Подключение к Azure Data Explorer с помощью Apache Spark для Azure Synapse Analytics
В этой статье описывается, как получить доступ к базам данных Azure Data Explorer из Synapse Studio с помощью Apache Spark для Azure Synapse Analytics.
Необходимые компоненты
- Создайте кластер и базу данных Azure Data Explorer.
- У вас есть рабочая область Azure Synapse Analytics или создайте новую рабочую область, выполнив действия, описанные в кратком руководстве. Создание рабочей области Azure Synapse.
- Укажите существующий пул Apache Spark или создайте новый пул, выполнив действия, описанные в кратком руководстве. Создание пула Apache Spark с помощью портал Azure.
- Создайте приложение Microsoft Entra, подготовив приложение Microsoft Entra.
- Предоставьте приложению Microsoft Entra доступ к базе данных, выполнив действия, описанные в статье "Управление данными Azure Обозреватель разрешениями базы данных".
Перейдите в Synapse Studio
В рабочей области Azure Synapse выберите Запуск Synapse Studio. На домашней странице Synapse Studio выберите Данные, чтобы открыть обозреватель объектов данных.
Подключение базы данных Azure Data Explorer к рабочей области Azure Synapse
Подключение базы данных Azure Data Explorer к рабочей области выполняется через связанную службу. С помощью связанной службы Azure Data Explorer вы можете просматривать, изучать, читать и записывать данные из Apache Spark для Azure Synapse. Вы также можете запускать задания интеграции в конвейере.
В обозревателе объектов данных выполните следующие действия, чтобы создать прямое соединение с кластером Azure Data Explorer.
Выберите значок + рядом с областью Данные.
Выберите Подключиться, чтобы подключиться к внешним данным.
Выберите Azure Data Explorer (Kusto)
Выберите Продолжить.
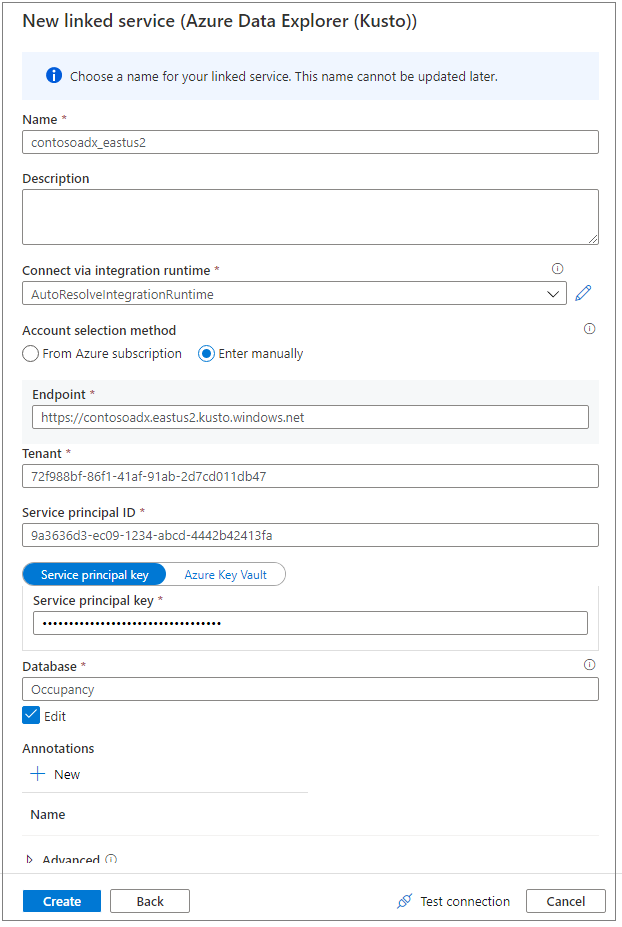
Чтобы присвоить имя связанной службе, используйте понятное имя. Имя появится в обозревателе объектов данных и будет использоваться средами выполнения Azure Synapse для подключения к базе данных.
Выберите кластер Azure Data Explorer из подписки или введите универсальный код ресурса (URI).
Введите идентификатор субъекта-службы и ключ субъекта-службы. Убедитесь, что субъект-служба имеет доступ на просмотр к базе данных для чтения и получения доступа для приема данных.
Введите имя базы данных Azure Data Explorer.
Щелкните Проверить подключение, чтобы убедиться в наличии нужных разрешений.
Выберите Создать.
Примечание.
(Необязательно) Проверка подключения не проверяет доступ на запись. Убедитесь, что у идентификатора субъекта-службы есть доступ на запись к базе данных Azure Data Explorer.
Кластеры и базы данных Azure Data Explorer отображаются на вкладке Связанные в разделе Azure Data Explorer.
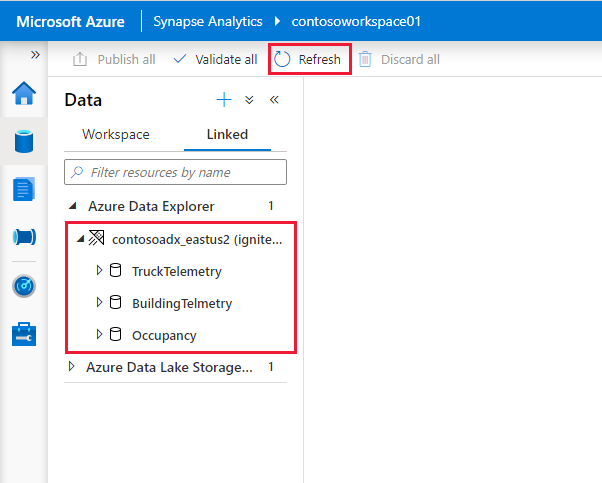
Прежде чем можно будет взаимодействовать со связанной службой из записной книжки, ее необходимо опубликовать в рабочей области. Нажмите Опубликовать на панели инструментов, просмотрите ожидающие изменения и щелкните OK.
Примечание.
В текущем выпуске объекты базы данных заполняются на основе разрешений учетной записи Microsoft Entra в базах данных Обозреватель Azure. При запуске записных книжек Apache Spark или заданий интеграции будут использоваться учетные данные в службе каналов (например, субъект-служба).
Быстрое взаимодействие с созданными кодом действиями
Если щелкнуть правой кнопкой мыши базу данных или таблицу, появится список примеров записных книжек Spark. Выберите параметр для чтения, записи или потоковой передачи данных в Azure Data Explorer.

Ниже приведен пример считывания данных. Подключите записную книжку к пулу Spark и выполните эту ячейку.

Примечание.
Первый запуск сеанса Spark может занять более трех минут. Последующие выполнения будут завершаться значительно быстрее.
Ограничения
Соединитель Azure Data Explorer в настоящее время не поддерживается в управляемых виртуальных сетях Azure Synapse.