Выполнение скриптов Python
Важно!
Поддержка Студии машинного обучения (классической) будет прекращена 31 августа 2024 г. До этой даты рекомендуется перейти на Машинное обучение Azure.
Начиная с 1 декабря 2021 года вы не сможете создавать новые ресурсы Студии машинного обучения (классической). Существующие ресурсы Студии машинного обучения (классическая версия) можно будет использовать до 31 августа 2024 г.
- См. сведения о перемещении проектов машинного обучения из ML Studio (классической) в Машинное обучение Azure.
- См. дополнительные сведения о Машинном обучении Azure.
Поддержка документации по ML Studio (классической) прекращается, а сама документация может не обновляться в будущем.
Выполняет скрипт Python из эксперимента Машинное обучение
Категория: Python языковые модули
Примечание
Область применения: только Машинное обучение Studio (классическая версия)
Подобные модули перетаскивания доступны в конструкторе машинного обучения Azure.
Обзор модуля
В этой статье описывается использование модуля «Выполнение Python скрипта» в Машинное обучение Studio (классическая модель) для выполнения кода Python. Дополнительные сведения об архитектуре и принципах проектирования Python в Студии (классической) см. в следующей статье.
С помощью Python можно выполнять задачи, которые в настоящее время не поддерживаются существующими модулями Студии (классической), такими как:
- Визуализация данных с помощью
matplotlib - Использование библиотек Python для перечисления наборов данных и моделей в рабочей области
- Чтение, загрузка и обработка данных из источников, не поддерживаемых модулем импорта данных
Машинное обучение Studio (классическая модель) использует распределение Anaconda Python, включающее множество общих служебных программ для обработки данных.
Использование скрипта выполнения Python
Модуль «Выполнение Python скрипта» содержит пример кода Python, который можно использовать в качестве отправной точки. Чтобы настроить модуль «Выполнение Python скрипта», укажите набор входных данных и Python код для выполнения в текстовом поле скрипта Python.
Добавьте модуль «Выполнение Python скрипта» в эксперимент.
Прокрутите страницу до нижней части области "Свойства"и выберите версию Python версии Python библиотек и среды выполнения для использования в скрипте.
- Распространение Anaconda 2.0 для Python 2.7.7
- Дистрибутив Anaconda 4.0 для Python 2.7.11
- Дистрибутив Anaconda 4.0 для Python 3.5 (по умолчанию)
Перед вводом нового кода рекомендуется задать версию. Если вы измените версию позже, появится запрос на подтверждение изменения.
Важно!
Если в эксперименте используется несколько экземпляров модуля «Выполнение Python скрипта», необходимо выбрать одну версию Python для всех модулей в эксперименте.
Добавьте и подключитесь к набору данных Dataset1 любые наборы данных из Студии (классическая модель), которые вы хотите использовать для ввода. Сошлитесь на этот набор данных в скрипте Python как DataFrame1.
Использование набора данных является необязательным, если вы хотите создать данные с помощью Python или использовать Python код для импорта данных непосредственно в модуль.
Этот модуль поддерживает добавление второго набора данных Студии (классической) в Dataset2. Сошлитесь на этот набор данных в скрипте Python как DataFrame2.
Наборы данных, хранящиеся в Студии (классическая модель), автоматически преобразуются в pandas data.frames при загрузке с помощью этого модуля.
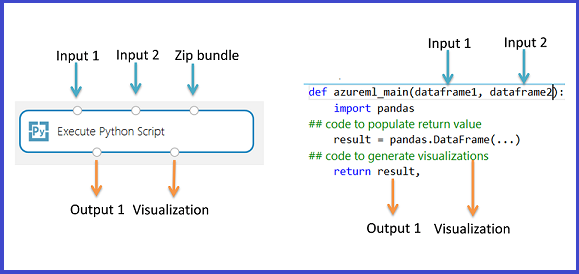
Чтобы включить новые пакеты или код Python, добавьте ZIP-файл, содержащий эти настраиваемые ресурсы в пакете скриптов. Входные данные в пакет скриптов должны быть zip-файлом, уже переданным в рабочую область. Дополнительные сведения о подготовке и отправке этих ресурсов см. в разделе "Распаковка zippped Data".
Любой файл, содержащийся в отправленном zip-архиве, можно использовать во время выполнения эксперимента. Если архив содержит структуру каталогов, структура сохраняется, но необходимо добавить каталог , называемый src , в путь.
В текстовом поле скрипт Python введите или вставьте допустимый скрипт Python.
Текстовое поле Python скрипта предварительно заполняется некоторыми инструкциями в комментариях и примером кода для доступа к данным и вывода. Этот код необходимо изменить или заменить. Обязательно соблюдайте Python соглашения о отступах и регистре.
- Скрипт должен содержать функцию с именем
azureml_mainв качестве точки входа для этого модуля. - Функция точки входа может содержать до двух входных аргументов:
Param<dataframe1>Param<dataframe2> - Zippped-файлы, подключенные к третьему порту ввода, распакуются и хранятся в каталоге,
.\Script Bundleкоторый также добавляется в Pythonsys.path.
Таким образом, если ZIP-файл содержится
mymodule.py, импортируйте его с помощьюimport mymodule.- Один набор данных можно вернуть в Студию (классическую), которая должна быть последовательностью типа
pandas.DataFrame. Вы можете создавать другие выходные данные в коде Python и записывать их непосредственно в службу хранилища Azure или создавать визуализации с помощью устройства Python.
- Скрипт должен содержать функцию с именем
Запустите эксперимент или выберите модуль и нажмите кнопку "Выполнить", чтобы запустить только скрипт Python.
Все данные и код загружаются на виртуальную машину и выполняются с помощью указанной среды Python.
Результаты
Модуль возвращает следующие выходные данные:
Набор данных результатов. Результаты любых вычислений, выполняемых внедренным Python кодом, должны быть предоставлены в виде pandas data.frame, который автоматически преобразуется в формат набора данных Машинное обучение, чтобы можно было использовать результаты с другими модулями в эксперименте. Модуль ограничен одним набором данных в качестве выходных данных. Дополнительные сведения см. в таблице данных.
Устройство Python. Обеспечивает поддержку вывода на консоль и отображения графики PNG с помощью интерпретатора Python.
Присоединение ресурсов скриптов
Модуль «Выполнение Python скрипта» поддерживает произвольные файлы скриптов Python в качестве входных данных, если они подготавливаются заранее и передаются в рабочую область в составе файла .ZIP.
Отправка ZIP-файла, содержащего код Python в рабочую область
В области эксперимента Машинное обучение Studio (классическая модель) щелкните наборы данных и нажмите кнопку "Создать".
Выберите параметр "Из локального файла".
В диалоговом окне "Отправка нового набора данных" щелкните раскрывающийся список для выбора типа нового набора данных и выберите параметр Zip-файла (.zip).
Нажмите кнопку "Обзор", чтобы найти ZIP-файл.
Введите новое имя для использования в рабочей области. Имя, присвоенное набору данных, становится именем папки в рабочей области, в которой извлекаются содержащиеся файлы.
После отправки zip-пакета в Студию (классическая модель) убедитесь, что zippped-файл доступен в списке сохраненных наборов данных , а затем подключите набор данных к порту ввода пакета скриптов .
Все файлы, содержащиеся в ZIP-файле, доступны для использования во время выполнения: например, примеры данных, скрипты или новые пакеты Python.
Если zip-файл содержит библиотеки, которые еще не установлены в Машинное обучение Studio (классическая версия), необходимо установить пакет библиотеки Python как часть пользовательского скрипта.
Если имеется структура каталогов, она сохраняется. Однако необходимо изменить код, чтобы добавить каталог src в путь.
Отладка кода Python
Модуль «Выполнение Python скрипта» лучше всего работает, если код был факторирован как функция с четко определенными входными и выходными данными, а не последовательностью слабо связанных исполняемых инструкций.
Этот модуль Python не поддерживает такие функции, как Intellisense и отладка. Если модуль завершается сбоем во время выполнения, можно просмотреть некоторые сведения об ошибке в журнале вывода модуля. Однако полная трассировка стека Python недоступна. Поэтому мы рекомендуем пользователям разрабатывать и отлаживать свои Python скрипты в другой среде, а затем импортировать код в модуль.
Некоторые распространенные проблемы, которые можно найти:
Проверьте типы данных в кадре данных, из
azureml_mainкоторый вы возвращаетесь. Ошибки могут возникать, если столбцы содержат типы данных, отличные от числовых типов и строк.Удалите значения NA из набора данных, используя
dataframe.dropna()при экспорте из скрипта Python. При подготовке данных используйте модуль "Чистые отсутствующие данные ".Проверьте внедренный код на наличие ошибок отступа и пробелов. Если появляется ошибка "IndentationError: ожидается отступ блока", ознакомьтесь со следующими ресурсами:
Известные ограничения
Среда выполнения Python изолирована и не разрешает доступ к сети или локальной файловой системе постоянным образом.
Все файлы, сохраненные локально, изолированы и удаляются после завершения выполнения модуля. С помощью кода Python нельзя получить доступ к большинству каталогов на компьютере, на котором он выполняется, за исключением текущего каталога и его подкаталогов.
При предоставлении zip-файла в качестве ресурса файлы копируются из рабочей области в пространство выполнения эксперимента, распаковываются и используются. Копирование и распаковка ресурсов может использовать память.
Модуль может выводить один кадр данных. Невозможно вернуть произвольные Python объекты, такие как обученные модели, непосредственно обратно в среду выполнения Студии (классическая модель). Однако объекты можно записывать в хранилище или в рабочую область. Другой вариант — сериализация
pickleнескольких объектов в массив байтов, а затем возврат массива внутри кадра данных.
Примеры
Примеры интеграции скриптов Python с экспериментами Студии (классической) см. в следующих ресурсах в коллекции ИИ Azure:
- Выполнение скрипта Python. Используйте разметку текста, парадигматический анализ и другую обработку естественного языка с помощью модуля «Выполнение Python скрипта».
- Пользовательские скрипты R и Python в Azure ML. Пошаговые инструкции по добавлению пользовательского кода a (R или Python), обработке данных и визуализации результатов.
- Анализ данных PyPI для определения Python 3 поддержки: оцените точку, когда спрос на Python 3 outstrips, что для Python 2.7 с помощью Python.