Руководство по Анализ текста со службами ИИ Azure
Анализ текста — это службы ИИ Azure, которые позволяют выполнять интеллектуальный анализ текста и анализ текста с помощью функций обработки естественного языка (NLP). В этом руководстве объясняется, как использовать Анализ текста для выполнения анализа неструктурированного текста в Azure Synapse Analytics.
В этом руководстве демонстрируется использование функции анализа текста с SynapseML для выполнения следующих задач:
- Определение меток тональности на уровне предложения или документа
- Указание языка для данного текстового ввода
- Распознавание сущностей из текста со ссылками на хорошо известную базу знаний
- Извлечение ключевых фраз из текста
- Идентификация различных сущностей в тексте и классификация их в предварительно определенные классы или типы
- Идентификация и редактирование конфиденциальных сущностей в заданном тексте
Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
Предварительные требования
- Рабочая область Azure Synapse Analytics с учетной записью хранения Azure Data Lake Storage 2-го поколения, настроенной в качестве хранилища по умолчанию. При работе с файловой системой Data Lake Storage 2-го поколения вам нужно иметь права участника для получения данных Хранилища BLOB-объектов.
- Пул Spark в рабочей области Azure Synapse Analytics. Дополнительные сведения см. в статье Создание пула Spark в Azure Synapse.
- Действия по предварительной настройке, описанные в руководстве Настройка служб ИИ Azure в Azure Synapse.
Начало работы
Откройте Synapse Studio и создайте записную книжку. Чтобы приступить к работе, импортируйте SynapseML.
import synapse.ml
from synapse.ml.cognitive import *
from pyspark.sql.functions import col
Настройка анализа текста
Используйте связанный анализ текста, настроенный на этапе предварительной конфигурации.
ai_service_name = "<Your linked service for text analytics>"
Тональность текста
Анализ тональности текста представляет собой способ обнаружения меток тональности (отрицательные, нейтральные и положительные) и оценок достоверности на уровне предложения и документа. Список включенных языков см. на странице Языки, поддерживаемые в API анализа текста.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, its sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Ожидаемые результаты
| text | Тональность |
|---|---|
| I am so happy today, its sunny! | позитивная тональность |
| I am frustrated by this rush hour traffic | негативная тональность |
| Службы ИИ Azure в Spark плохо | позитивная тональность |
Детектор языка
Средство распознавания языка оценивает текст входных данных каждого документа и возвращает идентификаторы языка с оценкой, указывающей на степень анализа. Эта возможность нужна для содержимого хранилищ, которое собирает произвольный текст, где язык неизвестен. Список включенных языков см. на странице Языки, поддерживаемые в API анализа текста.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Ожидаемые результаты

Детектор сущностей
Детектор сущностей возвращает список распознанных сущностей со ссылками на авторитетную базу знаний. Список включенных языков см. на странице Языки, поддерживаемые в API анализа текста.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Ожидаемые результаты
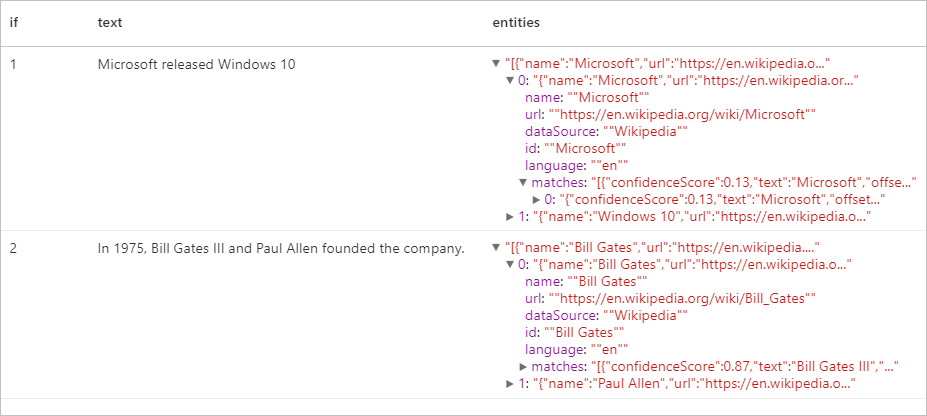
Извлечение ключевых фраз
Средство извлечения ключевых фраз оценивает неструктурированный текст и возвращает список ключевых фраз. Эта возможность полезна, если необходимо быстро определить основные тезисы в коллекции документов. Список включенных языков см. на странице Языки, поддерживаемые в API анализа текста.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Ожидаемые результаты
| text | keyPhrases |
|---|---|
| "Привет, мир!" Это пример входного текста, который мне нравится. | "["Привет, мир!","входной текст"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Распознавание именованных сущностей (NER)
Распознавание именованных сущностей (NER) — это возможность определения различных сущностей в тексте и категоризация их по заранее определенным классам или типам, таким как "пользователь", "расположение", "событие", "продукт" и "организация". Список включенных языков см. на странице Языки, поддерживаемые в API анализа текста.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Ожидаемые результаты
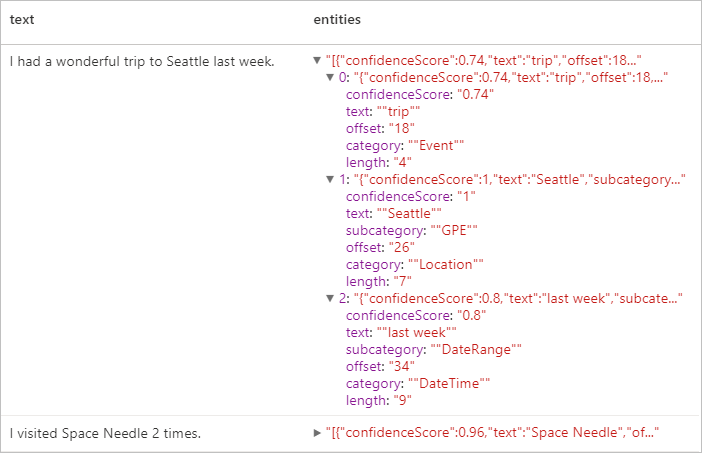
Личные сведения (PII) версии 3.1
Функция PII является частью NER и может находить и изменять конфиденциальные сущности в тексте, связанном с отдельным пользователем, например: номер телефона, адрес электронной почты, почтовый адрес, номер паспорта. Список включенных языков см. на странице Языки, поддерживаемые в API анализа текста.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Ожидаемые результаты

Очистка ресурсов
Чтобы правильно завершить работу экземпляра Spark, завершите все подключенные сеансы (записные книжки). Пул Apache Spark завершит работу автоматически, когда истечет указанное для него время простоя. Можно также выполнить команду остановки сеанса из строки состояния в верхней правой части записной книжки.
