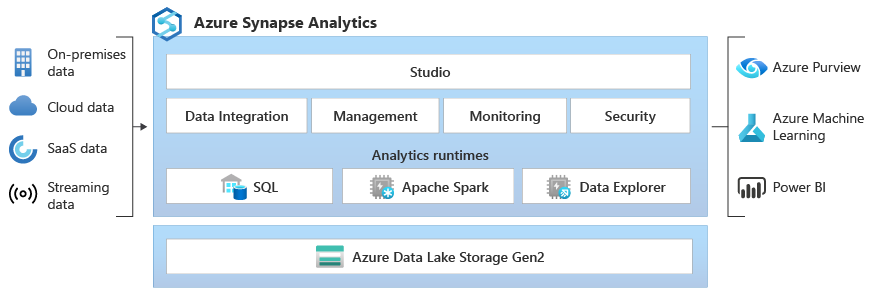
Что такое Azure Synapse Data Explorer? (предварительная версия)
Azure Synapse Data Explorer предоставляет клиентам интерфейс для извлечения ценной информации из данных журнала и телеметрии. Чтобы дополнить возможности существующих обработчиков среды выполнения аналитики SQL и Apache Spark, среда выполнения аналитики Data Explorer оптимизирована для эффективной работы с Log Analytics с помощью эффективной технологии индексирования для автоматического индексирования полнотекстовых и частично структурированных данных, часто встречающихся в данных телеметрии.
Дополнительные сведения см. в следующих видео:
В чем уникальность Azure Synapse Data Explorer?
Простой прием данных — Data Explorer предлагает встроенные средства интеграции для приема данных без кода и низкокодовых данных, а также кэширования данных из источников в реальном времени. Данные можно принимать из таких источников, как Центры событий Azure, Kafka, Azure Data Lake, открытый код агентов, таких как Fluentd/Fluentd Bit, а также из широкого спектра облачных и локальных источников данных.
Нет сложного моделирования данных. При использовании Data Explorer нет необходимости создавать сложные модели данных и создавать сложные скрипты для преобразования данных до их использования.
Без обслуживания индекса . Задачи обслуживания для оптимизации данных для повышения производительности запросов и обслуживание индекса не требуются. С Data Explorer все необработанные данные становятся доступными немедленно, что позволяет выполнять высокопроизводительные и высокопараллельные запросы к потоковой передаче и сохраненным данным. Эти запросы можно использовать для создания панелей мониторинга и оповещений практически в реальном времени, а также для подключения данных операционной аналитики к остальной части платформы аналитики данных.
Простой анализ данных — Data Explorer упрощает самообслуживание и анализ больших данных благодаря интуитивно понятному языку запросов Kusto Query Language (KQL), который объединяет возможности SQL с простотой Excel. KQL оптимизирован для изучения необработанных телеметрических данных и данных временных рядов за счет использования лучшей в своем классе технологии текстового индексирования Data Explorer для эффективного свободно-текстового поиска и поиска по регулярным выражениям, а также возможностей комплексного разбора для трассировок запросов, текстовых данных и полуструктурированных данных JSON, включая массивы и вложенные структуры. KQL предлагает расширенную поддержку временных рядов для создания, обработки и анализа нескольких временных рядов с помощью встроенной поддержки среды выполнения Python для оценки модели.
Проверенная технология в петабайтовом масштабе. Data Explorer — это распределенная система с вычислительными ресурсами и хранилищем, которая может масштабироваться независимо, позволяя выполнять аналитику по гигабайтам или петабайтам данных.
Интеграция — Azure Synapse Analytics обеспечивает взаимодействие между данными Data Explorer, Apache Spark и SQL, что позволяет специалистам по обработке и анализу данных, а также аналитикам данных легко и безопасно работать с одними и теми же данными в озере данных.
Когда следует использовать Azure Synapse Data Explorer?
Используйте Data Explorer как платформу данных для создания решений анализа журналов и аналитики IoT почти в реальном времени, чтобы получить следующие возможности:
Объединение и коррелирование данные журналов и событий в локальных, облачных и сторонних источниках данных.
Ускорение AI Ops (распознавание шаблонов, обнаружение аномалий, прогнозирование и многое другое).
Замена решений для поиска по журналам на основе инфраструктуры для снижения затрат и повышения производительности.
Создание решений для аналитики IoT для данных IoT.
Создание решений для аналитики SaaS для предоставления услуг внутренним и внешним клиентам.
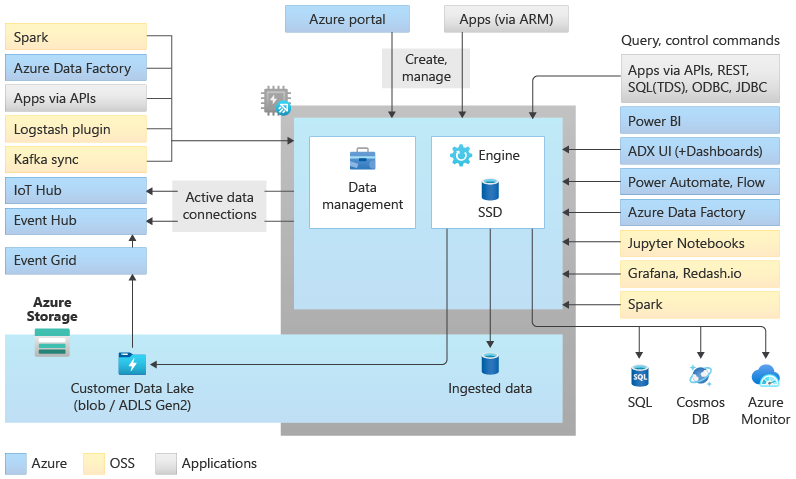
Архитектура пула Data Explorer
Data Explorer пулы реализуют архитектуру горизонтального масштабирования, разделяя вычислительные ресурсы и ресурсы хранилища. Это позволяет независимо масштабировать каждый ресурс и, например, выполнять несколько вычислений только для чтения на одних и том же данных. Data Explorer пулы состоят из набора вычислительных ресурсов под управлением подсистемы, которая отвечает за автоматическое индексирование, сжатие, кэширование и обслуживание распределенных запросов. У них также есть второй набор вычислительных ресурсов, работающих со службой управления данными, отвечающей за фоновые системные задания, а также управляемый прием данных и прием данных в очереди. Все данные сохраняются в управляемых учетных записях хранения BLOB-объектов с использованием формата со сжатыми столбцами.
Пулы Data Explorer поддерживают обширную экосистему приема данных с применением соединителей, пакетов SDK, интерфейсов REST API и других управляемых возможностей. Он предлагает различные способы использования данных для нерегламентированных запросов, отчетов, панелей мониторинга, оповещений, REST API и пакетов SDK.
Существует множество уникальных возможностей, которые делают Анализ данных лучшим аналитическим механизмом для аналитики журналов и временных рядов в Azure.
В следующих разделах выделяются ключевые отличия.
Индексирование данных с произвольным текстом и частично структурированным индексированием данных обеспечивает высокую производительность и высокую параллельную обработку запросов практически в реальном времени.
Data Explorer индексирует частично структурированные данные (JSON) и неструктурированные данные (свободный текст), что позволяет выполнять запросы с данными этого типа. По умолчанию каждое поле индексируется во время приема данных с возможностью использовать низкоуровневую политику кодирования для точной настройки или отключения индекса для определенных полей. Областью индекса является один сегмент данных.
Реализация индекса зависит от типа поля, как показано ниже.
| Тип поля | Реализация индексирования |
|---|---|
| String | Обработчик создает инвертированный индекс термина для значений строкового столбца. Каждое строковое значение анализируется и разделяется на нормализованные термины, и затем для каждого термина записывается упорядоченный список логических позиций, содержащий порядковые номера записей. Итоговый отсортированный список терминов и связанных с ними позиций хранится в виде неизменяемого сбалансированного дерева. |
| Числовой DateTime TimeSpan |
Обработчик создает простой индекс в виде прямого индекса на основе диапазона. Индекс записывает значения min и max для каждого блока, для группы блоков и для всего столбца в сегменте данных. |
| динамически; | Процесс приема данных перечисляет все "атомарные" элементы в динамическом значении, такие как имена свойств, значения и элементы массива, и пересылает их построителю индексов. Динамические поля имеют тот же инвертированный индекс термина, что и строковые поля. |
Эти эффективные возможности индексирования позволяют исследовать данные практически в реальном времени для высокопроизводительных запросов и запросов с высокой степенью параллелизма. Система автоматически оптимизирует сегменты данных для дальнейшего повышения производительности.
Язык запросов Kusto
Сообщество KQL быстро растет и активно внедряет возможности Azure Monitor Log Analytics и Application Insights, Microsoft Sentinel, Azure Data Explorer и других предложений Майкрософт. В языке используется простой для чтения синтаксис и обеспечивается плавный переход от простого кода в одну строку к сложным запросам на обработку данных. Это позволяет Data Explorer обеспечить расширенную поддержку IntelliSense, а также широкий набор языковых конструкций и встроенных возможностей для агрегирования, временных рядов и аналитики пользователей, которые недоступны в SQL для быстрого изучения данных телеметрии.