания см. в разделе Состояние развертывания.
Теперь у вас есть рабочая веб-служба для создания прогнозов! Вы можете проверить прогнозы, запросив соответствующую услугу с помощью встроенной функции поддержки Машинного обучение Azure в Power BI.