Учебник. конструктор — обучение модели регрессии без кода
Обучение модели линейной регрессии, которая прогнозирует цены на автомобили, с помощью конструктора Машинного обучения Azure. Это руководство представляет собой первую часть серии, состоящей из двух частей.
В этом учебнике используется конструктор Машинного обучения Azure. Дополнительные сведения см. в статье Что такое конструктор Машинного обучения Azure.
Примечание.
Конструктор поддерживает два типа компонентов, классические предварительно созданные компоненты (версии 1) и пользовательские компоненты (версия 2). Эти два типа компонентов несовместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты, главным образом для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют упаковывать собственный код в качестве компонента. Она поддерживает совместное использование компонентов между рабочими областями и простой разработки в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов мы настоятельно рекомендуем использовать настраиваемый компонент, совместимый с AzureML версии 2 и сохраняющий получение новых обновлений.
Эта статья относится к классическим предварительно созданным компонентам и не совместим с CLI версии 2 и пакетом SDK версии 2.
В первой части руководства вы узнаете, как:
- Создание нового конвейера.
- Импорт данных.
- Подготовка данных.
- обучить модель машинного обучения;
- оценить модель машинного обучения.
Во второй части этого учебника вы узнаете, как развернуть модель в виде конечной точки вывода в реальном времени и прогнозировать цену любого автомобиля, исходя из отправленных технических характеристик.
Примечание.
Готовая версия этого руководства доступна в качестве примера конвейера.
Вы можете найти ее в конструкторе в рабочей области. В разделе "Новый конвейер" выберите пример 1 — регрессия: прогнозирование цен на автомобили (базовый).
Важно!
Если вы не видите графические элементы, упомянутые в этом документе, такие как кнопки в студии или конструкторе, возможно, у вас нет соответствующих разрешений для рабочей области. Обратитесь к администратору подписки Azure, чтобы убедиться, что вам предоставлен правильный уровень доступа. Дополнительные сведения см. в статье Управление доступом к рабочей области Машинного обучения Azure.
Создание нового конвейера
Конвейеры Машинного обучения Azure объединяют несколько этапов машинного обучения и обработки данных в одном ресурсе. Конвейеры позволяют организовывать, администрировать и повторно использовать сложные рабочие процессы машинного обучения с несколькими проектами и пользователями.
Чтобы создать конвейер Машинного обучения Azure, вам потребуется рабочая область Машинного обучения Azure. В этом разделе вы узнаете, как создать оба этих ресурса.
Создание рабочей области
Чтобы использовать конструктор, вам потребуется рабочая область Машинного обучения Azure. Рабочая область — это ресурс верхнего уровня для Машинного обучения Azure, который обеспечивает централизованное расположение для работы со всеми артефактами, созданными в Машинном обучении Azure. Инструкции по созданию рабочей области см. в разделе "Создание ресурсов рабочей области".
Примечание.
Если рабочая область использует виртуальную сеть, для использования конструктора необходимо выполнить дополнительные действия по настройке. Дополнительные сведения см. в статье Использование Студии машинного обучения Azure в виртуальной сети Azure.
Создание конвейера
Примечание.
Конструктор поддерживает два типа компонентов, классические предварительно созданные компоненты и пользовательские компоненты. Эти два типа компонентов несовместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют предоставлять собственный код в качестве компонента. При этом поддерживается совместное использование рабочих областей и удобная разработка в интерфейсах Studio, CLI и пакетов SDK.
Эта статья относится к классическим предварительно созданным компонентам.
Войдите на сайт ml.azure.com и выберите рабочую область, с которой хотите работать.
Выбор конструктора ->классический предварительно созданный
Выберите " Создать конвейер" с помощью классических предварительно созданных компонентов.
Щелкните значок карандаша рядом с автоматически созданным именем проекта конвейера, переименуйте его в прогноз цен на автомобиль. Имя не должно быть уникальным.

Импорт данных
В этом конструкторе есть несколько примеров наборов данных, с которыми можно поэкспериментировать. Для этого урока используйте Automobile price data (Raw) (Данные о ценах на автомобили (необработанные)).
Слева на холсте конвейера расположена палитра наборов данных и компонентов. Выберите компонент ->Пример данных.
Выберите набор данных Automobile price data (raw) (Данные о ценах на автомобили (необработанные)) и перетащите его на холст.

Визуализация данных
Вы можете визуализировать данные, чтобы изучить набор данных, который вы будете использовать.
Щелкните правой кнопкой мыши Automobile price data (Raw) (Данные о ценах на автомобили (необработанные)) и выберите пункт Просмотр данных.
Щелкните любой столбец в окне данных, чтобы просмотреть сведения о нем.
Каждая строка представляет один автомобиль, а переменные, обозначающие их характеристики, представлены в виде столбцов. В этом наборе данных содержится 205 строк и 26 столбцов.
Подготовка данных
Обычно требуется предварительная обработка набора данных перед его анализом. Возможно, вы заметили некоторые пропущенные значения при проверке набора данных. Чтобы модель смогла правильно проанализировать данные, необходимо очистить эти недостающие значения.
Удаление столбца
При обучении модели необходимо что-то сделать с отсутствующими данными. В нашем примере в столбце normalized-losses (Нормированные потери) не хватает многих значений. Поэтому исключите весь этот столбец из модели.
В палитре наборов данных и компонентов слева от холста щелкните " Компонент " и найдите компонент "Выбор столбцов" в компоненте набора данных.
Щелкните и перетащите компонент Select Columns in Dataset (Выбор столбцов в наборе данных) на холст. Перетащите компонент под компонент наборов данных.
Соедините набор данных Automobile price data (Raw) (Данные о ценах на автомобили (необработанные)) с компонентом Select Columns in Dataset (Выбор столбцов в наборе данных). Выполните действие перетаскивания из порта вывода набора данных, который представляет собой маленький круг в нижней части набора данных на холсте, до порта входа Select Columns in Dataset (Выбор столбцов в наборе данных), который имеет форму маленького круга в верхней части компонента.
Совет
Присоединяя выходной порт одного компонента ко входному порту другого, вы создаете поток данных через конвейер.
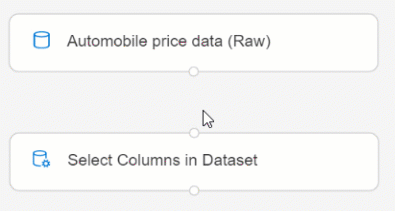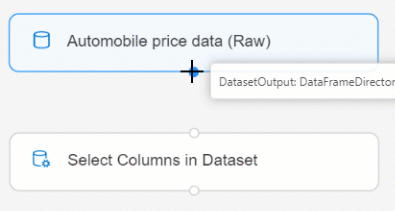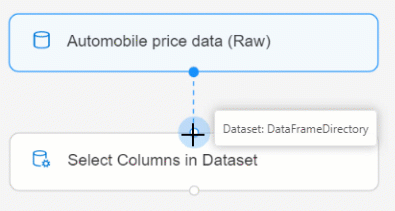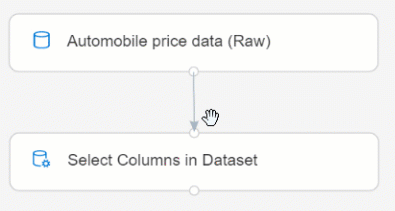
Выберите компонент Select Columns in Dataset (Выбор столбцов в наборе данных).
Щелкните значок стрелки под Параметры справа от холста, чтобы открыть область сведений о компоненте. Кроме того, можно дважды щелкнуть компонент выбора столбцов в наборе данных, чтобы открыть область сведений.
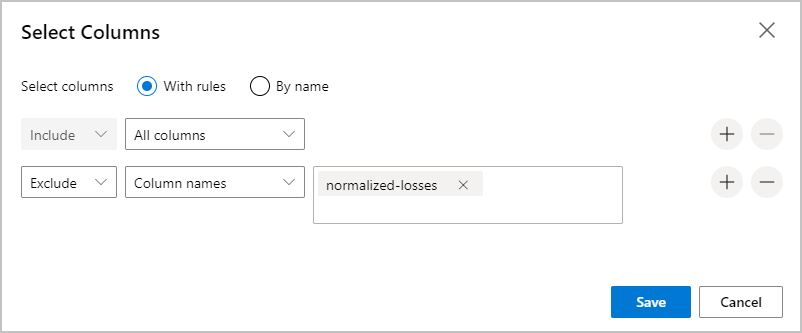
Выберите "Изменить столбец " справа от области.
Разверните раскрывающийся список Имена столбцов рядом с пунктом Включить и выберите Все столбцы.
Щелкните +, чтобы добавить новое правило.
В раскрывающемся списке выберите Исключить и щелкните Имена столбцов.
Введите normalized-losses (Нормализованные потери) в текстовое поле.
Нажмите кнопку Сохранить внизу справа, чтобы закрыть средство выбора столбцов.
В области сведений о компоненте набора данных выберите столбцы, разверните сведения о узле.
Выберите текстовое поле "Комментарий " и введите "Исключить нормализованные потери".
На графике будут показаны комментарии, которые помогут организовать конвейер.
Очистка недостающих данных
В наборе данных после удаления столбца normalized-losses по-прежнему отсутствует много значений. Вы можете устранить их, применив компонент Clean Missing Data (Удаление недостающих данных).
Совет
Удаление недостающих значений из входных данных — необходимое условие для использования большинства компонентов в конструкторе.
В палитре наборов данных и компонентов слева от холста нажмите кнопку "Компонент " и найдите компонент "Чистые отсутствующие данные ".
Перетащите компонент очистки недостающих данных на холст конвейера. Соедините его с компонентом выбора столбцов в наборе данных.
Выберите компонент Clean Missing Data (Очистка недостающих данных).
Щелкните значок стрелки под Параметры справа от холста, чтобы открыть область сведений о компоненте. Кроме того, можно дважды щелкнуть компонент "Очистить отсутствующие данные ", чтобы открыть область сведений.
Выберите "Изменить столбец " справа от области.
В открывшемся окне Columns to be cleaned (Столбцы для очистки) разверните раскрывающееся меню рядом с параметром Включить. Выберите Все столбцы.
Выберите Сохранить
В области сведений о компоненте "Чистые отсутствующие данные" в разделе "Очистка" выберите "Удалить всю строку".
В области сведений о компоненте "Чистые отсутствующие данные" разверните сведения о узле.
Выберите текстовое поле "Комментарий " и введите "Удалить отсутствующие строки значений".
Теперь конвейер должен выглядеть примерно так:
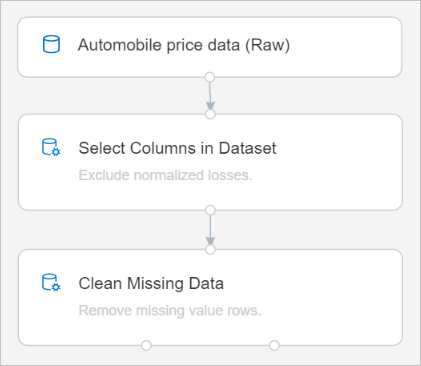
Обучение модели машинного обучения
Теперь, когда у вас есть компоненты для обработки данных, можно настроить обучающие компоненты.
Вам нужно предсказать цену, которая является числом, поэтому используйте алгоритм регрессии. В этом примере используется модель линейной регрессии.
Разделение данных
Разделение данных — это обычная задача в машинном обучении. Данные будут разделены на два отдельных набора. Один набор данных обучает модель, а другой проверяет, насколько хорошо выполнена модель.
В палитре наборов данных и компонентов слева от холста щелкните " Компонент " и найдите компонент split Data .
Перетащите компонент Split Data (Разделение данных) на холст конвейера.
Присоедините левый порт компонента Clean Missing Data (Очистка недостающих данных) к компоненту Split Data (Разделение данных).
Важно!
Убедитесь, что левый выходной порт очистки отсутствующих данных подключается к разделенным данным. Левый порт содержит очищенные данные. Правый порт содержит остальные данные.
Выберите компонент Split Data (Разделение данных).
Щелкните значок стрелки под Параметры справа от холста, чтобы открыть область сведений о компоненте. Кроме того, можно дважды щелкнуть компонент разделения данных , чтобы открыть область сведений.
В области сведений о разбиения данных установите значение "Доля строк" в первом выходном наборе данных значение 0,7.
Таким образом, мы применим 70 % данных для обучения модели и 30 % для тестирования. 70-процентный набор данных будет доступен по левому порту вывода. Остальные данные доступны через правый порт вывода.
В области сведений о разбиения данных разверните сведения о узле.
Выберите текстовое поле "Комментарий " и введите разделите набор данных на набор обучения (0.7) и тестовый набор (0.3).
Обучение модели
Обучите модель, передав ей набор данных цен. Алгоритм конструирует модель, объясняющую связь между признаками и ценами, представленными в данных обучения.
В палитре наборов данных и компонентов слева от холста щелкните " Компонент " и найдите компонент линейной регрессии .
Перетащите компонент линейной регрессии на холст конвейера.
В палитре наборов данных и компонентов слева от холста щелкните "Компонент" и найдите компонент "Обучение модели".
Перетащите компонент "Обучение модели" на холст конвейера.
Подключите выход компонента Линейная регрессия к левому входу компонента Обучение модели.
Подключите выход данных для обучения (левый порт) компонента разделения данных к правому входу компонента обучения модели.
Важно!
Убедитесь, что левый выходной порт разделенных данных подключается к модели обучения. Левый порт содержит набор для обучения. Правый порт содержит набор для проверки.
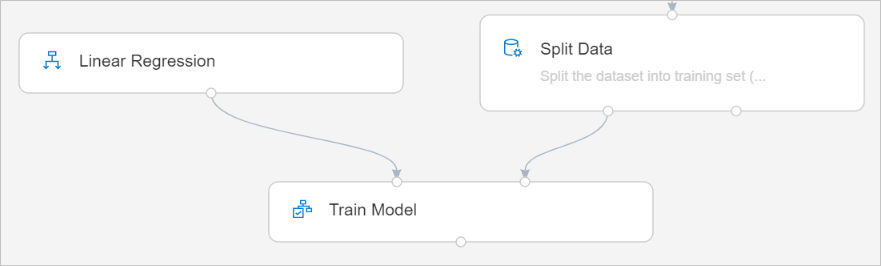
Выберите компонент Обучение модели.
Щелкните значок стрелки под Параметры справа от холста, чтобы открыть область сведений о компоненте. Кроме того, можно дважды щелкнуть компонент "Обучение модели ", чтобы открыть область сведений.
Выберите "Изменить столбец " справа от области.
В появившемся окне столбца метки разверните раскрывающееся меню и выберите имена столбцов.
В текстовом поле введите price (цена), чтобы указать значение, которое будет прогнозировать модель.
Важно!
Убедитесь, что вы ввели именно имя столбца. Не пишите price (цена) прописными буквами.
Теперь конвейер будет выглядеть следующим образом:
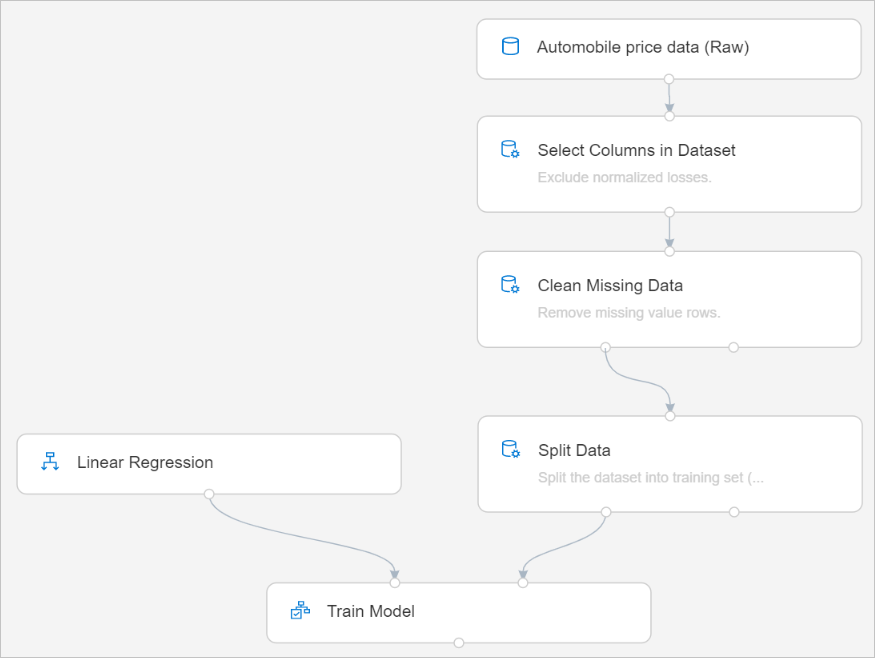
Добавление компонента "Score Model" (Оценка модели)
Когда вы обучите модель, использовав 70 % данных, ее можно будет применить для оценки оставшихся 30 % данных и проверить, насколько хорошо она работает.
В палитре наборов данных и компонентов слева от холста щелкните "Компонент" и найдите компонент "Оценка модели".
Перетащите компонент "Оценка модели" на холст конвейера.
Соедините выход компонента Train Model (Обучение модели) с левым входным портом компонента Score Model (Оценка модели). Соедините выход тестовых данных (правый порт) компонента Split Data (Разделение данных) с правым входным портом Score Model (Оценка модели).
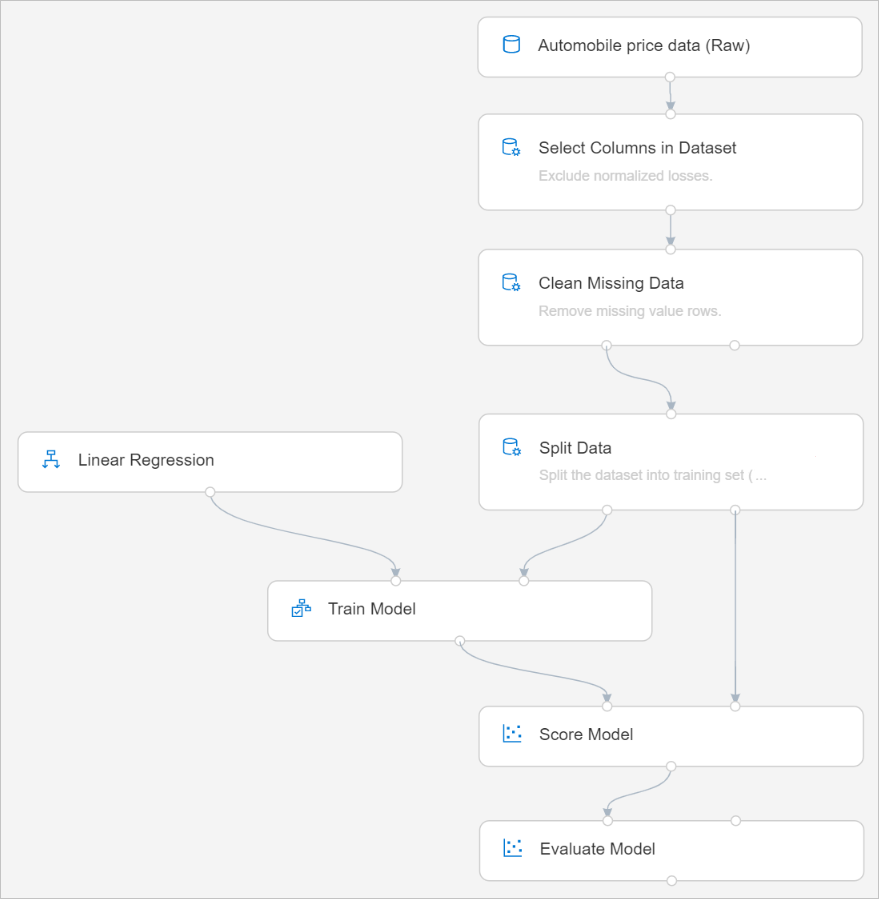
Добавление компонента "Evaluate Model" (Анализ модели)
Используйте компонент Evaluate Model (Анализ модели), чтобы узнать, насколько хорошо модель оценивает проверочный набор данных.
В палитре наборов данных и компонентов слева от холста щелкните "Компонент" и найдите компонент "Оценка модели".
Перетащите компонент "Оценка модели" на холст конвейера.
Присоедините выход компонента Score Model (Оценка модели) к левому входному порту компонента Evaluate Model (Анализ модели).
Готовый вариант конвейера должен выглядеть примерно так:
Отправить конвейер
Нажмите кнопку "Настроить" и " Отправить " в правом верхнем углу, чтобы отправить конвейер.

Затем вы увидите пошаговый мастер, следуйте инструкциям мастера, чтобы отправить задание конвейера.


На шаге "Основы" можно настроить эксперимент, отображаемое имя задания, описание задания и т. д.
На шаге входных и выходных данных можно назначить значение входным и выходным данным, которые повышаются до уровня конвейера. В этом примере он будет пустым, так как мы не повысили уровень входных и выходных данных до уровня конвейера.
В параметрах среды выполнения можно настроить хранилище данных по умолчанию и вычисления по умолчанию для конвейера. Это хранилище или вычисление по умолчанию для всех компонентов в конвейере. Однако при явном задании другого вычислительного или хранилища данных для компонента система учитывает параметр уровня компонента. В противном случае используется значение по умолчанию.
Шаг проверки и отправки — это последний шаг для проверки всех параметров перед отправкой. Мастер запоминает последнюю конфигурацию, если вы когда-либо отправляете конвейер.
После отправки задания конвейера вверху появится сообщение со ссылкой на сведения о задании. Эту ссылку можно выбрать, чтобы просмотреть сведения о задании.

Просмотр оцененных меток
На странице сведений о задании можно проверить состояние, результаты и журналы задания конвейера.
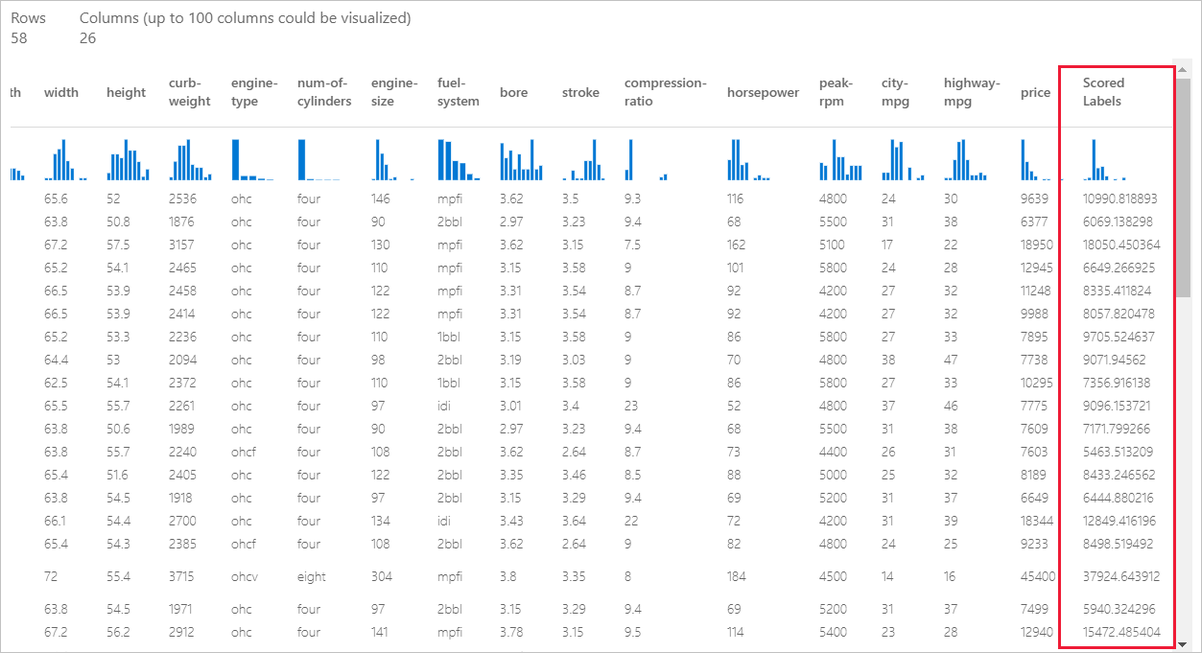
После завершения задания можно просмотреть результаты задания конвейера. Сначала просмотрите прогнозы, созданные моделью регрессии.
Щелкните правой кнопкой мыши компонент Score Model (Оценка модели) и выберите Просмотр данных>Оцененный набор данных, чтобы просмотреть его выходные данные.
Здесь можно просмотреть прогнозируемые цены и фактические цены из тестовых данных.
Анализ моделей
Используйте модуль Evaluate Model (Анализ модели), чтобы на тестовом наборе данных проверить, насколько хорошо работает обученная модель.
- Щелкните правой кнопкой мыши компонент Evaluate Model (Анализ модели) и выберите Просмотр данных>Результаты оценки, чтобы просмотреть его выходные данные.
Для вашей модели будет выведена следующая статистика.
- Средняя абсолютная ошибка (MAE): среднее значение абсолютных ошибок. Погрешность — это разница между спрогнозированным и фактическим значением.
- Среднеквадратичное отклонение (RMSE) — квадратный корень из среднего значения возведенных в квадрат арифметических отклонений спрогнозированных значений тестового набора данных.
- Относительное арифметическое отклонение— среднее арифметическое отклонение по отношению к абсолютной разнице между фактическими значениями и средним арифметическим всех фактических значений.
- Относительное среднеквадратичное отклонение— среднее арифметическое среднеквадратичных отклонений по отношению к абсолютной разнице между фактическими значениями и средним арифметическим всех фактических значений.
- Коэффициент определения: также известное как квадратное значение R, эта статистическая метрика указывает, насколько хорошо модель соответствует данным.
Чем меньше значение каждой погрешности, тем лучше. Меньшее значение указывает на то, что прогноз ближе к фактическим значениям. Что касается показателя коэффициента смешанной корреляции, чем ближе его значение к единице (1,0), тем точнее прогноз.
Очистка ресурсов
Пропустите этот раздел, если хотите продолжить со 2 части руководства по развертыванию модели машинного обучения с помощью конструктора (предварительная версия).
Важно!
Созданные ресурсы можно использовать в качестве необходимых компонентов для других учебников и статей с практическими рекомендациями по Машинному обучению Azure.
Удаление всех ресурсов
Если вы не планируете использовать созданные ресурсы, удалите всю группу ресурсов, чтобы с вас не взималась плата.
На портале Azure слева выберите Группы ресурсов.

В списке выберите созданную группу ресурсов.
Выберите команду Удалить группу ресурсов.
При удалении группы ресурсов будут также удалены все ресурсы, созданные в конструкторе.
Удаление отдельных ресурсов
В конструкторе, в котором вы создали эксперимент, удалите отдельные ресурсы, выбрав их и нажав кнопку Удалить.
Созданный вами целевой объект вычислений автоматически масштабируется до нуля узлов, когда он не используется. Это действие предпринимается для снижения расходов. Чтобы удалить целевой объект вычислений, сделайте следующее:

Вы можете отменить регистрацию наборов данных в рабочей области. Для этого выберите каждый набор данных и щелкните Отменить регистрацию.

Чтобы удалить набор данных, перейдите к учетной записи хранения на портале Azure или в приложении "Обозреватель службы хранилища Azure", а затем вручную удалите эти ресурсы.
Следующие шаги
Из второй части вы узнаете, как развернуть готовую модель в конечной точке для прогнозирования в реальном времени.
Tutorial: Deploy a machine learning model with the visual interface (Руководство. Развертывание модели машинного обучения с помощью графического интерфейса)