Руководство по Создание приложения машинного обучения с помощью Apache Spark MLlib и Azure Synapse Analytics
В этой статье описано, как с помощью Apache Spark MLlib создать приложение машинного обучения для проведения простого прогнозного анализа на основе открытого набора данных Azure. Apache Spark содержит встроенные библиотеки машинного обучения. В этом примере используется классификация с помощью логистической регрессии.
SparkML и MLlib — это основные библиотеки Spark, содержащие множество служебных программ, которые подходят для выполнения задач машинного обучения, в частности для таких:
- Классификация
- Регрессия
- Кластеризация
- тематического моделирования;
- сингулярного разложения и анализа по методу главных компонент;
- проверки гипотез и статистической выборки.
Общие сведения о классификации и логистической регрессии
Классификация — это распространенная задача машинного обучения, которая представляет собой процесс сортировки входных данных по категориям. Алгоритм классификации определяет принцип назначения меток предоставленным входным данным. Например, вы можете создать алгоритм машинного обучения, который принимает в качестве входных данных информацию об акциях и делит их на две категории: акции, которые следует продать, и акции, которые стоит оставить.
Логистическая регрессия — один из алгоритмов, который можно использовать для классификации. API Spark для логистической регрессии подходит для задач двоичной классификации или разделения входных данных на две группы. Дополнительные сведения о логистической регрессии см. на соответствующей вики-странице (на английском языке).
В общих словах, в основе логистической регрессии лежит некая логистическая функция, используемая для прогнозирования вероятности принадлежности вектора входных данных к одной или другой группе.
Пример прогнозного анализа на основе данных такси Нью-Йорка
В этом примере Spark используется для выполнения прогнозного анализа данных о чаевых, оставленных таксистам Нью-Йорка. Данные доступны через открытые наборы данных Azure. Это подмножество набора данных содержит сведения о поездках на такси, включая сведения о каждой поездке, времени начала и окончания и расположениях, стоимости и других интересных атрибутах.
Важно!
За извлечение этих данных из хранилища может взиматься дополнительная плата.
Далее вы разработаете модель для прогнозирования того, будут ли чаевые за ту или иную поездку.
Создание модели машинного обучения Apache Spark
Создайте записную книжку, используя ядро PySpark. Инструкции см. в разделе Создание записной книжки.
Импортируйте типы, необходимые для этого приложения. Скопируйте указанный ниже фрагмент кода, вставьте его в пустую ячейку и нажмите клавиши SHIFT+ВВОД. Или выполните ячейку, щелкнув синий значок воспроизведения слева от кода.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorЯдро PySpark позволяет не задавать контексты явным образом. Контекст Spark будет создан автоматически при выполнении первой ячейки кода.
Создание входного кадра данных
Так как необработанные данные имеют формат Parquet, вы можете использовать контекст Spark, чтобы извлечь файл в память напрямую в виде кадра данных. Хотя в коде из описанных ниже шагов используются параметры по умолчанию, при необходимости можно принудительно сопоставить типы данных и другие атрибуты схемы.
Выполните приведенные ниже строки, чтобы создать кадр данных Spark, вставив код в новую ячейку. При этом данные извлекаются через API Открытых наборов данных. Получение всех этих данных приводит к созданию порядка 1 500 000 000 строк.
В зависимости от размера бессерверного пула Apache Spark объем необработанных данных может быть слишком большим или их обработка может занимать слишком много времени. Эти данные можно отфильтровать до меньшего объема. В следующем примере кода с помощью параметров
start_dateиend_dateприменяется фильтр, который возвращает данные за один месяц.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Недостаток простой фильтрации состоит в том, что с точки зрения статистической схемы это может привести к смещению данных. Другой подход заключается в использовании выборки, встроенной в Spark.
Приведенный ниже код позволяет сократить набор данных до 2000 строк, если он применяется после приведенного выше кода. Этот шаг выборки можно использовать вместо простой фильтрации или в сочетании с простым фильтром.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Теперь вы можете просмотреть данные, чтобы узнать, что было считано. Обычно целесообразнее просмотреть данные с подмножеством, а не с полным набором. Это зависит от размера набора данных.
Приведенный ниже код позволяет просмотреть данные двумя способами. Первый способ прост. Второй способ предоставляет многофункциональные возможности работы с сеткой, а также возможность визуализировать данные графически.
#sampled_taxi_df.show(5) display(sampled_taxi_df)В зависимости от размера созданного набора данных и необходимости повторно запускать эксперимент или записную книжку, может быть полезным кэширование набора данных в локальную рабочую область. Существует три способа для явного кэширования:
- сохранение кадра данных локально в виде файла;
- сохранение кадра данных в виде временной таблицы или представления;
- сохранение кадра данных в виде постоянной таблицы.
Первые два из этих способов включены в приведенные ниже примеры кода.
При создании временной таблицы или представления используются разные пути доступа к данным, которые действуют только в течение сеанса экземпляра Spark.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Подготовка данных
Данные в необработанной форме часто не подходят для передачи непосредственно в модель. В отношении данных необходимо выполнить ряд действий, чтобы перевести их в состояние, в котором модель может их использовать.
В следующем коде выполняются четыре класса операций:
- Удаление выбросов или неверных значений с помощью фильтрации.
- Удаление ненужных столбцов.
- Создание новых столбцов, производных от необработанных данных, для повышения эффективности работы модели. Эта операция иногда называется конструированием признаков.
- Добавление меток. Так как выполняется двоичная классификация (будут ли оставлены чаевые после той или иной поездки), сумму чаевых необходимо преобразовать в значение 0 или 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Затем выполняется второй проход по данным для добавления окончательных функций.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
создание модели логистической регрессии;
И последняя задача — преобразование данных с метками в формат, удобный для анализа методом логистической регрессии. Входные данные для алгоритма логистической регрессии должны представлять собой набор пар "метка — вектор признаков" , где вектор признаков содержит числа, представляющие точку входных данных.
Поэтому необходимо преобразовать столбцы категорий в числа. А именно, столбцы trafficTimeBins и weekdayString нужно преобразовать в целочисленные представления. Есть несколько подходов к выполнению преобразования. В следующем примере используется подход OneHotEncoder, который довольно популярен.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Это действие позволяет создать новый кадр данных со всеми столбцами в правильном формате для обучения модели.
Обучение модели логистической регрессии
Первая задача — разделить набор данных на обучающий набор и тестовый или проверочный набор. Разделение здесь является произвольным. Поэкспериментируйте с различными параметрами разделения, чтобы понять, влияют ли они на модель.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Теперь, когда есть два кадра данных, необходимо создать формулу модели и выполнить ее для обучающего кадра данных, а затем проверить по тестовому кадру данных. Поэкспериментируйте с различными версиями формулы модели, чтобы оценить влияние разных сочетаний.
Примечание
Чтобы сохранить модель, назначьте роль Azure Участник для данных BLOB-объектов хранилища для области ресурсов сервера Базы данных SQL. Подробные инструкции см. в статье Назначение ролей Azure с помощью портала Microsoft Azure. Это действие могут выполнять только участники с правами владельца.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
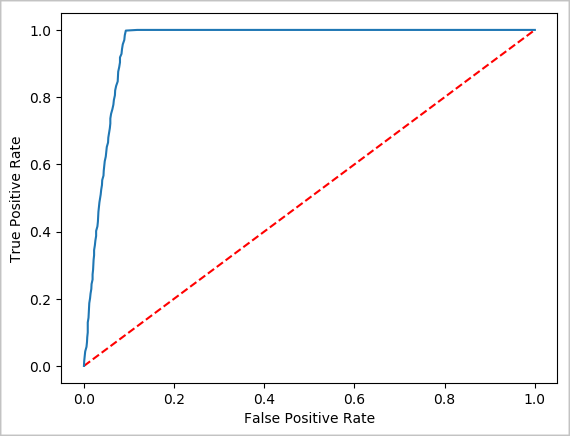
print("Area under ROC = %s" % metrics.areaUnderROC)
Выходные данные этой ячейки выглядят так:
Area under ROC = 0.9779470729751403
Создание визуального представления прогноза
Теперь создайте итоговую визуализацию, которая позволит оценить результаты теста. Один из способов просмотра результата — кривая ROC.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Завершение работы экземпляра Spark
По окончании использования приложения закройте вкладку, чтобы завершить работу записной книжки и освободить ресурсы. Или выберите элемент Завершить сеанс из строки состояния в нижней части записной книжки.
См. также раздел
Дальнейшие действия
- Документация по .NET для Apache Spark
- Azure Synapse Analytics
- Официальная документация по Apache Spark
Примечание
В некоторых из официальных документов по Apache Spark предполагается использование консоли Spark, которая недоступна для Apache Spark в Azure Synapse Analytics. Вместо этого используйте интерфейсы записной книжки или IntelliJ.