Процесс Обработка и анализ данных команды (TDSP) — это гибкая итеративная методология обработки и анализа данных, которую можно использовать для эффективного предоставления решений прогнозной аналитики и приложений ИИ. TDSP помогает улучшить совместную работу команды и обучение, предложив лучшее взаимодействие ролей команды. TDSP включает рекомендации и структуры от Корпорации Майкрософт и других отраслевых лидеров, чтобы помочь вашей команде успешно реализовать инициативы по обработке и анализу данных и полностью реализовать преимущества вашей программы аналитики.
В этой статье приведен обзор методики TDSP и ее основных компонентов. В нем представлены рекомендации по реализации TDSP с помощью средств и инфраструктуры Майкрософт. Более подробные ресурсы можно найти в этой статье.
Ключевые компоненты TDSP
TDSP имеет следующие ключевые компоненты:
- определение жизненного цикла обработки и анализа данных;
- стандартная структура проекта;
- инфраструктура и ресурсы, рекомендуемые для проектов обработки и анализа данных;
- средства и служебные программы, рекомендуемые для выполнения проекта.
Жизненный цикл обработки и анализа данных
TDSP предоставляет жизненный цикл, который можно использовать для структуры разработки проектов обработки и анализа данных. Жизненный цикл охватывает все этапы, которые выполняются в успешных проектах.
TDSP на основе задач можно объединить с другими жизненными циклами обработки и анализа данных, например межиндустрийный стандартный процесс интеллектуального анализа данных (CRISP-DM), обнаружение знаний в базах данных (KDD) или другой настраиваемый процесс. На высоком уровне эти различные методики имеют много общего.
Этот жизненный цикл следует использовать, если у вас есть проект для обработки и анализа данных, который является частью интеллектуального приложения. Интеллектуальные приложения развертывают модели машинного обучения или искусственного интеллекта для прогнозной аналитики. Этот процесс также можно использовать для исследовательских проектов по обработке и анализу импровизированных аналитических проектов.
Жизненный цикл TDSP состоит из пяти основных этапов, которые команда выполняет итеративно. Эти этапы включают:
Ниже приведено визуальное представление жизненного цикла TDSP:
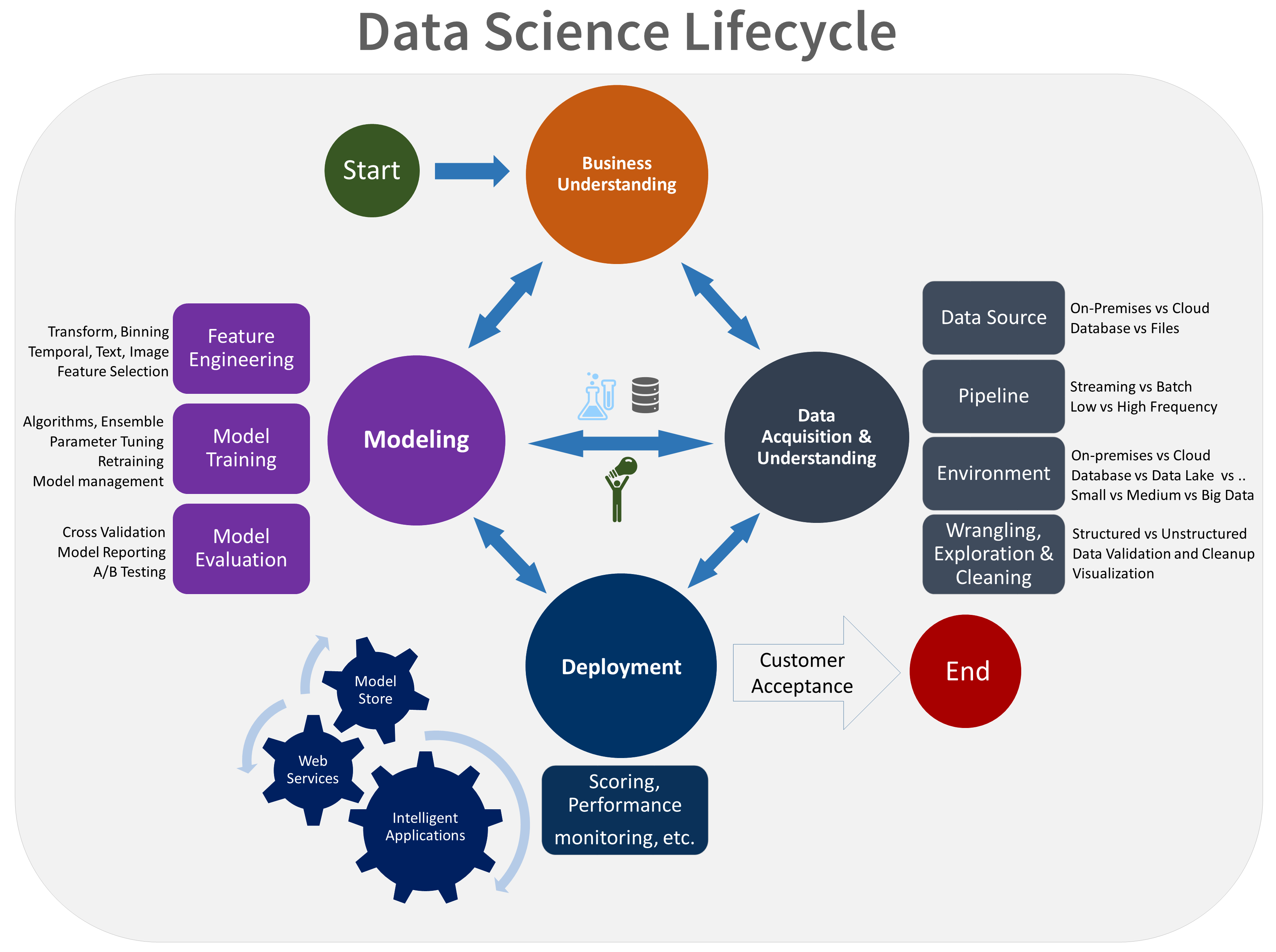
Сведения о задачах, задачах и артефактах документации для каждого этапа см. в разделе "Жизненный цикл процесса Обработка и анализ данных команды".
Эти задачи и артефакты связаны с ролями проекта, например:
- Архитектор решений.
- Диспетчер проектов.
- Инженер данных.
- Специалист по обработке и анализу данных.
- Разработчик приложений.
- Ведущий проект.
На следующей схеме показаны задачи (синие) и артефакты (зеленый), связанные с каждым этапом жизненного цикла (на горизонтальной оси) для этих ролей (на вертикальной оси).

Стандартная структура проекта
Ваша команда может использовать инфраструктуру Azure для организации ресурсов обработки и анализа данных.
Машинное обучение Azure поддерживает открытый исходный код MLflow. Мы рекомендуем использовать MLflow для обработки и анализа данных и управления проектами искусственного интеллекта. MLflow предназначен для управления полным жизненным циклом машинного обучения. Он обучает и обслуживает модели на разных платформах, поэтому вы можете использовать согласованный набор инструментов независимо от того, где выполняются эксперименты. MLflow можно использовать локально на компьютере, в удаленном целевом объекте вычислений, на виртуальной машине или в Машинное обучение вычислительном экземпляре.
MLflow состоит из нескольких ключевых функций:
Отслеживание экспериментов. С помощью MLflow можно отслеживать эксперименты, включая параметры, версии кода, метрики и выходные файлы. Эта функция позволяет эффективно сравнивать различные запуски и управлять процессом экспериментирования.
Код пакета: он предлагает стандартизованный формат для упаковки кода машинного обучения, который включает зависимости и конфигурации. Эта упаковка упрощает воспроизведение запуска и совместного использования кода с другими пользователями.
Управление моделями: MLflow предоставляет функциональные возможности для управления моделями управления версиями и управления ими. Она поддерживает различные платформы машинного обучения, поэтому вы можете хранить, версии и обслуживать модели.
Обслуживание и развертывание моделей: MLflow интегрирует возможности обслуживания и развертывания моделей, чтобы легко развертывать модели в различных средах.
Регистрация моделей. Вы можете управлять жизненным циклом модели, включая управление версиями, переходы этапов и заметки. MLflow полезна для обслуживания централизованного хранилища моделей в среде совместной работы.
Использование API и пользовательского интерфейса. Внутри Azure MLflow упаковано в Машинное обучение API версии 2, чтобы вы могли взаимодействовать с системой программным способом. Вы можете использовать портал Azure для взаимодействия с пользовательским интерфейсом.
MLflow направлена на упрощение и стандартизацию процесса разработки машинного обучения, от экспериментирования до развертывания.
Машинное обучение интегрируется с репозиториями Git, поэтому можно использовать службы, совместимые с Git: GitHub, GitLab, Bitbucket, Azure DevOps или другую службу, совместимую с Git. Помимо ресурсов, уже отслеживаемых в Машинное обучение, ваша команда может разработать собственную таксономию в своей службе, совместимой с Git, для хранения других сведений о проекте, таких как:
- Документации
- Проект, например окончательный отчет о проекте
- Отчет о данных, например словарь данных или отчеты о качестве данных
- Модель, например отчеты о модели
- Код
- Подготовка данных
- Разработка модели
- Эксплуатация, включая безопасность и соответствие требованиям
Инфраструктура и ресурсы
TDSP предоставляет рекомендации по управлению общей аналитикой и инфраструктурой хранилища, например:
- Облачные файловые системы для хранения наборов данных
- Базы данных
- Кластеры больших данных, например SQL или Spark
- Службы машинного обучения
Аналитику и инфраструктуру хранилища можно разместить, где необработанные и обработанные наборы данных хранятся в облаке или локальной среде. Эта инфраструктура обеспечивает возможность воспроизводимого анализа. Он также предотвращает дублирование, что может привести к несоответствиям и ненужным затратам на инфраструктуру. В инфраструктуре есть средства для подготовки общих ресурсов, их отслеживания и безопасного подключения к этим ресурсам каждый участник команды. Рекомендуется также создать согласованную среду вычислений для членов проекта. Затем различные члены команды могут реплика te и проверить эксперименты.
Ниже приведен пример команды, работающей над несколькими проектами и совместное использование различных компонентов инфраструктуры облачной аналитики:

Средства и служебные программы
В большинстве организаций сложно внедрить процессы. Инфраструктура предоставляет средства для реализации TDSP и жизненного цикла, помогая снизить барьеры и повысить согласованность их внедрения.
С помощью Машинное обучение специалисты по обработке и анализу данных могут применять средства с открытым кодом в рамках конвейера обработки и анализа данных или рабочего процесса. В рамках Машинное обучение корпорация Майкрософт продвигает ответственные средства искусственного интеллекта, которые помогают достичь стандарта ответственного искусственного интеллекта Майкрософт.
Одноранговые ссылки
TDSP — это хорошо установленная методология, используемая в рамках взаимодействия Майкрософт, и поэтому была задокументирована и изучена в одноранговой литературе. Эти ссылки предоставляют возможность исследовать функции и приложения TDSP. См. страницу обзора жизненного цикла для списка ссылок.
Связанные ресурсы
Роли и задачи в процессе командной Обработка и анализ данных