Шаблоны для разработки таблиц
В этой статье приводится описание некоторых шаблонов, которые подходят для использования с решениями для службы таблиц. Кроме того, вы увидите практическое решение ряда проблем и сможете выбрать компромиссный вариант из предлагаемых в других статьях о разработке для хранилища таблиц. На следующей схеме показаны связи между различными шаблонами.
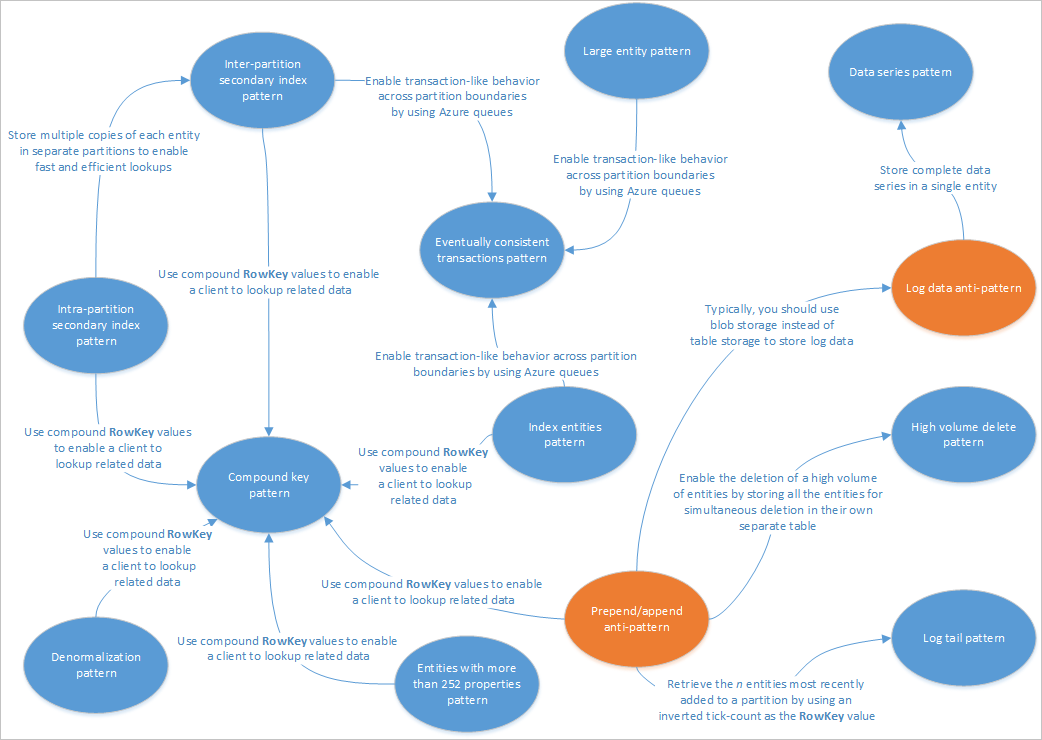
На схеме шаблонов представлены некоторые связи между шаблонами (синий цвет) и антишаблонами (оранжевый цвет), которые приведены в этом руководстве. Существует множество других шаблонов, на которые стоит обратить внимание. Например, один из основных сценариев для службы таблиц — использование шаблона материализованного представления из шаблона Разделение ответственности команд и запросов (CQRS).
Шаблон вторичного индекса внутри раздела
Хранение нескольких копий каждой сущности с помощью различных значений RowKey (в одном разделе) для выполнения быстрых и эффективных операций поиска и активации альтернативных порядков сортировки с помощью различных значений RowKey. Согласованность обновлений между копиями можно поддерживать посредством транзакций группы сущностей (EGT).
Контекст и проблема
Служба таблиц автоматически индексирует сущности с помощью значений PartitionKey и RowKey. Это позволяет клиентскому приложению эффективно извлекать сущности с использованием этих значений. Например, используя приведенную ниже структуру таблицы, клиентское приложение может выполнить точечный запрос для извлечения отдельной сущности сотрудника с указанием названия отдела и идентификатора сотрудника (значения PartitionKey и RowKey). Клиент также может извлекать сущности, отсортированные по идентификатору сотрудника в каждом отделе.

Чтобы найти сущность сотрудника на основе другого свойства (например, адрес электронной почты), необходимо использовать менее эффективную функцию просмотра раздела. Это связано с тем, что служба таблиц не поддерживает вторичные индексы. Кроме того, невозможно запросить список сотрудников, отсортированный в порядке, отличном от RowKey.
Решение
Чтобы решить проблему отсутствия вторичных индексов, можно сохранить несколько копий каждой сущности с каждой копией, используя другое значение RowKey. При сохранении сущностей с приведенными ниже структурами можно эффективно извлекать сущности сотрудников на основе адреса электронной почты или идентификатор сотрудника. Значения префиксов empid_ и email_ для RowKey позволяют выполнять запросы для одного сотрудника или ряда сотрудников с помощью диапазона адресов электронной почты или идентификаторов сотрудников.

Следующие два условия фильтрации (одно для поиска по идентификатору сотрудника и второе для поиска по адресу электронной почты сотрудника) задают точечные запросы.
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'email_jonesj@contoso.com')
Если требуется запросить диапазон сущностей сотрудников, можно указать диапазон, отсортированный по идентификаторам сотрудников или по их адресам электронной почты, выполнив запрос на сущности с соответствующим префиксом в свойстве RowKey.
Чтобы найти всех сотрудников отдела продаж с идентификатором в диапазоне от 000100 до 000199, используйте следующее условие фильтрации: $filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000100') and (RowKey le 'empid_000199').
Чтобы найти всех сотрудников отдела продаж с адресом электронной почты, начинающимся с буквы "a", используйте следующее условие фильтрации: $filter=(PartitionKey eq 'Sales') and (RowKey ge 'email_a') and (RowKey lt 'email_b').
Синтаксис фильтрации, используемый в приведенных выше примерах, взят из REST API службы таблиц. Дополнительные сведения см. в статье Query Entities (Сущности запроса).
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
Хранилище таблиц является относительно недорогим в использовании, поэтому накладные расходы на хранение повторяющихся данных не являются предметом первостепенной важности. Однако затраты на разработку всегда следует оценивать с учетом требований к планируемому хранилищу и добавлять повторяющиеся сущности только в целях поддержки запросов, которые будет выполнять клиентское приложение.
Поскольку сущности вторичного индекса хранятся в одном разделе с исходными сущностями, следует убедиться в том, что целевые показатели масштабируемости для отдельного раздела не превышены.
Чтобы обеспечить согласованность повторяющихся сущностей, можно воспользоваться транзакциями группы сущностей (EGT) для автоматического обновления двух копий сущности. Это означает, что все копии сущности необходимо хранить в одном разделе. Дополнительные сведения см. в разделе Транзакции группы сущностей.
Значение свойства RowKey должно быть уникальным для каждой сущности. Рекомендуется использовать значения составного ключа.
Заполнение числовых значений в свойстве RowKey (например, для идентификатора сотрудника 000223) позволяет правильно выполнять операции сортировки и фильтрации на основе верхних и нижних границ.
Дублировать все свойства сущности не требуется. Например, если для запросов, которые ищут сущности по электронному адресу в RowKey, не требуется возраст сотрудника, то эти сущности могут иметь следующую структуру.

Рекомендуется сохранить повторяющиеся данные и убедиться в том, что все необходимые данные можно получить с помощью одного запроса, а не использовать один запрос для поиска сущности, а другой — для поиска необходимых данных.
Когда следует использовать этот шаблон
Используйте этот шаблон, если клиентскому приложению требуется извлечь сущности с помощью множества различных ключей, если клиенту требуется извлечь сущностей в различных порядках сортировки и если каждую сущность можно определить с помощью целого ряда уникальных значений. При выполнении поисков сущностей с использованием различных значений RowKey следует убедиться, что целевые показатели масштабируемости раздела не превышены.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Шаблон вторичного индекса в разных разделах;
- Шаблон составного ключа;
- Транзакции группы сущностей
- Работа с разными типами сущностей
Шаблон вторичного индекса в разных разделах;
Храните несколько копий каждой сущности с помощью различных значений RowKey в отдельных разделах или отдельных таблицах для выполнения быстрых и эффективных операций поиска и активации альтернативных порядков сортировки с помощью различных значений RowKey.
Контекст и проблема
Служба таблиц автоматически индексирует сущности с помощью значений PartitionKey и RowKey. Это позволяет клиентскому приложению эффективно извлекать сущности с использованием этих значений. Например, используя приведенную ниже структуру таблицы, клиентское приложение может выполнить точечный запрос для извлечения отдельной сущности сотрудника с указанием названия отдела и идентификатора сотрудника (значения PartitionKey и RowKey). Клиент также может извлекать сущности, отсортированные по идентификатору сотрудника в каждом отделе.

Чтобы найти сущность сотрудника на основе другого свойства (например, адрес электронной почты), необходимо использовать менее эффективную функцию просмотра раздела. Это связано с тем, что служба таблиц не поддерживает вторичные индексы. Кроме того, невозможно запросить список сотрудников, отсортированный в порядке, отличном от RowKey.
Вы планируете выполнять множество операций с этими сущностями и хотите свести к минимуму риск регулирования клиента со стороны службы таблиц.
Решение
Чтобы решить проблему отсутствия вторичных индексов, можно сохранить несколько копий каждой сущности с каждой копией, используя различные значения PartitionKey и RowKey. При сохранении сущностей с приведенными ниже структурами можно эффективно извлекать сущности сотрудников на основе адреса электронной почты или идентификатор сотрудника. Значения префиксов empid_ и email_ для PartitionKey позволяют определить нужный индекс, который будет использоваться для запроса.

Следующие два условия фильтрации (одно для поиска по идентификатору сотрудника и второе для поиска по адресу электронной почты сотрудника) задают точечные запросы.
- $filter=(PartitionKey eq 'empid_Sales') and (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') and (RowKey eq 'jonesj@contoso.com')
Если требуется запросить диапазон сущностей сотрудников, можно указать диапазон, отсортированный по идентификаторам сотрудников или по их адресам электронной почты, выполнив запрос на сущности с соответствующим префиксом в свойстве RowKey.
- Чтобы найти всех сотрудников отдела продаж с идентификатором сотрудника в диапазоне от 000100 до 000199, отсортированных по идентификатору сотрудника, используйте следующее условие: $filter=(PartitionKey eq 'empid_Sales') and (RowKey ge '000100') and (RowKey le '000199').
- Чтобы найти всех сотрудников отдела продаж с адресом электронной почты, который начинается с "a", и сортировкой по ИД сотрудника, используйте следующее условие: $filter=(PartitionKey eq 'email_Sales') and (RowKey ge 'a') and (RowKey lt 'b').
Синтаксис фильтрации, используемый в приведенных выше примерах, взят из REST API службы таблиц. Дополнительные сведения см. в статье Query Entities (Сущности запроса).
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
Чтобы обеспечить согласованность копий сущностей, можно использовать шаблон для согласованных транзакций для сущностей основного и вторичного индексов.
Хранилище таблиц является относительно недорогим в использовании, поэтому накладные расходы на хранение повторяющихся данных не являются предметом первостепенной важности. Однако затраты на разработку всегда следует оценивать с учетом требований к планируемому хранилищу и добавлять повторяющиеся сущности только в целях поддержки запросов, которые будет выполнять клиентское приложение.
Значение свойства RowKey должно быть уникальным для каждой сущности. Рекомендуется использовать значения составного ключа.
Заполнение числовых значений в свойстве RowKey (например, для идентификатора сотрудника 000223) позволяет правильно выполнять операции сортировки и фильтрации на основе верхних и нижних границ.
Дублировать все свойства сущности не требуется. Например, если для запросов, которые ищут сущности по электронному адресу в RowKey, не требуется возраст сотрудника, то эти сущности могут иметь следующую структуру.
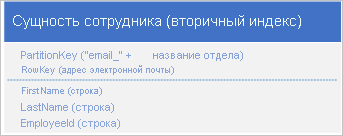
Повторяющиеся данные рекомендуется сохранить и убедиться, что все необходимые данные можно извлечь с помощью одного запроса, вместо того, чтобы выполнять один запрос для поиска сущности с помощью вторичного индекса, а другой — для поиска необходимых данных в первичном индексе.
Когда следует использовать этот шаблон
Используйте этот шаблон, если клиентскому приложению требуется извлечь сущности с помощью множества различных ключей, если клиенту требуется извлечь сущностей в различных порядках сортировки и если каждую сущность можно определить с помощью целого ряда уникальных значений. Используйте этот шаблон, если при поиске сущностей с помощью различных значений RowKey нужно избежать превышения показателей ограничения масштабирования раздела.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Шаблон для согласованных транзакций;
- Шаблон вторичного индекса внутри раздела;
- Шаблон составного ключа;
- Транзакции группы сущностей
- Работа с разными типами сущностей
Шаблон для согласованных транзакций;
Обеспечьте согласованное поведение в рамках границ раздела или границ системы хранения с помощью запросов Azure.
Контекст и проблема
Транзакции группы сущностей приводят к выполнению атомарных транзакций в нескольких сущностях, использующих один общий ключ раздела. Из соображений производительности и масштабируемости может потребоваться сохранить сущности согласно требованиям к согласованности в отдельных разделах или отдельной системе хранения. В этом случае использовать транзакции группы сущностей для обеспечения согласованности нельзя. Например, может существовать требование к обеспечению согласованности между следующими элементами.
- Сущности, хранящиеся в двух разных секциях одной таблицы, в разных таблицах или в разных учетных записях хранения.
- Сущность, хранящаяся в службе таблиц, и большой двоичный объект, хранящийся в службе BLOB-объектов.
- Сущность, хранящаяся в службе таблиц, и файл в файловой системе.
- Сущность, хранящаяся в службе таблиц, но проиндексированная с помощью службы "Когнитивный поиск Azure".
Решение
Используя очереди Azure, можно реализовать решение, обеспечивающее согласованность между двумя и более разделами или системами хранения. Чтобы продемонстрировать этот подход, предположим, что существует требование к архивации старых сущностей сотрудников. К старым сущностям сотрудников редко выполняются запросы, поэтому они должны быть исключены из любых действий, связанных с текущими сотрудниками. Чтобы реализовать это требование, действующие сотрудники сохраняются в таблице Current, а бывшие сотрудники — в таблице Archive. Для архивации сотрудника необходимо удалить сущность из таблицы Current и добавить сущность в таблицу Archive. Но для выполнения этих двух операций нельзя использовать транзакции группы сущностей. Чтобы избежать риска отображения сущности в обеих таблицах или ни в одной из них в случае сбоя, операция архивации должна быть согласованной. Этапы этой операции приведены на следующей схеме. Дополнительные сведения об исключениях см. далее.
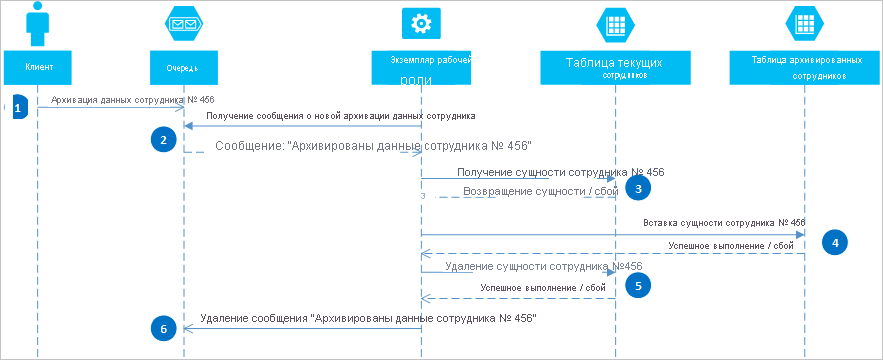
Клиент инициирует операцию архивации, помещая сообщение в очередь Azure. В этом примере выполняется архивация сотрудника №456. Рабочая роль опрашивает очередь на наличие новых сообщений. При обнаружении такого сообщения она читает сообщение и оставляет в очереди скрытую копию. Затем рабочая роль извлекает копию сущности из таблицы Current, вставляет копию в таблицу Archive и после этого удаляет исходную сущность из таблицы Current. Если предыдущие действия выполнены без ошибок, рабочая роль удаляет скрытое сообщения из очереди.
В этом примере на шаге 4 происходит вставка сотрудника в таблицу Archive . Сотрудника можно добавить в большой двоичный объект в службе BLOB-объектов или в файл в файловой системе.
Восстановление после сбоев
Важно отметить, что, если рабочей роли требуется перезапустить операцию архивации, операции на шагах 4 и 5 должны быть идемпотентными. Если используется служба таблиц, на шаге 4 необходимо выполнить операцию "Вставить или заменить". На шаге 5 в клиентской библиотеке необходимо выполнить операцию "Удалить, если существует". Если используется другая система хранения данных, необходимо выполнить соответствующую идемпотентную операцию.
Если рабочая роль никогда не выполняет действие на шаге 6, по истечении времени ожидания сообщение повторно появится в очереди, чтобы рабочая роль могла обработать его еще раз. Рабочая роль может проверить, сколько раз было прочтено сообщение в очереди, и при необходимости пометит его как «подозрительное» и требующее изучения, отправив в отдельную очередь. Дополнительные сведения о чтении сообщений в очередях и проверке количества сообщений, выведенных из очереди, см. в статье о получении сообщений.
Некоторые ошибки в службах очередей и таблиц являются временными, поэтому клиентское приложение должно содержать логику повтора, подходящую для их обработки.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Это решение не поддерживает изоляцию транзакций. Например, клиент мог считывать таблицы Current и Archive, когда рабочая роль находилась между шагами 4 и 5, и заметить несогласованное представление данных. В конечном счете данные будут согласованы.
- Необходимо убедиться, что для обеспечения окончательной согласованности окончательной шаги 4 и 5 являются идемпотентными.
- Для масштабирования решения можно использовать несколько очередей и экземпляров рабочих ролей.
Когда следует использовать этот шаблон
Используйте этот шаблон, чтобы обеспечить согласованность между сущностями, которые существуют в различных разделах или таблицах. Этот шаблон можно расширить и обеспечить согласованность операций в службе таблиц и службе BLOB-объектов, а также в других источниках данных, не входящих в службу хранения Azure, таких как база данных или файловая система.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Транзакции группы сущностей
- Объединение или замена.
Примечание.
Если изоляция транзакции имеет важное значение для решения, рекомендуется переработать таблицы для использования транзакций группы сущностей.
Шаблон сущностей индекса
Поддерживайте сущности индексов для выполнения эффективных операций поиска, возвращающих списки сущностей.
Контекст и проблема
Служба таблиц автоматически индексирует сущности с помощью значений PartitionKey и RowKey. Это позволяет клиентскому приложению эффективно извлекать сущность с помощью запроса точки. Например, используя приведенную ниже структуру таблицы, клиентское приложение может эффективно извлекать сущность отдельного сотрудника с помощью названия отдела и идентификатора сотрудника (PartitionKey и RowKey).

Если наряду с этим необходимо извлекать список сущностей сотрудников на основе значения другого неуникального свойства, например фамилий, для поиска совпадений следует использовать менее эффективную функцию просмотра раздела, а не индекс для прямого поиска. Это связано с тем, что служба таблиц не поддерживает вторичные индексы.
Решение
Чтобы включить поиск по фамилии с помощью структуры сущности, приведенной выше, необходимо создать и поддерживать списки идентификаторов сотрудников. Чтобы извлечь сущности сотрудников с определенной фамилией, например Jones, сначала найдите список кодов для сотрудников с фамилией Jones, а затем извлеките сущности этих сотрудников. Существует три основных варианта хранения списков кодов сотрудников.
- Использование хранилища больших двоичных объектов.
- Создание сущностей индексов в одном разделе с сущностями сотрудников.
- Создание сущностей индексов в отдельном разделе или таблице.
Вариант № 1. Использование хранилища больших двоичных объектов
В этом случае вы создаете большой двоичный объект для каждой уникальной фамилии, а затем в каждом таком объекте сохраняете список значений PartitionKey (отдел) и RowKey (идентификатор сотрудника) для сотрудников с этой фамилией. При добавлении или удалении сотрудника следует убедиться, что содержимое соответствующего большого двоичного объекта согласовано с сущностями сотрудников.
Вариант 2. Создание сущностей индексов в одном разделе с сущностями сотрудников
В этом случае используйте сущности индексов, хранящие следующие данные.
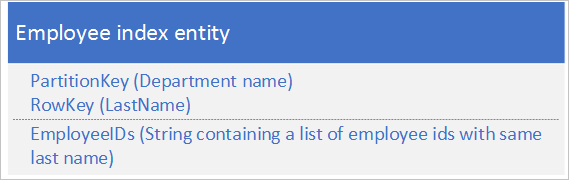
Свойство EmployeeIDs содержит список идентификаторов для сотрудников, фамилии которых хранятся в свойстве RowKey.
Ниже описан процесс, которого следует придерживаться при добавлении нового сотрудника при использовании второго варианта. В этом примере мы добавляем сотрудника с идентификатором 000152 и фамилией Jones в отдел продаж.
- Извлеките сущность индекса с помощью значения PartitionKey "Sales" и значения RowKey "Jones". Сохраните ETag этой сущности для использования на шаге 2.
- Создайте транзакцию группы сущностей, которая вставляет новую сущность сотрудника (значение PartitionKey Sales и значение RowKey 000152) и обновляет сущность индекса (значение PartitionKey Sales и значение RowKey Jones), добавив новый идентификатор сотрудника в список в поле EmployeeIDs. Сведения о транзакциях группы сущностей см. в разделе "Транзакции группы сущностей".
- Если транзакция группы сущностей не может быть выполнена из-за ошибки оптимистичного параллелизма (другой пользователь только что изменил сущность индекса), необходимо вернуться к шагу 1.
Если используется второй вариант, можно использовать аналогичный подход для удаления сотрудника. Изменить фамилию сотрудника немного сложнее, поскольку потребуется выполнить транзакцию группы сущностей для обновления трех сущностей: сущности сотрудника, сущности индекса для старой фамилии и сущности индекса для новой фамилии. Перед внесением любых изменений необходимо извлекать каждую сущность для последующего получения значений ETag, которые затем можно использовать для выполнения обновлений с помощью оптимистичного параллелизма.
Если используется второй вариант, следуйте приведенной далее процедуре поиска всех сотрудников отдела с нужной фамилией. В этом примере осуществляется поиск всех сотрудников с фамилией Jones в отделе продаж.
- Извлеките сущность индекса с помощью значения PartitionKey Sales и значения RowKey Jones.
- Выполните анализ списка идентификаторов сотрудников в поле EmployeeIDs.
- Чтобы получить дополнительные сведения о каждом из этих сотрудников (например, адрес электронной почты), извлеките каждую сущность сотрудника с помощью значения PartitionKey Sales и значений RowKey из списка сотрудников, полученного на шаге 2.
Вариант 3. Создание сущностей индексов в отдельном разделе или таблице
Для этого варианта используйте сущности индексов, хранящих следующие данные.

Свойство EmployeeDetails содержит список идентификаторов сотрудников и названий подразделений для сотрудников, фамилии которых хранятся в свойстве RowKey.
В третьем случае использовать транзакции группы сущностей для обеспечения согласованности нельзя, поскольку сущности индексов находятся в разделе, отличном от раздела с сущностями сотрудников. Убедитесь, что сущности индексов согласованы с сущностями сотрудников.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- В этом решении требуется как минимум два запроса для извлечения совпадающих сущностей: один для запроса сущностей индексов с целью получения списка значений RowKey , а другой — для извлечения каждой сущности в списке.
- С учетом того что размер отдельной сущности не превышает 1 МБ, в вариантах 2 и 3 решения предполагается, что размер списка идентификаторов сотрудников с любой заданной фамилией никогда не будет больше 1 МБ. Если размер списка идентификаторов сотрудников с большой вероятностью превышает 1 МБ, следует использовать вариант 1 и сохранить данные индекса в хранилище BLOB-объектов.
- Если выбран вариант 2 (с использованием транзакций группы сущностей для обработки операций добавления и удаления сотрудников и изменения фамилии сотрудника), то необходимо оценить отношение объема транзакций к ограничениям масштабируемости в определенном разделе. Если значение объема транзакций приближается к ограничениям, рекомендуется обратить внимание на согласованное решение (вариант 1 или 3), которое использует очереди для обработки запросов на обновление и позволяет хранить сущности индексов в разделе, отличном от раздела с сущностями сотрудников.
- Вариант 2 в этом решении предполагает, что поиск в рамках отдела будет выполняться по фамилии. Например, нужно получить список сотрудников с фамилией Jones из отдела продаж. Чтобы получить возможность поиска всех сотрудников с фамилией Jones в масштабах организации, выберите вариант 1 или 3.
- Можно развернуть решение на основе очереди, что обеспечит согласованность (дополнительные сведения см. в разделе Шаблон для согласованных транзакций).
Когда следует использовать этот шаблон
Используйте этот шаблон для поиска набора сущностей с общим значением свойства, например всех сотрудников с фамилией Jones.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Шаблон составного ключа;
- Шаблон для согласованных транзакций;
- Транзакции группы сущностей
- Работа с разными типами сущностей
Шаблон денормализации
Объедините связанные данных в одной сущности для извлечения необходимых данных с помощью одного запроса точки.
Контекст и проблема
В реляционной базе данных нормализация данных обычно выполняется для удаления дубликатов, что приводит к созданию запросов для извлечения данных из нескольких таблиц. Если нормализация данных осуществляется в таблицах Azure, для извлечения связанных данных требуется сделать несколько переходов от клиента к серверу и обратно. Например, чтобы получить сведения об отделе при использовании показанной ниже структуры таблицы, необходимо два круговых пути: один для получения сущности отдела, включающей идентификатор руководителя, а затем выполнить другой запрос для получения сведений о руководителе в сущности сотрудника.

Решение
Вместо хранения данных в двух отдельных сущностях денормализуйте данные и сохраните копию со сведениями о руководителе в сущности отдела. Например:
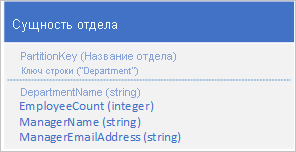
Теперь когда сущности отделов хранятся с этими свойствами, все сведения об отделе можно получать с помощью запроса точки.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Двойное хранение некоторых данных связано с определенными издержками. Повышение производительности (достигаемое в результате сокращения количества запросов к службе хранилища) обычно перевешивает незначительный рост затрат на хранение (эти затраты частично компенсируются снижением количества транзакций для получения сведения об отделе).
- Необходимо поддерживать согласованность двух сущностей, в которых хранятся сведения о руководителях. Для решения проблем согласованности можно воспользоваться транзакциями групп сущностей, которые обновляют несколько сущностей с помощью одной атомарной транзакции. В этом случае сущность отдела и сущность сотрудника для руководителя отдела хранятся в одном разделе.
Когда следует использовать этот шаблон
Используйте этот шаблон, если необходимость поиска связанных данных возникает довольно часто. Этот шаблон уменьшает количество запросов, которые необходимо выполнить клиенту для извлечения требуемых данных.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Шаблон составного ключа;
- Транзакции группы сущностей
- Работа с разными типами сущностей
Шаблон составного ключа;
Используйте составные значения RowKey, чтобы клиент мог выполнять поиск связанных данных с помощью одного точечного запроса.
Контекст и проблема
В реляционной базе данных считается естественным использовать присоединения в запросах с целью возврата связанных частей данных в клиент в одном запросе. Например, с помощью идентификатора сотрудника можно выполнить поиск списка связанных сущностей, которые содержат данные о производительности этого сотрудника.
Предположим, что сущности сотрудников хранятся в службе таблиц с использованием следующей структуры.

Необходимо также сохранить исторические данные, связанные с производительностью и оценкой продуктивности по каждому году, отработанному сотрудников в организации. Кроме того, эти данные должны быть доступны по каждому году. Одним из вариантов является создание другой таблицы, в которой хранятся сущности со следующей структурой.

Обратите внимание, что в этом случае вы можете дублировать некоторые сведения (например, имя и фамилию) в новую сущность, чтобы затем извлекать данные с помощью одного запроса. Но вы не можете поддерживать высокий уровень согласованности, поскольку использование транзакций группы сущностей для обновления двух сущностей не допускается.
Решение
Сохраните новый тип сущности в исходную таблицу с помощью сущностей со следующей структурой.
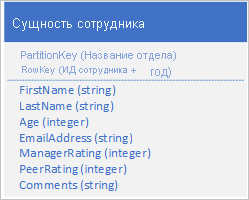
Обратите внимание на то, что RowKey теперь является составным ключом, состоящим из идентификатора сотрудника и года отчетных данных. Этот ключ позволяет извлекать данные о производительности сотрудника с помощью одного запроса к одной сущности.
В следующем примере показан процесс извлечения всех отчетных данных по конкретному сотруднику (например, сотрудник 000123 из отдела продаж).
$filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000123') and (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Необходимо использовать соответствующий символ-разделитель, упрощающий анализ значения RowKey. Например, 000123_2012.
- Эта сущность сохраняется в одном разделе с другими сущностями, которые содержат связанные данные по тому же сотруднику. Это значит, что поддержка высокого уровня согласованности осуществляется с помощью транзакций группы сущностей.
- Чтобы определить допустимость использования этого шаблона, рекомендуется принять во внимание частоту выполнения запросов к данным. Если вы будете обращаться к отчетным данным редко, а к основным данным сотрудника часто, их следует сохранить как отдельные сущности.
Когда следует использовать этот шаблон
Используйте этот шаблон, если необходимо сохранить одну или несколько связанных часто запрашиваемых сущностей.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Транзакции группы сущностей
- Работа с разными типами сущностей
- Шаблон для согласованных транзакций;
Шаблон для заключительного фрагмента журнала
Извлечение n сущностей, недавно добавленных в раздел, с помощью значения RowKey , выполняющего сортировку по дате и времени в обратном порядке.
Контекст и проблема
Общее требование заключается в возможности извлекать последние созданные сущности. Например, 10 последних заявок на возмещение расходов, отправленных сотрудником. Табличные запросы поддерживают операцию запроса $top для возвращения первых n сущностей из набора. Аналогичная операция запроса для возвращения последних n сущностей в наборе отсутствует.
Решение
Сохраните сущности с помощью свойства RowKey, которое естественным образом сортирует даты и время в обратном порядке. В этом случае самая последняя запись всегда будет отображаться первой.
Например, чтобы извлечь 10 последних заявок на возмещение расходов, отправленных сотрудником, можно использовать число обратных тактов, являющееся производным от текущей даты и времени. В следующем примере кода C# показан один из способов создания подходящего значения «обратных тиков» для свойства RowKey , которое выполняет сортировку с самого последнего значения и до самого первого.
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Чтобы вернуться к исходному значению даты и времени, воспользуйтесь следующим кодом.
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
Табличный запрос выглядит следующим образом.
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Чтобы обеспечить надлежащую сортировку, необходимо заполнить начало значения обратного тика нулями.
- Необходимо соблюдать целевые показатели масштабирования на уровне раздела. Не создайте разделы с высокой нагрузкой.
Когда следует использовать этот шаблон
Этот шаблон используется в случаях, если необходимо получить доступ к сущностям в обратном порядке даты и времени или если требуется доступ к последним добавленным сущностям.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
Шаблон для удаления больших объемов сущностей
Включите операцию удаления больших объемов сущностей за счет сохранения всех сущностей для одновременного удаления в отдельной таблице. Удаление сущностей происходит при удалении таблицы.
Контекст и проблема
Многие приложения удаляют старые данные, которые больше не требуются для клиентского приложения. Кроме того, данные могут удаляться при архивации приложения на другой носитель. Такие данные обычно можно определить по дате. Например, существует требование для удаления записей всех запросов на вход, которые были созданы более 60 дней назад.
Один из возможных вариантов заключается в использовании даты и времени запроса на вход в свойстве RowKey.
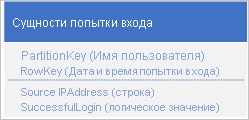
Такой подход позволяет избежать формирования активных областей в разделах, так как приложение сможет вставлять и удалять сущности входа для каждого пользователя в отдельном разделе. Однако при наличии большого количества сущностей этот подход может быть дорогостоящими и требовать значительного времени, поскольку сначала необходимо просмотреть таблицу, чтобы определить все сущности для удаления, а затем удалить каждую старую сущность. Количество переходов к серверу, необходимых для удаления старых сущностей, можно сократить путем пакетной вставки нескольких запросов на удаление в EGT.
Решение
Используйте отдельную таблицу для каждого дня, когда предпринимаются попытки входа с систему. Можно воспользоваться приведенной выше структурой сущности, чтобы избежание формирование активных областей во время вставки сущностей. Процедура удаления старых сущностей теперь заключается в ежедневном удалении одной таблицы (выполнение одной операции хранения), поскольку находить и удалять сотни и тысячи отдельных сущностей входа больше не требуется.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Ваш проект поддерживает другие способы использования данных приложением, например поиск конкретных сущностей, установка связи с другими данными или создание сводных данных?
- Ваш проект предотвращает формирование активных областей в случае вставки новых сущностей?
- Повторное использование того же имени таблицы после его удаления связано с определенной задержкой. Рекомендуется всегда использовать уникальные имена таблиц.
- Первое использование новой таблицы предполагает регулирование ресурсов, поскольку служба таблиц изучает шаблоны доступа и распределяет разделы по узлам. Рекомендуется определить периодичность создания новых таблиц.
Когда следует использовать этот шаблон
Используйте этот шаблон при наличии большого количества сущностей для одновременного удаления.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Транзакции группы сущностей
- Изменение сущностей.
Шаблон для рядов данных
Чтобы сократить количество выполняемых запросов, храните ряды данных в одной сущности.
Контекст и проблема
Возьмем распространенный сценарий, когда приложение сохраняет ряды данных, которые требуется извлечь все сразу. Например, приложение может записывать количество сообщений, ежечасно отправляемых каждым сотрудником, а затем использовать эти сведения для отображения количества сообщений, отправленных каждым пользователем за предыдущие 24 часа. Для хранения 24 сущностей для каждого сотрудника можно разработать одну структуру.
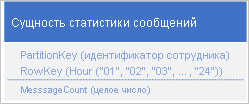
В ней можно без труда находить и обновлять сущности для каждого сотрудника каждый раз, когда приложению требуется обновить значение количества сообщений. Однако чтобы извлечь данные для построения графика активности за предыдущие 24 часа, потребуется извлечь 24 сущности.
Решение
Используйте следующую структуру с отдельным свойством для хранения количества сообщений за каждый час.

В этом случае вы сможете обновлять количество сообщений по сотруднику за определенный час с помощью операции объединения. Теперь с помощью запроса к одной сущности можно извлечь все сведения, необходимые для построения графика.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Если ряды данных не могут полностью поместиться в одну сущность (сущности могут содержать до 252 свойств), используйте альтернативное хранилище данных, например BLOB-объект.
- Если сущность обновляется несколькими клиентами одновременно, потребуется воспользоваться ETag для реализации оптимистичного параллелизма. Большое количество клиентов может привести к высокому уровню конкуренции.
Когда следует использовать этот шаблон
Используйте этот шаблон, если необходимо обновить и получить ряды данных, связанных с отдельной сущностью.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Шаблон для сущностей больших размеров
- Объединение или замена.
- Шаблон для согласованных транзакций (при сохранении рядов данных в BLOB-объект).
Шаблон для масштабных сущностей
Чтобы сохранить сущности, имеющие более 252 свойств, используйте несколько физических сущностей.
Контекст и проблема
Отдельные сущности могут иметь не более 252 свойства (за исключением обязательных свойств системы), а общий объем хранимых данных не должен превышать 1 МБ. В реляционной базе вопрос с ограничениями по размеру строки обычно решается путем добавления новой таблицы и установкой отношения «один-к-одному».
Решение
С помощью службы таблиц можно сохранить несколько сущностей, которые будут представлять один крупный бизнес-объект с более чем 252 свойствами. Например, чтобы сохранить количество мгновенных сообщений, отправленных каждого сотрудником за последние 365 дней, можно использовать следующую структуру с двумя сущностями, имеющими разные схемы.
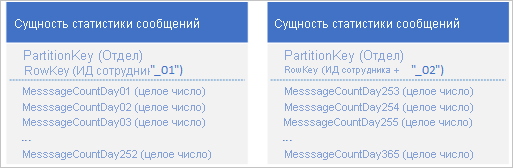
Если необходимо внести изменение, требующее обновления обеих сущностей для обеспечения их синхронизации, воспользуйтесь транзакциями группы сущностей. В противном случае можно выполнить одну операцию объединения, которая позволит обновить количество сообщений за определенный день. Чтобы извлечь все данные по отдельному сотруднику, необходимо извлечь обе сущности. Для этого воспользуйтесь двумя эффективными запросами, использующими значения PartitionKey и RowKey.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Извлечение логической сущности целиком связано с выполнением как минимум двух операций с хранилищем: одна для извлечения каждой физической сущности.
Когда следует использовать этот шаблон
Используйте этот шаблон, если требуется сохранить сущности, размер или количество свойств которых превышает ограничения для отдельной сущности в службе таблиц.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
- Транзакции группы сущностей
- Объединение или замена.
Шаблон для сущностей больших размеров
Для хранения больших по объему значений свойств используйте хранилище больших двоичных объектов.
Контекст и проблема
В отдельной сущности нельзя сохранить данные, общий объем которых превышает 1 МБ. Если в одном или нескольких свойствах хранятся значения, из-за которых общий размер сущности превышает указанное значение, эту сущность нельзя сохранить в службе таблиц.
Решение
Если размер сущности превышает 1 МБ из-за того, что одно или несколько свойств содержат большой объем данных, эти данные можно сохранить в службе BLOB-объектов, а затем сохранить адрес большого двоичного объекта в свойстве в сущности. Например, фотографию сотрудника можно сохранить в хранилище больших двоичных объектов, а ссылку на фотографию — в свойстве Photo сущности сотрудника.

Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Чтобы обеспечить согласованность между сущностью в службе таблиц и данными в службе BLOB-объектов, используйте шаблон для согласованных транзакций .
- Для извлечения полной сущности требуется как минимум две транзакции хранилища: одна для извлечения сущности и одна для извлечения данных большого двоичного объекта.
Когда следует использовать этот шаблон
Используйте этот шаблон, если необходимо сохранить сущности, размер которых превышает ограничения для отдельной сущности в службе таблиц.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
Анти-шаблон, предусматривающий добавление в начало или конец
При наличии большого количества операций вставки, повысьте уровень масштабируемости путем распределения вставляемых компонентов по нескольким разделам.
Контекст и проблема
Как правило, добавление сущностей в начало или конец хранящихся сущностей приводит к тому, что приложение будет добавлять новые сущности к первому или последнему разделу в последовательности разделов. В таком случае все операции вставки в любой момент времени выполняются в одном разделе. При этом создается активная область, не позволяющая службе таблиц распределять операции вставки по нескольким узлам, и может возникнуть ситуация, когда приложение достигает целевых показателей масштабируемости для раздела. Например, при наличии приложения, регистрирующего доступ сотрудников к сети и ресурсам, использование показанной ниже структуры сущности может привести к тому, что раздел текущего часа станет активной областью, если объем транзакций достигнет целевых показателей масштабируемости для отдельного раздела.

Решение
Следующая альтернативная структура сущности предотвращает формирование активной области в любом разделе во время регистрации событий приложением.

Обратите внимание, что в этом примере PartitionKey и RowKey являются составными ключами. Свойство PartitionKey использует идентификаторы отдела и сотрудника для распределения операции ведения журнала по нескольким разделам.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
- Альтернативная структура ключа, которая предотвращает создание разделов с высокой нагрузкой во время выполнения операций вставки, поддерживает запросы, выполняемые клиентским приложением?
- Ожидаемый объем транзакций означает вероятность достижения целевых показателей масштабируемости для отдельного раздела и возможность регулирования службой хранения?
Когда следует использовать этот шаблон
Не используйте анти-шаблон, предусматривающий добавление в начало или конец, если объем транзакций может привести к регулированию при доступе к разделу с высокой нагрузкой.
Связанные шаблоны и рекомендации
При реализации данного шаблона можно принять во внимание следующие шаблоны и рекомендации:
Анти-шаблон для данных журнала
Как правило, данные журнала следует хранить не в службе таблиц, а в службе BLOB-объектов.
Контекст и проблема
Стандартный вариант использования данных журнала — извлечение выборки записей журнала по конкретному диапазону дат и времени. Например, требуется найти все сообщения об ошибках и важные сообщения, зафиксированные приложением в журнале в период с 15:04 до 15:06 в конкретный день. Чтобы определить раздел, в котором хранятся сущности журнала, не рекомендуется использовать дату и время записи журнала, так как это приведет к созданию раздела с высокой нагрузкой. Это означает, что в любой момент времени все сущности журнала будут обращаться к одному общему значению PartitionKey (см. раздел Антишаблон, предусматривающий добавление в начало или конец). Например, следующая схема сущности для сообщения журнала приводит к созданию раздела с высокой нагрузкой, так как приложение записывает все сообщения журнала в раздел для текущей даты и часа.

В этом примере RowKey содержит дату и время сообщения журнала, чтобы обеспечить сортировку хранящихся сообщений по дате и времени. Если одинаковые дату и время имеют несколько сообщений журнала, в это свойство также входит идентификатор сообщения.
Другим вариантом является использование свойства PartitionKey для записи сообщений в несколько разделов. Например, если источник сообщения журнала позволяет распределять сообщения по нескольким разделам, можно использовать следующую схему сущности.
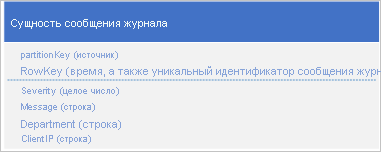
Однако здесь возникает проблема, которая заключается в том, что для извлечения всех сообщений журнала за определенный период времени необходимо выполнить поиск в каждом разделе таблицы.
Решение
В предыдущем разделе была отмечена проблема использования службы таблиц для хранения записей журнала и предлагались две неудовлетворительные схемы. Результатом одного решения было формирование активной области с риском снижения производительности записи сообщений журнала. Другое решение приводило к ухудшению производительности запросов в связи с требованием просматривать каждый раздел в таблице для получения сообщений журнала за определенный промежуток времени. Хранилище больших двоичных объектов предлагает наилучшее решение в такой ситуации. Оно связано с преимуществами хранения данных журнала в службе аналитики хранилища Azure.
Описанные в этом разделе способы хранения данных журнала службой аналитики хранилища в хранилище больших двоичных объектов иллюстрируют подход к хранению данных, запрашиваемых по диапазону.
Служба аналитики хранилища сохраняет сообщения журнала в формате с разделителями в нескольких больших двоичных объектах. Формат с разделителями упрощает анализ данных в сообщениях журнала.
Служба аналитики хранилища использует соглашение об именовании больших двоичных объектов, позволяющее находить большой двоичный объект (или большие двоичные объекты), которые содержат искомые сообщения журнала. Например, большой двоичный объект с именем «queue/2014/07/31/1800/000001.log» содержит сообщения журнала, относящиеся к службе очередей, за час, начиная с 18:00 31 июля 2014 г. «000001» означает первый файл журнала за этот период. Служба аналитики хранилища также записывает метки времени первого и последнего сообщений журнала, хранящихся в файле в составе метаданных большого двоичного объекта. С помощью API Хранилища BLOB-объектов можно выполнять поиск больших двоичных объектов в контейнере на основе префикса имени. Чтобы найти все большие двоичные объекты, содержащие данные журнала очереди за час, начиная с 18:00, используйте префикс "queue/2014/07/31/1800".
Служба аналитики хранилища помещает сообщения журнала во внутренний буфер, а затем периодически обновляет соответствующий большой двоичный объект или создает новый с последним пакетом записей журнала. Это способствует сокращению количества операций записи, которые должны быть выполнены в службу BLOB-объектов.
При реализации подобного решения в собственном приложении вам необходимо решить вопрос управления компромиссом между надежностью (запись каждого сообщения журнала в хранилище больших двоичных объектов), затратами и масштабируемостью (буферизация обновлений в приложении и их пакетная запись в хранилище больших двоичных объектов).
Проблемы и рекомендации
При выборе способа хранения данных журнала, необходимо учитывать следующие моменты.
- При создании схемы таблицы без потенциальных разделов с высокой нагрузкой может оказаться, что доступ к данным журнала осуществляется неэффективно.
- Для обработки данные журнала клиенту часто требуется загружать много записей.
- Несмотря на то, что данные журнала часто носят структурированный характер, наилучшим решением может быть хранилище больших двоичных объектов.
Вопросы реализации
В этом разделе рассматриваются некоторые вопросы, которые необходимо иметь в виду при реализации моделей, описанных в предыдущих разделах. В большинстве этих разделов используются примеры, написанные на C#, которые используют клиентская библиотека служба хранилища (версия 4.3.0 во время написания).
Извлечение сущностей.
Как упоминалось в разделе "Разработка для запросов", самый эффективный запрос — точечный. Однако в некоторых случаях может потребоваться извлечь несколько сущностей. В этом разделе описаны некоторые распространенные подходы к извлечению сущностей с помощью клиентской библиотеки служба хранилища.
Выполнение запроса точки с помощью клиентской библиотеки служба хранилища
Самый простой способ выполнить точечный запрос — использовать метод GetEntityAsync, приведенный в следующем фрагменте кода C#. Он извлекает сущность, у которой свойство PartitionKey имеет значение Sales, а свойство RowKey — значение 212.
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Обратите внимание на то, что извлекаемая сущность будет иметь тип EmployeeEntity.
Извлечение нескольких сущностей с помощью LINQ
LINQ можно использовать для получения нескольких сущностей из службы таблиц при работе с стандартной библиотекой таблиц Microsoft Azure Cosmos DB.
dotnet add package Azure.Data.Tables
Чтобы использовать приведенные ниже примеры, необходимо включить следующие пространства имен:
using System.Linq;
using Azure.Data.Tables
Получение нескольких сущностей можно добиться, указав запрос с предложением фильтра . Чтобы исключить просмотр таблицы, в предложение filter необходимо всегда включать значение PartitionKey и, если возможно, значение RowKey, которые позволят избежать просмотров таблиц и секций. Служба таблиц поддерживает ограниченный набор операторов сравнения (больше, больше или равно, меньше, меньше или равно, равно, не равно), которые могут использоваться в предложении filter.
В следующем примере employeeTable используется объект TableClient . В этом примере все сотрудники, фамилию которых начинается с "B" (при условии, что RowKey хранит фамилию) в отделе продаж (при условии, что PartitionKey сохраняет имя отдела):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Обратите внимание на то, каким образом в запросе указываются свойства RowKey и PartitionKey для обеспечения максимального быстродействия.
В следующем примере кода показана эквивалентная функциональность без использования синтаксиса LINQ:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Примечание.
В примере объединено несколько методов Query для включения трех условий фильтрации.
Извлечение большого количества сущностей из запроса
Оптимальный запрос возвращает отдельные сущности на основе значений PartitionKey и RowKey. Однако в некоторых ситуациях может существовать требование о возвращении нескольких сущностей из одного или даже нескольких разделов.
В таких случаях следует полностью протестировать производительность приложения.
Запрос к службе таблиц может возвращать максимум 1000 сущностей одновременно, а время его выполнения не превышает 5 секунд. Если результирующий набор содержит более 1000 сущностей, если запрос выполняется более 5 секунд или выходит за пределы раздела, служба таблиц возвращает маркер продолжения, чтобы клиентское приложение смогло выполнить запрос к следующему набору сущностей. Дополнительные сведения о принципе действия маркеров продолжения см. в статье Query Timeout and Pagination (Время ожидания запроса и разбивка на страницы).
Если вы используете клиентская библиотека таблиц Azure, она может автоматически обрабатывать маркеры продолжения, так как она возвращает сущности из службы таблиц. Следующий пример кода C# с помощью клиентской библиотеки автоматически обрабатывает маркеры продолжения, если служба таблиц возвращает их в ответе:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Можно также указать максимальное количество сущностей, возвращаемых на страницу. В следующем примере показано, как запрашивать сущности с помощью maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
В более сложных сценариях может потребоваться сохранить маркер продолжения, возвращенный службой, чтобы код точно был получен при получении следующих страниц. В следующем примере показан базовый сценарий того, как маркер можно получить и применить к результатам с разбивкой на страницы:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Явное использование маркеров продолжения позволяет управлять извлечением следующего сегмента данных. Например, если клиентское приложение разрешает пользователям постранично просматривать хранящиеся в таблице сущности, пользователь может отказаться от постраничного просмотра всех сущностей, полученных запросом, поэтому приложение будет использовать маркер продолжения для извлечения следующего сегмента только после того, как пользователь завершит постраничный просмотр всех сущностей в текущем сегменте. Такой подход имеет несколько преимуществ.
- Он позволяет ограничивать объем данных, извлекаемых из службы таблиц и перемещаемых по сети.
- Он позволяет выполнять асинхронные операции ввода-вывода в .NET.
- Он позволяет сериализовать маркер продолжения в постоянное хранилище, чтобы пользователь мог продолжить свои действия в случае сбоя приложения.
Примечание.
Маркер продолжения обычно возвращает сегмент, содержащий 1000 сущностей и меньше. Это действительно и в том случае, если количество сущностей, возвращаемых в результате запроса, ограничивается с помощью операции Take для возврата первых n сущностей, соответствующих условию поиска. Служба таблиц может вернуть сегмент, содержащий меньше n сущностей, а также маркер продолжения, который позволит получить остальные сущности.
Проекция на стороне сервера
Одна сущность может иметь до 255 свойств и быть размером не более 1 МБ. При выполнении запроса к таблице и извлечении сущностей может потребоваться только часть свойств, а передача данных будет осуществляться только при необходимости (для сокращения времени задержки и снижения затрат). Проекции на стороне сервера можно использовать для передачи только необходимых свойств. В следующем примере извлекается только свойство Email (вместе с PartitionKey, RowKey, Timestamp и ETag) из сущностей, выбранных запросом.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Обратите внимание на доступность значения RowKey несмотря на то, что оно не включено в список возвращаемых свойств.
Изменение сущностей.
Клиентская библиотека служба хранилища позволяет изменять сущности, хранящиеся в службе таблиц, путем вставки, удаления и обновления сущностей. С помощью транзакций группы сущностей можно выполнять пакетные операции вставки, обновления и удаления, сокращая тем самым количество круговых переходов и повышая производительность решения.
Исключения, возникающие при выполнении клиентской библиотеки служба хранилища обычно включают индекс сущности, вызвавшей сбой пакета. Это может оказаться полезным при отладке кода, использующего транзакции группы сущностей.
Следует также учитывать влияние разработки на то, каким образом клиентское приложение обрабатывает операций параллелизма и обновления.
Управление параллелизмом
По умолчанию служба таблиц реализует проверки оптимистичного параллелизма на уровне отдельных сущностей для операций Insert, Merge и Delete несмотря на то, что клиент может принудительно заставить службу таблиц обойти эти проверки. Дополнительные сведения о том, каким образом служба таблиц осуществляет управление параллелизмом, см. в статье Управление параллелизмом в службе хранилища Microsoft Azure.
Объединение или замена.
Метод Replace класса TableOperation всегда полностью заменяет сущность в службе таблиц. Если это свойство не включено в запрос, но существует в хранимой сущности, запрос удалит это свойство из хранимой сущности. Каждое свойство требуется в включать в запрос до тех пор, пока оно явным образом не будет удалено из хранимой сущности.
Метод Merge класса TableOperation можно использовать для сокращения объема данных, отправляемых в службу таблиц при необходимости обновления сущности. Метод Merge заменяет любые свойства в хранимой сущности значениями свойств из сущности в составе запроса, но не изменяет свойства в хранимой сущности, которые не включены в запрос. Это полезно при наличии сущностей больших размеров и если нужно обновить незначительное количество свойств в запросе.
Примечание.
Если сущность не существует, методы Replace и Merge завершаются ошибкой. В качестве альтернативы рекомендуется рассмотреть методы InsertOrReplace и InsertOrMerge, которые в случае отсутствия сущности создают таковую.
Работа с разными типами сущностей
Служба таблиц представляет собой табличное хранилище schema-less. Это значит, что в одной таблице могут храниться сущности нескольких типов, что обеспечивает исключительную гибкость разработки. В следующем примере показана таблица, в которой хранятся сущности сотрудников и отделов.
| PartitionKey | RowKey | Метка времени | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Каждая сущность должна иметь значения PartitionKey, RowKey и Timestamp и при этом может содержать любой набор свойств. Кроме того, тип сущности будет указан только после выбора места для хранения этих сведений. Существует два варианта определения типа сущности.
- Добавьте тип сущности в начало свойства RowKey (или, возможно, свойства PartitionKey). Например, EMPLOYEE_000123 или DEPARTMENT_SALES в качестве значений RowKey.
- Используйте отдельное свойство для записи типа сущности, как показано в таблице ниже.
| PartitionKey | RowKey | Метка времени | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
Первый вариант (добавление типа сущности в начало свойства RowKey) полезен, если существует вероятность, что две сущности разных типов имеют одинаковое значение ключа. Кроме того, он позволяет объединять сущности одного типа в раздел.
Методики, рассматриваемые в этом разделе, особенно актуальны для темы Отношения наследования, которая обсуждалась ранее в статье Моделирование отношений.
Примечание.
Чтобы клиентские приложения могли формировать объекты POCO и работать с различными версиями, рекомендуется включить номер версии в значение типа сущности.
Оставшаяся часть этого раздела описывает некоторые функции в клиентской библиотеке служба хранилища, которые упрощают работу с несколькими типами сущностей в одной таблице.
Извлечение разных типов сущностей
При использовании клиентской библиотеки таблиц у вас есть три варианта работы с несколькими типами сущностей.
Если вы знаете тип сущности, хранящейся с определенными значениями RowKey и PartitionKey, можно указать тип сущности при получении сущности, как показано в предыдущих двух примерах, которые извлекают сущности типа EmployeeEntity: выполнение запроса точки с помощью клиентской библиотеки служба хранилища и извлечения нескольких сущностей с помощью LINQ.
Вторым вариантом является использование типа TableEntity (контейнер свойств) вместо конкретного типа сущности POCO. Этот вариант способен повысить производительность, так как не нужно выполнять сериализацию и десериализацию сущности в типы .NET. В следующем примере кода C# показано извлечение нескольких сущностей различных типов из таблицы и возвращение всех сущностей в качестве экземпляров TableEntity. После этого в примере используется свойство EntityType для определения типа каждой сущности.
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Чтобы извлечь другие свойства, необходимо использовать метод GetString в entity класса TableEntity.
Изменение разных типов сущностей
Чтобы удалить тип сущности, его не нужно знать. Однако при вставке тип сущности всегда известен. Чтобы обновить сущность, не зная ее тип и не используя класс сущности POCO, можно воспользоваться типом TableEntity. Следующий пример кода извлекает одну сущность и проверяет свойство EmployeeCount перед его обновлением.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Управление доступом с помощью подписей общего доступа
Маркеры подписи общего доступа (SAS) позволяют клиентским приложениям изменять сущности таблицы и выполнять запросы к ним без необходимости включать ключ учетной записи хранения в код. Существует три основных преимущества использования SAS в приложении.
- Не нужно распространять ключ учетной записи хранения на небезопасной платформе (например, на мобильном устройстве), чтобы предоставить устройству права на доступ и изменение сущностей в службе таблиц.
- Часть операций по управлению сущностями, выполняемых веб- и рабочими ролями, можно перенести на клиентские устройства, такие как компьютеры конечных пользователей и мобильные устройства.
- Клиенту можно назначить ограниченный ресурсами и временем набор разрешений (например, доступ только для чтения к определенным ресурсам).
Дополнительные сведения об использовании маркеров SAS со службой таблиц см. в статье Использование подписанных URL-адресов (SAS).
Однако вы по-прежнему должны создавать маркеры SAS, предоставляющие клиентскому приложению доступ к сущностям в службе таблиц. Выполнять эту операцию следует в среде с безопасным доступом к ключам учетной записи хранения. Как правило, для создания маркеров SAS их доставки в клиентские приложения, которым требуется доступ к сущностям, используются веб-роли или рабочие роли. Поскольку процесс создания маркеров SAS и их доставки клиентов по-прежнему связан с издержками, рекомендуется рассмотреть оптимальные варианты сокращения расходов в сценариях с большим количеством операций.
Можно создать маркер SAS, который предоставляет доступ к подмножеству сущностей в таблице. По умолчанию создается маркер SAS для всей таблицы. Однако можно указать, что маркер SAS предоставляет доступ либо к диапазону значений PartitionKey, либо к диапазону значений PartitionKey и RowKey. Маркеры SAS можно создать для отдельных пользователей системы таким образом, чтобы маркер SAS предоставлял пользователю доступ только к его собственным сущностям в службе таблиц.
Асинхронные и параллельные операции
Чтобы улучшить производительность и время отклика клиента в случае распределения запросов по нескольким разделам, рекомендуется обратить внимание на асинхронные и параллельные запросы. Например, в вашем распоряжении может быть два или несколько экземпляров рабочих ролей с параллельным доступом к таблицам. Отдельные рабочие роли могут отвечать за определенные наборы разделов или же просто несколько экземпляров рабочих ролей могут получать доступ ко всем разделам в таблице.
Повысить производительность в экземпляре клиента можно путем асинхронного выполнения операций хранения. Клиентская библиотека служба хранилища упрощает запись асинхронных запросов и изменений. Например, можно начать с синхронного метода, который извлекает все сущности в разделе, как показано в следующем коде C#.
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Этот код можно легко изменить, чтобы запрос выполнялся в асинхронном режиме, как показано ниже.
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
В данном примере асинхронного режима присутствуют следующие отличия от синхронной версии.
- Теперь подпись метода содержит модификатор async и возвращает экземпляр Task.
- Вместо вызова метода Query для извлечения результатов теперь метод вызывает метод QueryAsync и использует модификатор await для асинхронного получения результатов.
Клиентское приложение может вызывать этот метод несколько раз (с разными значениями параметра department), а каждый запрос будет выполняться в отдельном потоке.
Можно вставлять, обновлять и удалять сущности в асинхронном режиме. В следующем примере кода C# показан простой синхронный метод вставки или замены сущности сотрудника.
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Этот код можно легко изменить, чтобы обновление выполнялось в асинхронном режиме, как показано ниже.
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
В данном примере асинхронного режима присутствуют следующие отличия от синхронной версии.
- Теперь подпись метода содержит модификатор async и возвращает экземпляр Task.
- Вместо вызова метода Execute для обновления сущности метод вызывает метод ExecuteAsync и использует модификатор await для асинхронного получения результатов.
Клиентское приложение может вызывать несколько подобных асинхронных методов, а каждый вызов метода будет выполняться в отдельном потоке.