Развертывание модели в качестве сетевой конечной точки
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Пакет SDK для Python azure-ai-ml версии 2 (current)
Узнайте, как развернуть модель в онлайн-конечной точке с помощью пакета SDK для Python версии 2 Машинное обучение Azure.
В этом руководстве вы развертываете и используете модель, которая прогнозирует вероятность использования клиента по умолчанию для кредитной карта оплаты.
Теперь необходимо выполнить следующие шаги:
- Регистрация модели
- Создание конечной точки и первого развертывания
- Развертывание пробного запуска
- Отправка тестовых данных вручную в развертывание
- Получение сведений о развертывании
- Создание второго развертывания
- Масштабирование второго развертывания вручную
- Обновление распределения рабочего трафика между обоими развертываниями
- Получение сведений о втором развертывании
- Развертывание нового развертывания и удаление первого
В этом видео показано, как приступить к работе в Студия машинного обучения Azure, чтобы выполнить действия, описанные в руководстве. В видео показано, как создать записную книжку, создать вычислительный экземпляр и клонировать записную книжку. Действия также описаны в следующих разделах.
Необходимые компоненты
-
Чтобы использовать Машинное обучение Azure, сначала потребуется рабочая область. Если у вас нет ресурсов, выполните инструкции по созданию рабочей области и узнайте больше об использовании.
-
Войдите в студию и выберите рабочую область, если она еще не открыта.
-
Откройте или создайте записную книжку в рабочей области:
- Создайте записную книжку, если вы хотите скопировать и вставить код в ячейки.
- Кроме того, откройте учебники/приступая к работе с записными книжками/deploy-model.ipynb из раздела "Примеры " студии. Затем выберите "Клонировать", чтобы добавить записную книжку в файлы. (См. сведения о том, где найти примеры.)
Просмотрите квоту виртуальной машины и убедитесь, что у вас достаточно квот для создания сетевых развертываний. В этом руководстве требуется по крайней мере 8 ядер
STANDARD_DS3_v2и 12 ядерSTANDARD_F4s_v2. Чтобы просмотреть увеличение квоты виртуальной машины и увеличение квоты запросов, см. статью "Управление квотами ресурсов".
Настройка ядра
На верхней панели над открытой записной книжкой создайте вычислительный экземпляр, если у вас еще нет.

Если вычислительный экземпляр остановлен, нажмите кнопку "Пуск вычислений " и подождите, пока она не будет запущена.

Убедитесь, что ядро, найденное в правом верхнем углу.
Python 3.10 - SDK v2В противном случае используйте раскрывающийся список для выбора этого ядра.
Если вы видите баннер, который говорит, что необходимо пройти проверку подлинности, выберите "Проверка подлинности".



Внимание
Остальная часть этого руководства содержит ячейки записной книжки учебника. Скопируйте и вставьте их в новую записную книжку или переключитесь на записную книжку, если она клонирована.
Примечание.
- Бессерверные вычисления Spark не
Python 3.10 - SDK v2установлены по умолчанию. Мы рекомендуем пользователям создать вычислительный экземпляр и выбрать его, прежде чем продолжить работу с руководством.
Создание дескриптора в рабочей области
Прежде чем изучить код, вам потребуется способ ссылаться на рабочую область. Создайте ml_client дескриптор рабочей области и используйте ml_client для управления ресурсами и заданиями.
В следующей ячейке введите идентификатор подписки, имя группы ресурсов и имя рабочей области. Вот как найти эти значения:
- На панели инструментов в правом верхнем углу Студии машинного обучения Azure выберите имя рабочей области.
- Скопируйте значение рабочей области, группы ресурсов и идентификатор подписки в код.
- Необходимо скопировать одно значение, закрыть область и вставить, а затем вернуться к следующей.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Примечание.
Создание MLClient не будет подключаться к рабочей области. Инициализация клиента отложена и ожидает первого вызова (это происходит в следующей ячейке кода).
Регистрация модели.
Если вы уже выполнили предыдущее учебное руководство, обучить модель, вы зарегистрировали модель MLflow в рамках сценария обучения и можете перейти к следующему разделу.
Если вы не выполнили обучение, необходимо зарегистрировать модель. Регистрация модели перед развертыванием рекомендуется.
Следующий код указывает встроенный path код (где отправлять файлы из). Если вы клонировали папку учебников, запустите следующий код как есть. В противном случае скачайте файлы и метаданные для модели, чтобы развернуть и распаковать файлы. Обновите путь к расположению распакованных файлов на локальном компьютере.
Пакет SDK автоматически отправляет файлы и регистрирует модель.
Дополнительные сведения о регистрации модели в качестве ресурса см. в разделе "Регистрация модели в качестве ресурса" в Машинное обучение с помощью пакета SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Убедитесь, что модель зарегистрирована
Вы можете проверка страницу "Модели" в Студия машинного обучения Azure, чтобы определить последнюю версию зарегистрированной модели.
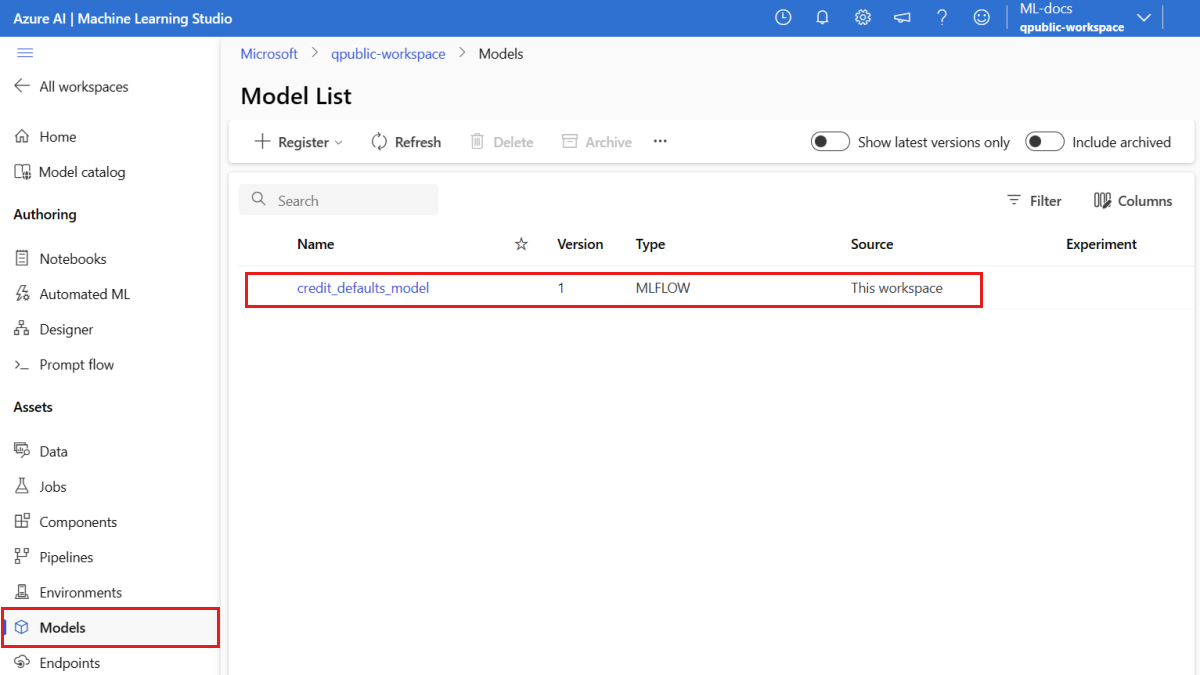
Кроме того, следующий код получает последний номер версии для использования.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Теперь, когда у вас зарегистрированная модель, можно создать конечную точку и развертывание. В следующем разделе кратко рассматриваются некоторые ключевые сведения об этих разделах.
Конечные точки и развертывания
После обучения модели машинного обучения необходимо развернуть ее, чтобы другие пользователи могли использовать ее для вывода. Для этого Машинное обучение Azure позволяет создавать конечные точки и добавлять в них развертывания.
Конечная точка в этом контексте — это путь HTTPS, который предоставляет интерфейс для клиентов для отправки запросов (входных данных) в обученную модель и получения результатов вывода (оценки) из модели. Конечная точка предоставляет:
- Проверка подлинности с помощью проверки подлинности на основе ключа или токена
- Завершение TLS(SSL)
- Стабильный URI оценки (endpoint-name.region.inference.ml.azure.com)
Развертывание представляет собой набор ресурсов, необходимых для размещения модели, которая выполняет процесс вывода.
Одна конечная точка может содержать несколько развертываний. Конечные точки и развертывания — это независимые ресурсы ARM, которые отображаются на портале Azure.
Машинное обучение Azure позволяет реализовать сетевые конечные точки для вывода в режиме реального времени на клиентские данные и пакетные конечные точки для вывода больших объемов данных за период времени.
В этом руководстве описано, как реализовать управляемую конечную точку в Сети. Управляемые сетевые конечные точки работают с мощными компьютерами ЦП и GPU в Azure в масштабируемом режиме, который освобождает вас от затрат на настройку и управление базовой инфраструктурой развертывания.
Создание сетевой конечной точки
Теперь, когда у вас есть зарегистрированная модель, пришло время создать свою конечную точку в Сети. Имя конечной точки должно быть уникальным в пределах всего региона Azure. В этом руководстве вы создадите уникальное имя с помощью универсального уникального идентификатора UUID. Дополнительные сведения о правилах именования конечных точек см. в разделе "Ограничения конечной точки".
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Сначала определите конечную точку ManagedOnlineEndpoint с помощью класса.
Совет
auth_mode: Используйтеkeyдля проведения проверки подлинности на основе ключей. Используйтеaml_tokenдля проверки подлинности в службе "Машинное обучение Azure" на основе маркеров. Срок действияkeyне истекает, в отличие отaml_token. Дополнительные сведения о проверке подлинности см. в статье "Проверка подлинности клиентов для сетевых конечных точек".При необходимости можно добавить описание и теги в конечную точку.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
С помощью созданной ранее конечной MLClient точки создайте конечную точку в рабочей области. Эта команда запускает создание конечной точки и возвращает ответ подтверждения во время создания конечной точки.
Примечание.
Ожидается, что создание конечной точки займет около 2 минут.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
После создания конечной точки его можно получить следующим образом:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Общие сведения о развертывании в Сети
Ключевыми аспектами развертывания являются:
name— имя развертывания.endpoint_name— имя конечной точки, содержащей развертывание.model— модель, которая будет использоваться для развертывания. Это значение может быть ссылкой на существующую модель с управлением версиями в рабочей области или спецификацией встроенной модели.environment— среда, используемая для развертывания (или для запуска модели). Это значение может быть ссылкой на существующую среду с управлением версиями в рабочей области или спецификацией встроенной среды. Среда может быть образом Docker с зависимостями Conda или Dockerfile.code_configuration— конфигурация исходного кода и скрипт оценки.path— Путь к каталогу исходного кода для оценки модели.scoring_script— Относительный путь к файлу оценки в каталоге исходного кода. Этот скрипт выполняет модель в заданном входном запросе. Пример сценария оценки см. в статье "Развертывание модели машинного обучения с помощью веб-конечной точки".
instance_type- Размер виртуальной машины, используемый для развертывания. Список поддерживаемых размеров см. в списке SKU управляемых сетевых конечных точек.instance_count— количество экземпляров, используемых для развертывания.
Развертывание с помощью модели MLflow
Машинное обучение Azure поддерживает развертывание модели без кода, созданной и зарегистрированной с помощью MLflow. Это означает, что вам не нужно предоставлять скрипт оценки или среду во время развертывания модели, так как скрипт оценки и среда автоматически создаются при обучении модели MLflow. Если бы вы использовали пользовательскую модель, однако вам придется указать среду и скрипт оценки во время развертывания.
Внимание
Если вы обычно развертываете модели с помощью скриптов оценки и пользовательских сред и хотите достичь той же функциональности с помощью моделей MLflow, рекомендуется ознакомиться с рекомендациями по развертыванию моделей MLflow.
Развертывание модели в конечной точке
Начните с создания одного развертывания, обрабатывающего 100 % входящего трафика. Выберите произвольное имя цвета (синий) для развертывания. Чтобы создать развертывание для конечной точки, используйте ManagedOnlineDeployment класс.
Примечание.
Нет необходимости указывать среду или скрипт оценки в качестве модели для развертывания является моделью MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Используя созданную MLClient ранее версию, создайте развертывание в рабочей области. Эта команда запускает создание развертывания и возвращает ответ подтверждения во время создания развертывания.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Проверка состояния конечной точки
Вы можете проверка состояние конечной точки, чтобы узнать, была ли модель развернута без ошибок:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Тестирование конечной точки с образцами данных
Теперь когда модель развернута в конечной точке, можно выполнить вывод с помощью этой модели. Начните с создания примера файла запроса, который следует проектированию, ожидаемому в методе выполнения, найденном в скрипте оценки.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Теперь создайте файл в каталоге развертывания. Следующая ячейка кода использует магию IPython для записи файла в только что созданный каталог.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
MLClient Используя созданный ранее дескриптор, получите дескриптор конечной точки. Конечную точку можно вызвать с помощью invoke команды со следующими параметрами:
endpoint_name— имя конечной точкиrequest_file— файл с данными запросаdeployment_name— имя конкретного развертывания для тестирования в конечной точке.
Протестируйте синее развертывание с помощью примеров данных.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Получение журналов развертывания
Проверьте журналы, чтобы узнать, был ли вызвана конечная точка или развертывание успешно. При возникновении ошибок см. статью "Устранение неполадок с сетевыми конечными точками".
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Создание второго развертывания
Разверните модель как второе развертывание green. На практике можно создать несколько развертываний и сравнить их производительность. Эти развертывания могут использовать другую версию той же модели, другой модели или более мощный вычислительный экземпляр.
В этом примере вы развертываете ту же версию модели, используя более мощный вычислительный экземпляр, который может повысить производительность.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Масштабирование развертывания для обработки большего трафика
С помощью созданного MLClient ранее дескриптора можно получить дескриптор green развертывания. Затем его можно масштабировать, увеличив или уменьшая instance_count.
В следующем коде вы вручную увеличиваете экземпляр виртуальной машины. Однако также можно автомасштабировать сетевые конечные точки. Благодаря автомасштабированию автоматически запускается именно тот объем ресурсов, который нужен для обработки нагрузки в вашем приложении. Управляемые сетевые конечные точки поддерживают автоматическое масштабирование через интеграцию с функцией автомасштабирования Azure Monitor. Сведения о настройке автомасштабирования см. в разделе "Автомасштабирование сетевых конечных точек".
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Обновление выделения трафика для развертываний
Рабочий трафик можно разделить между развертываниями. Сначала может потребоваться протестировать green развертывание с примерами данных, как и для blue развертывания. После тестирования зеленого развертывания выделите небольшой процент трафика.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Протестируйте выделение трафика, вызвав конечную точку несколько раз:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Отображение журналов из green развертывания в проверка о том, что были входящие запросы, и модель была успешно оценена.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Просмотр метрик с помощью Azure Monitor
Вы можете просмотреть различные метрики (номера запросов, задержку запроса, сетевые байты, загрузку ЦП/GPU/диск/память и многое другое) для сетевой конечной точки и ее развертываний, следуя ссылкам со страницы сведений конечной точки в студии. После выполнения любой из этих ссылок вы перейдете на страницу точных метрик в портал Azure для конечной точки или развертывания.

Если открыть метрики для веб-конечной точки, вы можете настроить страницу для просмотра метрик, таких как средняя задержка запроса, как показано на следующем рисунке.

Дополнительные сведения о том, как просматривать метрики сетевых конечных точек, см. в разделе "Мониторинг сетевых конечных точек".
Отправка всего трафика в новое развертывание
Когда вы полностью удовлетворены green развертыванием, переключите весь трафик на него.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Удаление старого развертывания
Удалите старое (синее) развертывание:
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Очистка ресурсов
Если вы не собираетесь использовать конечную точку и развертывание после завершения работы с этим руководством, удалите их.
Примечание.
Ожидается, что полное удаление займет около 20 минут.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Удаление всех ресурсов
Выполните следующие действия, чтобы удалить рабочую область Машинного обучения Azure и все вычислительные ресурсы.
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
На портале Azure выберите Группы ресурсов в левой части окна.
Выберите созданную группу ресурсов из списка.
Выберите команду Удалить группу ресурсов.
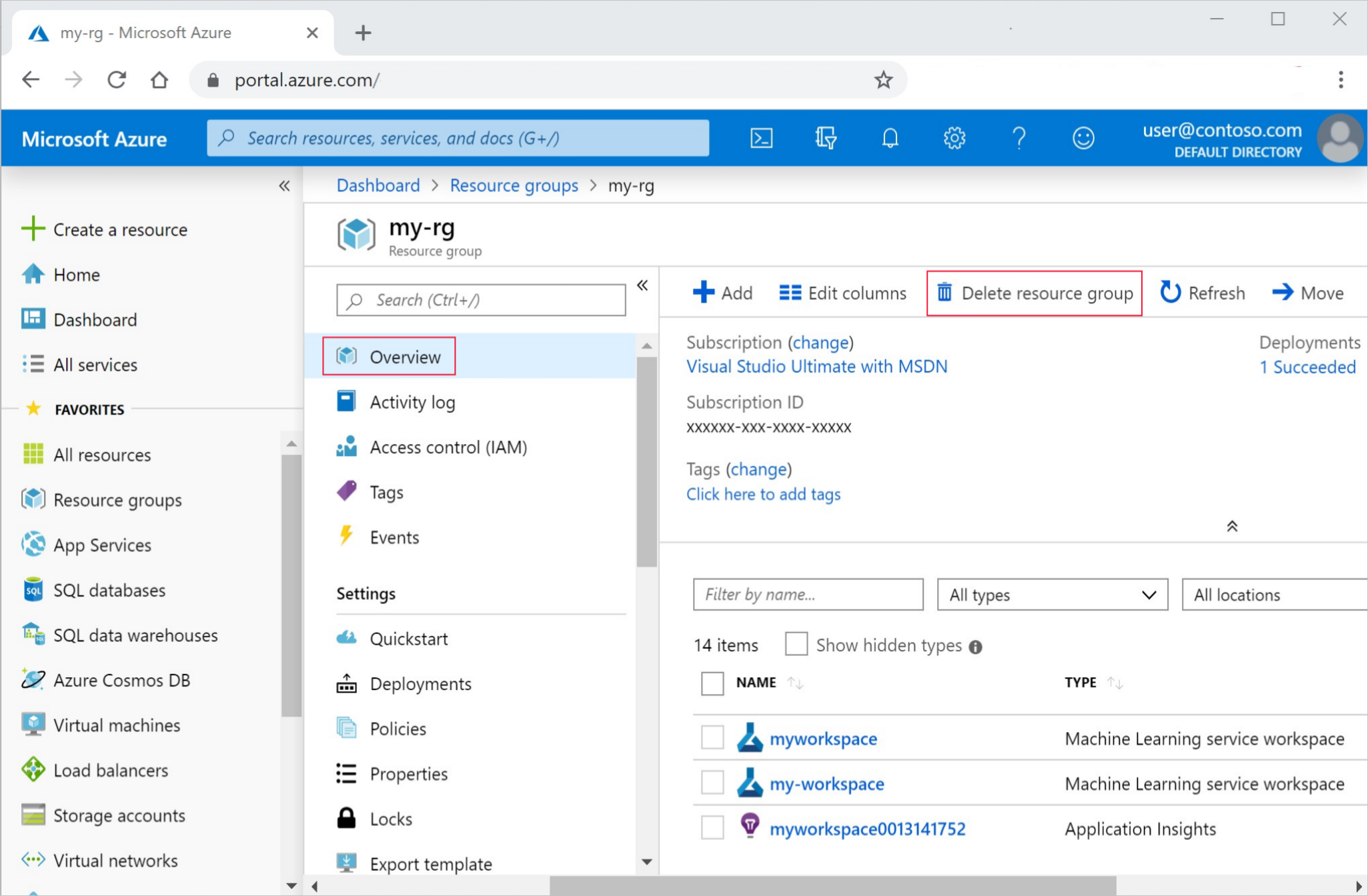
Введите имя группы ресурсов. Затем выберите Удалить.