Создание хранилища векторов
В службе "Поиск ИИ Azure" векторное хранилище содержит схему индекса, которая определяет поля векторов и невекторов, векторную конфигурацию для алгоритмов, создающих пространство внедрения, и параметры определений векторных полей, используемых в запросах. API создания индекса создает векторное хранилище.
Выполните следующие действия, чтобы индексировать векторные данные:
- Определение схемы с одной или несколькими векторными конфигурациями, определяющими алгоритмы индексирования и поиска
- Добавление одного или нескольких векторных полей
- Загрузите предварительно подготовленные данные в качестве отдельного шага или используйте встроенную векторизацию (предварительная версия) для фрагментирования и кодирования данных во время индексирования.
Эта статья относится к общедоступной версии векторного поиска, которая предполагает, что код приложения вызывает внешние ресурсы для фрагментирования и кодирования.
Примечание.
Ищете рекомендации по миграции с версии 2023-07-01-preview? См. раздел REST API обновления.
Необходимые компоненты
Поиск ИИ Azure в любом регионе и на любом уровне. Большинство существующих служб поддерживают векторный поиск. Для служб, созданных до января 2019 года, существует небольшое подмножество, которое не поддерживает векторный поиск. Если индекс, содержащий поля векторов, не может быть создан или обновлен, это индикатор. В этой ситуации необходимо создать новую службу.
Предварительно существующие векторные внедрения в исходные документы. Поиск ИИ Azure не создает векторы в общедоступной версии пакетов SDK Azure и REST API. Мы рекомендуем использовать модели внедрения Azure OpenAI, но можно использовать любую модель для векторизации. Дополнительные сведения см. в разделе "Создание внедрения".
Необходимо знать предел измерений модели, используемой для создания внедрения и вычисления сходства. В Azure OpenAI для преобразования текста в ada-002 длина числового вектора составляет 1536. Сходство вычисляется с помощью
cosine. Допустимые значения : 2–3072 измерения.Вы должны быть знакомы с созданием индекса. Схема должна содержать поле для ключа документа, другие поля, которые требуется выполнить поиск или фильтрацию, и другие конфигурации для поведения, необходимых во время индексирования и запросов.
Подготовка документов к индексации
Перед индексированием соберите полезные данные документа, включающее поля векторных и невекторных данных. Структура документа должна соответствовать схеме индекса.
Убедитесь, что документы:
Укажите поле или свойство метаданных, которое однозначно идентифицирует каждый документ. Для всех индексов поиска требуется ключ документа. Чтобы удовлетворить требования к ключу документа, исходный документ должен иметь одно поле или свойство, которое может однозначно идентифицировать его в индексе. Это исходное поле должно быть сопоставлено с полем индекса типа
Edm.Stringиkey=trueв индексе поиска.Укажите векторные данные (массив чисел с плавающей запятой с одной точностью) в исходных полях.
Векторные поля содержат числовые данные, созданные путем внедрения моделей, по одному внедрению на каждое поле. Мы рекомендуем внедрять модели в Azure OpenAI, например text-embedding-ada-002 для текстовых документов или REST API извлечения изображений для изображений. Поддерживаются только поля векторов верхнего уровня: вложенные поля векторов в настоящее время не поддерживаются.
Предоставьте другие поля с буквенно-цифровым содержимым для ответа запроса, а также для сценариев гибридного запроса, которые включают полный текстовый поиск или семантический ранжирование в том же запросе.
Индекс поиска должен содержать поля и содержимое для всех сценариев запросов, которые вы хотите поддерживать. Предположим, вы хотите выполнить поиск или фильтрацию по именам продуктов, версиям, метаданным или адресам. В этом случае поиск сходства особенно не полезен. Поиск ключевых слов, гео-поиск или фильтры будут лучшим выбором. Индекс поиска, включающий комплексную коллекцию векторных и невекторных данных, обеспечивает максимальную гибкость для построения запросов и композиции ответов.
Краткий пример полезных данных документов, включающих векторные и невекторные поля, находится в разделе данных вектора нагрузки этой статьи.
Добавление конфигурации векторного поиска
Конфигурация вектора задает алгоритм поиска векторов и параметры, используемые во время индексирования для создания сведений о ближайших соседах между векторными узлами:
- Иерархический навигации небольшой мир (HNSW)
- Исчерпывающий KNN
Если вы выберете HNSW в поле, вы можете выбрать исчерпывающий KNN во время запроса. Но другое направление не будет работать: если выбрать исчерпывающий, вы не сможете позже запросить поиск HNSW, так как дополнительные структуры данных, обеспечивающие приблизительный поиск, не существуют.
Ищете рекомендации по миграции предварительной версии в стабильную версию? Инструкции см. в статье об обновлениях REST API.
REST API версии 2023-11-01 поддерживает конфигурацию векторов:
vectorSearchалгоритмы иhnswexhaustiveKnnближайшие соседи с параметрами индексирования и оценки.vectorProfilesдля нескольких сочетаний конфигураций алгоритмов.
Убедитесь, что у вас есть стратегия векторизации содержимого. Стабильная версия не предоставляет векторизаторы для встроенного внедрения.
Используйте API создания или обновления индекса для создания индекса.
vectorSearchДобавьте раздел в индекс, указывающий алгоритмы поиска, используемые для создания пространства внедрения."vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } }, { "name": "my-hnsw-config-2", "kind": "hnsw", "hnswParameters": { "m": 8, "efConstruction": 800, "efSearch": 800, "metric": "cosine" } }, { "name": "my-eknn-config", "kind": "exhaustiveKnn", "exhaustiveKnnParameters": { "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-2" } ] }Основные моменты:
- Имя конфигурации. Имя должно быть уникальным в индексе.
profilesдобавьте слой абстракции для размещения более богатых определений. Профиль определяетсяvectorSearchв , а затем ссылается по имени в каждом поле вектора."hnsw"и"exhaustiveKnn"являются алгоритмами приблизительных ближайших соседей (ANN), используемыми для упорядочивания векторного содержимого во время индексирования."m"Значение по умолчанию (число двунаправленных ссылок) — 4. Диапазон составляет от 4 до 10. Более низкие значения должны возвращать меньше шума в результатах."efConstruction"значение по умолчанию — 400. Диапазон составляет от 100 до 1000. Это число ближайших соседей, используемых во время индексирования."efSearch"значение по умолчанию — 500. Диапазон составляет от 100 до 1000. Это число ближайших соседей, используемых во время поиска."metric"если вы используете Azure OpenAI, в противном случае используйте метрику сходства, связанную с используемой моделью внедрения. Поддерживаемые значения:cosine,dotProduct.euclidean
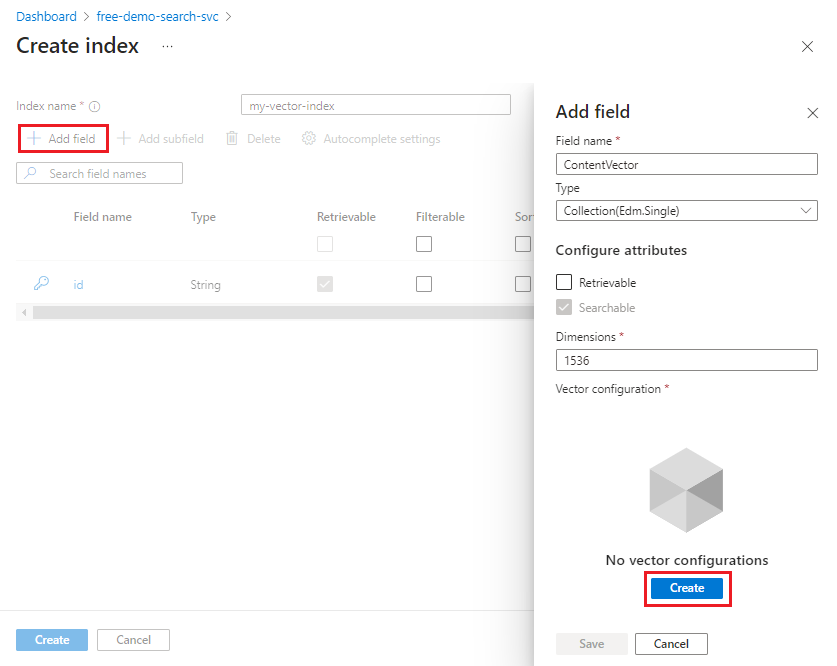
Добавление векторного поля в коллекцию полей
Коллекция полей должна содержать поле для ключа документа, векторных полей и других полей, необходимых для гибридных сценариев поиска.
Векторные поля имеют тип Collection(Edm.Single) и значения с плавающей запятой с одной точностью. Поле этого типа также имеет dimensions свойство и указывает конфигурацию вектора.
Используйте эту версию, если требуется только общедоступные функции.
Используйте индекс создания или обновления для создания индекса.
Определите поле вектора со следующими атрибутами. Вы можете сохранить одно созданное внедрение на поле. Для каждого поля вектора:
- Аргумент
typeдолжен иметь значениеCollection(Edm.Single). dimensions— это количество измерений, созданных моделью внедрения. Для преобразования текста в ada-002 это значение 1536.vectorSearchProfile— это имя профиля, определенного в другом месте индекса.searchableдолжно быть true.retrievableможет иметь значение true или false. True возвращает необработанные векторы (1536 из них) в виде обычного текста и потребляет место в хранилище. Задайте значение true, если вы передаете результат вектора в нижнее приложение.filterable,facetablesortableдолжен иметь значение false.
- Аргумент
Добавьте фильтруемые поля невектора в коллекцию, например "title" с
filterableзаданным значением true, если требуется вызвать префильтрацию или послефильтрацию в векторном запросе.Добавьте другие поля, определяющие вещество и структуру индексированного содержимого. Как минимум, вам нужен ключ документа.
Кроме того, следует добавить поля, полезные в запросе или в ответе. В следующем примере показаны векторные поля для заголовка и содержимого ("titleVector", "contentVector"), которые эквивалентны векторам. Он также предоставляет поля для эквивалентного текстового содержимого ("title", "content") полезно для сортировки, фильтрации и чтения в результатах поиска.
В следующем примере показана коллекция полей:
PUT https://my-search-service.search.windows.net/indexes/my-index?api-version=2023-11-01&allowIndexDowntime=true Content-Type: application/json api-key: {{admin-api-key}} { "name": "{{index-name}}", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "filterable": true }, { "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "retrievable": true }, { "name": "titleVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" }, { "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true }, { "name": "contentVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" } ], "vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-1" } ] } }

Загрузка векторных данных для индексирования
Содержимое, предоставленное для индексирования, должно соответствовать схеме индекса и включать уникальное строковое значение ключа документа. Превекторные данные загружаются в одно или несколько векторных полей, которые могут сосуществовать с другими полями, содержащими буквенно-цифровое содержимое.
Для приема данных можно использовать методы принудительной отправки или извлечения.
Используйте индексные документы (2023-11-01), индексные документы (2023-10-01-Preview) или добавление, обновление или удаление документов (2023-07-01-Preview) для отправки документов, содержащих векторные данные.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/index?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"value": [
{
"id": "1",
"title": "Azure App Service",
"content": "Azure App Service is a fully managed platform for building, deploying, and scaling web apps. You can host web apps, mobile app backends, and RESTful APIs. It supports a variety of programming languages and frameworks, such as .NET, Java, Node.js, Python, and PHP. The service offers built-in auto-scaling and load balancing capabilities. It also provides integration with other Azure services, such as Azure DevOps, GitHub, and Bitbucket.",
"category": "Web",
"titleVector": [
-0.02250031754374504,
. . .
],
"contentVector": [
-0.024740582332015038,
. . .
],
"@search.action": "upload"
},
{
"id": "2",
"title": "Azure Functions",
"content": "Azure Functions is a serverless compute service that enables you to run code on-demand without having to manage infrastructure. It allows you to build and deploy event-driven applications that automatically scale with your workload. Functions support various languages, including C#, F#, Node.js, Python, and Java. It offers a variety of triggers and bindings to integrate with other Azure services and external services. You only pay for the compute time you consume.",
"category": "Compute",
"titleVector": [
-0.020159931853413582,
. . .
],
"contentVector": [
-0.02780858241021633,
. . .
],
"@search.action": "upload"
}
. . .
]
}
Проверьте индекс для векторного содержимого
В целях проверки можно запросить индекс с помощью поиска Обозреватель в портал Azure или вызове REST API. Так как поиск по искусственному интеллекту Azure не может преобразовать вектор в удобочитаемый пользователем текст, попробуйте вернуть поля из того же документа, который предоставляет доказательства соответствия. Например, если векторный запрос предназначен для поля titleVector, можно выбрать "title" для результатов поиска.
Поля должны быть указаны как "извлекаемые" для включения в результаты.
Для запроса индекса можно использовать Обозреватель поиска. В обозревателе поиска есть два представления: представление запросов (по умолчанию) и представление JSON.
Используйте представление JSON для векторных запросов, вставляя в определение JSON векторного запроса, который требуется выполнить.
Используйте представление запроса по умолчанию для быстрого подтверждения того, что индекс содержит векторы. Представление запроса предназначено для полнотекстового поиска. Хотя его нельзя использовать для векторных запросов, можно отправить пустой поиск (
search=*) в проверка для содержимого. Содержимое всех полей, включая векторные поля, возвращается в виде обычного текста.
Обновление хранилища векторов
Чтобы обновить векторное хранилище, измените схему и при необходимости перезагрузите документы, чтобы заполнить новые поля. API для обновлений схемы включают создание или обновление индекса (REST), CreateOrUpdateIndex в пакете SDK azure для .NET, create_or_update_index в пакете SDK Azure для Python и аналогичных методах в других пакетах SDK Azure.
Стандартное руководство по обновлению индекса рассматривается в раскрывающемся списке и перестроении индекса.
Ключевые моменты:
Удаление и перестроение часто требуется для обновлений и удаления существующих полей.
Однако можно обновить существующую схему со следующими изменениями без необходимости перестроения:
- Добавление новых полей в коллекцию полей.
- Добавьте новые конфигурации векторов, назначенные новым полям, но не существующим полям, которые уже векторизированы.
- Измените значение "извлекаемое" (значения имеют значение true или false) в существующем поле. Поля векторов должны быть доступны для поиска и извлечения, но если вы хотите отключить доступ к полю вектора в ситуациях, когда удаление и перестроение невозможно, можно задать значение false.
Следующие шаги
На следующем шаге мы рекомендуем запрашивать векторные данные в индексе поиска.
Примеры кода в репозитории azure-search-vector демонстрируют сквозные рабочие процессы, включающие определение схемы, векторизацию, индексирование и запросы.
Существует демонстрационный код для Python, C# и JavaScript.