Балансировка кластера Service Fabric
Диспетчер кластерных ресурсов Service Fabric поддерживает динамическое изменение нагрузки, реагируя на добавление и удаление узлов или служб. Он также автоматически исправляет нарушения ограничений и упреждающе перераспределяет нагрузку в кластере. Но как часто выполняются эти действия и что их инициирует?
Существует три различных категории работы, которую выполняет Resource Manager кластера.
- Размещение: на этом этапе происходит размещение отсутствующих метрик с отслеживанием состояния или без. Размещаются как новые службы, так и реплики с отслеживанием состояния или экземпляры без отслеживания состояния, которые вызвали сбой. Тут выполняется удаление реплик и экземпляров.
- Проверка ограничений: на этом этапе проверяются и устраняются нарушения различных ограничений (правил) размещения в системе. Примерами правил являются такие вещи, как обеспечение того, чтобы узлы не переместились и что ограничения размещения службы соблюдаются.
- Балансировка . На этом этапе проверяется необходимость перебалансировки на основе настроенного требуемого уровня баланса для различных метрик. Если это необходимо, предпринимается попытка найти более сбалансированную схему упорядочения в кластере.
Настройка таймеров диспетчера кластерных ресурсов
Первый набор элементов управления балансировкой — это набор таймеров. Они определяют, как часто диспетчер кластерных ресурсов проверяет состояние кластера и выполняет корректирующие действия.
Каждым из типов исправлений, которые может внести Cluster Resource Manager, управляет соответствующий таймер, который определяет частоту их применения. При каждом срабатывании таймера задача добавляется в расписание. По умолчанию диспетчер ресурсов:
- проверяет состояние и применяет обновления (например, записывает, что узел не работает) каждые 1/10 секунды;
- каждую секунду устанавливает флаг проверки размещения;
- каждую секунду устанавливает флаг проверки ограничений;
- каждые пять секунд устанавливает флаг распределения нагрузки.
Ниже приведены примеры конфигураций, устанавливающих эти таймеры.
ClusterManifest.xml:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="PLBRefreshGap" Value="0.1" />
<Parameter Name="MinPlacementInterval" Value="1.0" />
<Parameter Name="MinConstraintCheckInterval" Value="1.0" />
<Parameter Name="MinLoadBalancingInterval" Value="5.0" />
</Section>
Для автономных развертываний используется ClusterConfig.json, а для размещенных в Azure кластеров — Template.json.
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "PLBRefreshGap",
"value": "0.10"
},
{
"name": "MinPlacementInterval",
"value": "1.0"
},
{
"name": "MinConstraintCheckInterval",
"value": "1.0"
},
{
"name": "MinLoadBalancingInterval",
"value": "5.0"
}
]
}
]
На сегодняшний день диспетчер кластерных ресурсов выполняет эти действия только по очереди. Именно поэтому мы называем таймеры минимальными интервалами, а действия, которые выполняются при срабатывании таймеров, — флагами параметров. Например, Cluster Resource Manager обрабатывает ожидающие запросы, чтобы создать службы перед балансировкой кластера. Как можно видеть, заданные интервалы времени по умолчанию означают, что диспетчер кластерных ресурсов часто проверяет, какие задачи ему необходимо выполнять. Обычно это означает, что набор изменений, вносимых на каждом шаге, мал. Небольшие и частые изменения позволяют Resource Manager кластера реагировать на события в кластере. Таймеры по умолчанию обеспечивают своего рода пакетную обработку, поскольку обычно множество событий одного типа происходят одновременно.
Например, когда происходит сбой узлов, то может выполняться одновременная обработка доменов сбоя целиком. Все эти сбои регистрируются во время следующего изменения состояния после PLBRefreshGap. Исправления определяются во время следующих циклов размещения, проверки ограничений и балансировки нагрузки. По умолчанию Resource Manager кластера не проверяет часы изменений в кластере и пытается устранить все изменения одновременно. Такой подход может приводить к резкому увеличению оттока.
Чтобы выявить дисбаланс кластера, Cluster Resource Manager необходимы также некоторые дополнительные сведения. Для этого используются два других элемента конфигурации: пороговые значения балансировки и пороговые значения активности.
Пороговые значения балансировки
Пороговое значение балансировки — это основной элемент управления для запуска перераспределения нагрузки. Пороговое значение балансировки для метрики представляет собой коэффициент. Если нагрузка для метрики на наиболее загруженном узле, деленная на объем нагрузки на наименее загруженном узле, превышает пороговое значение балансировки, то кластер считается несбалансированным. В результате балансировка запускается при очередной проверке службой Cluster Resource Manager. Таймер MinLoadBalancingInterval задает частоту, с которой диспетчер кластерных ресурсов проверяет необходимость перераспределения нагрузки. Проверка не означает, что что-то действительно произойдет.
Пороговые значения балансировки задаются в определении кластера на основе метрик. Дополнительные сведения о метриках проверка в статье о метриках.
ClusterManifest.xml
<Section Name="MetricBalancingThresholds">
<Parameter Name="MetricName1" Value="2"/>
<Parameter Name="MetricName2" Value="3.5"/>
</Section>
Для автономных развертываний используется ClusterConfig.json, а для размещенных в Azure кластеров — Template.json.
"fabricSettings": [
{
"name": "MetricBalancingThresholds",
"parameters": [
{
"name": "MetricName1",
"value": "2"
},
{
"name": "MetricName2",
"value": "3.5"
}
]
}
]
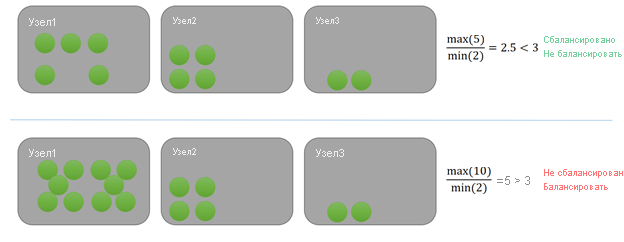
В этом примере каждая служба использует одну единицу определенной метрики. В верхнем примере максимальная нагрузка на узле составляет пять, а минимальная — два. Предположим, что пороговое значение балансировки для метрики — три. Так как коэффициент для кластера 5/2 = 2,5, что меньше указанного порогового значения балансировки, равного трем, кластер сбалансирован. При очередной проверке службой Cluster Resource Manager балансировка не запускается.
В примере ниже максимальная нагрузка на узле составляет десять, а минимальная — два (значит, коэффициент будет равен пяти). Пять больше установленного порогового значения балансировки для этой метрики, равного трем. В результате при следующем срабатывании таймера будет запланирован запуск перераспределения кластера. В такой ситуации некоторая нагрузка обычно распределяется на узел 3. Так как Resource Manager кластера Service Fabric не использует жадный подход, некоторая нагрузка также может быть распределена на узел 2.
Примечание
Для управления нагрузкой в кластере применяются две разные стратегии балансировки. Стратегия по умолчанию, которую использует диспетчер кластерных ресурсов, заключается в распределении нагрузки между узлами в кластере. Другой стратегией является дефрагментация. Дефрагментация выполняется во время того же цикла балансировки. Стратегии балансировки и дефрагментации могут использоваться для различных метрик в одном и том же кластере. У службы могут быть метрики балансировки и дефрагментации. Для метрик дефрагментации соотношение нагрузок в кластере активирует перебалансировку, когда она ниже порогового значения балансировки.
Превышение порогового значения балансировки не является явной целью. Пороговые значения балансировки — всего лишь триггеры. При выполнении балансировки диспетчер кластерных ресурсов определяет, какие улучшения он может внести, если это возможно. Сам по себе запуск балансировки не означает, что что-либо будет перемещено. Иногда кластер несбалансирован, но слишком ограничен для того, чтобы это можно было исправить. Кроме того, для внесения улучшений требуются перемещения, которые могут быть слишком дорогостоящими.
пороговые значения активности
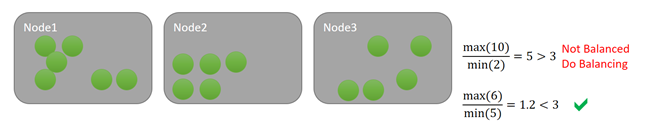
Иногда узлы могут быть относительно несбалансированными, даже если общий объем нагрузки в кластере небольшой. Отсутствие нагрузки может быть связано с ее временным снижением или с тем, что кластер только что создан и проходит начальную загрузку. В любом случае в такой ситуации можно не тратить время на балансировку кластера, так как это вряд ли принесет ощутимые результаты. Если кластер прошел балансировку, вы только потратите сетевые и вычислительные ресурсы на перемещение данных, а в результате не ощутите абсолютно никакой разницы. Чтобы ненужных перемещений, можно воспользоваться еще одним элементом управления под названием "Пороговые значения активности". С его помощью можно задать абсолютное значение нижней границы активности. Если это пороговое значение не превышено ни для одного узла, балансировка не запускается даже при достижении ее порогового значения.
Предположим, что для этой метрики задано пороговое значение балансировки, равное 3. Также предположим, что пороговое значение активности равно 1536. В первом случае согласно пороговому значению балансировки кластер несбалансирован, однако ни один из узлов не превышает пороговое значение активности, поэтому ничего не происходит. В нижнем примере узел 1 превышает пороговое значение действия. Так как для метрики превышены пороговые значения балансировки и активности, планируется балансировка. Например, рассмотрим схему ниже.

Как и пороговые значения балансировки, пороговые значения активности определяются в определении кластера на основе метрик:
ClusterManifest.xml
<Section Name="MetricActivityThresholds">
<Parameter Name="Memory" Value="1536"/>
</Section>
Для автономных развертываний используется ClusterConfig.json, а для размещенных в Azure кластеров — Template.json.
"fabricSettings": [
{
"name": "MetricActivityThresholds",
"parameters": [
{
"name": "Memory",
"value": "1536"
}
]
}
]
Пороговые значения балансировки и активности привязаны к определенной метрике. Балансировка запускается только тогда, когда оба эти пороговые значения превышены для одной метрики.
Примечание
Если ничего не указывать, пороговое значение балансировки для метрики будет равно 1, а пороговое значение активности — 0. Это означает, что диспетчер кластерных ресурсов будет сохранять оптимальную балансировку этой метрики для любой заданной нагрузки. Если вы используете пользовательские метрики, рекомендуется явно определить собственные пороговые значения балансировки и активности для метрик.
Одновременная балансировка служб
Несбалансированность кластера определяется на уровне кластера. Тем не менее мы исправим эту проблему, переместив отдельные реплики и экземпляры служб. Звучит разумно, не правда ли? Если память накапливается в одном узле, это может быть вызвано сразу несколькими репликами или экземплярами. Для устранения дисбаланса может потребоваться перемещение всех реплик с отслеживанием состояния или экземпляров без отслеживания состояния, для которых используется несбалансированная метрика.
В отдельных случаях перемещается служба, которая сама по себе не была несбалансированной (вспомните обсуждение локальных и глобальных весов, приведенное ранее). Почему же служба перемещается, если все ее метрики сбалансированы? Рассмотрим пример.
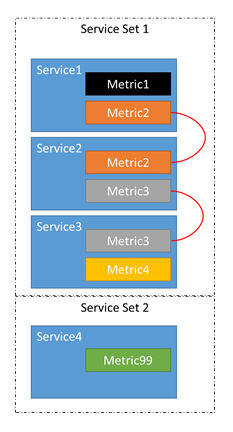
- Предположим, есть четыре службы: служба 1, служба 2, служба 3 и служба 4.
- Служба 1 сообщает о метриках 1 и метрика 2.
- Служба 2 сообщает метрики Метрики 2 и Метрика 3.
- Служба 3 сообщает о метриках 3 и метрика 4.
- Служба 4 сообщает метрику 99.
Мы имеем дело не с четырьмя независимыми службами, а с тремя связанными службами и одной отдельной службой.
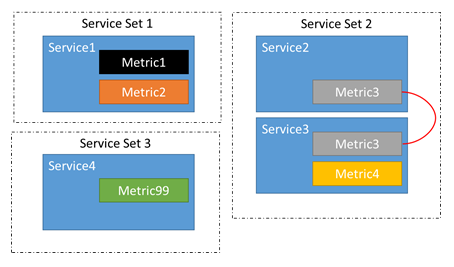
Из-за этой цепочки вполне возможно, что дисбаланс в метриках Metric1–Metric4 может привести к перемещению реплик или экземпляров, относящихся к службам Service1–Service3. Мы также знаем, что дисбаланс в метриках 1, 2 или 3 не может привести к перемещению в службе 4. Нет смысла, так как перемещение реплик или экземпляров, принадлежащих службе 4, не может повлиять на баланс метрик 1–3.
Диспетчер кластерных ресурсов автоматически определяет, какие службы связаны. Добавление, удаление или изменение метрик для служб может влиять на их связи. Например, между двумя запусками балансировки служба 2 могла быть обновлена, чтобы удалить метрику 2. Это разорвет цепочку между службой 1 и службой 2. В этом случае две группы связанных служб превратятся в три.
Балансировка кластера на тип узла
Как мы уже говорили в предыдущих разделах, main элементами управления активацией перебалансировки являются пороговые значения активности, балансировка пороговых значений и таймеры. Кластер Service Fabric Resource Manager обеспечивает более детализированный контроль над активацией перебалансировки с указанием параметров для каждого типа узла и разрешением перемещения только на несбалансированных типах узлов. Преимущество main балансировки по типам узлов позволяет повысить производительность для типов узлов, требующих более строгих правил балансировки, без снижения производительности на других типах узлов. Компонент содержит две main части:
- Обнаружение дисбаланса выполняется для каждого типа узла. Ранее глобальное вычисление дисбаланса вычисляется для каждого типа узла. Если все типы узлов сбалансированы, CRM не активирует этап балансировки. В противном случае, если хотя бы один тип узла несбалансирован, требуется этап балансировки.
- Балансировка перемещает реплики только на несбалансированных типах узлов, другие типы узлов не затрагиваются этапом балансировки.
Влияние балансировки на тип узла на кластер
Во время балансировки кластера для каждого типа узла кластер Service Fabric Resource Manager вычисляет состояние дисбаланса для каждого типа узла. Если хотя бы один тип узла несбалансирован, активируется этап балансировки. Этап балансировки не перемещает реплики на несбалансированных типах узлов, если балансировка временно приостановлена на этих типах узлов (например, минимальный интервал балансировки не прошел с предыдущего этапа балансировки). При обнаружении несбалансированного состояния используются распространенные механизмы, уже доступные для классической балансировки кластеров, но повышает степень детализации и гибкость конфигурации. Механизмы, используемые для балансировки по типам узлов для обнаружения дисбаланса, приведены в следующем списке:
- Пороговые значения балансировки метрик для каждого типа узла — это значения, которые имеют ту же роль, что и глобально определенное пороговое значение балансировки, используемое в классической балансировке. Соотношение минимальной и максимальной нагрузки метрики вычисляется для каждого типа узла. Если это отношение типа узла выше определенного порогового значения балансировки для типа узла, тип узла помечается как несбалансированный. Дополнительные сведения о настройке пороговых значений активности метрик для каждого типа узла проверка разделе Пороговые значения балансировки для каждого типа узла.
- Пороговые значения активности метрик для каждого типа узла — это значения, которые имеют аналогичную роль глобально определенному порогу активности, используемому в классической балансировке. Максимальная нагрузка на метрики рассчитывается для каждого типа узла. Если максимальная нагрузка типа узла выше определенного порогового значения активности для этого типа узла, тип узла помечается как несбалансированный. Дополнительные сведения о настройке пороговых значений активности метрик для каждого типа узла проверка разделе activity-thresholds-per-node-type.
- Минимальный интервал балансировки для каждого типа узла имеет роль, аналогичную глобально определенному минимальному интервалу балансировки. Для каждого типа узла Resource Manager кластера сохраняет метку времени последней балансировки. Не удалось выполнить два последовательных этапа балансировки для типа узла в пределах определенного минимального интервала балансировки. Дополнительные сведения о настройке минимального интервала балансировки для каждого типа узла проверка разделе Минимальный интервал балансировки для каждого типа узла.
Описание балансировки по типу узла
Чтобы включить балансировку для каждого типа узла, в манифесте кластера необходимо включить параметр SeparateBalancingStrategyPerNodeType. Кроме того, необходимо также включить функцию подкластеринга. Пример раздела PlacementAndLoadBalancing манифеста кластера для включения этой функции:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="SeparateBalancingStrategyPerNodeType" Value="true" />
<Parameter Name="SubclusteringEnabled" Value="true" />
<Parameter Name="SubclusteringReportingPolicy" Value="1" />
</Section>
ClusterConfig.json для автономных развертываний или Template.json для кластеров, размещенных в Azure:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "SeparateBalancingStrategyPerNodeType",
"value": "true"
},
{
"name": "SubclusteringEnabled",
"value": "true"
},
{
"name": "SubclusteringReportingPolicy",
"value": "1"
},
]
}
]
Как описано в предыдущем разделе, пороговые значения и интервалы можно указать для каждого типа узла. Дополнительные сведения об обновлении определенного параметра проверка следующих разделах:
- Пороговые значения балансировки метрик для каждого типа узла
- Пороговые значения активности метрик для каждого типа узла
- Минимальный интервал балансировки для каждого типа узла
Балансировка пороговых значений для каждого типа узла
Пороговое значение балансировки метрик можно определить для каждого типа узла, чтобы повысить степень детализации конфигурации балансировки. Пороговые значения балансировки имеют тип с плавающей запятой, так как они представляют пороговое значение для соотношения максимального и минимального значений нагрузки в пределах определенного типа узла. Пороговые значения балансировки определяются в разделе PlacementAndLoadBalancingOverrides для каждого типа узла:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricBalancingThresholdsPerNodeType>
<BalancingThreshold Name="Metric1" Value="2.5">
<BalancingThreshold Name="Metric2" Value="4">
<BalancingThreshold Name="Metric3" Value="3.25">
</MetricBalancingThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
Если пороговое значение балансировки для метрики не определено для типа узла, пороговое значение наследует значение порогового значения балансировки метрики, определенного глобально в разделе PlacementAndLoadBalancing . В противном случае, если пороговое значение балансировки для метрики не определено ни для типа узла, ни глобально в разделе PlacementAndLoadBalancing, пороговое значение будет иметь значение по умолчанию .
Пороговые значения активности для каждого типа узла
Порог активности метрик можно определить для каждого типа узла, чтобы повысить степень детализации конфигурации балансировки. Пороговые значения активности имеют целочисленный тип, так как они представляют собой пороговое значение максимальной нагрузки в пределах определенного типа узла. Пороговые значения действий определяются в разделе PlacementAndLoadBalancingOverrides для каждого типа узла:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricActivityThresholdsPerNodeType>
<ActivityThreshold Name="Metric1" Value="500">
<ActivityThreshold Name="Metric2" Value="40">
<ActivityThreshold Name="Metric3" Value="1000">
</MetricActivityThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
Если пороговое значение активности для метрики не определено для типа узла, пороговое значение наследует от порогового значения действия метрики, определенного глобально в разделе PlacementAndLoadBalancing . В противном случае, если порог активности для метрики не определен ни для типа узла, ни глобально в разделе PlacementAndLoadBalancing , пороговое значение по умолчанию будет равно нулю.
Минимальный интервал балансировки для каждого типа узла
Для каждого типа узла можно определить минимальный интервал балансировки, чтобы повысить степень детализации конфигурации балансировки. Минимальный интервал балансировки имеет целочисленный тип, так как представляет собой минимальное количество времени, которое должно пройти до двух последовательных циклов балансировки на одном узле. Минимальный интервал балансировки определен в разделе PlacementAndLoadBalancingOverrides для каждого типа узла:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MinLoadBalancingIntervalPerNodeType>100</MinLoadBalancingIntervalPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
Если минимальный интервал балансировки не определен для типа узла, интервал наследует значение от минимального интервала балансировки, определенного глобально в разделе PlacementAndLoadBalancing . В противном случае, если минимальный интервал не определен ни для типа узла, ни глобально в разделе PlacementAndLoadBalancing , минимальный интервал будет иметь нулевое значение по умолчанию, указывающее, что пауза между последовательными раундами балансировки не требуется.
Примеры
Пример 1
Рассмотрим случай, когда кластер содержит два типа узлов: тип узла A и узел типа B. Все службы сообщают одну и ту же метрику, и они разделены между этими типами узлов, поэтому статистика загрузки для них отличается. В этом примере узел типа A имеет максимальную нагрузку 300 и не менее 100, а узел типа B имеет максимальную нагрузку 700 и минимальную нагрузку 500:

Клиент обнаружил, что рабочие нагрузки двух типов узлов имеют разные потребности в балансировке, и решил задать разные пороговые значения балансировки и активности для каждого типа узла. Пороговое значение балансировки узла типа A равно 2,5, а пороговое значение активности — 50. Для узла типа B клиент устанавливает пороговое значение балансировки 1.2, а пороговое значение активности — 400.
При обнаружении дисбаланса для кластера в этом примере оба типа узлов нарушают пороговое значение активности. Максимальная нагрузка узла типа Aв 300 выше определенного порогового значения активности 50. Максимальная нагрузка узла типа Bв 700 выше определенного порогового значения активности 400. Узел типа A нарушает пороговые критерии балансировки, так как текущее соотношение максимальной и минимальной нагрузки равно 3, а пороговое значение балансировки — 2,5. Напротив, тип узла B не нарушает пороговые критерии балансировки, так как текущее соотношение максимальной и минимальной нагрузки для этого типа узла равно 1,2, а пороговое значение балансировки — 1,4. Балансировка требуется только для реплик в узле типа A, и единственным набором реплик, которые будут доступны для перемещения на этапе балансировки, являются реплики, размещенные в узле типа A.
Пример 2
Рассмотрим случай, когда кластер содержит три типа узлов: узел типа A, B и C. Все службы сообщают одну и ту же метрику, и они разделены между этими типами узлов, поэтому статистика загрузки для них отличается. В этом примере тип узла A имеет максимальную нагрузку 600 и не менее 100, узел типа B имеет максимальную нагрузку 900 и минимальную нагрузку 100, а тип узла C — максимальную нагрузку 600 и минимальную нагрузку 300:

Клиент обнаружил, что рабочие нагрузки этих типов узлов имеют разные потребности в балансировке, и решил задать разные пороговые значения балансировки и активности для каждого типа узла. Пороговое значение балансировки узла типа A равно 5, а пороговое значение активности — 700. Для узла типа B клиент устанавливает пороговое значение балансировки равным 10, а пороговое значение активности — 200. Для типа узла C клиент устанавливает пороговое значение балансировки 2, а пороговое значение действия — 300.
Максимальная нагрузка узла типа A600 ниже определенного порогового значения активности 700, поэтому тип узла A не будет сбалансирован. Максимальная нагрузка узла типа Bв 900 выше определенного порогового значения активности 200. Узел типа B нарушает пороговые условия действия. Максимальная нагрузка узла типа C600 выше определенного порогового значения активности 300. Тип узла C нарушает пороговые условия действия. Узел типа B не нарушает пороговые критерии балансировки, так как текущее соотношение максимальной и минимальной нагрузки для этого типа узла равно 9, а пороговое значение балансировки — 10. Узел типа C нарушает пороговые критерии балансировки, так как текущее соотношение максимальной и минимальной нагрузки равно 2, а пороговое значение балансировки — 2. Балансировка требуется только для реплик в узле типа C, и единственным набором реплик, которые будут доступны для перемещения на этапе балансировки, являются реплики, размещенные в узле типа C.
Дальнейшие действия
- Метрики показывают, как диспетчер кластерных ресурсов Service Fabric управляет потреблением и емкостью в кластере. Чтобы узнать больше о метриках и их настройке, проверка статью о метриках.
- Стоимость перемещения — один из способов сообщить диспетчеру кластерных ресурсов, что некоторые службы перемещать затратнее, чем остальные. Дополнительные сведения о стоимости перемещения см. в статье стоимость перемещения.
- В диспетчере кластерных ресурсов имеется несколько регулировок, которые можно настроить, чтобы замедлить отток в кластере. Обычно они не нужны, но если они вам нужны, см. статью о расширенном регулировании.
- Кластер Resource Manager может распознавать и обрабатывать подкластеризацию. Подкластерия может возникнуть при использовании ограничений размещения и балансировки. Сведения о том, как подкластерия может повлиять на балансировку и как ее можно обрабатывать, см. в статье о подкластерировании.