Обнаружение аномалий в Azure Stream Analytics
Azure Stream Analytics, доступный в облаке и в Azure IoT Edge, предлагает встроенные возможности обнаружения аномалий на основе машинного обучения, которые можно использовать для мониторинга двух наиболее часто встречающихся аномалий: временной и постоянной. С помощью функций AnomalyDetection_SpikeAndDip и AnomalyDetection_ChangePoint можно выполнять обнаружение аномалий непосредственно в задании Stream Analytics.
Модели машинного обучения предполагают наличие временных рядов с равномерной выборкой. Если временные ряды не одинаковы, можно вставить шаг агрегирования с переворачивающимся окном перед вызовом обнаружения аномалий.
Операции машинного обучения не поддерживают тенденции сезонности или многовариантные корреляции в настоящее время.
Обнаружение аномалий с использованием машинного обучения в Azure Stream Analytics
В следующем видео показано, как определить аномалию в режиме реального времени с помощью функций машинного обучения в Azure Stream Analytics.
Поведение модели
Как правило, точность модели повышается с увеличением количества данных в скользящем окне. Данные в указанном скользящем окне обрабатываются как часть нормального диапазона значений для этого интервала времени. Модель рассматривает историю событий только через скользящее окно, чтобы проверить, является ли текущее событие аномальным. При перемещении скользящего окна старые значения исключаются из обучения модели.
Функции работают путем установления определенного нормального на основе того, что они видели до сих пор. Выбросы определяются путем сравнения с установленной нормой в пределах уровня достоверности. Размер окна должен основываться на минимальных событиях, необходимых для обучения модели нормальному поведению, чтобы при возникновении аномалии она могла его распознать.
Время отклика модели увеличивается с размером журнала, так как нужно сравнение с большим числом прошедших событий. Рекомендуется включить только необходимое количество событий для повышения производительности.
Разрывы во временных рядах могут произойти, потому что модель не получает события в определенные моменты времени. Эта ситуация обрабатывается в Stream Analytics с помощью подстановки. Размер журнала, а также продолжительность времени для одного и того же скользящего окна используются для расчета средней скорости, с которой ожидаются события.
Генератор аномалий, доступный здесь, можно использовать для передачи в центр Интернета вещей данных с разными шаблонами аномалий. Задание Azure Stream Analytics можно настроить с помощью этих функций обнаружения аномалий для чтения из этого Центра Iot и обнаружения аномалий.
Пики и спады
Временные аномалии в потоке событий временных рядов называются пиками и спадами. Пики и спады можно отслеживать с помощью оператора Машинного обучения AnomalyDetection_SpikeAndDip.

В том же скользящем окне, если второй пик меньше первого, вычисленная оценка меньшего пика, вероятно, недостаточно значительна по сравнению с оценкой первого пика в пределах указанного уровня достоверности. Чтобы обнаруживать такие аномалии, можно попробовать уменьшить значение уровня достоверности модели. Однако если предупреждений становится слишком много, можно использовать более высокий интервал достоверности.
Следующий пример запроса предполагает равномерную скорость ввода одного события в секунду в 2-минутном скользящем окне с журналом со 120 событиями. Заключительная инструкция SELECT извлекает и выводит оценку и состояние аномалии с уровнем достоверности 95 %.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Изменение точки
Постоянные аномалии в потоке событий временных рядов — это изменения в распределении значений в потоке событий, такие как изменения уровня и тенденции. В Stream Analytics такие аномалии обнаруживаются с помощью оператора AnomalyDetection_ChangePoint, основанного на Машинном обучении.
Постоянные изменения длились гораздо дольше, чем пики и спады, и могут указывать на катастрофические события. Постоянные изменения обычно не видны невооруженным глазам, но могут быть обнаружены с помощью оператора AnomalyDetection_ChangePoint .
На следующем рисунке показан пример изменения уровня:
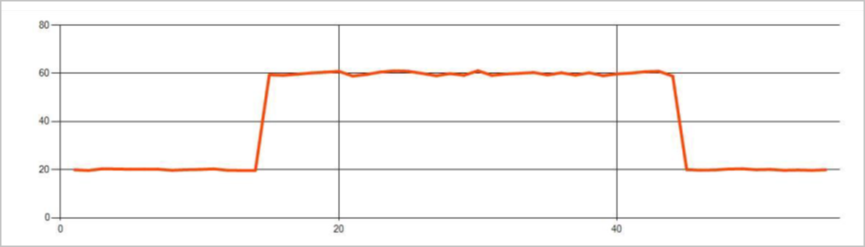
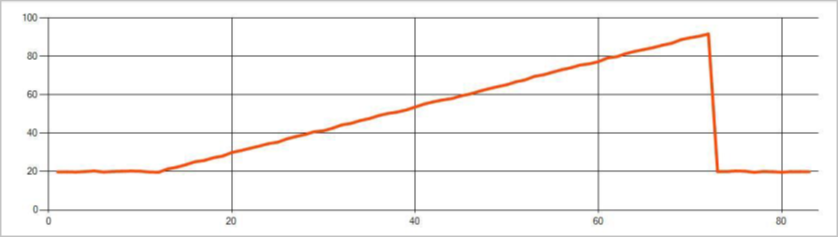
На следующем рисунке показан пример изменения тенденции:
В следующем примере запроса предполагается единая скорость ввода одного события в секунду в 20-минутном скользящем окне с размером журнала 1200 событий. Заключительная инструкция SELECT извлекает и выводит оценку и состояние аномалии с уровнем достоверности 80 %.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Характеристики производительности
Производительность этих моделей зависит от размера журнала, длительности периода, загрузки событий, а также от того, используется ли секционирование на уровне функции. В этом разделе рассматриваются эти конфигурации и приведены примеры для поддержания скорости приема 1 K, 5 K и 10K событий в секунду.
- Размер журнала — производительность этих моделей напрямую связана с размером журнала. Чем больше размер журнала, тем больше времени требуется модели для оценки нового события. Это связано с тем, что модели сравнивают новое событие с каждым из прошлых событий в буфере журнала.
- Длительность периода — длительность периода должна отражать, сколько времени займет получение такого количества событий, которое указано в размере журнала. Если за этот период не произойдет такое количество событий, Azure Stream Analytics условно назначит недостающие значения. Таким образом, использование ЦП зависит от размера журнала.
- Нагрузка событий — чем больше нагрузка событий, тем больше работы выполняют модели, что влияет на потребление ресурсов ЦП. Масштаб задания можно горизонтально увеличивать для параллельного выполнения, если бизнес-логика получит преимущества от использования большего числа входных секций.
- Секционирование на уровне функций — секционирование на уровне функций осуществляется с помощью
PARTITION BYв вызове функции обнаружения аномалий. Этот тип секционирования добавляет дополнительные издержки, так как состояние должно поддерживаться для нескольких моделей одновременно. Секционирование на уровне функций используется в таких сценариях, как секционирование на уровне устройства.
Отношение
Размер журнала, длительность периода и общая нагрузка событий связаны следующим образом:
windowDuration (в мс) = 1000 * historySize / (общее количество входных событий в секунду / число входных секций)
При секционировании функции по идентификатору устройств добавьте "PARTITION BY deviceId" в вызов функции обнаружения аномалий.
Наблюдения
В следующей таблице приведены наблюдения за пропускной способностью для одного узла (шесть SU) для непартиментированного случая:
| Размер журнала (события) | Длительность периода (мс) | Общее количество входных событий в секунду |
|---|---|---|
| 60 | 55 | 2 200 |
| 600 | 728 | 1650 |
| 6000 | 10 910 | 1100 |
В следующей таблице приведены наблюдения за пропускной способностью для одного узла (шесть su) для секционированного дела:
| Размер журнала (события) | Длительность периода (мс) | Общее количество входных событий в секунду | Число устройств |
|---|---|---|---|
| 60 | 1091 | 1100 | 10 |
| 600 | 10 910 | 1100 | 10 |
| 6000 | 218 182 | <550 | 10 |
| 60 | 21 819 | 550 | 100 |
| 600 | 218 182 | 550 | 100 |
| 6000 | 2 181 819 | <550 | 100 |
Пример кода для запуска непартиментированных конфигураций выше находится в репозитории Streaming At Scale в Azure Samples. Код создает задание stream analytics без секционирования уровня функций, которое использует Центры событий в качестве входных и выходных данных. Входная нагрузка создается с помощью тестовых клиентов. Каждое входное событие — это 1 КБ документ json. События имитируют устройство Интернета вещей, отправляющее данные JSON (до 1 K устройств). Размер журнала, длительность окна и общая загрузка событий различаются по двум входным секциям.
Примечание.
Чтобы получить более точную оценку, настройте примеры в соответствии с имеющимся сценарием.
Выявление узких мест
Чтобы определить узкие места в конвейере, используйте область метрик в задании Azure Stream Analytics. Просмотрите параметры События ввода и вывода с данными о пропускной способности и Предельная задержка или Отложенные события, чтобы узнать, выполняется ли задание в соответствии с входной скоростью. Чтобы просмотреть метрики Центров событий, проверьте раздел Регулируемые запросы, а затем соответствующим образом скорректируйте единицы порогового значения. Сведения о метриках Azure Cosmos DB см. в разделе "Пропускная способность", чтобы обеспечить равномерное использование диапазонов ключей секции. Чтобы просмотреть метрики для базы данных SQL Azure, см. разделы Операции ввода-вывода журнала и ЦП.