Создание наборов данных для Машинного обучения Azure из Открытых наборов данных Azure
Внимание
Эта статья ссылается на CentOS, дистрибутив Linux, который приближается к состоянию конца жизни (EOL). Пожалуйста, рассмотрите возможность использования и планирования соответствующим образом. Дополнительные сведения см. в руководстве centOS End Of Life.
Из этой статьи вы узнаете, как перенести проверенные данные обогащения в локальные или удаленные эксперименты машинного обучения с помощью наборов данных Машинного обучения Azure и Открытых наборов данных Azure.
Создавая набор данных Машинного обучение Azure, вы создаете ссылку на расположение источника данных, а также копию его метаданных. Поскольку наборы данных оцениваются в медленном режиме и данные остаются в существующем расположении,
- Дополнительная плата за хранение не взимается.
- Снижаются риски непреднамеренного изменения исходных источников данных.
- улучшается производительность рабочих процессов машинного обучения.
Сведения о работе с наборами данных в общем рабочем процессе доступа к данным в машинном обучении Azure см. в статье Безопасный доступ к данным.
Открытые наборы данных Azure — это проверенные общедоступные наборы данных, которые можно использовать для добавления функций для конкретных сценариев, чтобы расширить возможности прогнозных решений и повысить их точность. В разделе Каталог Открытых наборов данных см. сведения об общедоступных доменах, которые могут помочь в обучении моделей машинного обучения, таких как:
- weather
- census
- holidays
- public safety
- расположение
Открытые наборы данных находятся в облаке на Microsoft Azure и включены в пакет Python SDK для Машинного обучения Azure и в Студии Машинного обучения Azure.
Необходимые компоненты
Для работы с этой статьей вам потребуется:
Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начать работу. Попробуйте бесплатную или платную версию Машинного обучения Azure.
Установленный пакет SDK Машинного обучения Azure для Python, который включает пакет
azureml-datasets.- Создайте вычислительный экземпляр службы Машинное обучение Azure, который представляет собой полностью настроенную и управляемую среду разработки, включающую интегрированные записные книжки и уже установленный пакет SDK.
ИЛИ
- Вы можете работать с собственной средой Python и установить пакет SDK самостоятельно с помощью этих инструкций.
Примечание.
Некоторые классы наборов данных имеют зависимости от пакета azureml-dataprep, совместимого только с 64-разрядным Python. В системе Linux эти классы поддерживаются только в следующих дистрибутивах: Red Hat Enterprise Linux (7, 8), Ubuntu (14.04, 16.04, 18.04), Fedora (27, 28), Debian (8, 9) и CentOS (7).
Создание наборов данных при помощи пакета средств разработки
Чтобы создать наборы данных Машинного обучения Azure с помощью классов Открытых наборов данных Azure в пакете SDK для Python, убедитесь, что пакет установлен с использованием pip install azureml-opendatasets. Каждый дискретный набор данных представлен собственным классом в пакете SDK, а некоторые классы доступны в виде TabularDataset Машинного обучения Azure, FileDataset или и того и другого. Полный список классов см. в справочной документацииopendatasets.
Некоторые классы opendatasets можно извлечь как TabularDataset или FileDataset, что позволяет напрямую управлять файлами и (или) скачивать их. Другие классы могут получить набор данных только с помощью функций get_tabular_dataset() или get_file_dataset() из класса Dataset в пакете SDK Python.
В следующем коде показано, что класс MNIST opendatasets может возвращать значение TabularDataset или FileDataset.
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
В этом примере класс Diabetes opendatasets доступен только в качестве TabularDataset, поэтому используется get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Регистрация наборов данных
Зарегистрируйте набор данных Машинного обучения Azure в рабочей области, чтобы вы могли поделиться ими с другими пользователями и использовать их в разных экспериментах в рабочей области. При регистрации набора данных Машинного обучения Azure, созданного из Открытых наборов данных, данные сразу не загружаются, но при запросе к данным они будут доступны позже (например, во время обучения) из центрального хранилища.
Чтобы зарегистрировать наборы данных в рабочей области, используйте метод register().
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Создание наборов данных с помощью студии
Вы также можете создавать наборы данных Машинного обучения Azure из Открытых наборов данных Azure с помощью Студии машинного обучения Azure, объединенного веб-интерфейса, включающего средства машинного обучения, для выполнения сценариев обработки и анализа данных для специалистов по обработке и анализу и обработке данных на всех уровнях навыков.
Примечание.
Наборы данных, созданные с помощью Студии машинного обучения Azure, автоматически регистрируются в рабочей области.
В рабочей области перейдите на вкладку Наборы данных в разделе Ресурсы. В раскрывающемся меню Создать набор данных выберите пункт Из Открытых наборов данных.
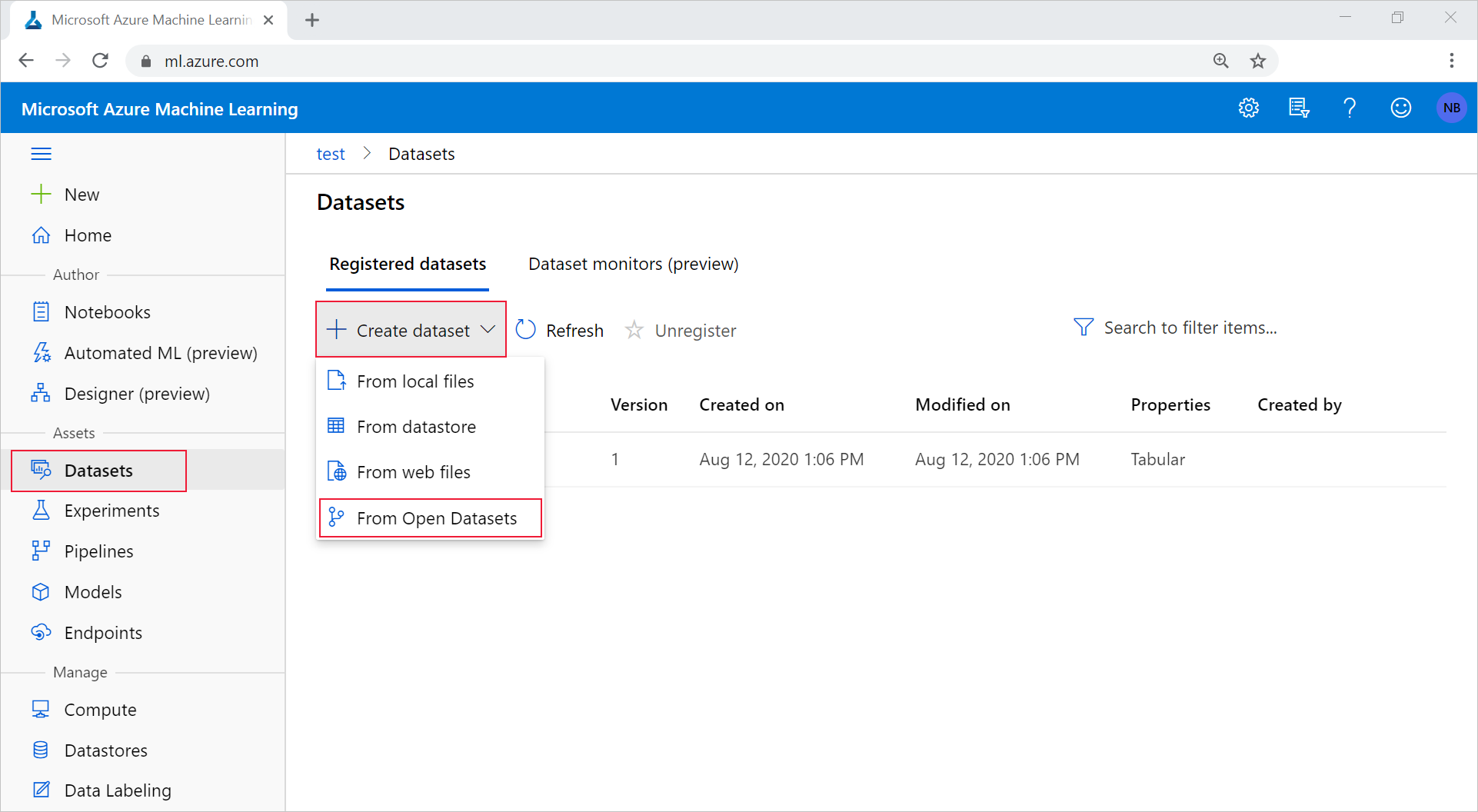
Выберите набор данных, щелкнув его плитку. (Можно выполнить фильтрацию с помощью панели поиска.) Нажмите кнопку Далее.
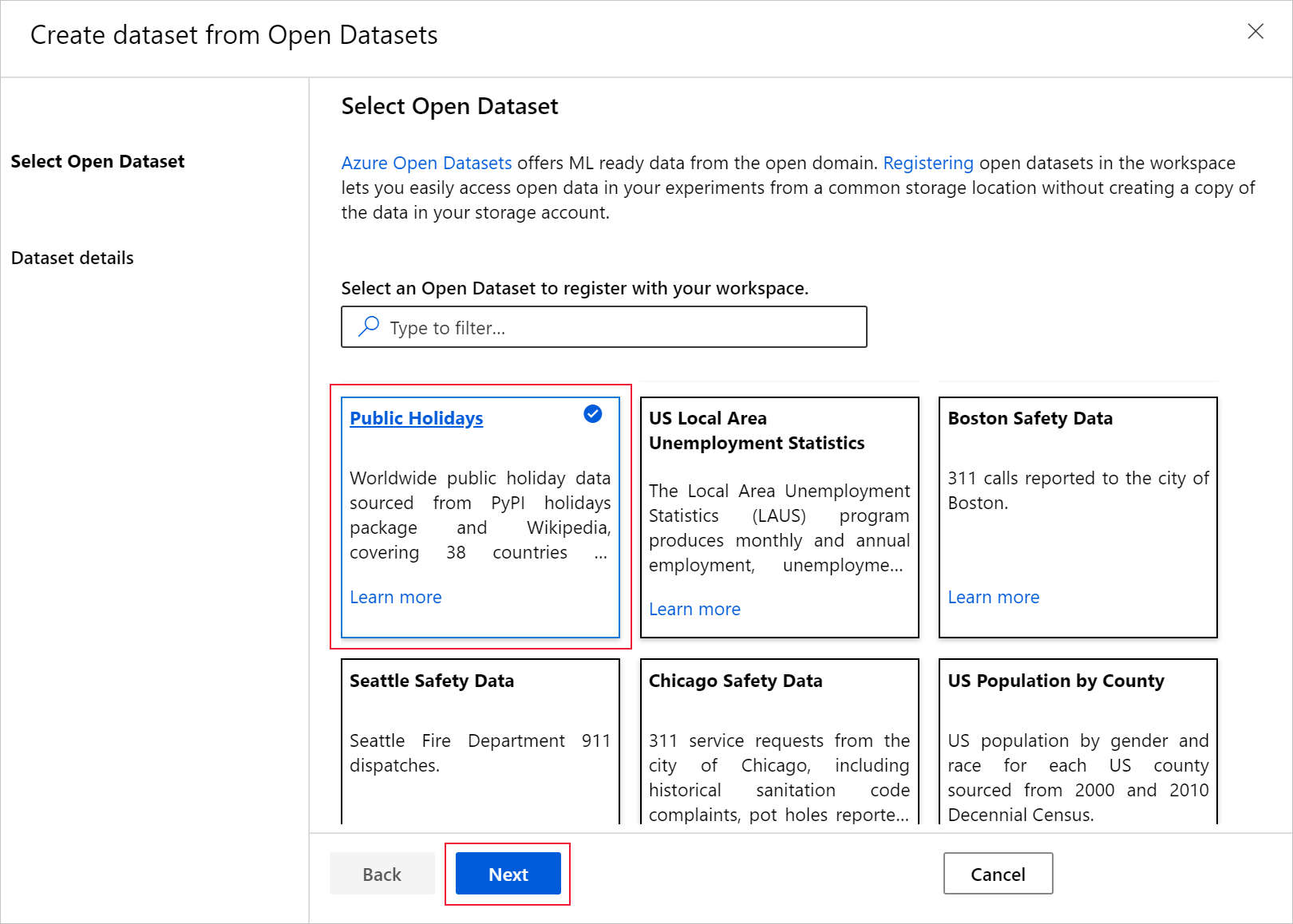
Выберите имя, под которым будет зарегистрирован набор данных, и при необходимости отфильтруйте данные с помощью доступных фильтров. В этом случае для набора данных public holidays вы фильтруете период времени в один год и код страны только в США. Подробные сведения о данных, такие как описания полей и диапазоны дат, см. в разделе Каталог Открытых наборов данных Azure. Нажмите кнопку создания.
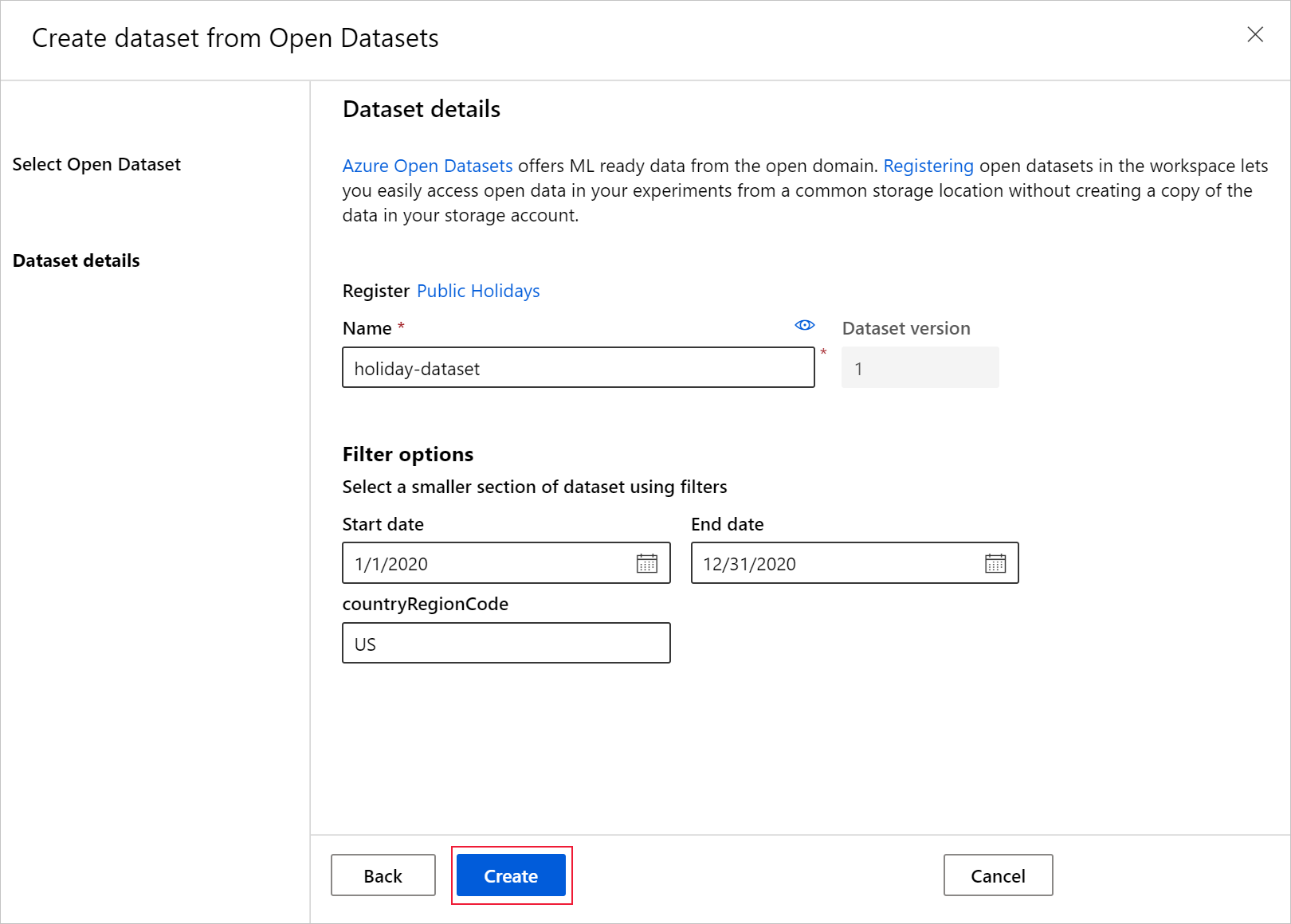
Набор данных теперь доступен в рабочей области в разделе Наборы данных. Его можно использовать точно так же, как и другие созданные наборы данных.
Доступ к наборам данных для экспериментов
Используйте наборы данных в экспериментах машинного обучения для обучения моделей машинного обучения. Узнайте больше об обучении с наборами данных.
Примеры записных книжек
Примеры и демонстрацию функций Открытых наборов данных см. в примерах записных книжек.