Выбор параметров для оптимизации алгоритмов в Студии машинного обучения (классическая модель)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Студия машинного обучения (классическая)
Студия машинного обучения (классическая)  Машинное обучение Azure
Машинное обучение Azure
Важно!
Поддержка Студии машинного обучения (классической) будет прекращена 31 августа 2024 г. До этой даты рекомендуется перейти на Машинное обучение Azure.
Начиная с 1 декабря 2021 года вы не сможете создавать новые ресурсы Студии машинного обучения (классической). Существующие ресурсы Студии машинного обучения (классическая версия) можно будет использовать до 31 августа 2024 г.
- См. сведения о переносе проектов машинного обучения из Студии машинного обучения (классическая версия) в Машинное обучение Azure.
- См. дополнительные сведения о Машинном обучении Azure.
Прекращается поддержка документации по Студии машинного обучения (классическая версия). В будущем она может не обновляться.
В этой статье содержится информация о выборе правильного набора гиперпараметров для алгоритма в Студии машинного обучения (классическая). В большинстве алгоритмов машинного обучения есть параметры, которые необходимо настроить. Например, это требуется сделать при обучении модели. Эффективность обученной модели зависит от выбранных для нее параметров. Процесс определения оптимального набора параметров называется выбором модели.
Выбор модели осуществляется разными способами. В машинном обучении чаще всего используется перекрестная проверка, которая является одним из широко используемых методов выбора модели, — это механизм выбора модели по умолчанию в Студии машинного обучения (классическая). Так как в Студии машинного обучения (классическая) поддерживаются языки R и Python, всегда можно реализовать свой механизм выбора модели, используя либо R, либо Python.
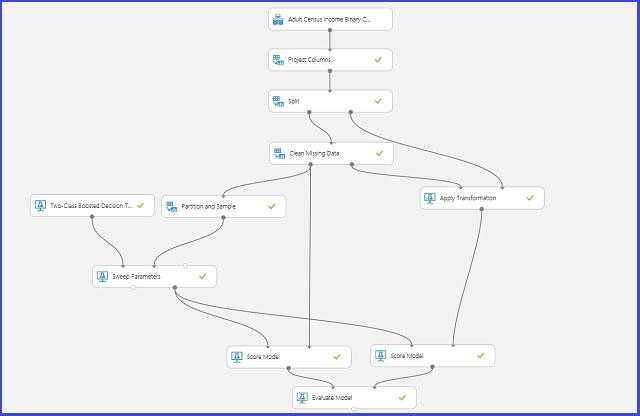
Оптимальный набор параметров подбирается в четыре этапа.
- Определение пространства параметров. Сначала мы определяем точные значения параметров, которые будут учитываться алгоритмом.
- Определение параметров перекрестной проверки. Затем нам нужно определить, как будут выбираться свертки перекрестной проверки для набора данных.
- Определение метрики. Также нужно выбрать метрику, которая будет использоваться для определения оптимального набора параметров, включая правильность, среднеквадратическую погрешность, точность, полноту и F-оценку.
- Обучение, оценка и сравнение. После этого для каждого уникального сочетания значений параметров на основе выбранной пользователем метрики погрешности выполняется перекрестная проверка. После оценки и сравнения можно выбрать оптимальную модель.
На следующем рисунке показано, как это осуществляется в Студии машинного обучения (классическая).
Определение пространства параметров
Набор параметров можно определить на этапе инициализации модели. На панели параметров всех алгоритмов машинного обучения доступны два режима обучения: Single Parameter (Один параметр) и Parameter Range (Диапазон параметров). Выберите режим с диапазоном параметров. В этом режиме каждому параметру можно присвоить несколько значений. В текстовое поле можно ввести разделенные запятыми значения.

Или же можно с помощью параметра Use Range Builder (Использовать построитель диапазонов) можно определить минимальное, максимальное и общее число создаваемых в сетке точек. По умолчанию значения параметров отображаются на линейной шкале. Но если установлен флажок Log Scale (Логарифмическая шкала), значения будут отображаться на логарифмической шкале (т. е. соотношение соседних точек останется неизменным). Диапазон для целочисленных параметров можно определить с помощью дефиса. Например, значение "1–10" указывает, что набор параметров образован всеми целыми числами от 1 до 10 (включая крайние). Также поддерживается смешанный режим. Например, набор параметров "1–10, 20, 50" будет включать целые числа от 1 до 10, а также 20 и 50.

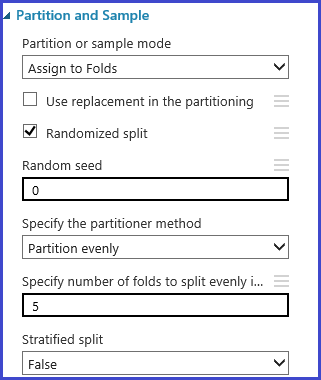
Определение сверток перекрестной проверки
Модуль Partition and Sample (Секционирование и выборка) используется для назначения сверток данным в случайном порядке. Ниже приведен пример с конфигурацией модуля, где задано пять сверток и выбран параметр случайного присвоения номеров сверток экземплярам выборки.
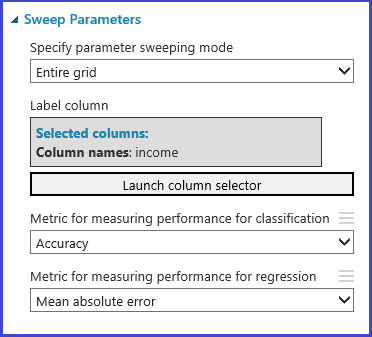
Определение метрики
Модуль Tune Model Hyperparameters (Настройка гиперпараметров модели) позволяет эмпирически выбрать оптимальный набор параметров для заданного алгоритма и набора данных. Вместе с другими сведениями об обучении модели на панели свойств этого модуля доступна метрика, которая позволяет определить оптимальный набор параметров. На этой панели также есть два раскрывающихся списка для выбора алгоритмов классификации и регрессии. Если рассматривается алгоритм классификации, то метрика регрессии игнорируется и наоборот. В этом примере метрика отображает значение правильности.
Обучение, оценка и сравнение
Тот же модуль настройки гиперпараметров модели обучает все модели, соответствующие набору параметров, оценивает разные метрики, а затем создает оптимально обученную модель на основе выбранной вами метрики. Для этого модуля необходимо обязательно предоставить следующие входные данные:
- необученный обучаемый объект;
- набор данных.
Для модуля также можно указать дополнительный набор данных. Подключите набор данных со сведениями о свертке к обязательному набору данных. Если для набора данных не назначены сведения о свертке, по умолчанию будет автоматически выполняться перекрестная проверка 10 сверток. Если свертка не назначена, а на дополнительный порт набора данных подан проверочный набор данных, будет выбран режим тестового обучения. В этом случае первый набор данных используется для обучения модели с каждой комбинацией параметров.
Затем в проверочном наборе данных выполняется оценка модели. Левый порт вывода модуля отображает разные метрики как функции значений параметров. Правый порт вывода отображает обученную модель в соответствии с оптимальной моделью и выбранной метрикой (в нашем примере — метрикой правильности).
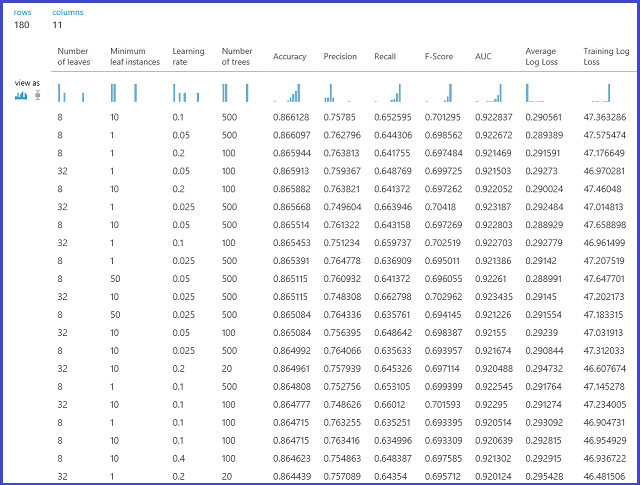
Чтобы просмотреть выбранные параметры, визуализируйте правый порт вывода. Эту модель можно использовать для оценки проверочного набора или в развернутой веб-службе после сохранения обученной модели.