Краткое руководство. Создание набора навыков на портале Azure
В этом кратком руководстве вы узнаете, как набор навыков в поиске ИИ Azure добавляет оптическое распознавание символов (OCR), анализ изображений, обнаружение языка, перевод текста и распознавание сущностей для создания содержимого с возможностью поиска в индексе поиска.
Мастер импорта данных можно запустить в портал Azure, чтобы применить навыки, которые создают и преобразуют текстовое содержимое во время индексирования. Входные данные — это необработанные данные, обычно большие двоичные объекты в служба хранилища Azure. Выходные данные — это индекс, содержащий текст изображения, созданный ИИ, подпись и сущности. Созданное содержимое запрашивается на портале с помощью обозревателя поиска.
Чтобы подготовиться, необходимо создать несколько ресурсов и отправить примеры файлов перед запуском мастера.
Необходимые компоненты
Прежде чем приступить к работе, подготовьте указанные ниже необходимые компоненты:
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно .
Поиск по искусственному интеллекту Azure. Создайте новую или найдите существующую службу. Вы можете использовать бесплатную службу для выполнения инструкций, описанных в этом кратком руководстве.
Учетная запись хранения Azure с Хранилищем BLOB-объектов.
Примечание.
В этом кратком руководстве используются службы ИИ Azure для преобразований ИИ. Так как рабочая нагрузка настолько мала, службы ИИ Azure касаются за кулисами для бесплатной обработки до 20 транзакций. Это упражнение можно выполнить, не создавая многослужбный ресурс Azure AI.
Настройка данных
Выполните следующие действия, чтобы настроить контейнер больших двоичных объектов в службе хранилища Azure для хранения разнородных файлов содержимого.
Скачайте пример данных, который состоит из небольшого набора файлов различных типов.
Войдите на портал Azure с помощью своей учетной записи Azure.
Создайте учетную запись хранения Azure или найдите имеющуюся учетную запись.
Выберите тот же регион, что и поиск ВИ Azure, чтобы избежать расходов на пропускную способность.
Выберите StorageV2 (общего назначения версии 2).
В портал Azure откройте страницу служба хранилища Azure и создайте контейнер. Уровень доступа по умолчанию можно использовать.
В контейнере выберите "Отправить ", чтобы отправить примеры файлов. Обратите внимание, что у вас есть широкий спектр типов контента, включая изображения и файлы приложений, которые не доступны для полнотекстового поиска в собственных форматах.
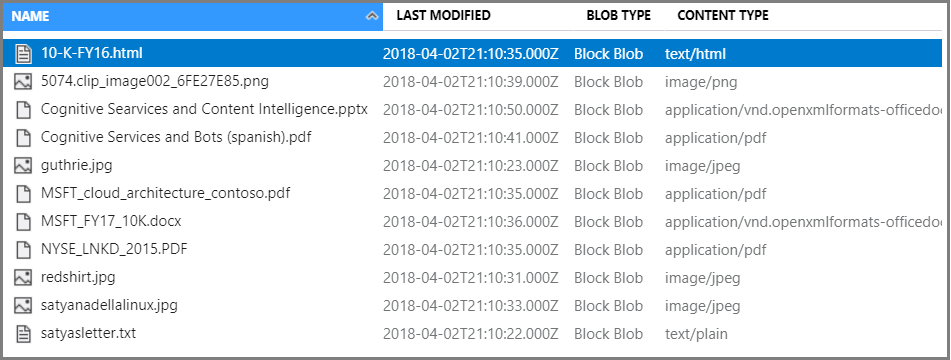
Теперь вы готовы перейти к мастеру импорта данных.
Запуск мастера импорта данных
Войдите на портал Azure с помощью своей учетной записи Azure.
Найдите службу поиска и на странице обзора выберите "Импорт данных " на панели команд, чтобы создать содержимое, доступное для поиска, в четырех шагах.

Шаг 1. Создание источника данных
В разделе Подключение к данным выберите элемент Хранилище BLOB-объектов Azure.
Выберите существующее подключение к учетной записи хранения и выберите созданный контейнер. Присвойте источнику данных имя, а для остальных параметров используйте значения по умолчанию.
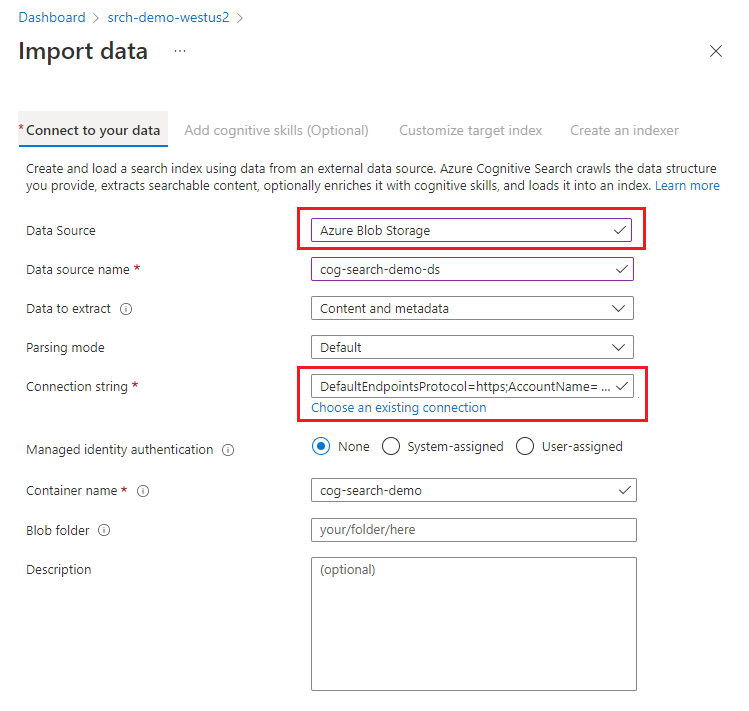
Перейдите к следующей странице.
Если вы получите сообщение "Ошибка обнаружения схемы индекса из источника данных", индексатор, который позволяет мастеру не подключиться к источнику данных. Скорее всего, источник данных имеет защиту безопасности. Попробуйте выполнить следующие решения, а затем повторно запустить мастер.
| Функции безопасности | Решение |
|---|---|
| Для ресурса требуются роли Azure или его ключи доступа отключены | Подключение в качестве доверенной службы или подключения с помощью управляемого удостоверения |
| Ресурс находится за брандмауэром IP-адресов | Создание правила для входящего трафика для поиска и портал Azure |
| Для ресурса требуется подключение частной конечной точки | Подключение через частную конечную точку |
Шаг 2. Добавление когнитивных навыков
Настройте обогащение с помощью ИИ, которое выполняет распознавание текста, анализ изображений и обработку естественного языка.
В этом кратком руководстве мы используем ресурс бесплатных служб ИИ Azure. Пример данных состоит из 14 файлов, поэтому для этого краткого руководства достаточно свободное выделение 20 транзакций в службах ИИ Azure.
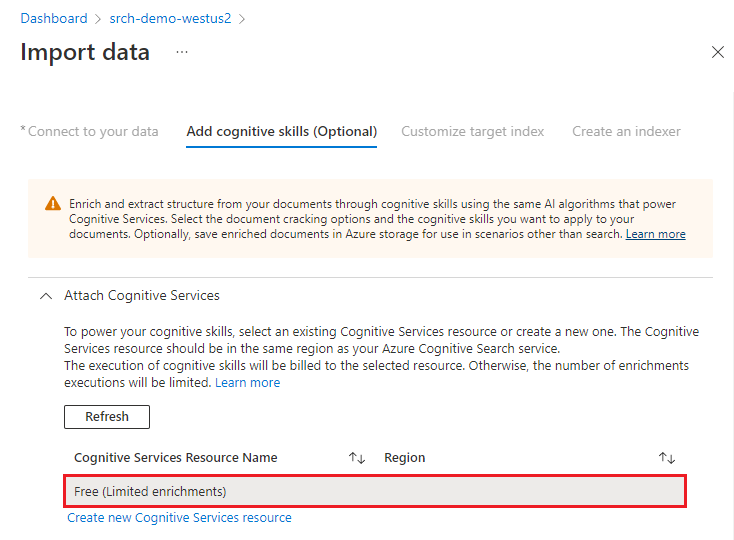
Разверните узел "Добавить обогащения" и выберите шесть элементов.
Включите распознавание текста, чтобы добавить навыки анализа изображений на страницу мастера.
Выберите навыки распознавания сущностей (люди, организации, расположения) и анализ изображений (теги, подпись).
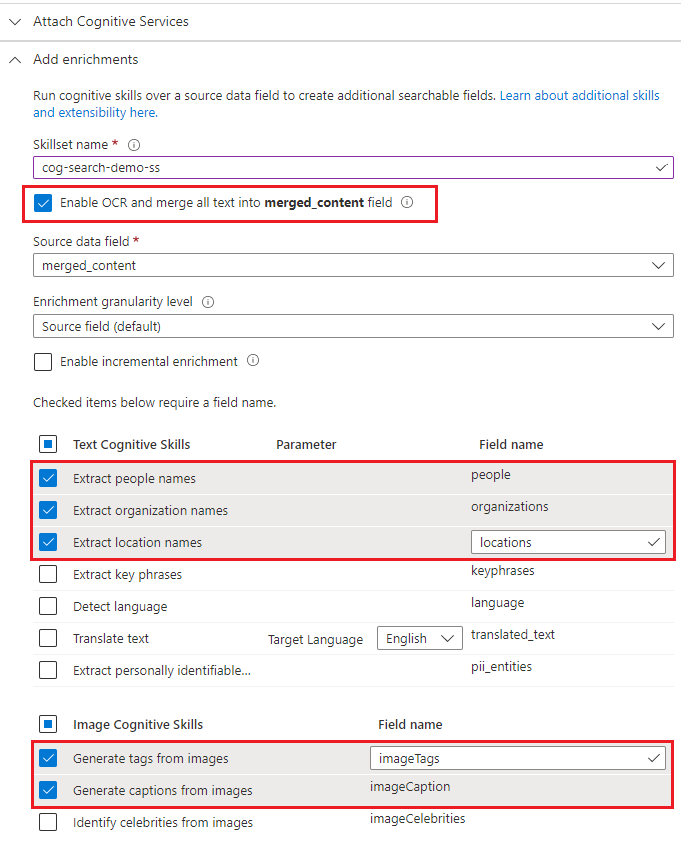
Перейдите к следующей странице.
Шаг 3. Настройка индекса
Индекс содержит содержимое, доступные для поиска, и мастер импорта данных обычно может создать схему путем выборки источника данных. На этом шаге проверьте созданную схему и, возможно, измените некоторые параметры.
В этом кратком руководстве мастер устанавливает разумные значения по умолчанию:
Поля по умолчанию основаны на свойствах метаданных существующих больших двоичных объектов, а также новых полей для выходных данных обогащения (например,
people,organizations).locationsТипы данных выводятся по метаданным и на основе выборки данных.Ключ документа по умолчанию — metadata_storage_path (выбран, так как поле содержит уникальные значения).
По умолчанию устанавливаются атрибуты Доступный для получения и Доступный для поиска. С возможностью поиска разрешает полнотекстовый поиск по этому полю. Доступный для поиска означает, что значения поля можно возвращать в результатах. Мастер предполагает, что вы хотите, чтобы эти поля были доступны для получения и поиска, потому что вы создали их с помощью набора навыков. Выберите "Фильтровать" , если вы хотите использовать поля в выражении фильтра.
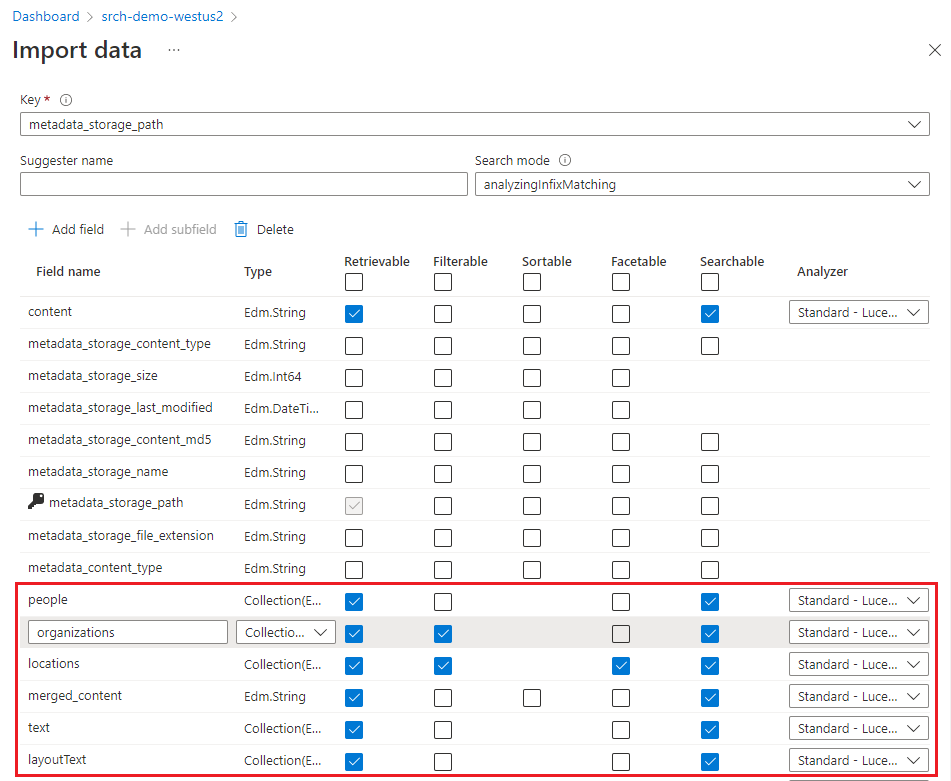
Пометка поля как извлекаемого не означает, что поле должно присутствовать в результатах поиска. Вы можете управлять композицией результатов поиска с помощью параметра выбора запроса, чтобы указать, какие поля следует включить.
Перейдите к следующей странице.
Шаг 4. Настройка индексатора
Индексатор управляет процессом индексирования. Он задает имя источника данных, целевой индекс и частоту выполнения. Мастер импорта данных создает несколько объектов, включая индексатор, который можно сбрасывать и выполнять многократно.
На странице индексатора примите имя по умолчанию и выберите "Один раз".
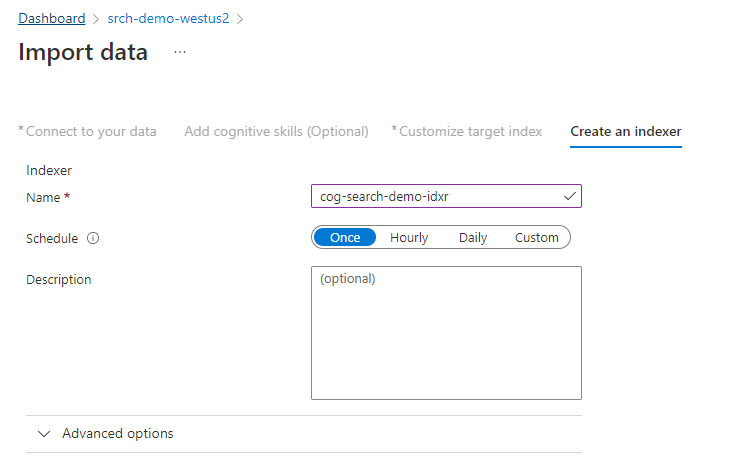
Нажмите кнопку "Отправить ", чтобы создать и одновременно запустить индексатор.
Состояние монитора
Выберите индексаторы в области навигации слева, чтобы отслеживать состояние, а затем выберите индексатор. Индексирование на основе навыков занимает больше времени, чем индексирование на основе текста, особенно анализ OCR и изображений.
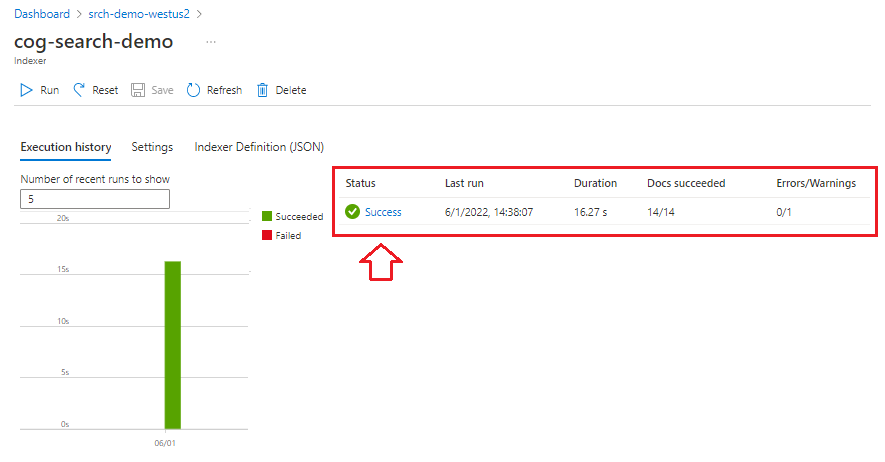
Чтобы просмотреть сведения о состоянии выполнения, нажмите кнопку Success (или Failed), чтобы просмотреть сведения о выполнении.
В этой демонстрации есть несколько предупреждений: "Could not execute skill because one or more skill input was invalid." он сообщает, что PNG-файл в источнике данных не предоставляет текстовые входные данные для распознавания сущностей. Это предупреждение возникает из-за того, что навык OCR вышестоящий не распознал текст на изображении, и поэтому не мог предоставить текстовые входные данные навыку распознавания сущностей нижестоящего элемента.
Предупреждения распространены в выполнении набора навыков. Как вы узнаете, как навыки итерируют данные, вы можете начать замечать шаблоны и узнать, какие предупреждения безопасно игнорировать.
Запросы в обозревателе поиска
После создания индекса используйте обозреватель поиска для возврата результатов.
Слева выберите индексы и выберите индекс. Обозреватель поиска находится на первой вкладке.
Введите строку поиска для запроса по индексу, например
satya nadella. Панель поиска принимает ключевое слово, вложенные в кавычки фразы и операторы ("Satya Nadella" +"Bill Gates" +"Steve Ballmer").
Результаты возвращаются в виде подробного JSON, который может быть трудно прочитать, особенно в больших документах. Вот несколько советов по поиску с помощью этого средства:
Переключитесь в представление JSON, чтобы указать параметры, результаты фигуры.
Добавьте
select, чтобы ограничить поля в результатах.Добавьте
count, чтобы отобразить количество совпадений.сочетание клавиш CTRL+F позволяет найти определенные свойства или термины в документе JSON;
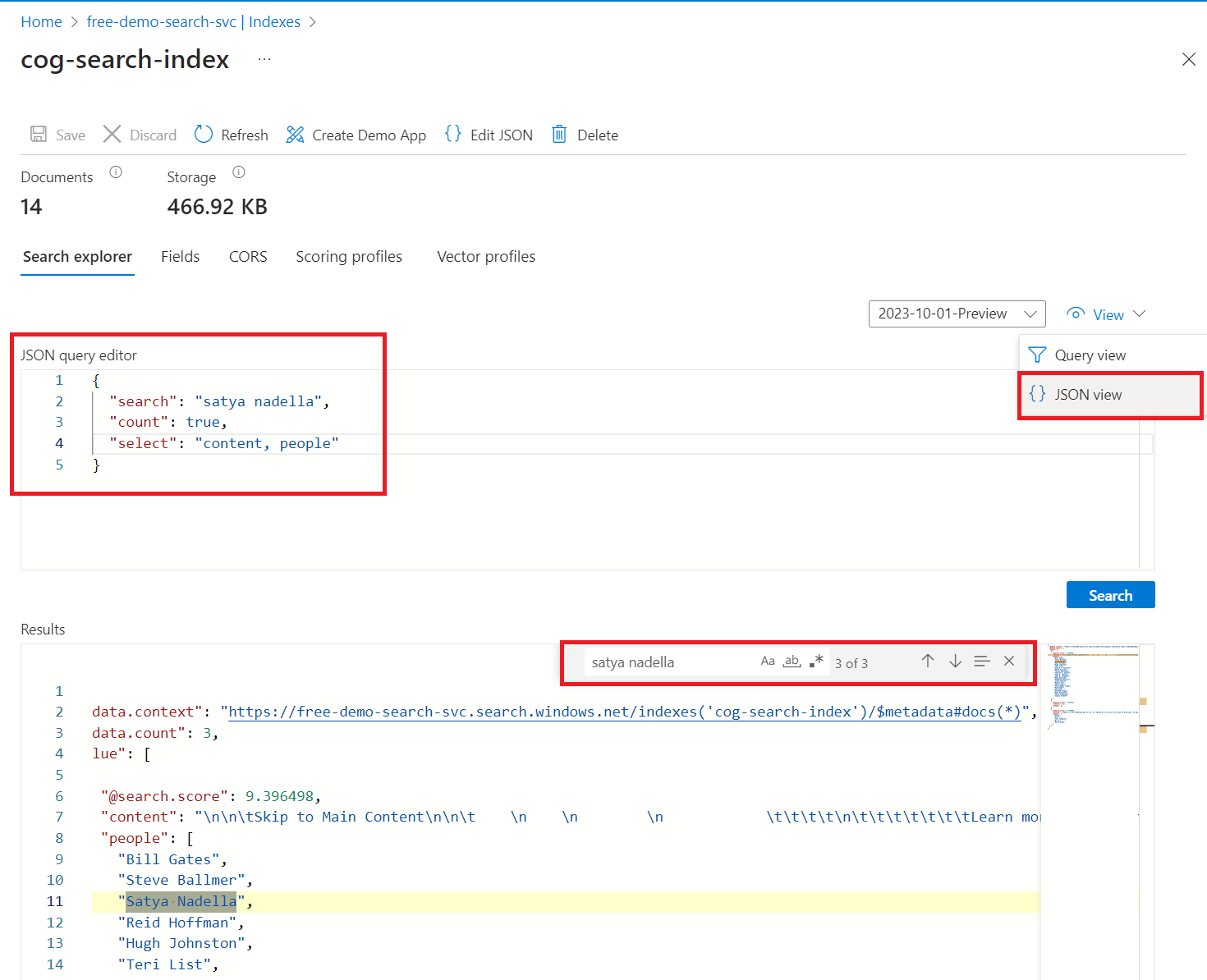
Ниже приведен пример JSON, который можно вставить в представление:
{
"search": "\"Satya Nadella\" +\"Bill Gates\" +\"Steve Ballmer\"",
"count": true,
"select": "content, people"
}
Совет
в строках запроса учитывается регистр, поэтому при получении сообщения "неизвестное поле" проверьте правильность написания и регистр в значениях Fields (поля) Index Definition (JSON) (определение индекса).
Общие выводы
Теперь вы создали свой первый набор навыков и узнали основные шаги индексирования на основе навыков.
Некоторые ключевые понятия, которые мы надеемся, что вы выбрали, включают зависимости. Набор навыков привязан к индексатору, а индексаторы зависят от Azure и источника. Несмотря на то что краткое руководство использует хранилище BLOB-объектов Azure, можно использовать и другие источники данных Azure. Дополнительные сведения см. в статье "Индексаторы" в службе "Поиск ИИ Azure".
Еще одна важная концепция заключается в том, что навыки работают над типами контента, а при работе с разнородным содержимым некоторые входные данные пропускаются. Кроме того, крупные файлы и (или) значения полей могут привести к превышению лимитов на используемом уровне службы. В таких случаях появление предупреждений считается нормальным.
Выходные данные направляются в индекс поиска, и в индексе создается сопоставление пар "имя-значение", созданных во время индексирования и отдельных полей в индексе. Внутри мастера настраивается дерево обогащения и определяется набор навыков, устанавливающий порядок операций и общий поток. Эти действия скрыты в мастере, но при запуске написания кода эти понятия становятся важными.
Наконец, вы узнали, что можно проверять содержимое путем запроса индекса. В конце концов, что предоставляет поиск ИИ Azure— это индекс, доступный для поиска, который можно запрашивать с помощью простого или полностью расширенного синтаксиса запросов. Индекс, который содержит обогащенные поля, не отличается от других. Если вы хотите включить стандартные или пользовательские анализаторы, профили оценки, синонимы, фасетную навигацию, геоизбыточное поиск или любую другую функцию поиска ИИ Azure, это можно сделать.
Очистка ресурсов
Если вы работаете в собственной подписке, в конце проекта следует решить, нужны ли вам созданные ресурсы. Ресурсы, которые продолжат работать, могут быть платными. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Просматривать ресурсы и управлять ими можно на портале с помощью ссылок Все ресурсы или Группы ресурсов на панели навигации слева.
Если вы использовали бесплатную службу, помните, что вы ограничены тремя индексами, индексаторами и источниками данных. Вы можете удалить отдельные элементы на портале, чтобы не превысить лимит.
Следующие шаги
Вы можете создавать наборы навыков, используя портал, .NET SDK или REST API. Чтобы получить дополнительные знания, попробуйте ИСПОЛЬЗОВАТЬ REST API с помощью клиента REST и дополнительных примеров данных.